카프카 브로커는 카프카 클라이언트와 데이터를 주고 받기 위해 사용하는 주체
또한 브로커는 데이터를 분산 저장하여 장애가 발생하더라도 안전하게 사용할 수 있도록 도와주는 애플리케이션이다.
브로커
하나의 서버에는 기본적으로 1개의 카프카 프로세스가 실행된다.
카프카를 사용할 때 조금 더 안전하게 보관하고 처리하기 위해서는 3대 이상의 브로커 서버를 1개의 클러스터로 묶어서 운영한다.
클러스터 내부의 브로커들은 프로듀서가 보낸 데이터를 안전하게 분산 저장 및 복제를 한다.
데이터 저장, 전송
프로듀서로부터 데이터 전달을 받은 브로커는 프로듀서가 요청한 토픽의 파티션에 데이터를 저장하고,
컨슈머가 데이터를 요청하면 파티션에 저장된 데이터를 전달한다.
프로듀서로부터 전달되는 데이터는 파일 시스템에 저장된다.
파일 시스템에 저장을 하면 처리속도가 메모리에서 처리하는것 보다는 현저히 느린 이슈가 있지만, 카프카는 페이지 캐시 방식을 적용하여 디스크 입출력 속도를 해결하였다.
페이지 캐시
OS에서 파일 입출력의 성능 향상을 위해 만들어 놓은 메모리 영역
추후 동일한 파일에 접근을 할 시 디스크에서 읽는 것이 아닌 메모리에서 직접읽는 방식이다.
데이터 복제, 링크
카프카는 기본적으로 장애를 허용하는 시스템이다. 이것이 가능한 이유는 카프카는 데이터 복제를 하기 때문이다.
클러스터로 묶인 브로커중 일부에 장애가 발생을 하여도 복제를 함으로써 데이터를 유실하지 않고 안전하게 사용할 수 있다.
카프카의 데이터 복제는 파티션 단위로 이루어진다.
토픽을 생성할 때 파티션의 복제 개수를 지정하여 사용한다.
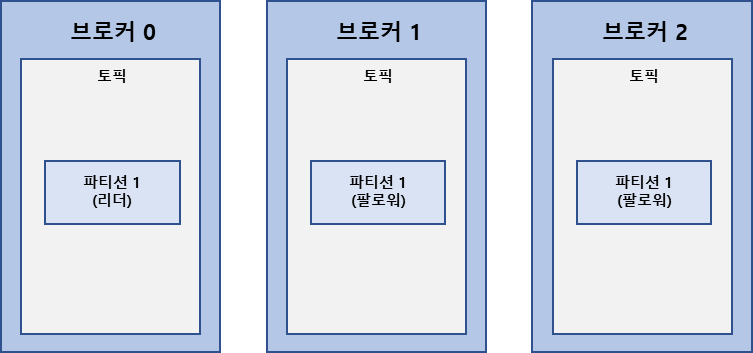
복제된 파티션은 리더와 팔로워를 가진다.
프로듀서, 컨슈머와 직접 통신하는 파티션을 리더, 나머지 복제 데이터를 가지고 있는 파티션을 팔로워라고 부른다.
복제 파티션은 팔로워라고 부르는데 리더 팔로워가 장애가 발생하면 다른 팔로워가 리더 역할을 대신하여 임무를 계속 수행한다.
