리액티브 프로그래밍 이해하기
리액티브 프로그래밍은 명령형 프로그래밍의 대안이 되는 패러다임입니다.
명령형 프로그래밍의 발상은 간단합니다. 한 번에 하나씩 만나는 순서대로 실행되는 명령어들로 코드를 작성하면 됩니다. 그리고 프로그램에서는 하나의 작업이 완전히 끝나기를 기다렸다가 그다음 작업을 수행합니다. 각 단계마다 처리되는 데이터는 전체를 처리할 수 있도록 사용할 수 있어야 합니다.
그러나 작업이 수행되는 동안 특히 이 작업이 원격지 서버로부터 데이터베이스에 데이터를 쓰거나 가져오는 것과 같은 것이라면 이 작업이 완료될 때까지 아무것도 할 수 없습니다. 따라서 이 작업을 수행하는 스레드는 차단되고 이렇게 차단된 스레드는 낭비입니다.
자바를 비롯해서 대부분의 프로그래밍 언어는 동시 프로그래밍을 지원합니다. 자바에서는 스레드가 어떤 작업을 수행하는 동안 이 스레드에서 다른 스레드를 시작시키고 작업을 수행하는 것은 매우 쉽습니다. 하지만 스레드를 생성하는 것은 쉬울지라도 생성된 스레드는 어떤 이유로든 결국 차단될 수 있습니다. 게다가 다중 스레드로 동시성을 관리하는 것은 쉽지 않습니다.
리액티브 프로그래밍은 본질적으로 함수적이면서 선언적 입니다. 즉, 순차적으로 수행되는 작업 단계를 나타낸 것이 아니라 데이터가 흘러가는 파이프라인이나 스트림을 포함합니다. 그리고 이런 리액티브 스트림은 데이터 전체를 사용할 수 있을 때까지 가디리지 않고 사용 가능한 데이터가 있을 때마가 처리되므로 사실상 입력되는 데이터는 무한할 수 있습니다.
리액티브 스트림 정의하기
리액티브 프로그래밍은 동시에 여러 작업을 수행하여 더 큰 확장성을 얻게 해줍니다. 백 프레셔는 데이터를 소비하는 컨슈머가 처리할 수 있는 만큼으로 전달 데이터를 제한함으로써 지나치게 빠른 데이터 소스로부터의 데이터 전달 폭주를 피할 수 있는 수단입니다.
cf) 자바 스트림 vs 리액티브 스트림
자바 스트림과 리액티브 스트림은 많은 유사성이 있습니다. 우선, 둘 다 Streams라는 단어가 이름에 포함됩니다. 또한, 데이터로 작업하기 위한 다수의 똑같은 API를 제공합니다.
그러나 자바 스트림은 대게 동기화되어 있고 한정된 데이터로 작업을 수행합니다.
리액티브 스트림은 무한 데이터셋을 비롯해서 어떤 크기의 데이터셋이건 비동기 처리를 지원합니다. 그리고 실시간으로 데이터를 처리하며, 백 프레셔를 사용하여 데이터 전달 폭주를 막습니다.
리액티브 스트림은 4개의 인터페이스로 요약할 수 있습니다.
- Publisher : 발행자
- Subscriber : 구독자
- Subscription : 구독
- Processor : 프로세서
Publisher는 하나의 Subscription당 하나의 Subscriber에 발행하는 데이터를 생성합니다. Publisher 인터페이스에는 Subscriber가 Publisher를 구독 신청할 수 있는 subscribe() 메서드 한 개가 선언되어 있습니다.
public interface Publisher<T> {
void subscribe(Subscriber<? super T> subscriber);
}그리고 Subscriber가 구독 신청되면 Publisher로부터 이벤트를 수신할 수 있습니다. 이 이벤트들을 Subscriber 인터페이스의 메서드를 통해 전송됩니다.
public static interface Subscriber<T> {
public void onSubscribe(Subscription subscription);
public void onNext(T item);
public void onError(Throwable throwable);
public void onComplete();
}Subscriber가 수신할 첫 번째 이벤트는 onSubscribe()의 호출을 통해 이뤄집니다. Publisher가 onSubscribe 메서드를 호출할 때 인자로 Subscription 객체를 전달하면 Subscriber는 Subcription 객체를 통해서 구독을 관리합니다.
public interface Subscription {
void request(long n);
void cancel();
}Subscriber는 request 메서드를 호출하여 전송되는 데이터를 요청하거나, 또는 더 이상 데이터를 수신하지 않고 구독을 취소한다는 것을 나타내기 위해 cancel 메서드를 호출할 수 있습니다. request 메서드를 호출할 때 Subscriber는 받고자 하는 데이터 항목 수를 나타내는 long타입의 값을 인자로 전달합니다. 바로 이것이 백 프레셔이며, Subscriber가 처리할 수 있는 것보다 더 많은 데이터를 Publisher가 전송하는 것을 막아줍니다. 요청된 수의 데이터를 Publisher가 전송한 후에 Subscriber는 다시 request 메서드를 호출하여 더 많은 요청을 할 수 있습니다.
Subscriber의 데이터 요청이 완료되면 데이터가 스트림을 통해 전달되기 시작합니다. 이때 onNext 메서드가 호출되어 Publisher가 전송하는 데이터가 Subscriber에게 전달되며, 만일 에러가 발생하면 onError 메서드가 호출됩니다. 그리고 Publisher에서 전송할 데이터가 없고 더 이상의 데이터를 생성하지 않는다면 Publisher가 onComplete 메서드를 호출하여 작업이 끝났다고 Subscriber에게 알려줍니다.
Processor 인터페이스는 다음과 같이 Subscriber 인터페이스와 Publisher 인터페이스를 결합한 것입니다.
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {}Subscriber 역할로 Processor는 데이터를 수신하고 처리합니다. 그다음에 역할을 바꾸어 Publisher 역할로 처리 결과를 자신의 Subcriber들에게 발행합니다.
보면 알 수 있듯이, 리액티브 스트림은 꽤 직관적이라서 데이터 처리 파이프라인을 개발하는 방법을 쉽게 알 수 있습니다. 즉, Publisher로부터 시작해서 0 또는 그 이상의 Processor를 통해 데이터를 끌어온 다음 최종 결과를 Subscriber에게 전달합니다.
그러나 리액티브 스트림 인터페이스는 스트림을 구성하는 기능이 없습니다. 이에 따라 프로젝트 리액터에서는 리액티브 스트림을 구성하는 API를 제공하여 리액티브 스트림 인터페이스를 구현했습니다. 이후 설명하겠지만, 리액터는 스프링 5의 리액티브 프로그래밍 모델의 기반입니다.
리액터 시작하기
리액티브 프로그래밍은 명령형 프로그래밍과 매우 다른 방식으로 접근해야 합니다. 즉, 일련의 작업 단계를 기술하는 것이 아니라 데이터가 전달될 파이프라인을 구성해야 합니다. 그리고 이 파이프라인을 통해 데이터갖 ㅓㄴ달되는 동안 어떤 형태로든 변경 또는 사용될 수 있습니다.
String name = "Craig";
String capitalName = name.toUpperCase();
String greeting = "Hello, " + capitalName + "!";
System.out.println(greeting);위 코드는 같은 스레드에서 한 단계씩 차례로 실행됩니다. 따라서 각 단계가 완료될 때까지 다음 단계로 이동하지 못하게 실행 중인 스레드를 막습니다.
Mono.just("Craig")
.map(n -> n.toUpperCase())
.map(cn -> "Hello, " + cn + "!")
.subscribe(System.out::println);위 리액티브 코드는 단계별로 실행되는 것처럼 보이겠지만, 실제로는 데이터가 전달되는 파이프라인을 구성하는 것입니다. 그리고 파이프라인의 각 단계에서는 어떻게 하든 데이터가 변경됩니다. 또한, 각 오퍼레이션은 같은 스레드로 실행되거나 다른 스레드로 실행될 수 있습니다.
Mono와 Flux
Mono와 Flux는 리액터의 핵심 타입입니다. 둘다 리액티브 스트림의 Publisher 인터페이스를 구현한 것입니다.
- Flux : 0, 1 또는 다수의 데이터를 갖는 타입
- Mono : 하나의 데이터 항목만 갖는 타입
바로 위의 Mono 예시를 다시 보겠습니다.
예시에서는 세 개의 Mono가 생성됩니다. just 메서드가 첫 번째 Mono를 생성합니다. 그리고 그 값을 map 메서드가 받아서 대문자로 변경한 뒤 새로운 두번째 Mono를 생성합니다. 이것이 다음 map 메서드에 전달되어 문자열 결합 후 새로운 세번째 Mono를 생성합니다. 그리고 끝으로 subscribe 메서드에서는 세번째 Mono를 구독하여 데이터를 수신하고 출력합니다.
정리하면, Mono가 방출한 값을 오퍼레이션(메서드)가 새로운 Mono를 만들어 냅니다. Flux도 마찬가지로 Flux는 여러 값을 방출하고 오퍼레이션(메서드)가 받아서 새로운 Flux 값을 만들어냅니다.
리액터 의존성 추가
implementation 'io.projectreactor:reactor-core'
testImplementation 'io.projectreactor:reactor-test'리액티브 오퍼레이션 적용하기
Flux와 Mono는 리액터가 제공하는 가장 핵심적인 타입입니다. 두 타입이 제공하는 오퍼레이션(메서드)들은 두 타입을 함께 결합하여 데이터가 전달될 수 있는 파이프라인을 생성합니다. 약 500개 이상의 오퍼레이션이 있으며 다음과 같이 분류됩니다.
- 생성
- 조합
- 변환
- 로직
리액티브 타입 생성하기
스프링에서 리액티브 타입을 사용할 때는 리포지토리나 서비스로부터 Flux나 Mono가 제공되므로 따로 리액티브 타입을 생성할 필요는 없습니다. 그러나 데이터를 발행하는 새로운 리액티브 발행자를 생성해야 할 때가 있습니다.
리액터는 Flux나 Mono를 생성하는 오퍼레이션을 제공하는데 몇가지 알아봅시다.
객체로부터 생성하기
Flux나 Mono로 생성하려는 하나 이상의 객체가 있다면 Flux나 Mono의 just() 메서드를 사용하여 리액티브 타입을 생성할 수 있습니다.
just()
@Test
public void createAFlux_just() {
Flux<String> fruitFlux = Flux
.just("Apple", "Orange", "Grape", "Banana", "Strawberry");
}위 코드에서는 5개의 String 객체로부터 Flux를 생성했습니다.
이 경우 Flux는 생성되지만 Subscriber가 없습니다. 구독자가 없이는 데이터가 전달되지 않기 때문에 구독자를 추가할 때는 subcribe 메서드를 호출하면 됩니다.
subcribe()
fruitFlux.subscribe(
f -> System.out.println("here's some fruit: " + f)
)여기서 람다는 Consumer이며 리액티브 스트림의 Subscriber 객체를 생성하기 위해 사용됩니다.
Flux와 Mono의 항목들을 콘솔로 출력하면 실제 작동하는 것을 파악하는 데 좋습니다. 그러나 리액터의 StepVerifier를 사용하는 것이 Flux나 Mono를 테스트하는 더 좋은 방법입니다.
StepVerifier는 해당 리액티브 타입을 구독한 다음에 스트림을 통해 전달되는 데이터에 대해 assertion을 적용하고 기대한 대로 동작하는지 검사합니다.
StepVerifier.create(fruitFlux)
.expectNext("Apple")
.expectNext("Orange")
.expectNext("Grape")
.expectNext("Banana")
.expectNext("Strawberry")
.verifyComplete();각 데이터 항목이 기대한 과일 이름과 일치하는지 assertion을 적용하고 마지막에는 fruitFlux가 완전한지 검사합니다.
컬렉션으로부터 생성하기
Flux는 배열, Iterable 객체, 자바 Stream객체로부터 생성될 수도 있습니다.
@Test
public void createAFlux_fromArray() {
String[] fruits = new String[] {
"Apple", "Orange", "Grape", "Banana", "Strawberry" };
// 배열로부터 생성하기
Flux<String> fruitFlux = Flux.fromArray(fruits);
// Iterable로부터 생성
Flux<String> fruitFlux = Flux.fromIterable(fruitList);
// Stream으로부터 생성
Flux<String> fruitFlux = Flux.fromStream(fruitStream);Flux 데이터 생성하기
때로는 매번 새 값으로 증가하는 숫자를 방출하는 카운터 역할의 Flux가 필요한 경우가 있습니다.
@Test
public void createAFlux_range() {
Flux<Integer> intervalFlux =
Flux.range(1, 5); // 1부터 5까지 포함하는 Flux 생성
StepVerifier.create(intervalFlux)
.expectNext(1)
.expectNext(2)
.expectNext(3)
.expectNext(4)
.expectNext(5)
.verifyComplete();
}range와 유사한 기능을 제공하는 interval 메서드가 있는데 이는 시작 값과 종료 값 대신 값이 방출되는 시간 간격이나 주기를 지정합니다.
interval()
@Test
public void createAFlux_interval() {
Flux<Long> intervalFlux =
Flux.interval(Duration.ofSeconds(1))
.take(5);
StepVerifier.create(intervalFlux)
.expectNext(0L)
.expectNext(1L)
.expectNext(2L)
.expectNext(3L)
.expectNext(4L)
.verifyComplete();
}Flux가 방출하는 값은 0부터임을 주의해야 하고 최대값이 지정되지 않는 경우 무한정 실행됩니다. 따럿 take 메서드를 사용하여 5개의 항목으로 제한할 수 있습니다.
리액티브 타입 조합하기
두 개의 리액티브 타입을 결합해야 하거나 하나의 Flux를 두 개 이상의 리액티브 타입으로 분할해야 하는 경우가 있을 수 있습니다.
리액티브 타입 결합하기
두 개의 Flux 스트림을 하느이 Flux로 결합하기 위한 mergeWith 메서드가 존재합니다.
mergeWith()
@Test
public void mergeFluxes() {
Flux<String> characterFlux = Flux
.just("Garfield", "Kojak", "Barbossa")
.delayElements(Duration.ofMillis(500));
Flux<String> foodFlux = Flux
.just("Lasagna", "Lollipops", "Apples")
.delaySubscription(Duration.ofMillis(250))
.delayElements(Duration.ofMillis(500));
Flux<String> mergedFlux = characterFlux.mergeWith(foodFlux);
StepVerifier.create(mergedFlux)
.expectNext("Garfield")
.expectNext("Lasagna")
.expectNext("Kojak")
.expectNext("Lollipops")
.expectNext("Barbossa")
.expectNext("Apples")
.verifyComplete();
}일반적으로 Flux는 가능한 빨리 데이터를 방출하기 때문에 조금 느리게 방출하기 위해 0.5초 딜레이를 주었습니다. 또한, foodFlux가 characterFlux가 방출한 이후에 방출하도록 순서를 정해주기 위해 delaySubscription 메서드를 적용하여 0.25초가 지난 후에 구독 및 데이터를 방출하도록 하였습니다. 이렇게 하여 하나의 새로운 Flux로 만들어냈습니다.
mergedFlux로부터 방출되는 항목의 순서는 두 개의 Flux로부터 방출되는 시간에 맞춰 결정됩니다. 여기서는 잘 맞춰서 character -> food -> character 순이지만 방출 속도가 조절되면 순서는 바뀔 수 있습니다.
mergeWith 메서드는 Flux들이 값이 완벽하게 번갈아 방출되게 보장할 수 없으므로 필요하다면 zip 메서들르 사용하여 각 Flux로부터 한 항목씩 번갈아 가져와 새로운 Flux를 생성하게 할 수 있습니다.
zip()
@Test
public void zipFluxes() {
Flux<String> characterFlux = Flux
.just("Garfield", "Kojak", "Barbossa");
Flux<String> foodFlux = Flux
.just("Lasagna", "Lollipops", "Apples");
Flux<Tuple2<String, String>> zippedFlux =
Flux.zip(characterFlux, foodFlux);
StepVerifier.create(zippedFlux)
.expectNextMatches(p ->
p.getT1().equals("Garfield") &&
p.getT2().equals("Lasagna"))
.expectNextMatches(p ->
p.getT1().equals("Kojak") &&
p.getT2().equals("Lollipops"))
.expectNextMatches(p ->
p.getT1().equals("Barbossa") &&
p.getT2().equals("Apples"))
.verifyComplete();
}zip메서드로 생성된 Flux로부터 방출되는 각 항목은 Tuple2(두 개의 다른 객체를 전달하는 컨테이너)이며, 각 소스 Flux가 순서대로 방출하는 항목을 포함합니다. 만약 Tuple2가 아닌 다른 타입을 사용하고 싶다면 우리가 원하는 객체를 생성하는 함수를 zip에 제공하면 됩니다.
@Test
public void zipFluxesToObject() {
Flux<String> characterFlux = Flux
.just("Garfield", "Kojak", "Barbossa");
Flux<String> foodFlux = Flux
.just("Lasagna", "Lollipops", "Apples");
Flux<String> zippedFlux =
Flux.zip(characterFlux, foodFlux, (c, f) -> c + " eats " + f);
StepVerifier.create(zippedFlux)
.expectNext("Garfield eats Lasagna")
.expectNext("Kojak eats Lollipops")
.expectNext("Barbossa eats Apples")
.verifyComplete();
}zip에 전달되는 함수에서 두 Flux의 항목을 문자열로 결합하여 String 타입인 Flux를 만들어 낼 수 있습니다.
먼저 값을 방출하는 리액티브 타입 선택하기
두 개의 Flux가 있는데 결합하는 대신 먼저 값을 방출하는 Flux의 값을 발행하는 새로운 Flux가 생성하고 싶다면 first 메서드를 사용합니다.
first()
@Test
public void firstFlux() {
Flux<String> slowFlux = Flux.just("tortoise", "snail", "sloth")
.delaySubscription(Duration.ofMillis(100));
Flux<String> fastFlux = Flux.just("hare", "cheetah", "squirrel");
Flux<String> firstFlux = Flux.first(slowFlux, fastFlux);
StepVerifier.create(firstFlux)
.expectNext("hare")
.expectNext("cheetah")
.expectNext("squirrel")
.verifyComplete();
}first 메서드는 두 Flux 중에서 느린 것은 무시하고 먼저 방출되는 Flux만 가지로 새로운 Flux를 만듭니다.
리액티브 스트림의 변환과 필터링
데이터가 스트림을 통해 흐르는 동안 일부 값을 필터링하거나 변경해야 할 경우가 있습니다.
리액티브 타입으로부터 데이터 필터링하기
Flux로부터 데이터가 전달될 때 필터링하는 가장 기본적인 방식은 skip 하는 것입니다.
skip()
@Test
public void skipAFew() {
Flux<String> countFlux = Flux.just(
"one", "two", "skip a few", "ninety nine", "one hundred")
.skip(3);
StepVerifier.create(countFlux)
.expectNext("ninety nine", "one hundred")
.verifyComplete();
}앞선 3개의 스트림을 skip 합니다.
특정 항목 수를 건너뛰는 대신 일정 시간이 경과할 때까지 처음의 여러 항목을 건너뛰어야 하는 경우가 있습니다.
@Test
public void skipAFewSeconds() {
Flux<String> countFlux = Flux.just(
"one", "two", "skip a few", "ninety nine", "one hundred")
.delayElements(Duration.ofSeconds(1))
.skip(Duration.ofSeconds(4));
StepVerifier.create(countFlux)
.expectNext("ninety nine", "one hundred")
.verifyComplete();
}항목간의 1초 지연으로 방출을 시도하고 skip을 사용해 4초간의 방출 데이터는 스킵하고 이후부터 실질적으로 방출합니다.
이에 반대 기능은 take 입니다. 처음부터 지정된 개수의 항목만을 방출합니다.
take()
@Test
public void take() {
Flux<String> nationalParkFlux = Flux.just(
"Yellowstone", "Yosemite", "Grand Canyon", "Zion", "Acadia")
.take(3);
StepVerifier.create(nationalParkFlux)
.expectNext("Yellowstone", "Yosemite", "Grand Canyon")
.verifyComplete();
}@Test
public void takeForAwhile() {
Flux<String> nationalParkFlux = Flux.just(
"Yellowstone", "Yosemite", "Grand Canyon", "Zion", "Grand Teton")
.delayElements(Duration.ofSeconds(1))
.take(Duration.ofMillis(3500));
StepVerifier.create(nationalParkFlux)
.expectNext("Yellowstone", "Yosemite", "Grand Canyon")
.verifyComplete();
}take도 skip과 마찬가지로 경과 시간을 기준으로 방출 데이터를 처리할 수 있습니다. 1초 간격으로 방출되는 데이터 중에서 3.5초 동안의 데이터만 실질적으로 방출합니다.
take과 skip은 카운트와 시간을 기준으로 필터링했다면 일반적인 필터링은 predicate을 지정하는 filter 메서드가 있습니다.
filter()
@Test
public void filter() {
Flux<String> nationalParkFlux = Flux.just(
"Yellowstone", "Yosemite", "Grand Canyon", "Zion", "Grand Teton")
.filter(np -> !np.contains(" "));
StepVerifier.create(nationalParkFlux)
.expectNext("Yellowstone", "Yosemite", "Zion")
.verifyComplete();
} 경우에 따라서는 이미 발행된 항목(중복 제거)은 필터링으로 걸러낼 필요가 있는데 이때는 distinct 메서드를 사용합니다.
distinct()
@Test
public void distinct() {
Flux<String> animalFlux = Flux.just(
"dog", "cat", "bird", "dog", "bird", "anteater")
.distinct();
StepVerifier.create(animalFlux)
.expectNext("dog", "cat", "bird", "anteater")
.verifyComplete();
}리액티브 데이터 매핑하기
가장 많이 사용하는 메서드 중 하나는 다른 형태나 타입으로 매핑하는 것입니다. 리액티브의 타입은 map과 flatMap 메서드를 제공합니다.
map 메서드는 변환을 수행하는 Flux를 생성합니다.
map()
@Test
public void map() {
Flux<Player> playerFlux = Flux
.just("Michael Jordan", "Scottie Pippen", "Steve Kerr")
.map(n -> {
String[] split = n.split("\\s");
return new Player(split[0], split[1]);
});
StepVerifier.create(playerFlux)
.expectNext(new Player("Michael", "Jordan"))
.expectNext(new Player("Scottie", "Pippen"))
.expectNext(new Player("Steve", "Kerr"))
.verifyComplete();
}just로 생성된 Flux는 String을 발행하고 map의 결과로 생성된 Flux는 Player 객체를 발행합니다.
map에서 중요한 것은, 각 항목이 Flux로부터 발행될 때 동기적으로(각 항목을 순차적 처리) 매핑이 된다는 것입니다. 따라서 비동기적으로 (각 항목을 병행 처리) 매핑하고 싶다면 flatMap 메서드 를 사용해야 합니다. map에서는 한 객체를 다른 객체로 매핑하는 정도였지만, flatMap은 각 객체를 새로운 Mono나 Flux로 매핑하며, 해당 Mono나 Flux들의 결과는 하나의 새로운 Flux로 만들어 냅니다. 이 때 subscribeOn 메서드를 함께 사용하면 리택터 타입의 변환을 비동기적으로 수행할 수 있습니다.
flatMap()
@Test
public void flatMap() {
Flux<Player> playerFlux = Flux
.just("Michael Jordan", "Scottie Pippen", "Steve Kerr") // Flux 생성
.flatMap(n -> Mono.just(n) // 각각을 Mono로 만들고
.map(p -> { // Player로 변환
String[] split = p.split("\\s");
return new Player(split[0], split[1]);
})
.subscribeOn(Schedulers.parallel()) // 비동기
);
List<Player> playerList = Arrays.asList(
new Player("Michael", "Jordan"),
new Player("Scottie", "Pippen"),
new Player("Steve", "Kerr"));
StepVerifier.create(playerFlux)
.expectNextMatches(p -> playerList.contains(p))
.expectNextMatches(p -> playerList.contains(p))
.expectNextMatches(p -> playerList.contains(p))
.verifyComplete();
}String 타입의 입력 문자열을 Flux 타입으로 변환하고 FlatMap에서는 Mono로 변환한 뒤 map을 통해서 Player Flux로 변환합니다. 여기서 멈춘다면 Flux는 Player 객체를 동기적으로 생성하게 됩니다. 그러나 subscribeOn을 호출하였기 때문에 map 메서드가 비동기적으로 병행 수행되게 됩니다. 이때 인자로는 Schedulers의 static 메서드 중 하나를 사용합니다. 위 예에서는 고정된 크기의 스레드 풀(CPU 코어의 개수)의 작업 스레드로 실행되는 parallel을 사용했습니다. 추가적으로 지원하는 동시성 모델은 다음과 같습니다.

flatMap이나 subscribeOn 메서드를 사용할 때의 장점은 다수의 병행 스레드에 작업을 분할하여 스트림의 처리량을 증가시킬 수 있다는 것입니다. 그러나 작업이 병행으로 수행되므로 순서가 보장되지 않아 결과 Flux에서 방출되는 항목의 순서를 알 수 없고 위처럼 기대하는 항목이 존재하는지만 검사할 수 있습니다.
single, newSingle, parallel은 논블로킹 작업에 사용되는 스레드를 생성합니다. 이 세 가지 스케줄러에 의해 생성되는 스레드는 리액터의 NonBlocking 인터페이스를 구현합니다. 따라서 block, blockFirst, blockLast 같은 블로킹 코드가 사용되면 IllegalStateException이 발생합니다.
리액터 플로우에서 스케줄러를 변경하는 방법은 두 가지 입니다.
- publishOn : 호출되는 시점 이후로는 지정한 스케줄러를 사용합니다. 이 방법을 사용하면 사용하는 스케줄러를 여러 번 바꿀 수 있습니다.
- bscribeOn : 플로우 전 단계에 걸쳐 사용되는 스케줄러를 지정합니다. 플로우 전체에 영향을 미치므로 publishOn에 비해 영향 범위가 넓습니다.
subscribeOn 메서드의 위치는 중요하지 않고 어디에 위치하든 해당 플로우 전체가 subscribeOn 메서드로 지정한 스레드에서 실행됩니다. 다만 나중에 publishOn으로 스레드를 다시 지정하면 지정한 지점 이후부터는 publishOn으로 새로 지정한 스레드에서 리액터 플로우가 실행됩니다.
리액티브 스트림의 데이터 버퍼링하기
Flux를 통해 전달되는 데이터를 처리하는 동안 데이터 스트림을 작은 덩어리로 분할하면 도움이 될 수 있는데 이때 buffer 메서드를 사용합니다. buffer 메서드는 Flux로부터 List 컬렉션들을 포함하는 새로운 Flux를 생성합니다.
@Test
public void buffer() {
Flux<String> fruitFlux = Flux.just(
"apple", "orange", "banana", "kiwi", "strawberry");
Flux<List<String>> bufferedFlux = fruitFlux.buffer(3); // 3개 단위의 List를 발행하는 Flux 생성
StepVerifier
.create(bufferedFlux)
.expectNext(Arrays.asList("apple", "orange", "banana"))
.expectNext(Arrays.asList("kiwi", "strawberry"))
.verifyComplete();
}위에서는 3개 단위로 쪼개기 때문에 2개의 컬렉션을 방출하는 Flux로 변환됩니다.
리액티브 Flux로부터 리액티브가 아닌 List 컬렉션으로 버퍼링되는 값은 비생상적인 것처럼 보이지만 buffer 메서드를 flatMap 메서드와 함께 사용하면 각 List 컬렉션을 병행으로 처리할 수 있습니다.
@Test
public void bufferAndFlatMap() throws Exception {
Flux.just(
"apple", "orange", "banana", "kiwi", "strawberry")
.buffer(3) //Flux<List<String>>
.flatMap(x ->
Flux.fromIterable(x)
.map(y -> y.toUpperCase())
.subscribeOn(Schedulers.parallel())
.log()
).subscribe();
}5개의 값으로 된 Flux를 새로운 Flux로 버퍼링하지만, 이 Flux는 여전히 List 컬렉션을 포함합니다. 그러나 다음에 List 컬렉션의 Flux에 flatMap을 적용합니다. 이 경우 flatMap에서는 각 List 버퍼를 가져와 해당 List의 요소로부터 새로운 Flux를 생성하고 map 오퍼레이션을 적용합니다. 마지막에 subscribeOn을 통해 별도의 스레드에서 병행 처리될 수 있도록 해줍니다.
잘 동작하는지 확인하기 위해 log 메서드을 포함했는데 log 메서드는 모든 리액티브 스트림 이벤트를 로깅하여 어떻게 처리되었는지 파악할 수 있습니다.
만일 어떤 이유로 Flux가 방출되는 모든 항목을 List로 모을 필요가 있다면 buffer의 인자를 아무것도 주지 않으면 됩니다.
Flux<List<String>> bufferedFlux = fruitFlux.buffer();이 경우에는 Flux가 발행한 모든 항목을 포함하는 List를 방축하는 새로운 Flux가 생성되는데 collectionList 메서드를 사용하면 똑같은 결과를 얻을 수 있습니다.
@Test
public void collectList() {
Flux<String> fruitFlux = Flux.just(
"apple", "orange", "banana", "kiwi", "strawberry");
Mono<List<String>> fruitListMono = fruitFlux.collectList();
StepVerifier
.create(fruitListMono)
.expectNext(Arrays.asList(
"apple", "orange", "banana", "kiwi", "strawberry"))
.verifyComplete();
}Flux의 방출 항목을 모으는 기능으로 collectMap 메서드도 있습니다. collectMap은 Map을 포함하는 Mono를 생성합니다. 이때 해당 Map에는 지정된 함수로 산출된 키를 갖는 항목이 저장됩니다.
@Test
public void collectMap() {
Flux<String> animalFlux = Flux.just(
"aardvark", "elephant", "koala", "eagle", "kangaroo");
Mono<Map<Character, String>> animalMapMono =
animalFlux.collectMap(a -> a.charAt(0));
StepVerifier
.create(animalMapMono)
.expectNextMatches(map -> {
return
map.size() == 3 &&
map.get('a').equals("aardvark") &&
map.get('e').equals("eagle") &&
map.get('k').equals("kangaroo");
})
.verifyComplete();
}Map의 키는 동물의 첫 번째 문자로 결정되고 밸류는 동물 이름 자체가 됩니다. 첫 글자가 같은 경우에는 나중에 나온 동물이 밸류가 됩니다.
리액티브 타입에 로직 오퍼레이션 수행하기
발행한 항목이 어떤 조건과 일치하는지만 알아야 하는 경우가 있는데 이때는 all과 any 메서드를 사용합니다.
all()
@Test
public void all() {
Flux<String> animalFlux = Flux.just(
"aardvark", "elephant", "koala", "eagle", "kangaroo");
Mono<Boolean> hasAMono = animalFlux.all(a -> a.contains("a"));
StepVerifier.create(hasAMono)
.expectNext(true)
.verifyComplete();
Mono<Boolean> hasKMono = animalFlux.all(a -> a.contains("k"));
StepVerifier.create(hasKMono)
.expectNext(false)
.verifyComplete();
}all 메서드는 모든 동물의 이름에 a가 들어있는 지, k가 들어있는지를 검사합니다.
any()
@Test
public void any() {
Flux<String> animalFlux = Flux.just(
"aardvark", "elephant", "koala", "eagle", "kangaroo");
Mono<Boolean> hasAMono = animalFlux.any(a -> a.contains("a"));
StepVerifier.create(hasAMono)
.expectNext(true)
.verifyComplete();
Mono<Boolean> hasZMono = animalFlux.any(a -> a.contains("z"));
StepVerifier.create(hasZMono)
.expectNext(false)
.verifyComplete();
}any는 최소한의 하나의 항목이라도 일치하는지를 검사합니다. 여기서는 a는 어느 하나라도 포함되지만, z는 어느 하나에도 포함되지 않기 때문에 false가 나옵니다.
Rest API 리액티브하게 사용하기(WebClient)
스프링 MVC와 WebFlux 간의 주요한 차이는 빌드에 추가하는 의존성입니다. 스프링 WebFlux를 사용할 때는 표준 웹 스타터(spring-boot-starter-web) 대신 WebFlux 의존성을 추가해야 합니다.
implementation 'org.springframework.boot:spring-boot-starter-webflux'또한 WebFlux를 사용하면 기본 내장 서버가 톰캣 대신 Netty가 됩니다. Netty는 비동기적인 이벤트 중싱의 서버 중 하나입니다.
기존에는 RestTemplate을 통해 애플리케이션의 요청을 수행했습니다. 그러나 RestTemplate이 제공하는 모든 메서드는 리액티브가 아닌 도메인 타입이나 컬렉션을 처리합니다. 따라서 리액티브 방식으로 응답 데이터를 사용하고자 한다면, Flux, Mono 타입으로 래핑해야 합니다. 그리고 Flux, Mono 타입이 있으면서 POST, PUT 요청으로 전송하고 싶다면, 요청 하기 전에 Flux, Mono 데이터를 리액티브가 아닌 타입으로 추출해야 합니다.
이런 문제를 해결하기 위해 스프링 5가 RestTemplate의 리액티브 대안으로 WebClient를 제공합니다. WebClient는 외부 API로 요청을 할 때 리액티브 타입의 전송과 수신 모두를 합니다. Webclient의 사용은 RestTemplate과 많이 다릅니다. 다수의 메서드로 서로 다른 요청을 처리하는 대신 WebClient는 요청을 나타내고 전송하게 해주는 빌더 방식의 인터페이스를 사용합니다.
- WebClient의 인스턴스를 생성한다.(또는 빈을 주입한다.)
- 요청을 전송할 HTTP 메서드를 지정한다.
- 요청에 필요한 URI와 헤더를 지정한다.
- 요청을 제출한다.
- 응답을 소비(사용)한다.
GET
Mono<Ingredient> ingredient = WebClient.create()
.get()
.uri("http://localhost:8000/ingredients/{id}", ingredient)
.retrieve()
.bodyToMono(Ingredient.class);
ingredient.subscribe( i -> {...})- create 메서드로 새로운 WebClient 인스턴스를 생성한다.
- get과 uri 메서드를 사용해 GET 요청을 정의한다. 플레이스 홀더 값은 콤마 뒤에 값으로 매핑된다.
- retrieve 메서드는 해당 요청을 실행한다.
- bodyToMono 메서드는 응답 몸체의 페이로드를 Mono\로 추출한다.
bodyToMono로부터 반환되는 Mono에 추가로 메서드를 적용하려면 해당 요청이 전송되기 전에 구독해야 합니다. 따라서 제일 끝에서 subscribe 메서드를 호출합니다.
컬렉션에 저장된 값들을 반환하는 요청을 하는 것도 매우 쉽습니다.
Flux<Ingredient> ingredients = WebClient.create()
.get()
.uri("http://localhost:8000/ingredients/{id}", ingredients)
.retrieve()
.bodyToFlux(Ingredient.class);
ingredients.subscribe( i -> {...})bodyToMono 대신 bodyToFlux를 사용하면 Flux로 추출할 수 있습니다.
기본 URI로 요청하기
기본 URI는 서로 다른 많은 요청에서 사용할 수 있습니다. 이 경우 기본 URI를 갖는 WebClient 빈을 생성하고 주입받아서 사용할 수 있습니다.
@Bean
public WebClient webClient() {
return WebClient.create("http://localhost:8080");
}
@Autowired
WebClient webClitent;
public Mono<Ingredient> getIngredientById(String ingredientId) {
Mono<Ingredient> ingredient = webClient
.get()
.uri("/ingredients/{id}", ingredientId)
.retrieve()
.bodyToMono(Ingredient.class);
...
}WebClient를 빈으로 등록했기 때문에 바로 사용할 수 있습니다.
오래 실행되는 요청 타임아웃시키기
네트워크 지연 때문에 클라리언트 요청이 지체되는 것을 방지하기 위해 Flux나 Mono의 timeout 메서드를 사용하여 데이터를 기다리는 시간을 제한할 수 있습니다.
Mono<Ingredient> ingredient = WebClient.create()
.get()
.uri("http://localhost:8000/ingredients/{id}", ingredient)
.retrieve()
.bodyToMono(Ingredient.class);
ingredient
.timeout(Duration.ofSeconds(1))
.subscribe(
i -> { ... },
e -> {
// handle timeout error
}
)timeout을 1초 미만으로 수행할 수 있다면 아무런 문제가 없습니다. 그러나 1초보다 오래 걸리면 타임아웃이 되어 subscribe()의 두 번째 인자로 지정된 에러 핸들러가 호출됩니다.
리소스 전송하기
Mono<Ingredient> ingredientMono = ...;
Mono<Ingredient> ingredient = WebClient.create()
.post()
.uri("http://localhost:8000/ingredients/{id}", ingredient)
.body(ingredientMono, Ingredient.class)
.retrieve()
.bodyToMono(Ingredient.class);
ingredient.subscribe( i -> {...})get 대신 post 메서드를 사용하고 body 메서드를 호출하여 Mono를 사용하여 해당 요청 몸체에 넣는 것만 지정하면 됩니다.
만약 전송할 Mono, Flux가 없는 대신 도메인 객체가 있다면 syncBody를 사용할 수 있습니다.
예를 들어 Mono\ 대신 Ingredient 객체를 요청 몸체에 포함시켜 전송하고 싶다면 다음과 같습니다.
// post
Ingredient ingredient = ...;
Mono<Ingredient> ingredient = WebClient.create()
.post()
.uri("http://localhost:8000/ingredients/{id}", ingredient)
.syncBody(ingredient)
.retrieve()
.bodyToMono(Ingredient.class);
ingredient.subscribe( i -> {...})
// put
Ingredient ingredient = ...;
Mono<Void> ingredient = WebClient.create()
.put()
.uri("http://localhost:8000/ingredients/{id}", ingredient)
.syncBody(ingredient)
.retrieve()
.bodyToMono(Void.class)
.subscribe();리소스 삭제하기
// delete
Ingredient ingredient = ...;
Mono<Void> ingredient = WebClient.create()
.delete()
.uri("http://localhost:8000/ingredients/{id}", ingredient)
.syncBody(ingredient)
.retrieve()
.bodyToMono(Void.class)
.subscribe();삭제는 delete 메서드를 사용하면 됩니다.
다시 말하지만, 요청을 전송하려면 bodyToMono 메서드에 타입을 반환하고 subscribe 메서드로 구독해야 합니다.
에러 처리하기
에러를 처리해야 할 때는 onStatus() 메서드를 호출하여 처리해야 할 HTTP 상태 코드를 지정할 수 있습니다. onStatus()는 두 개의 함수를 인자로 받습니다. 처리해야 할 HTTP 상태와 일치시키는 데 사용되는 조건 함수와 Mono\을 반환하는 함수 입니다.
Mono<Ingredient> ingredient = WebClient.create()
.get()
.uri("http://localhost:8000/ingredients/{id}", ingredient)
.retrieve()
.bodyToMono(Ingredient.class);
ingredient.subscribe(
ingredient -> {
// 식자재 데이터를 처리한다.
},
error -> {
// 에러를 처리한다.
}
)에러가 생길 수 있는 Mono, Flux를 구독할 때는 subscribe 메서드를 호출할 때 데이터 컨슈머는 물론 에러 컨슈머도 등록하는 것이 중요합니다.
subscribe의 첫 번째 인자로 전달된 람다가 컨슈머 역할을 합니다. 만일 요청 응답이 404 상태 코드를 갖게 되면 두 번째 인자로 전달된 에러 컨슈머가 실행되어 기본적으로 WebClientResponseException 을 발생시킵니다.
그러나 WebClientResponseException은 구체적인 예외를 나타내는 것이 아니므로 Mono에 무엇이 잘못되었는지 정확히 알 수 없습니다. 따라서 자세히 알 수 있는 에러 컨슈머를 지정할 필요가 있고 WebClient의 것이 아닌 우리 도메인에 관련된 것이라면 더욱 좋을 것십니다.
커스텀 에러 핸들러를 추가하면 HTTP 상태 코드를 우리가 선택한 Throwable로 변환하는 실행 코드를 제공할 수 있습니다. 예를 들어 식자재 리소스의 요청에 실패했을 때 unknownIngredientException 에러를 포함하는 Mono로 생성하고 싶다고 한다면 다음과 같이 합니다.
Mono<Ingredient> ingredient = WebClient.create()
.get()
.uri("http://localhost:8000/ingredients/{id}", ingredient)
.retrieve()
.onStatus(HttpStatus::is4xxClientError,
response -> Mono.just(new UnknownIngredientException()))
.bodyToMono(Ingredient.class);
Mono<Ingredient> ingredient = WebClient.create()
.get()
.uri("http://localhost:8000/ingredients/{id}", ingredient)
.retrieve()
.onStatus(status -> status == HttpStatus.Not_Found, // 특정 HTTP 코드 지정
response -> Mono.just(new UnknownIngredientException()))
.bodyToMono(Ingredient.class);onstatus 메서드의 첫 인자는 HttpStatus를 지정하는 조건식이며, 우리가 처리를 원하는 HTTP 상태 코드라면 true를 반환합니다. 그리고 상태 코드가 일치하면 두 번째 인자의 함수로 응답이 반환되고 이 함수에서는 Throwable 타입의 Mono 타입을 반환합니다.
요청 교환하기
지금까지 WebClient를 사용할 때는 retrive() 메서드를 사용해서 요청의 전송을 나타냈습니다 이때 retrieve() 메서드는 ResponseSpec 타입의 객체를 반환하였으며, 이 객체를 통해서 onStatus(), bodyToFlux(), bodyToMono()와 같은 메서드를 호출하여 응답을 처리할 수 있었습니다. 간단한 상황에서는 이처럼 ResponseSpec을 사용하는 것이 좋습니다. 그러나 이 경우 몇 가지 면에서 제약이 있습니다. 예를 들어, 응답의 헤더나 쿠키 값을 사용할 필요가 있을 때는 ResponseSpec으로 처리할 수 없습니다.
이때는 retrieve 메서드 대신 exchange 메서드를 호출할 수 있습니다. exchange 메서드는 ClientReponse 타입의 Mono를 반환합니다. ClientResponse 타입을 리액티브 메서드를 적용할 수 있고, 응답의 모든 부분(페이로드, 헤더, 쿠기 등)에서 데이터를 사용할 수 있습니다.
두 메서드의 차이에 앞서 유사점을 확인해 봅시다. 특정 ID값은 하나의 식자재를 가져온다는 코드입니다.
Mono<Ingredient> ingredient = WebClient.create()
.get()
.uri("http://localhost:8000/ingredients/{id}", ingredient)
.retrieve()
.bodyToMono(Ingredient.class);Mono<Ingredient> ingredient = WebClient.create()
.get()
.uri("http://localhost:8000/ingredients/{id}", ingredient)
.exchange()
.flatMap(cr -> cr.bodyToMono(Ingredient.class));exchange에서는 ResponseSpec 객체의 BodyToMono를 사용해서 Mono\ 객체를 가져오는 대신, 매핑 함수 중 하나인 flatMap을 사용해 ClientResponse를 Mono\와 연관시킬 수 있는 Mono\를 가져옵니다.
이제 다른점을 알아봅시다.
요청의 응답에 true 값을 갖는 X_UNAVAILABLE이라는 이름의 헤더가 포함될 수 있다고 합시다. 그리고 헤더가 존재한다면 결과 Mono는 빈 것이어야 한다고 가정해 봅시다. 이 경우 다음과 같이 또 다른 flatMap 호출을 추가해주면 됩니다.
Mono<Ingredient> ingredient = WebClient.create()
.get()
.uri("http://localhost:8000/ingredients/{id}", ingredient)
.exchange()
.flatMap(cr -> {
if (cr.headers().header("X_UNAVAILABLE").contains("true")) {
return Mono.empty();
}
return Mono.just(cr);
})
.flatMap(cr -> cr.bodyToMono(Ingredient.class));flatMap의 if문을 통해 헤더값을 검사하고 true면 빈값을, 아니면 새로운 Mono를 반환합니다. 어떤 경우이든 반환되는 Mono는 그 다음의 flatMap이 처리할 Mono가 됩니다.
리액티브 웹 API 보안
이제까지 스프링 시큐리티의 웹 보안 모델은 서블릿 필터를 중심으로 만들어졌습니다. 만일 요청자가 올바른 권한을 갖고 있는지 확인하기 위해 서블릿 기반 웹 프레임워크의 요청 바운드를 가로채야 한다면 서블릿 필터가 확실한 선택입니다. 그러나 WebFlux는 이런 방법이 곤란합니다.
MVC와 WebFlux의 차이점을 먼저 봅시다.
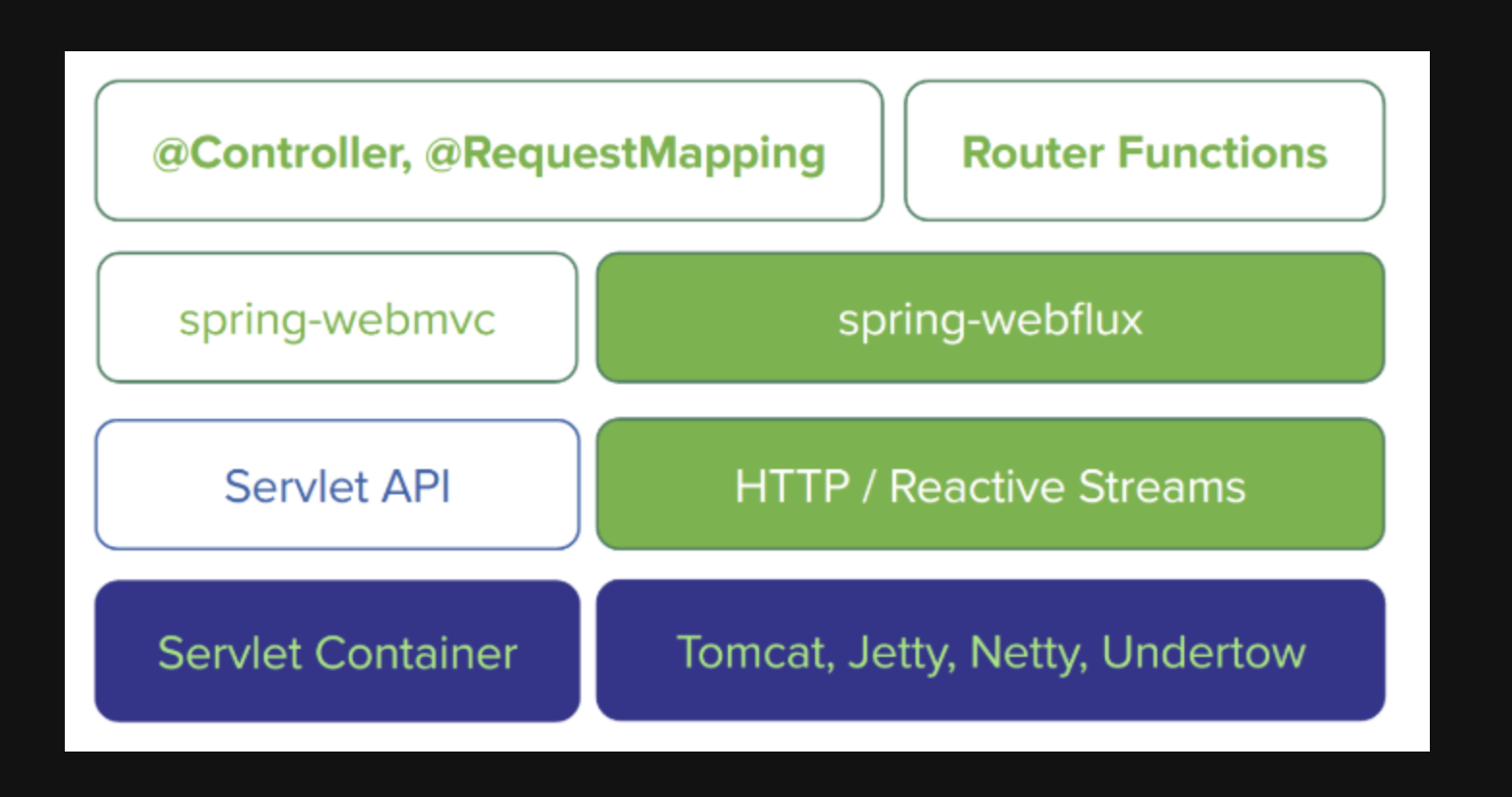
왼쪽이 스프링 MVC에 해당하고 오른쪽이 WebFlux입니다.
스프링 MVC는 실행 시 톰캣과 같은 서블릿 컨테이너가 필요한 자바 서블릿 API의 상위 계층에 위치합니다. WebFlux는 서블릿 API와 연계되지 않습니다. 따라서 서블릿 API가 제공하는 것과 동일한 기능의 리액티브 버전인 리액티브 HTTP API의 상위 계층에 위치합니다. 그리고 스프링 WebFlux는 서블릿 API에 연결되지 않으므로 실행하기 위해 서블릿 컨테이너를 필요로 하지 않습니다. 대신에 블로킹이 없는 어떤 웹 컨테이너에서도 실행될 수 있으며 이에는 Netty, Undertow, 톰캣, Jetty 또는 다른 서블릿 3.1 이상의 컨테이너가 포함됩니다.
즉, WebFlux로 웹 애플리케이션을 작성할 때는 서블릿이 개입된다는 보장이 없습니다. 스프링 WebFlux 애플리케이션의 보안에 서블릿 필터를 사용할 수 없는 것이 시실이나 5.0.0 버전부터 스프링 시큐리티는 서블릿 기반의 스프링 MVC와 리액티브 스프링 WebFlux 애플리케이션 모두의 보안에 사용될 수 있습니다. 스프링의 WebFliter가 이 일을 해줍니다. WebFilter는 서블릿 API에 의존하지 않는 스프링 특유의 서블릿 필터 같은 것입니다.
특이한 점은 기존 Spring 시큐리티와 크게 다르지 않다는 것입니다. 실제로 의존성도 따로 있는 것이 아니라 기존 스프링 시큐리티 의존성을 사용합니다. 그러나 구성 모델 간에서는 사소한 차이가 있습니다.
리액티브 웹 보안 구성하기
MVC에서 보안을 구성할 때는 webSecurityConfigurerAdapter의 서브 클래스로 새로운 클래스를 생성하여 @EnableWebSecurity 애노테이션을 지정합니다. 그리고 configuration 메서드를 재정의하여 요청 경로에 필요한 권한 등과 같은 웹 보안 명세를 지정합니다.
@Configuration
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.antMatchers("/design","/orders").hasAuthority("USER")
.antMatchers("/**").permitAll();
}
}이제 이것을 WebFlux 애플리키에션에서는 어떻게 하는지 알아봅시다.
@Configuration
@EnableWebFluxSecurity
public class SecurityConfig {
@Bean
public SecurityWebFilterChain securityWebFilterChain(ServerHttpSecurity http){
return http.authorizeExchange()
.pathMatchers("/design","/orders").hasAuthority("USER")
.anyExchange().permitAll()
.and()
.build();
}
}@EnableWebSecurity 대신 @EnableWebFluxSecurity 사용 합니다.
WebSecurityConfigurerAdapter 를 상속하지 않습니다.
SecurityWebFilterChain 반환 타입의 메서드가 mvc의 configure 메서드를 대신하고 빈으로 등록합니다.
인자로 전달된 ServerHttpSecurity를 사용해 authorizeExchange 메서드를 호출하는데 이는 authorizedRequests와 거의 같습니다. mvc에서 사용하는 HttpSecurity의 리액티브 버전이라고 보면 됩니다.
경로 일치의 경우 여전히 Ant 방식의 와일드카드 경로를 사용할 수 있지만, 메서드는 antMatchers 대신 pathMatchers를 사용합니다. 그리고 모든 경로를 의미하는 Ant 방식의 / 를 더 이상 지정할 필요가 없습니다. anyExchange() 메서드가 /를 반환하기 때문입니다.
마지막으로 SecurityWebFilterChain을 빈으로 선언하므로 반드시 build 메서드를 호출하여 모든 보안 규칙을 SecurityWebFilterChain으로 조립하고 반환해야 합니다.
리액티브 사용자 명세 서비스 구성하기
WebSecurityConfigurerAdapter의 서브 클래스로 구성 클래스를 작성할 때는 하나의 configure 메서드를 재정의하여 웹 보안 규칙을 선언하며, 또 다른 configure 메서드를 재정의하여 UserDetails 객체로 정의하는 인증 로직을 구성합니다.
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
auth
.userDetailsService(new userDetailsService(){
@Override
public UserDetails loadUserByUsername(String userName){
...
}
});
}리액티브가 아닌 구성에서는 UserDetailsService에서 필요한 loadUserByUsername() 메서드만 재정의합니다. 그리고 이 메서드 내부에서는 지정된 UserRepository를 사용해서 인자로 전달된 사용자 이름으로 사용자를 찾습니다. 만약 찾지 못하면 UsernameNotFoundException을 발생시킵니다. 그러나 찾으면 UserDetails 객체를 반환합니다.
반면에 리액티브 보안 구성에서는 configure 메서드를 재정의하지 않고 대신에 ReactiveUserDetailsService 빈을 선언합니다. 이것은 UserDetailsServie 리액티브 버전이며, 마찬가지로 하나의 메서드만 구현하면 됩니다. 특히 반환 타입이 리액티브 타입이고 리포지토리도 리액티브 스프링 데이터 리포지토리여야 한다는 것입니다.
@Service
public ReactiveUserDetailsService userDetailsService(UserRepository userRepo) {
return new RactiveUserDetailsService() {
@Override
public Mono<UserDetails> findByUsername(String username){
return userRepo.findByUsername(username){
.map(user -> {
return user.toUserDatils();
});
}
}
}
}리액티브 데이터 퍼시스턴스
컨트롤러는 같이 작동하는 다른 컴포넌트도 블로킹이 없어야 진정한 블로킹 없는 컨트롤러가 될 수 있습니다. 만일 블로킹 되는 리포지토리에 의존하는 스프링 WebFlux 리액티브 컨트롤러를 작성한다면, 이 컨트롤러는 해당 리포지토리의 데이터 생성을 기다리느라 블로킹 될 것입니다. 따라서 전체 flow가 리액티브하고 블로킹되지 않는 것이 중요합니다.
스프링 데이터 리액티브 개념 이해하기
스프링 데이터는 리액티브 리포지토리의 지원을 제공하기 시작했습니다. 여기에는 카산드라, 몽고DB, 카우치베이스, 레디스로 데이터를 저장할 때 리액티브 프로그래밍 모델을 지원하는 것이 포함됩니다. 그러나 관계형 DB나 JPA는 리액티브 리포지토리가 지원되지 않습니다. 관계형 DB는 업계에서 가장 많이 사용되지만, JPA로 리액티브 프로그래밍 모델을 지원하려면 관계형 DB와 JDBC 드라이버 역시 블로킹되지 않는 리액티브 모델을 지원해야 합니다. 하지만 아직까지는 관계형 DB를 리액티브하게 사용하기 위한 지원이 되지 않습니다.
스프링 데이터 리액티브 개요
리액티브 리포지토리는 도메인 타입이나 컬렉션 대신 Mono, Flux를 인자로 받거나 반환하는 메서드를 갖습니다.
Flux<Ingredient> findByType(Ingredient.Type type);
Flux<Taco> saveAll(Publisher<Taco> tacoPublisher)saveAll 메서드는 Taco 타입을 포함하는 Publisher인 Mono\, Flux\를 인자로 받으며, Flux\를 반환합니다.
간단히 말해, 리액티브가 아닌 리포지토리와 거의 동일한 프로그래밍 모델을 공유합니다. 단, 리액티브 리포지토리는 도메인 타입이나 컬렉션 대신 Mono, Flux 인자로 받거나 반환하는 메서드를 갖는 것만 다릅니다.
리액티브와 리액티브가 아닌 타입 간의 변화
리액티브 리포지토리를 작성하기 앞서 잠시 중요한 문제를 언급하고 넘어갑시다. 기존 관계형 DB가 있지만 스프링 데이터의 리액티브 프로그래밍 모델을 지원하는 4개의 데이터베이스 중 하나로 이전하는 것이 불가능할 것입니다. 이 경우 리액티브 프로그래밍을 현재 앱에는 전혀 적용할 수 없을까요?
리액티브 프로그래밍의 장점은 클라이언트로부터 데이터베이스까지 리액티브 모델을 가질 때 완전하게 발휘되나 데이터베이스가 리액티브가 아닌 경우에도 여전히 일부 장점을 살릴 수 있습니다. 심지어는 DB가 블로킹 없는 리액티브 타입을 지원하지 않더라도 블로킹 되는 방식으로 데이터를 가져와 가능한 빨리 리액티브 타입으로 변환하여 상위 컴포넌트들이 리액티브의 장점을 활용하게 할 수 있습니다.
예를 들어 관계형 DB에 JPA를 사용한다고 가정해봅시다.
List<Order> findByUser(User user);위 메서드는 호출되면 결과 데이터가 List에 저장되는데 이 처리를 하는 동안 블로킹됩니다. 왜냐하면 List가 리액티브 타입이 아니므로 리액티브 타입인 Flux가 제공하는 어떤 메서드도 수행할 수 없기 때문입니다. 게다라 컨트롤러에서 위 메서드를 호출하게 되면 결과를 리액티브하게 사용할 수 없어 확장성을 향상시킬 수 없습니다.
하지만 이 경우 가능한 빨리 리액티브가 아닌 List를 Flux로 변환하여 결과를 처리할 수는 있습니다. 이때는 Flux.fromIterable 메서드를 사용하면 됩니다.
List<Order> orders = repo.findByUser(user);
Flux<Order> orderFlux = Flux.fromIterable(orders);
// 주문 데이터를 가져와 변환
Order order = repo.findById(id);
Mono<Order> orderMono = Mono.just(order);이처럼 Mono.just 메서드와 Flux의 fromIterable, fromArray, fromStream 메서드를 사용하면 리포지토리의 리액티브가 아닌 블로킹 코드를 격리시키고 애플리케이션 어디서든 리액티브 타입으로 처리하게 할 수 있습니다.
만약 리액티브 타입을 사용하면서 JPA의 save를 호출해야 한다면 리액티브 타입은 모두 자신들이 발행하는 데이터를 도메인 타입이나 Iterable 타입으로 추출하는 메서드를 가지고 있기에 이를 사용하면 됩니다. 예를 들어 Mono\를 받아서 JPA에 저장하려고 한다면 block 메서드를 사용하여 도메인 객체를 추출해서 사용하면 됩니다.
Taco taco = TacoMono.block(); // 추출하기 위한 블로킹 메서드
tacoRepo.save(taco);
Iterable<Taco> tacos = tacoFlux.toIterable(); // iterable 타입으로 추출
tacoRepo.saveAll(tacos);그러나 두 메서드는 블로킹이 되므로 리액티브 프로그래밍 모델에서 벗어나므로 가급적 피하는 것이 좋습니다. 블로킹되는 추출 메서드를 피하는 더 리액티브한 방식이 있는데 리액티브 타입을 구독하면서 발행되는 요소 각각에 대해 원하는 메서드를 수행하는 것입니다. 예를 들어 Flux\가 발행하는 Taco 객체를 리액티브가 아닌 리포지토리에 저장할 때는 다음과 같이 할 수 있습니다.
tacoFlux.subscribe(taco -> {
tacoRepo.save(taco);
})위 코드도 역시 save가 블로킹 메서드이긴 하지만 리액티브 타입이 발행하는 데이터를 소비하고 처리하는 리액티브 방식의 subscribe 메서드를 사용하므로 블로킹 방식의 일괄 처리보다는 더 바람직합니다.
리액티브 카산드라
카산드라는 분산처리, 고성능, 상시 가용, 궁극적인 일관성을 갖는 NoSQL입니다.
카산드라는 데이터를 테이블에 저장된 행으로 처리하며, 각 행은 일대다 관계의 많은 분산 노드에 걸쳐 분할됩니다. 즉, 한 노드가 모든 데이터를 갖지는 않지만, 특정 행은 다수의 노드에 걸쳐 복제될 수 있으므로 한 노드에 문제가 생기면 전체가 사용 불가능한 문제(단일 장애점)를 없애줍니다.
스프링 데이터 카산드라는 카산드라 DB의 자동화된 리포지토리 지원을 제공하며, 도메인 타입을 DB구조에 매핑하는 애노테이션도 제공합니다. 카산드라를 살펴보기 전에 중요한 것이 있는데 카산드라는 오라클이나 SQL Server와 같은 관계형 DB와 유사한 많은 개념들을 공유하지만, 카산드라는 관계형 DB가 아니며, 여러 면에서 매우 다릅니다. 자세한 내용은 공식 문서를 참고하세요.
스프링 데이터 카산드라 활성화
// 기본 버전
implementation 'org.springframework.boot:spring-boot-starter-data-cassandra'
// 리액티브 버전
implementation 'org.springframework.boot:spring-boot-starter-data-cassandra-reactive'리액티브 버전의 의존성을 추가해줍니다. 대부분 구성이 자동으로 이뤄지지만 일부 구성이 필요합니다. 최소한 리포지토리가 운용되는 키 공간의 이름을 구성해야 하며, 이렇게 하기 위해 해당 키 공간을 생성해야 합니다. 키 공간을 자동으로 생성하도록 스프링 데이터 카산드라를 구성할 수 있지만 직접 구성하는 것이 훨씬 쉽습니다. 카산드라 CQL 셸에서 다음과 같이 create keyspace 명령을 사용하면 키 공간을 생성할 수 있습니다.
create keyspace tacocloud
... with replication={'class':'SimpleStrategy', 'replication_factor':1}
... and durable_writes=true;여기서는 단순 복제 및 durable_write가 true로 설정된 tacocloud라는 키 공간을 생성합니다. replication_factor가 1일 때는 각 행의 데이터를 여러 벌 복제하지 않고 한 벌만 유지함을 나타냅니다. 복제를 처리하는 방법은 복제 전략이 결정하며, 여기서는 SimpleStrategy를 지정했습니다. SimpleStrategy 복제 전략은 단일 데이터 센터 사용 시에 데모용 코드에 좋습니다. 그러나 카산드라 클러스터가 다수의 데이터 센터에 확산되어 있을 때는 NetworkTopologyStrategy를 고려할 수 있습니다.
키 공간을 생성했으므로 속성을 구성해줍니다.
spring:
data:
cassandra:
keyspace-name: tacocloud
schema-action: recreate-drop-unused schema-action에 작성한 옵션은 매번 시작할 때마다 지우고 재생성하는 옵션으로 기본값은 none으로 아무것도 하지 않습니다.
기본적으로 스프링 데이터 카산드라는 카산드라가 로컬에서 9092 포트를 리스닝하는 것으로 간주합니다. 만약 수정하고 싶다면 다음과 같이 설정합니다.
spring:
data:
cassandra:
keyspace-name: tacocloud
contact-points:
- casshost-1.tacocloud.com
- casshost-2.tacocloud.com
- casshost-3.tacocloud.com
port: 9043
username: ...
password: ...contact-points는 실행 중인 호스트를 카산드라 노드를 나타앱니다. 각 노드에 연결을 시도하여 카산드라 클러스터에 단일 장애점이 생기지 않게 해주며, contact-points에 지정된 호스트 중 하나를 통해 클러스터에 연결될 수 있게 해줍니다.
카산드라 데이터 모델링
카산드라 데이터 모델링은 관계형 DB 모델링과 다른 부분이 많습니다.
-
카산드라 테이블은 얼마든지 많은 열을 가질 수 있습니다.
-
그러나 모든 행이 같은 열을 갖지 않고, 행마다 서로 다른 열을 가질 수 있습니다.
-
카산드라 DB는 다수의 파티션에 걸쳐 분할되며 테이블의 어떤 행도 하나 이상의 파티션에서 관리될 수 있습니다.
-
그러나 각 파티션은 모든 행을 갖지 않고, 서로 다른 행을 가질 수 있습니다.
-
카산드라 테이블은 두 종류의 키를 갖습니다.
1) 파티션 키 : 각 행이 유지 관리되는 파티션을 결정하기 위해 해시 오퍼레이션이 각 행의 파티션 키에 수행됩니다.
2) 클러스터 키 : 각 행이 파티션 내부에서 유지 관뢰되는 순서를 결정합니다.
카산드라는 읽기 오퍼레이션에 최적화되어 있습니다. 따라서 테이블이 비정규화되고 데이터가 다수의 테이블에 걸쳐 중복되는 경우가 흔합니다. 예를 들어, 고객 정보는 고객 테이블에 저장되지만, 각 고객의 주문 정보를 포함하는 테이블에도 중복 저장될 수 있습니다.
카산드라 도메인 타입 매핑
@Getter
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Table("ingredients")
public class Ingredient {
@PrimaryKey
private String id;
private String name;
private Type type;
public static enum Type {
WRAP, PROTEIN, CHEESE, SAUCE
}
}
@Getter
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Table("tacos") // Table 매핑
public class Tacos {
@PrimaryKeyColumn(type= PrimaryKeyType.PARTITIONED) // 파이션 키
private UUID id = UUIDs.timeBased(); // 시간 기반 UUID
@PrimaryKeyColumn(type = PrimaryKeyType.CLUSTERED, // 클러스터링 키
ordering = Ordering.DESCENDING)
private Date createdAt = new Date();
@Column("ingredients") // List를 ingredients 열에 매핑
private List<IngredientUDT> ingredientUDTList;
}id값이 카산드라 파티션을 결정하기 위해 사용되는 파티션 키이고, createdAt이 파티션 내부에서 행의 순서를 결정하기 위해 사용되는 파티션 키입니다. ingredientUDTList는 List로 정의되어 있는데 카산드라 테이블은 비정규화되어서 다른 테이블과 중복되는 데이터를 포함할 수 있습니다. 따라서 모든 사용 가능한 식재료 데이터를 갖는 테이블은 ingredients이지만 각 타코에 섡택된 식재료는 여기 있는 tacos 테이블의 ingredients 열에 중복 저장될 수 있습니다. 그리고 ingredients 테이블의 하나 이상의 행을 참조하는 대신, ingredients 속성은 선택된 각 식재료의 전체 데이터를 포함합니다.
그런데 왜 그냥 Ingredient 클래스를 사용하지 않고 IngredientUDT 클래스를 사용할까요? 간단히 말해, ingredients 열처럼 데이터의 컬렉션을 포함하는 열은 네이티브 타입(정수, 문자열 등)의 컬렉션이거나 사용자 정의 타입(UDT)의 컬렉션이어야 하기 때문입니다.
카산드라에서 사용자 정의 타입은 단순한 네이티브 타입보다 더 다채로운 테이블 열을 선언할 수 있게 해줍니다. 그리고 비정규화된 관계형 DB 외래키처럼 사용됩니다. 단, 다른 테이블의 한 행에 대한 참조만 갖는 외래키와는 대조적으로, 사용자 정의 타입의 열은 다른 테이블의 한 행으로부터 복사될 수 있는 데이터를 실제로 갖습니다. 즉, tacos 테이블의 ingrediends 열은 식재료 자체를 정의하는 클래스 인스턴스의 컬렉션을 포함하는 것입니다.
Ingredient 클래스를 사용자 정의 타입으로 사용할 수 없는 이유는 @Table 애노테이션이 이미 Ingredient 클래스를 카산드라에 저장하는 엔티티(도메인 타입)으로 매핑했기 때문입니다. 따라서 taco 테이블의 ingredients 열에 식재료 데이터가 어떻게 저장되는지 정의하기 위해 새로운 클래스를 생성해야 합니다.
@Data
@RequiredArgsConstructor
@NoArgsConstructor(access = AccessLevel.PRIVATE, force = true)
@UserDefinedType("ingredient")
public class IngredientUDT {
private final String name;
private final Ingredient.Type type;
}카산드라의 사용자 정의 타입임을 알리는 @UserDefinedType 애노테이션을 붙여줍니다. UDT 클래스는 id속성을 포함하지 않습니다. 소스 클래스인 Ingredient의 id속성을 가질 필요가 없기 때문입니다.
관계형 DB처럼 다른 테이블의 행들을 외래키로 조인하지 않고 해당 테이블에 직접 포함시키는데 이는 빠른 데이터 검색에 테이블을 최적화하기 위함입니다.
리액티브 카산드라 리포지토리 작성하기
스프링 데이터의 기본 리포지토리 인터페이스 중 하나를 확장했던 것처럼 리액티브 리포지토리도 크게 다르지 않습니다. 다른점이 있다면 리액티브 타입을 사용한다는 것입니다. 리액티브 카산드라 리포지토리를 작성할 때는 두 개의 기본 인터페이스인 Reactive CassandraRepository나 ReactiveCrudRepository를 선택할 수 있습니다. ReactiveCassandraRepository는 ReactiveCrudRepository를 확장하여 새 객체가 저장될 때 사용되는 insert 메서드의 몇 가지 변형 버전을 제공하며 이외에는 동일합니다. 따라서, 많은 데이터를 추가한다면 ReactiveCassandraRepository를, 그렇지 않다면 ReactiveCrudRepository를 선택하는 것이 좋습니다.
// 기본
public interface IngredientRepository extends ReactiveCrudRepository<Ingredient, String> {}
// 커스텀
public interface UserRepository extends extends ReactiveCrudRepository<User, UUID> {
@AllowFiltering
Mono<User> findByUsername(String username);
}카산드라의 특성상 관계형 DB에서 SQL로 하듯이 테이블을 단순하게 where절로 쿼리할 수 없습니다. 카산드라는 데이터 읽기에 최적화되어있습니다. 그러나 where 절을 사용한 필터링 결과는 빠른 쿼리와는 달리 느리게 처리될 수 있습니다. 그렇지만 결과가 하나 이상의 열로 필터링되는 테이블 쿼리에는 매우 유용하므로 where 절을 사용할 필요가 있습니다. 이때 @AllFiltering 애노테이션을 사용합니다.
@AllowFiltering 애노테이션을 작성하지 않은 경우 내부적으로 다음과 같이 동작할 것이라고 예상할 수 있습니다.
select * from users where username='사용자이름';하지만 앞서 말했듯이 단순한 where절은 카산드라에서 허용되지 않습니다. 따라서 @AllowFiltering 애노테이션을 붙여야만 다음과 같이 내부적으로 수행되게 할 수 있습니다.
select * from users where username='사용자이름' allow filtering;쿼리 끝에 allow filtering은 성능에 영향을 준다는 것을 알고 있지만 어쨌든 수행해야 한다는 것을 카산드라에게 알려줍니다.
리액티브 몽고 DB
몽고DB도 NoSQL로 카산드라가 테이블의 행으로 데이터를 저장하는 NoSQL인 반면, 몽고 DB는 문서형 DB입니다. 몽고 DB는 BSON(binary JSON)형식의 문서로 데이터를 저장하며, 다른 DB에서 데이터를 쿼리하는 것과 거의 유사한 방법으로 문서를 쿼리하거나 검색할 수 있습니다.
스프링 데이터 몽고DB 활성화
// 기본 버전
implementation 'org.springframework.boot:spring-boot-starter-data-mongodb'
// 리액티브 버전
implementation 'org.springframework.boot:spring-boot-starter-data-mongodb-reactive'
// 내장 몽고 DB
implementation 'de.flapdoodle.embed:de.flapdoodle.embed.mongo:3.4.5'기본적으로 스프링 데이터 몽고DB는 27017 포트를 리스닝하는 것으로 간주됩니다. 그러나 위의 내장 몽고 DB의존성을 추가하면 인메모리 몽고 DB를 사용하는 것과 동일한 편의성(H2같은) 기능을 제공합니다.
spring:
data:
mongodb:
host: localhost
port: 27017
database: test
# 버전이 올라가면서 embedded 버전을 명시해줘야하게 되었다.
mongodb:
embedded:
version: 3.4.5- host : 실행 중인 호스트 이름, 기본값은 localhost
- port : 리스닝 포트
- username : 이름
- password : 패스워드
- database : 데이터베이스 이름으로 기본값은 test
host, port, database 옵션은 작성하지 않아도 알아서 세팅되서 동작합니다. 특히, 테스트에서는 옵션을 명시하게 되면 충돌이 발생할 수 있으므로 적지 않는게 낫습니다.
도메인 타입 문서로 매핑하기
- @Id : 문서 Id
- @Document : 도메인 타입을 몽고 DB에 저장되는 문서 엔티티로 선언
- @Field : 몽고DB의 문서에 속성을 저장하기 위해 필드 이름을 지정
지정하지 않으면 필드 이름과 속성 이름을 같은 것으로 간주
@Getter
@NoArgsConstructor
@Document
public class Ingredient {
@Id
private String id;
private String name;
private Type type;
public static enum Type {
WRAP, PROTEIN, CHEESE, SAUCE
}
}기본적으로 컬렉션(관계형 DB의 테이블과 유사)이름은 클래스 이름과 같고 첫 자만 소문자로 저장됩니다. 여기서는 지정하지 않았으므로 켈렉션 이름은 ingredient로 저장됩니다. 아래와 같이 사용하면 변경할 수 있습니다.
@Document(Collection="ingredients")@Id를 통해 문서의 ID값을 지정하게 되는데 String과 Long 타입을 포함해서 Serializable 타입인 어떤 속성에도 @Id를 사용할 수 있습니다.
@Getter
@NoArgsConstructor
@Document
public class Taco {
@Id
private String id;
private String name;
private Date createdAt = new Date();
private List<Ingredient> ingredients;
}카산드라와 다르게 몽고 DB의 경우 매핑이 훨씬 간단합니다. id값이 String으로 바뀐점을 주의해야하는데 몽고 DB의 경우 id값을 String 타입으로 사용할 경우 null로 들어가게 되면 자동으로 값을 지정해줍니다.
Ingredients의 경우 카산드라와 유사하게 비정규화된 상태로 저장되나 카산드라처럼 따로 타입을 만들어줄 필요없이 어떤 타입도 사용할 수 있습니다. @Document가 지정된 타입 또는 다른 타입이나 단순한 POJO도 모두 가능합니다.
리액티브 몽고DB 리토지토리 인터페이스
카산드라와 마찬가지로 ReactiveCrudRepository, ReactiveMongoRepository 중 선택할 수 있습니다. ReactiveCrudRepository는 새로운 문서나 기존 문서의 save 메서드에 의존하는 반면, ReactiveMongoRepository는 새로운 문서의 저장에 최적화된 소수의 특별한 insert 메서드를 지원합니다.
Ingredient 객체를 문서로 저장하는 리포지토리를 정의하는 것부터 시작해봅시다. 식재료를 저장한 문서는 초기에만 식재료 데이터를 데이터베이스에 추가할 때 생성되며 이외에는 거의 추가되지 않습니다. 따라서 새로운 문서의 저장에 최적화된 ReactiveMongoRepository는 유용하지 않으므로 ReactiveCrudRepository를 사용합니다.
public interface IngredientRepository extends ReactiveCrudRepository<Ingredient, String>{}반면에 Taco 문서는 자주 생성할 여지가 있기때문에 ReactiveMongoRepository의 최적화된 insert 메서드가 유용할 수 있습니다.
public interface TacoRepository extends ReactiveMongoRepository<Taco, String> {
Flux<Taco> findByOrderByCreatedAtDesc();
}RactiveMongoRepository를 사용할 때 유일한 단점은 Mongo에 특화되어있기에 나중에 DB를 전환하게 된다면 사용할 수 없게 된다는 점입니다. 따라서 신중하게 사용하게 하고 나중에 DB를 전환하지 않을 것이라면 선택하는 것이 좋은 선택이 될 수 있습니다.
새로운 메서드는 커스텀 쿼리 메서드의 명명 규칙에 따르게 작성한 것인데 Taco객체를 찾은 후 createdAt 속성의 값을 기준 내림차순으로 결과를 정렬하라는 것을 의마합니다. 반환값은 Flux이므로 페이징에 대해서 신경쓰지 않아도 되고 대신에 take 메서드를 적용하여 발행되는 개수를 조절할 수 있습니다.
Flux<Taco> recents = repo.findByOrderByCreatedAtDesc().take(12);정리
-
스프링 데이터는 카산드라, 몽고DB, 카우치베이스, 레디스 DB의 리액티브 리포지토리를 지원한다.
-
스프링 데이터 리액티브 리포지토리는 리액티브가 아닌 기존 리포티조티롸 동일한 프로그래밍 모델을 따르지만 반환 타입은 리액티브 타입을 사용한다.
-
JPA 리포지토리와 같은 리액티브가 아닌 리포지토리는 리액티브 타입을 사용하도록 조정할 수 있다. 그러나 데이터를 가져오거나 저장할 때 여전히 블로킹이 생긴다.
참조
https://velog.io/@backtony/Spring-Reactor-%EA%B0%9C%EC%9A%94#get
