
반복문은 왜 마지막 요소를 포함하지 않을까?
// rust
for i in 1..10 {
dbg!(i) // 1, 2, 3, 4, 5, 6, 7, 8, 9
}
let arr = [1, 2, 3, 4, 5];
dbg!(&arr[0..2]);for(let i = 1; i < 10 ; i++){
console.log(i); // 1, 2, 3, 4, 5, 6, 7, 8, 9
}
const arr = [1, 2, 3, 4, 5 ]
console.log(arr.slice(0, 2));- 🤔 반복문을 돌거나, 배열을 자를 때
마지막 요소가 포함되지 않는 이유는 무엇인가 궁금했다
이 부분에 대한 설득력 있는 의견을 발견했다!
다익스트라의 메모이다.
1 ~ 10까지는 몇 개야?
나는 당당하게 10개라고 말한다.
1, 2, 3, 4, 5, 6, 7, 8, 9, 10 // 10개
- 왜냐고?
- 10에서 1을 빼
- 9지?
- 근데 1을 포함해야 되니까 1을 더해 (???)
- 그러니 10개야 (???)
위의 답을 도출하기 위해 1과 10이 포함되므로 나는 10에서 1을 빼고 1을 더한다.
- 그럼 17에서 23까지는 몇개야?
17, 18, 19, 20, 21, 22, 23 // 7개
- 23에서 17을 빼
- 6이지?
- 근데 17을 포함해야 되니까 1을 더해
- 그러니 7개야
우리는 어떤 범위
N ~ M을 구할 때N - 1부터 출발한다.
우리는 어떤 범위N ~ M을 구할 때M을 포함한다.
학교에서 선생님이 1번부터 5번 나와
하면 (5번)까지가 안 붙었어도 1, 2, 3, 4, 5 번이 나왔었던 것 같다.
억지인가 .. ㅎㅎ;;
😤 각설하고, 구간에 대해 한 번 알아보자
구간(Interval)
우리가 범위를 표현 할 때(a와 b 사이의 수)는 4가지 방법이 있다
- a <= x <= b -> x는 a보다
크거나 같고, b보다작거나 같다. - a <= x < b -> x는 a보다
크거나 같고, b보다작다. - a < x <= b -> x는 a보다
크고, b보다작거나 같다. - a < x < b -> x는 a보다
크고, b보다작다.
- 🥸 여기서
a와b사이에x가 몇개가 될 수 있는지 생각 해보자 a= 1,b= 10
- 1 <= x <= 10 -> x는 1보다 크거나 같고, 10보다 작거나 같다.
-> 10 - 1 + 1 = 10
-> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 //10개
- 1 <= x < 10 -> x는 0보다 크거나 같고, 10 보다 작다
-> 10 - 1 = 9
-> 1, 2, 3, 4, 5, 6, 7, 8, 9 //9개
- 1 < x <= 10 -> x는 0보다 크고, 10보다 작거나 같다.
-> 10 - 1 = 9
-> 2, 3, 4, 5, 6, 7, 8, 9, 10 //9개
- 1 < x < 10 -> x는 0보다 크고, 10보다 작다
-> 10 - 1 - 1 = 8
-> 2, 3, 4, 5, 6, 7, 8 ,9 //8개
여기서 우리가 직관적으로 범위에 포함된 요소의 개수를 구할 때 가장 쉬운 방법은 2번과 3번이다.
-> 즉, 범위의 끝에서 범위의 시작을 빼는 것이다.
이를 다른 말로 하면, 반 닫힌 구간이다.
시작 수와 마지막 수의 차와집합의 크기가 같은 것은 요소의 개수를 구하기가 쉽다.
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10} - {1} = {2, 3, 4, 5, 6, 7, 8, 9}
10 - 1 = 9
N은 구간 내의 요소의 개수
(a, b], [a, b)는 |a-b| = N
[a, b]는 |a - b| = N - 1
(a, b)는 |a - b| = N + 1
Half-open interval(반 닫힌 구간)
범위에 포함되는 요소의 개수를 구할 때 반닫힌 구간을 이용한다는 것이 직관적이다라는 것을 이해했다.
그렇다면 반닫힌 구간에는
1. [a, b) -> 앞의 것을 포함
2. (a, b] -> 뒤의 것을 포함
두 가지 경우가 있는데 반복문은 왜 범위에 전자를 선택하였는 지 알아 보자.
✔ 일단, 반복문을 찍어보자
// [a, b) 컨밴션
for i in 1..10 {
dbg!(i) // 1, 2, 3, 4, 5, 6, 7, 8, 9 1을 포함하고 10을 제외 했다.
}
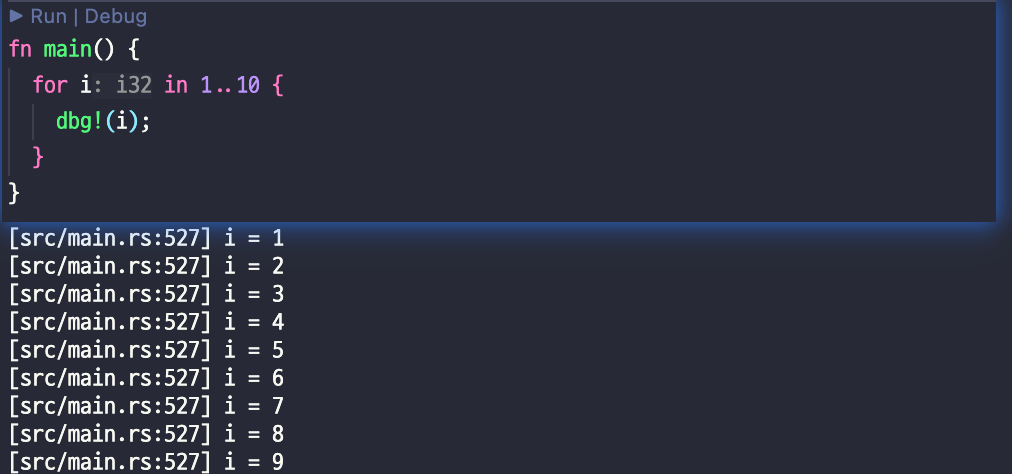
더 눈으로 보이는 비교를 위해 Rust 언어의 반복문 형식을 가져 왔다.
만약 러스트가 (a, b] 형식의 반닫힘 구간을 지원했다면 우리를 1 ~ 9까지를 콘솔에 찍기 위해 아래와 같이 표현을 해야 했을 것이다.
// 2. (a, b] 컨벤션
for i in -1..9 {
dbg!(i) // 1, 2, 3, 4, 5, 6, 7, 8, 9
}흠, 물론 사람마다 다를 수 있겠지만, 전자에 비해 더 헷갈리지 않을까?
다익스트라가 제시한 예시도 한 번 살펴보자.
Xerox PARC에서 Mesa라는 프로그래밍 언어 만들어서 사람들이 썼다고 한다.
이 언어에는(a,b] [a,b) [a,b] (a,b)이 네 가지 컨벤션을 지원하는 특별한 문법이 있었는데, 사람들이 이 컨벤션을 사용할 때[a,b)를 제외한 나머지 컨벤션은 오류가 많이 발생하는 원인 중 하나 였다고 한다.
이를 계기로 Mesa 프로그래머들이 나머지 3개 문법을 지원하지 않게 되었다.
🫡 여러모로 <= x < 의 범위를 사용하는 것이 편할 것 같다.
인덱스는 왜 0부터 시작할까?
메모리가 0부터 시작한다.
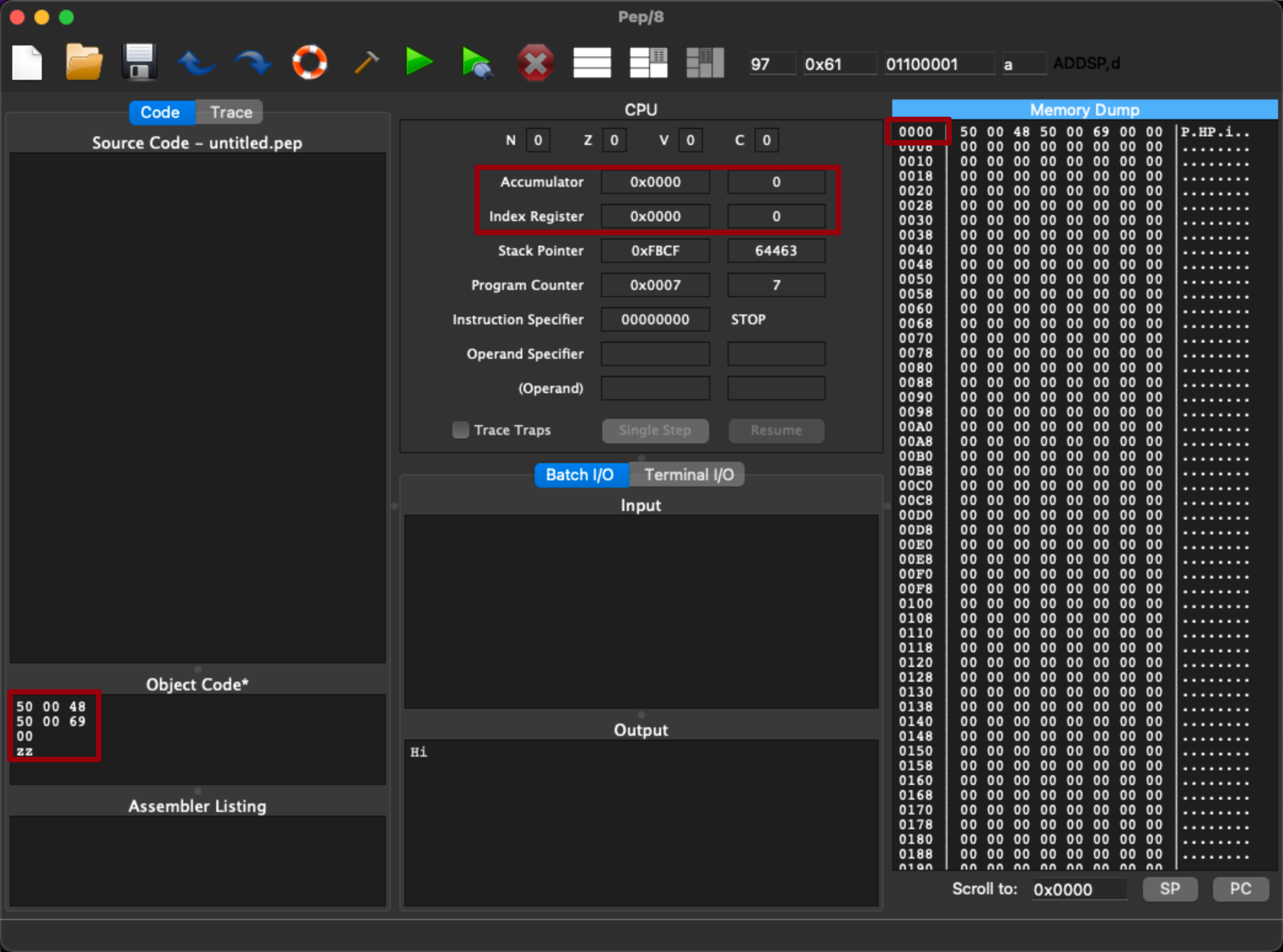
아래는 pep/8이라는 기계어를 실행하는 가상 머신이다.
아래 시작 인덱스를 보면 0x0000, Memory Dump를 보면 0000으로 시작한다.
아래는 러스트 언어로 Null의 포인터 값을 찍어본 것이다. 0으로 시작한다.
fn main() {
let address: *const () = std::ptr::null(); // ptr::null()은 메모리 주소 0을 나타냅니다.
println!("메모리 시작 주소: {:?}", address);
let null_varaible: *const () = std::ptr::null();
dbg!(null_varaible);
}
물론, 메모리에 적재되는
실제 주소가 아니라 프로세스의논리 주소이다.
실제 주소도 0부터.. 시작하지 않을까?// 오피셜은 더 찾아봐야겠다
[a, b)
[a, b) 반 닫힘 구간을 표현 할 때 0부터 시작하는 것이 가장 깔끔하다.
만약, 시작하는 숫자가 1이라고 정하면 우리는 N번 반복하기 위해 1 <= i < N + 1와 같이 표현할 것이다.
하지만, 시작하는 숫자가 0이라면 0 <= i < N으로 딱 떨어지고 깔끔하게 표현할 수 있게 된다!!
즉, 인덱스가
0부터 시작해야마지막 수가집합의 크기와 같아져서 더 직관적이게 된다.
0 <= i <10
10 === {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} //10번 순회
vs
1 <= i <11
10 === {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} //10번 순회
🫡 여러모로 0부터 시작하는 것이 편할 것 같다.
완벽하게 설득되지 않을 수도 있습니다..!
제가 느꼈을 때 가장 설득력 있는 메모라 정리해 보았습니다!
혹시라고 더 좋은 이유들이 있다면 공유해 주시면 감사하겠습니다 :) ( _ _)
참고자료
https://nanite.tistory.com/56
https://www.cs.utexas.edu/users/EWD/ewd08xx/EWD831.PDF
