카프카를 실행하기 앞서 config 폴더에서 server.properties 파일을 설정하여
클러스터 운영에 필요한 옵션들을 지정할 수 있다.
Kafka 설정파일
-
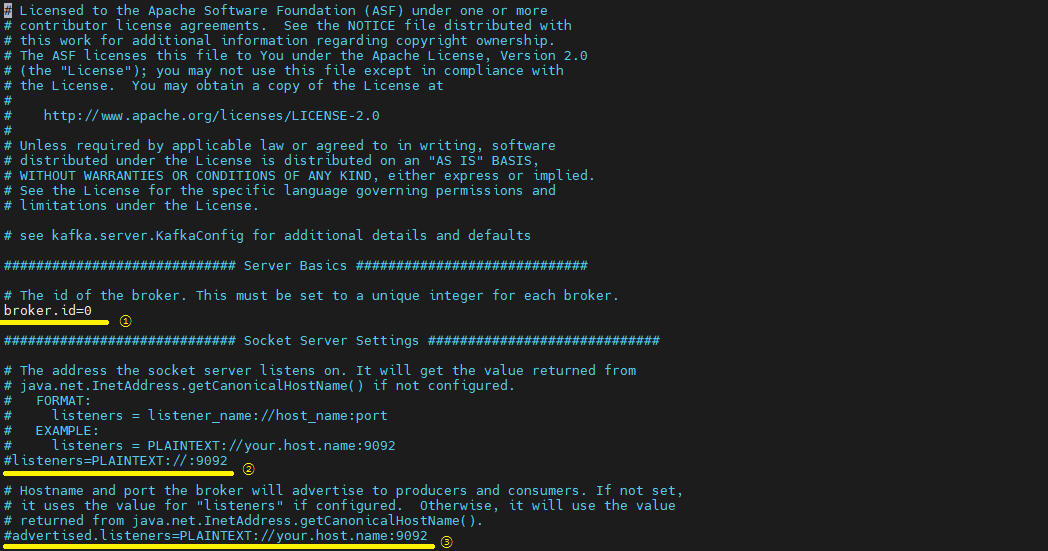
카프카의 브로커 번호를 지정하는 역할을 수행, 클러스터를 구축할 때 브로커들을 구분하기 위한 단 하나뿐인 번호로 설정해야한다., 동일한 ID를 가질경우 비정상적인 동작이 발생할 수 있다.
-
카프카 브로커가 통신을 위해 열어둘 인터페이스 IP, PORT 프로토콜 설정, 따로 설정하지 않으면 모든 IP, PORT에서 접속이 가능하다.
-
카프카 클라이언트, 카프카 CLI 툴에서 접속 할 때 사용하는 IP, PORT -> IP에는 인스턴스 생성시 발급받은 퍼블릭 IPv4 값을 넣고 PORT에는 카프카 기본포트인 9092를 넣는다.

-
SASL_SSL, SASL_PLAIN 보안 설정 시 프로토콜 매핑을 위한 설정
-
네트워크를 통한 처리를 할 때 사용하는 네트워크 스레드 개수
-
카프카 브로커 내부에서 사용할 스레드 개수
-
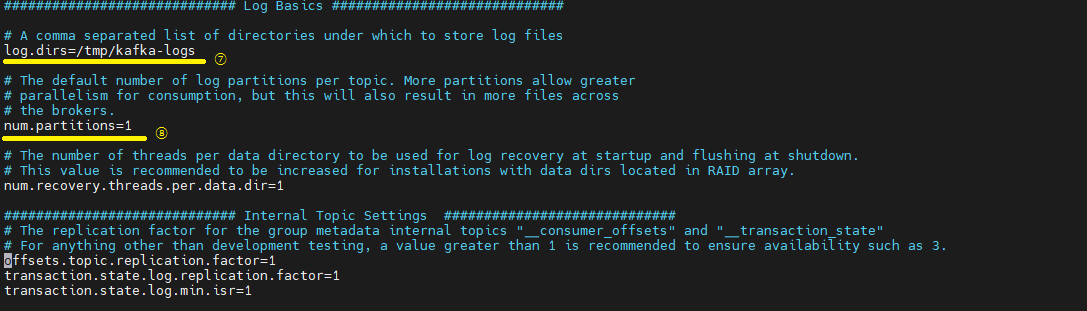
통신을 통해 가져온 데이터를 파일로 저장할 디렉터리 위치, 디렉터리가 생성되있지 않으면 오류가 발생 할 수 있기 때문에 브로커 실행 전 디렉터리를 생성해야 한다.
-
파티션 개수를 명시 하지 않고 토픽을 생성하였을 때 기본적으로 설정되는 파티션 개수이다.
-> 파티션의 개수가 많아지면 병렬처리 데이터 양이 늘어난다.
-
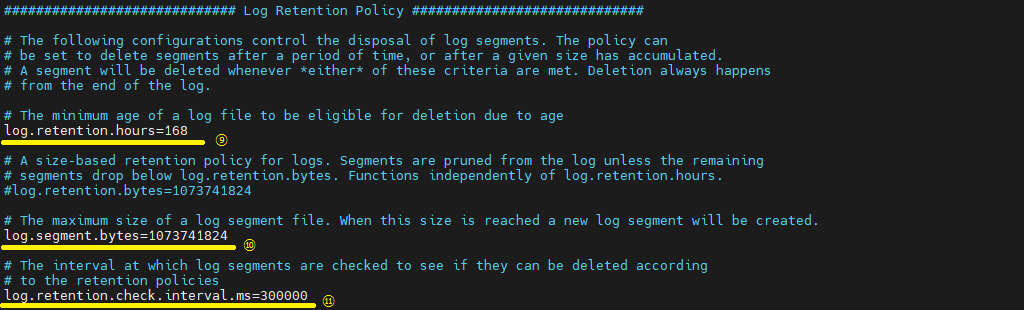
카프카 브로커가 저장한 파일이 삭제되기까지 걸리는 시간을 설정할 수 있다. [log.retention.hour, log.retention.ms]가 있다. 하지만 log.retention.ms로 하여 작은 단위를 기준으로 하여 운영하는 것을 추천, -1로 설정하면 파일이 영원히 삭제되지 않는다.
-
카프카 브로커가 저장할 파일의 최대 크기를 지정한다. 데이터양이 많아져서 크기를 다 채우면, 새로운 파일이 생성된다.
-
카프카 브로커가 저장한 파일을 삭제하기 위해 체크하는 간격을 지정할 수 있다.
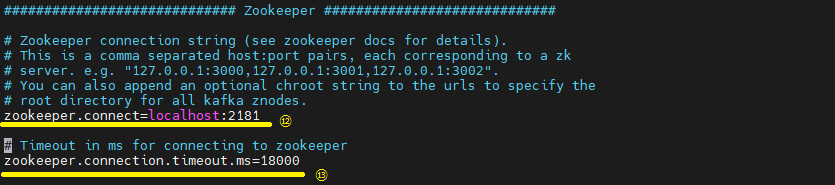
- 카프카 브로커와 연동할 주키퍼의 IP, PORT를 설정한다.
- 주키퍼의 세션 타임아웃 시간을 설정한다.
주키퍼 사용
주키퍼란? 분산 애플리케이션 관리를 위한 안정된 코디네이션 서비스이다.
코디네이션 서비스란?
분산 시스템 내에서 중요한 상태정보나 설정 정보들을 유지, 클러스터에 있는 서버들의 상태를 체크, 분산된 서버들간의 동기를 위한 lock처리 등을 관리.

여기서 Server(주키퍼)를 클러스터로 구성하고, 분산 애플리케이션(Kafka)들이 각각 클라이언트가 되어 주키퍼 서버들과 커넥션을 맺은 후 상태 정보등을 주고 받는다.
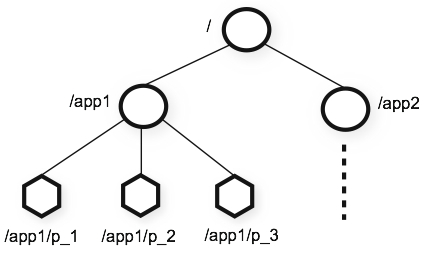
상태 정보들은 주키퍼의 znode(지노드)라고 불리는 곳에 key-value형식으로 저장하며, 지노드에 저장된 것을 이용하여 분산 애플리케이션은 서로 데이터를 주고 받게 된다.
znode
지노드는 우리가 알고 있는 디렉터리와 비슷한 형태로 되어있으며 자식노드를 가지고 있는 계층형 구조로 이루어져 있다.
주키퍼 실행
주키퍼도 카프카 클러스터와 마찬가지로 3대 이상의 서버로 구성하여 사용해야만 안정적인 서비스를 제공할 수 있다. 실습에서는 1개만 사용하는데, 이러한 주키퍼를 Quick-and-dirty single-node라고 불린다.
이러한 방식은 비정상적인 운영임을 뜻하며, 테스트 할 때만 사용하도록 해야한다.
주키퍼를 실행하기 위해 카프카 패키지의 bin 폴더 내부의 zookeeper-server-start.sh 파일을 실행시킨다. -daemon 옵션과 주키퍼 설정인 config/zookeeper.properties 파일을 함께 사용하여 백그라운드에서 실행 할 수 있다.
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
jps -vm
주키퍼를 실행 시키고 jps -vm 명령어를 사용하여 JVM 프로세스 상태를 확인 할 수 있다.
v옵션은 JVM에 전달된 인자 (힙 메모리 설정, log4j)설정을 함께 사용할 수 있으며, m 옵션은 main 메서드에 전달된 인자를 확인 할 수 있다.
카프카 실행
주키퍼을 실행 했으면 마지막으로 카프카를 실행 시키면 된다. -daemon옵션을 통해 카프카 브로커를 백그라운드로 실행할 수 있다. kafka-server-start.sh 파일을 사용하며 jps 명령을 통해 주키퍼와 브로커 프로세스의 동작 여부를 알 수 있다.
bin/kafka-server-start.sh -daemon config/server.properties
jps -m
tail -f log/server.log
카프카 브로커의 로그는 카프카 클라이언트를 개발 할 때 뿐만 아니라, 카프카 클러스터를 운영할 때 발생하는 이슈도 브로커의 로그에 남기 때문에 중요하다.
카프카 통신 확인
카프카 브로커가 정상적으로 실행이 되었다면, 브로커로 명령을 내려 정상적으로 통신하는지 확인 해야한다. 확인하는 가장 간단한 방법은 카프카 브로커 정보를 요청하는 것이다.
로컬에서 카프카 브로커에 명령을 내리기 위해서는 shell이 필요한데, windows에는 shell이없기 때문에 WSL2를 설치하여 윈도우에서 리눅스를 사용할 수 있는 환경을 구축하면된다.

이후 윈도우 로컬 환경에서 카프카 바이너리 패키지를 다운받아 압축을 해제 하면된다.
curl https://archive.apache.org/dist/kafka/2.5.0/kafka_2.12-2.5.0.tgz --output kafka.tgz
tar -xvf kafka.tgz
위 와 같이 압축이 해제 되는 것을 확인 할 수 있다.
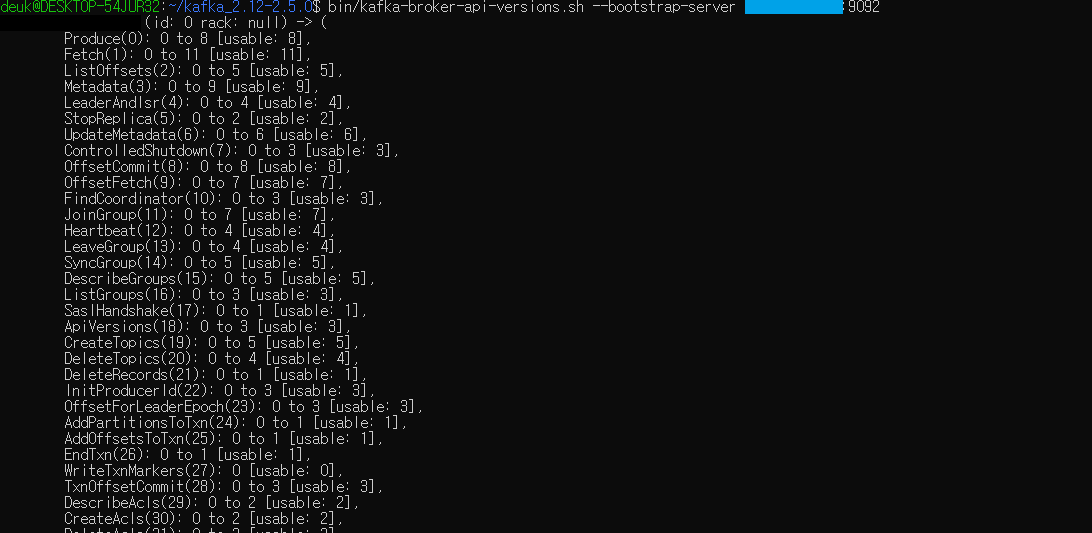
이후 kafka-broker-api-versions.sh 명령어와 함께 --bootstrap-server 옵션에 인스턴스 IP와 9092포트를 넣으면 원격으로 카프카 버전과 broker.id, rack 정보, 카프카 브로커 옵션들을 확인 할 수 있다.
bin/kafka-broker-api-versions.sh --bootstrap-server {aws 인스턴스 IP}:9092