1. 프로젝트 개요
1.1 개요
- 프로젝트 주제
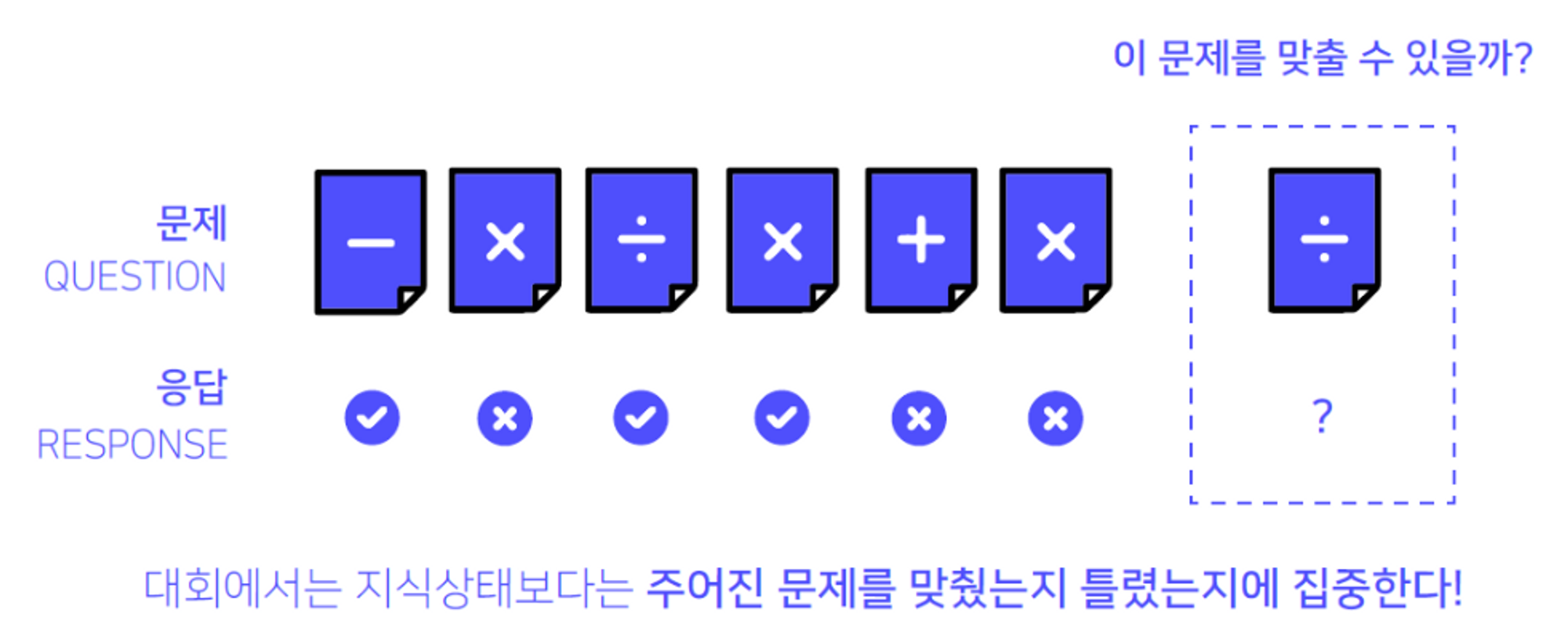
DKT는 Deep Knowledge Tracing의 약자로 “지식 상태”를 추적하는 딥러닝 방법론임. 이번 DKT대회에서는 학생들의 과거 문제 풀이 리스트와 정답여부가 담긴 Iscream 데이터셋을 이용하여 최종 문제를 맞출지 틀릴지 예측하는 것이 목표
1.2 환경
- (팀 구성 및 컴퓨터 환경) 5인 1팀, 인당 V100 서버를 할당받아 주피터랩과 VSCODE에서 사용
- (협업 환경) Notion, Github, WandB
- (의사소통) 카카오톡, ZOOM, Slack, gather town
2.프로젝트 팀 구성 및 역할
| 전체 | 문제정의, 계획 수립, 목표 설정, EDA, 모델 실험, 튜닝 |
|---|---|
| 김동환 | 모델링 및 데이터파이프라인 구성 |
| 김영서 | Bert, lstm 구현 및 실험 |
| 박재성 | LGBM, XGBoost 구현, Feature Engineering, Ensemble |
| 진성호 | LastQeury 구현, Hyperparameter Tuning 기초 구현, Git 관리 |
| 전예원 | TabNet, CatBoost 구현 및 실험 |
3 프로젝트 수행 절차 및 방법
3.1 팀 목표 설정
- wandb, Github와 같은 실험 및 협업 툴 사용해보기
- Baseline 이외의 모델 각자 선정해서 깊게 분석해보기
- 원활한 소통을 통해 서로 많이 배우고 성장하기
3.2 프로젝트 수행 절차
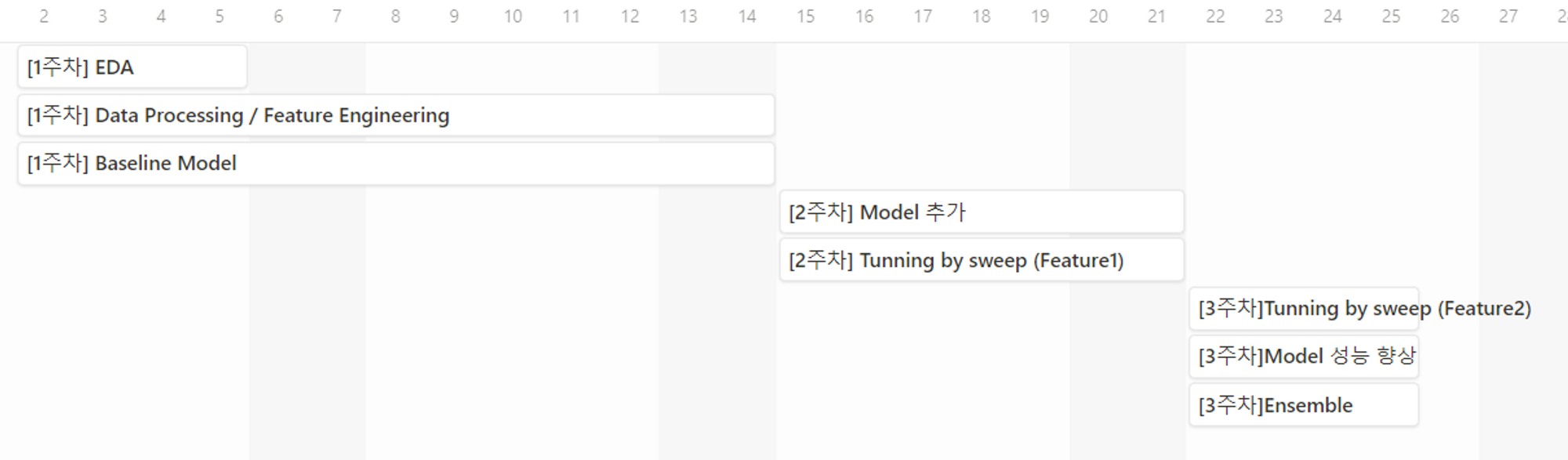
- 타임라인
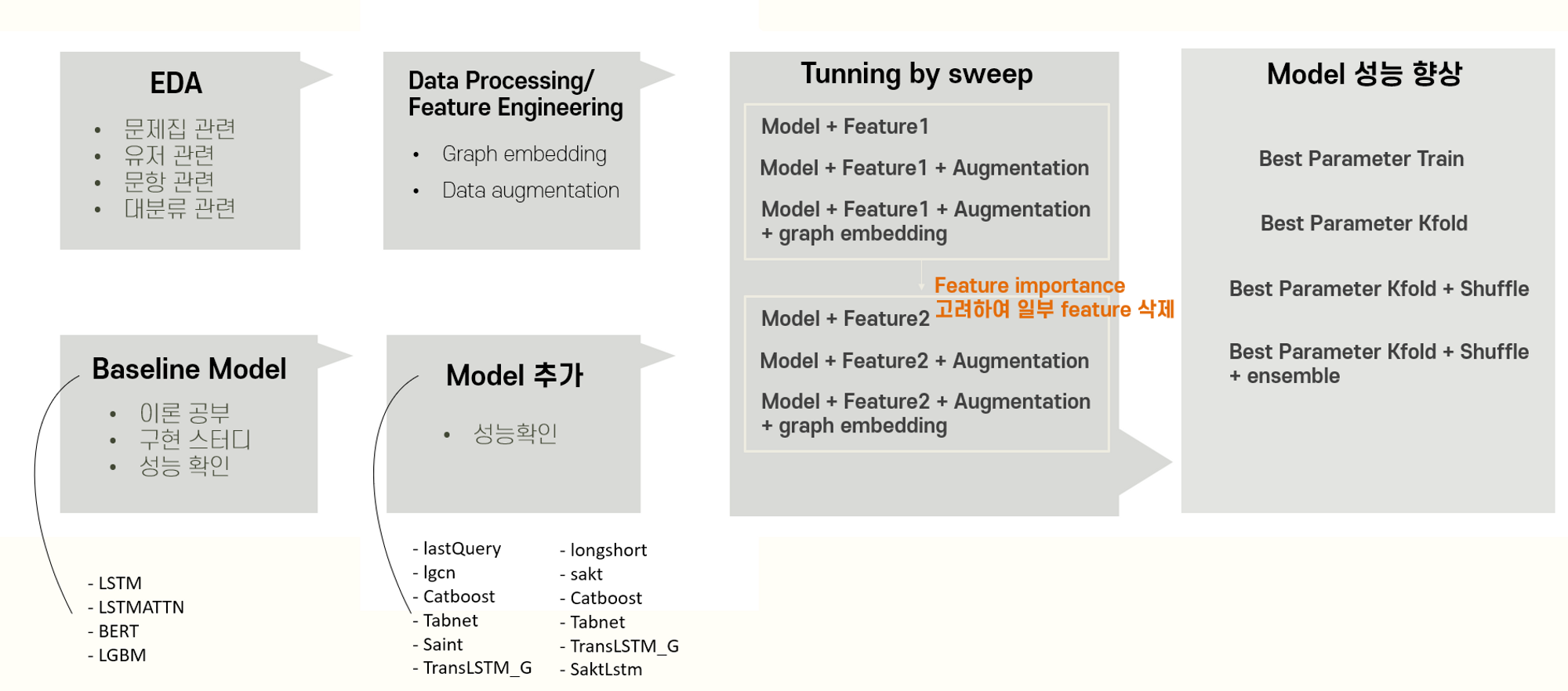
- 프로젝트 프로세스
3.3 협업 문화
-
Github
-
Branch 기능
- main : 배포될 branch. 문제가 없어야 하며, 충분한 검증을 통해 안정적이어야만 하는 branch
- develop : 새로 개발된 기능들을 기존 코드와 붙여 검증을 진행하는 branch. 충분한 검증이 완료되어 안정적이다 생각되면 main branch 로 merge.
- 개인 branch : 팀원 각자 새로 개발하는 기능들을 넣어 테스트하고, develop 으로 pull request 요청을 할 branch
-
Pull Request(PR)
- 개인 branch에서 작업한 내용을 develop에 push하기 전 PR을 열어 검토
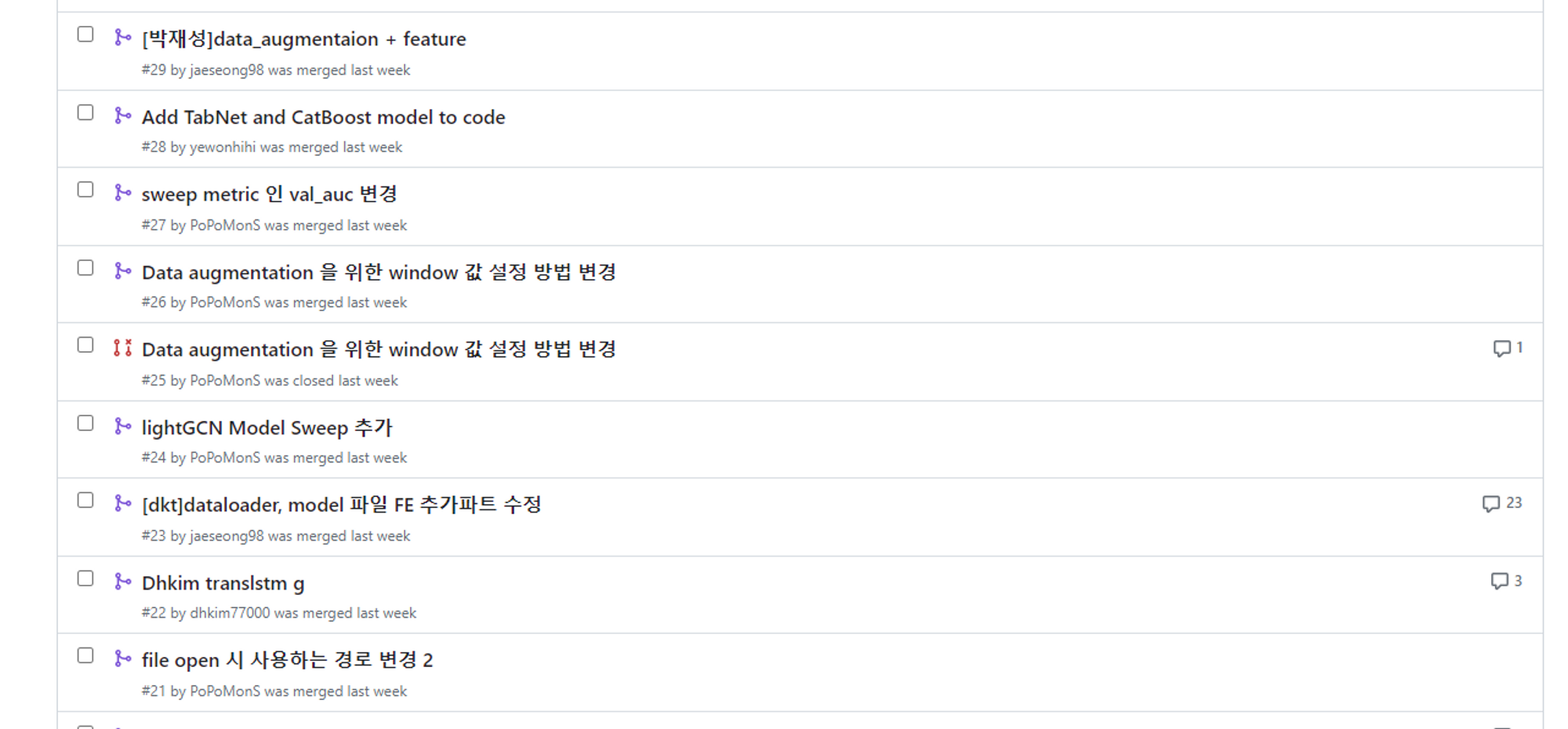
- 개인 branch에서 작업한 내용을 develop에 push하기 전 PR을 열어 검토
-
Slack으로 이슈 공유
- Github와 Slack 알림을 연동하여 PR, Push 등 변경사항을 확인
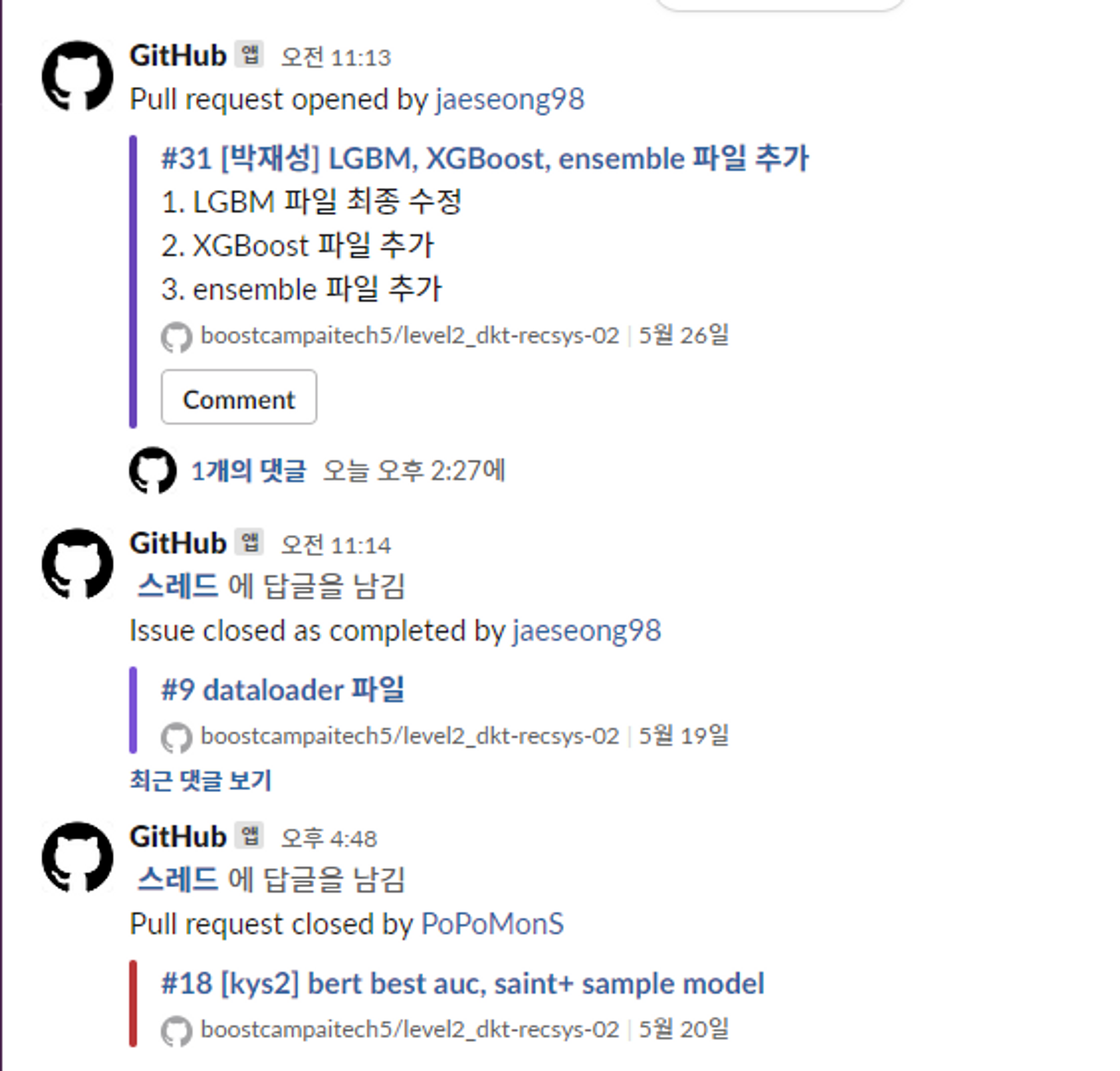
- Github와 Slack 알림을 연동하여 PR, Push 등 변경사항을 확인
-
- Notion
- 프로젝트 진행 상황 실시간 공유
- 프로젝트 진행 상황 실시간 공유
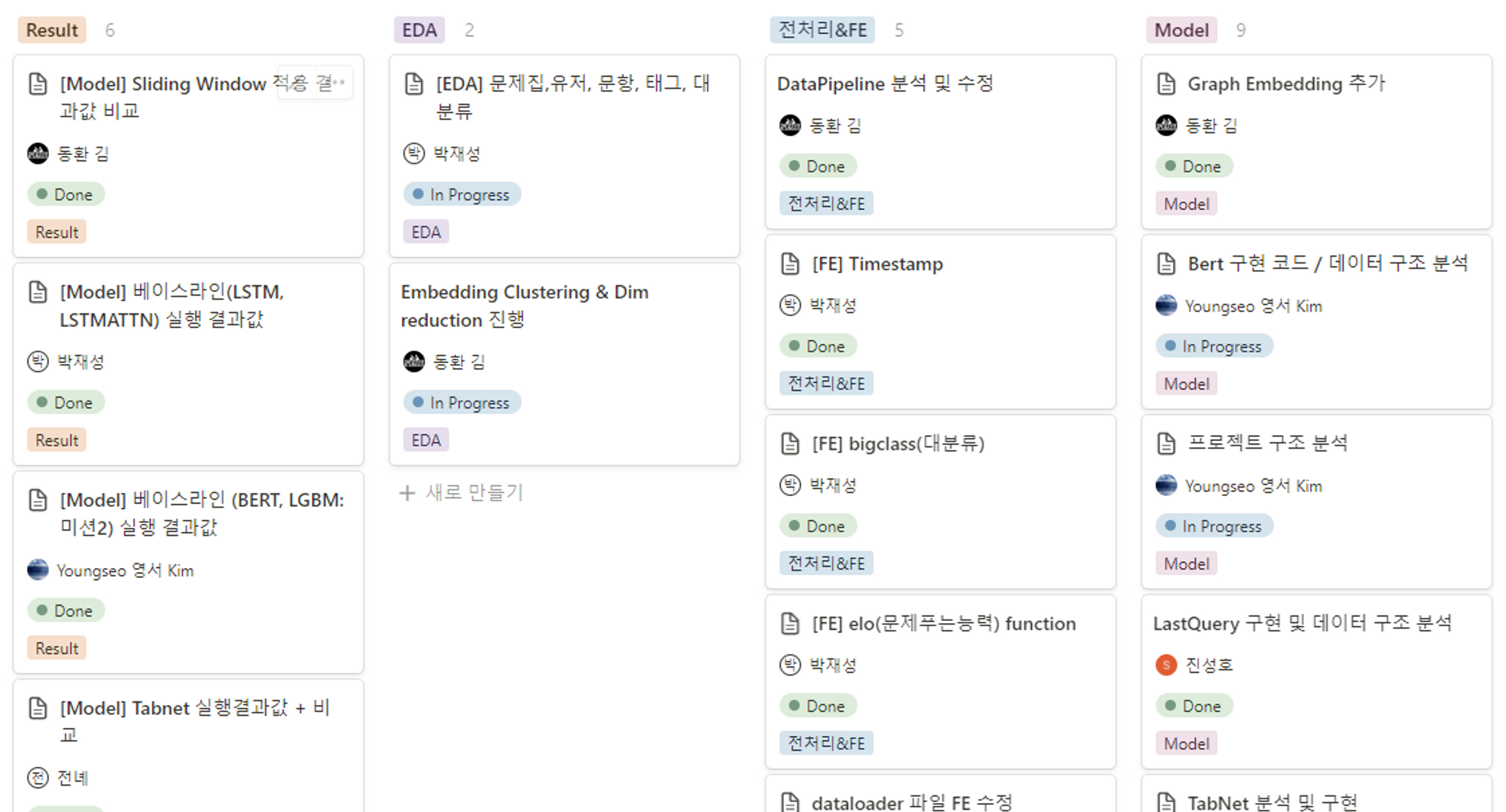
-
WandB
-
실험 결과 시각적으로 공유
-
Sweep으로 hyper parameter 자동 튜닝
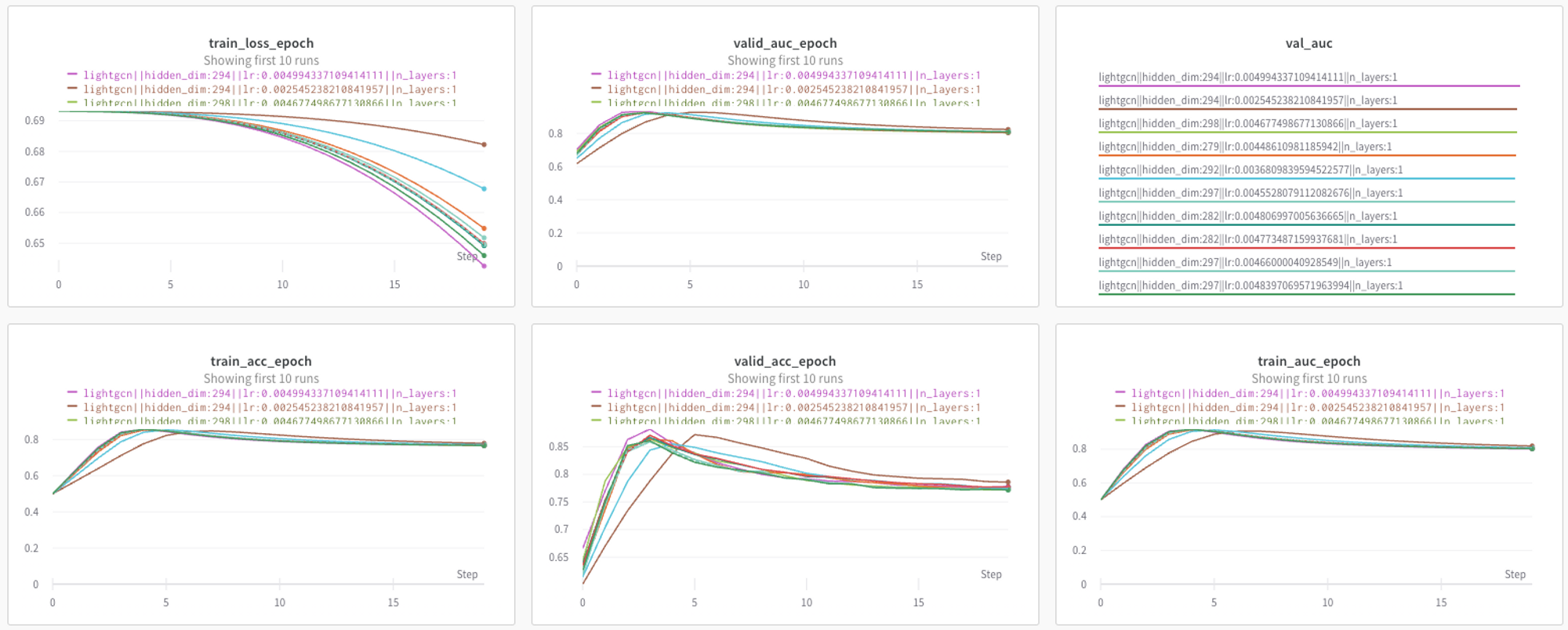
실험했던 여러 모델 중 하나
-
-
Offline Meeting
- 대회 후반부, 빠른 의견교환 및 효율성 향상을 위해 Offline Meeting 을 진행
4 프로젝트 수행 결과
4.1 탐색적 분석 및 전처리
- 데이터 소개
train/test 합쳐서 총 7,442명의 사용자가 존재함. 한 행은 한 사용자가 한 문항을 풀었을 때의 정보와 그 문항을 맞췄는지에 대한 정보가 담겨있음. 데이터는 모두 Timestamp 기준으로 정렬되어 있으며 이 때 사용자가 푼 마지막 문항의 정답을 맞출 것인지 예측하는 것이 최종목표
userID 사용자의 고유번호
assesmentItemID 문항의 고유번호
testId 시험지의 고유번호
answerCode 사용자의 해당 문항 정답 여부에 대한 이진데이터
Timestamp 사용자가 해당문항을 풀기 시작한 시점의 데이터
Knowledge 문항 당 하나씩 배정되는 태그
- EDA
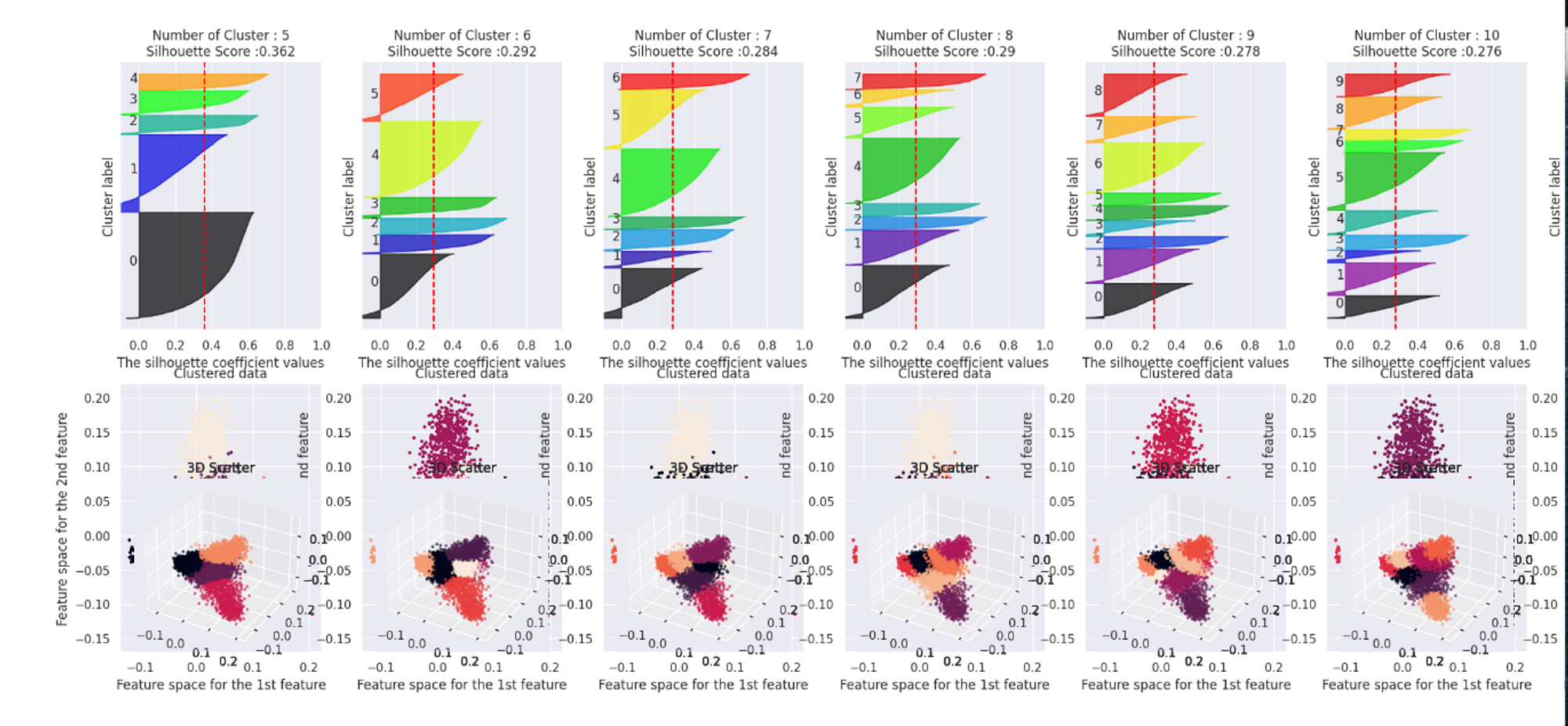
- LGCN으로 학습된 Embedding vector를 차원 축소와 클러스터링을 통해 분석
- 문항이 꽤 유의미하게 나뉘고 앞에 3번호에 따라서 나뉘는 것을 확인
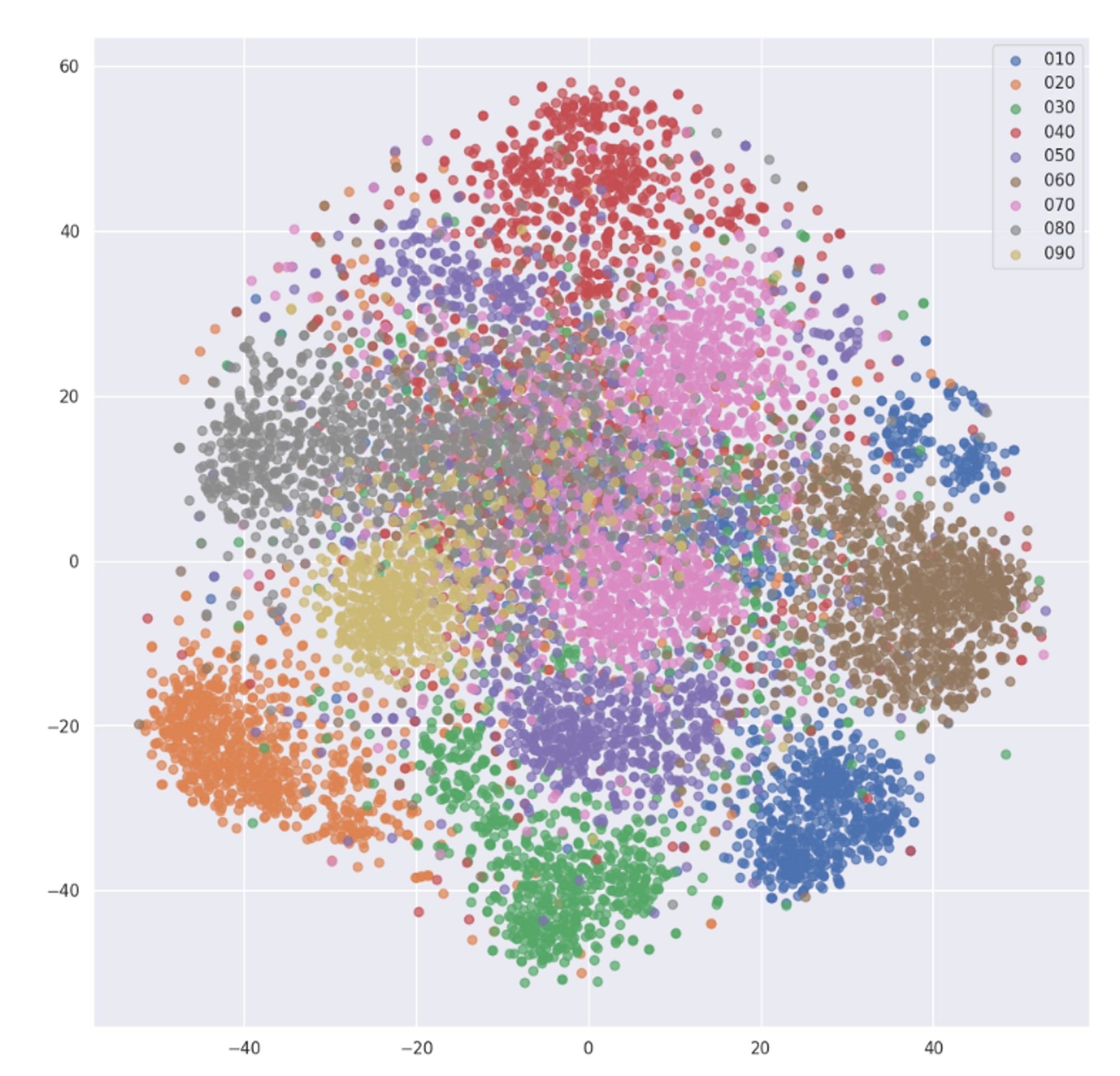
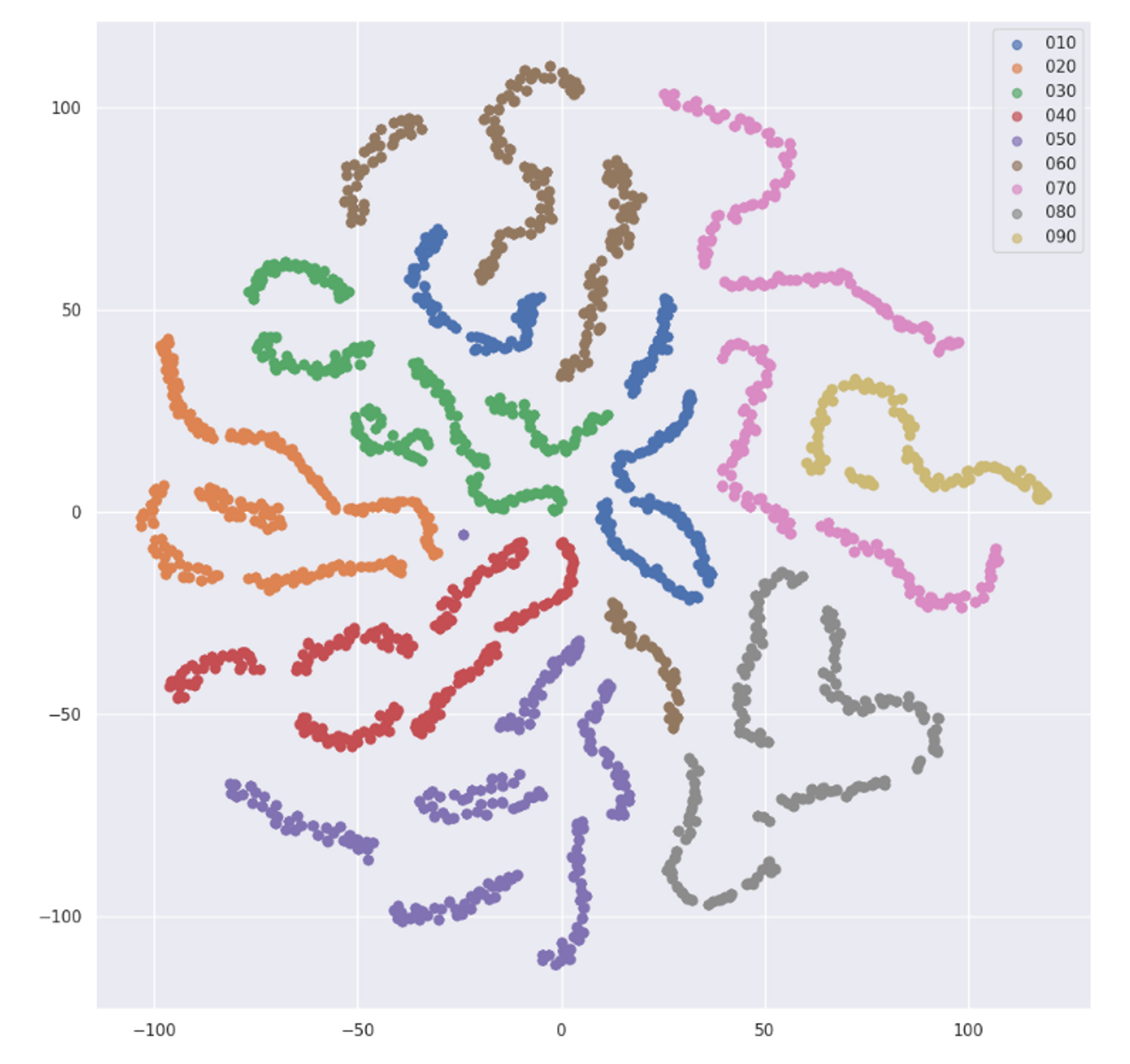
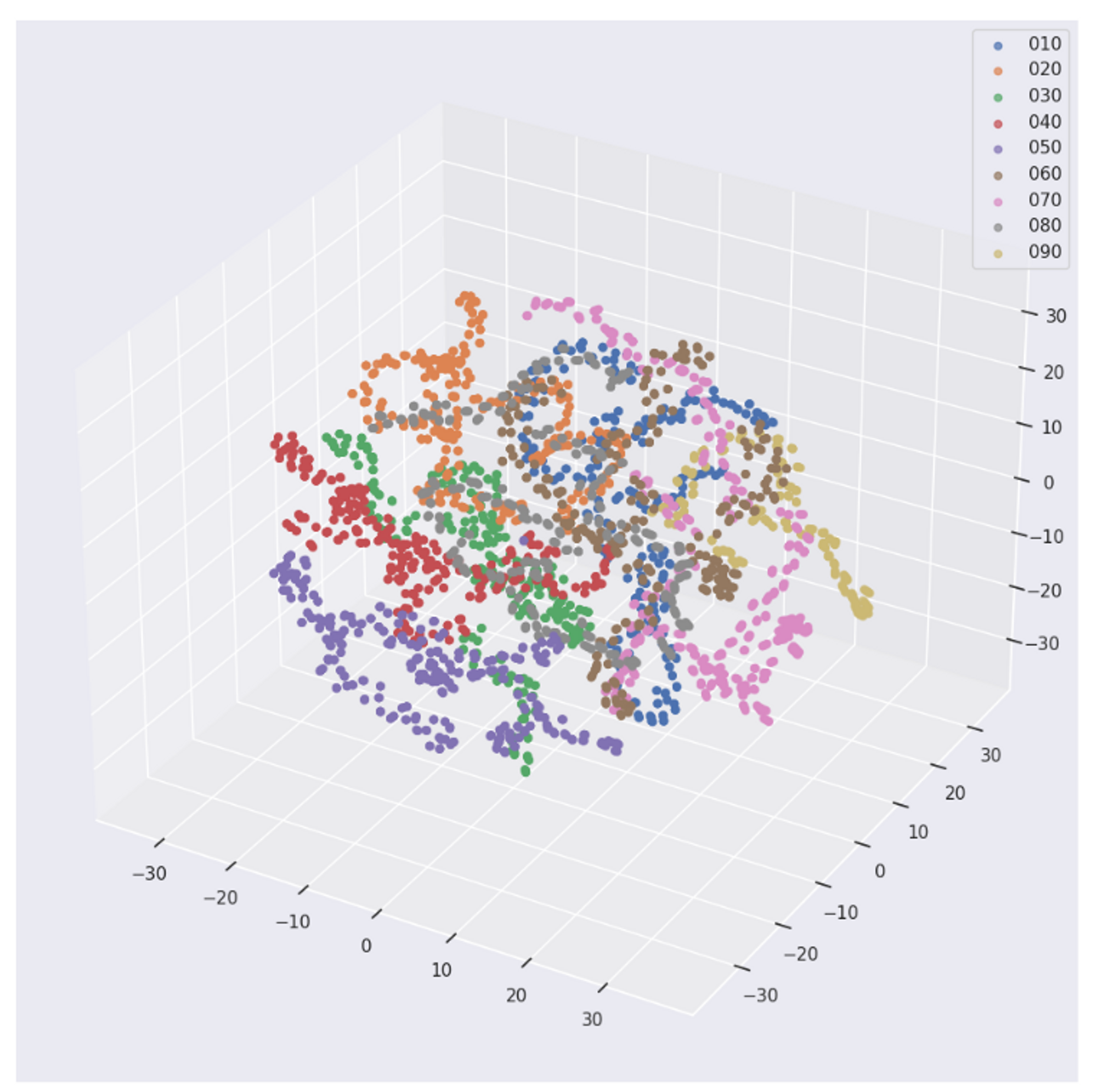
- Word2vec으로 학습된 Embedding Vector를 차원 축소와 클러스터링을 통해 분석
- LGCN와 다른 양상으로 나뉘었고 마찬가지로 앞에 3번호에 따라서 나뉘는 것을 확인 및 순서 정보가 반영된 embedding이 훨씬 효과적인 것도 확인
4.2 Feature Engineering
- Data Augmentation & Shuffling
- Stride를 두어서 max sequence length를 벗어난 데이터도 학습 데이터로 활용할 수 있도록 구현
- Shuffling으로 데이터의 마지막 순서만 제외하고 뒤섞어 데이터셋의 양을 늘리고 sequence에 대한 dependency도 학습이 될 수 있도록 구현
- 파생변수
기본 주어진 피쳐를 메모리 기법을 이용하여 6개의 피쳐에서 21개의 피쳐로 증가시킴. 메모리 기법이란 주어진 데이터 이전/이후 데이터들을 포함하는 메모리를 feature로 포함시킴으로서 순서 모델(Sequence Model)를 사용하지 않고 일반적인 지도 학습 모델(ex: Light GBM)을 사용하여 훈련할 수 있음
| Base | userID, assesmentItemID, testId, Timestamp, Knowledge, answerCode |
|---|---|
| Category | question_N, bigclass, dayname |
| Numeric | user_correct_acc, user_total_answer, user_acc, test_mean, test_sum, tag_mean, tag_sum, |
| Bigclass | bigclass, bigclasstime, bigclass_acc, bigclass_sum, bigclass_count |
| Time | elapsed, elapsed_cumsum,elapsed_med, month, day, hour, dayname |
| etc | elo |
4.3 모델링
-
모델 개요
Sequence Model
-
TransLSTM
- Transformer로 Feature들의 특성을 파악 후 이를 다시 한 번 LSTM에 넣어주어서 output으로 사용
-
saktLSTM
- 학생들의 과거 상호작용에서 관계있는 것들을 Transformer의 Attention을 이용해 찾고 예측하는 모델
- Sequential한 특징을 좀 더 반영하기 위해 Feed Forward Network가 아닌 Attention을 거친 뒤에 LSTM 단으로 예측한 값을 output으로 사용
- 문제를 맞췄는지 틀렸는지에 따라 문제 별로 다르게 임베딩이 되고 위치 정보 또한 지도록 고려되도록 구현
-
LongShort
- long term 효과와 short term 효과를 각각 다르게 학습 후 두 효과를 동시에 고려할 수 있도록 long을 예측하는 부분과 short을 예측하는 부분을 분리해서 구현한 모델
- 같은 길이의 sequence를 받아 long은 전체를 학습하고 short는 뒷부분은 padding 후에 학습해 이 둘을 합쳐 최종 output으로 예측
-
SAINT
- 정형 데이터에 Transformer 기법을 적용한 모델
-
Bert
- Transformer의 Encoder 구조를 중첩하여 data를 학습하고 분류를 위해 마지막 단에 Fully Connected Layer 를통과하여 output 생성
-
LastQuery
- Transformer의 Encoder + LSTM
- 의 시간 복잡도를 갖고있는 Transformer 모델을 마지막 Query vector 만 사용하도록 변형하여 의 시간 복잡도를 가짐
- 이렇게 학습을 진행해도 괜찮은 이유는 마지막 L 번째 시퀀스 데이터 이후 오는 값만 예측하면 되기 때문
- 모델의 특징으로인해, 시퀀스 데이터의 길이를 길게 늘릴 수 있음
-
LSTMATTN, LSTM, Bert
- 기본 모델Boosting Model
-
Catboost
- Target Encoding 방식으로 범주형 변수를 인코딩하고 Ordered Boosting 방식을 적용한 트리 구조 모델
-
Tabnet
- Tabular 데이터에 전처리 없이 Transformer와 Masking 기법을 적용한 AutoEncoder 모델
-
LGBM
- 트리기반 학습 알고리즘 모델인 Gradient Boosting 방식을 leaf-wise 구조로 확장한 모델
-
XGBoost
- 병렬처리 및 CART 앙상블 모델을 이용하여 기존 GBM을 개선한 모델
-
-
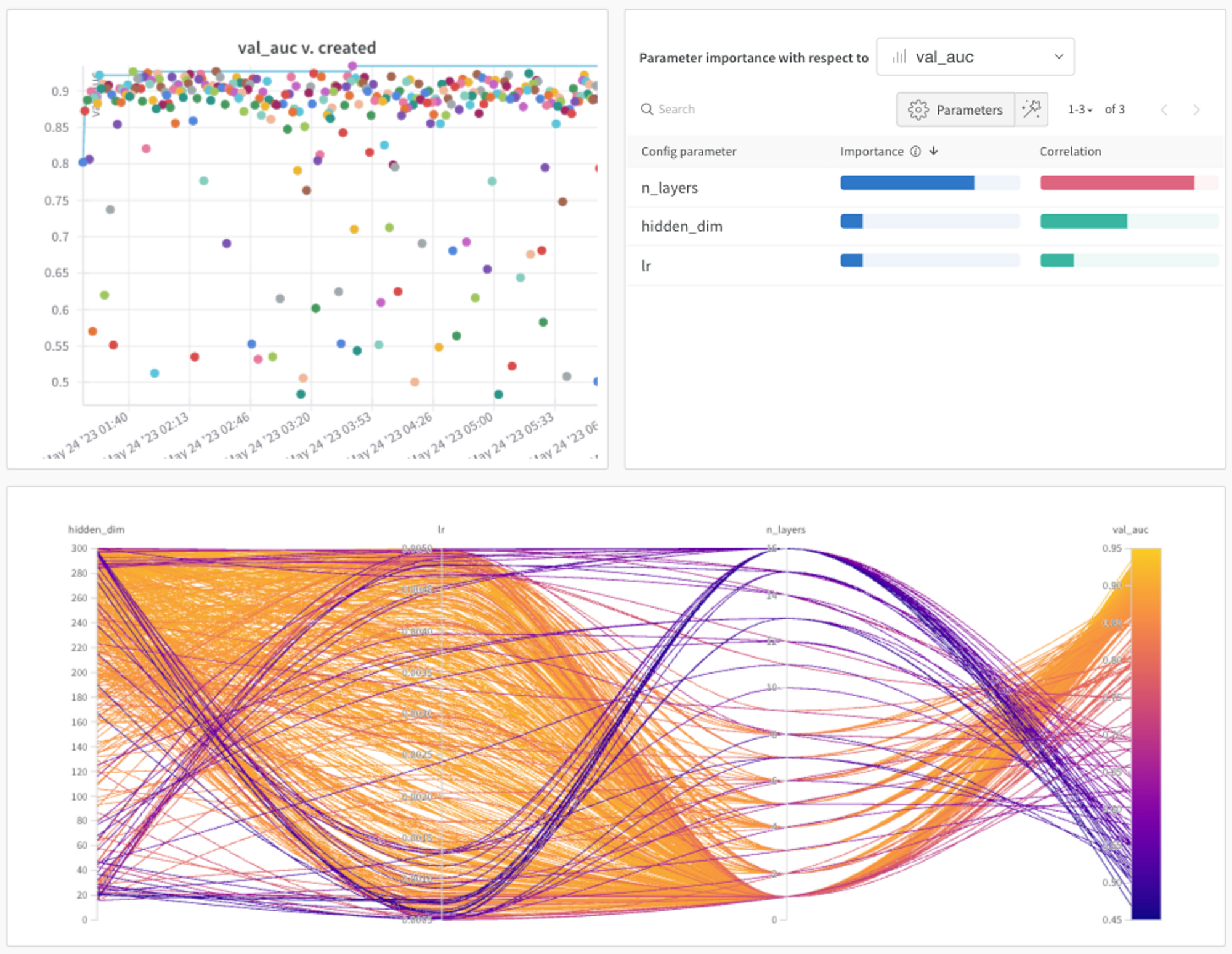
모델 선정 및 분석
- sweep을 통해 가장 적합한 파라미터(n layer, hidden dim) 등을 찾고 가장 적합한 paramter를 가질 때의 성능으로 판단
- 21개의 Feature를 사용할 경우 model 학습 속도가 너무 느려져 feature importance가 높은 feature 선택후 재학습
- sequence model의 경우 batch size가 클수록, 학습률이 낮을 수록 학습속도가 느려서 train 시키기 적당한 config값으로 재설정
- sequence model의 경우 graph embedding, shuffle 유무를 sweep config에 추가하여 실험
- LGCN에서 학습된 embedding을 사용해 성능을 향상
- Sequential한 정보로 얻을 수 있는 점과 Graph로 얻을 수 있는 정보가 달라 이를 같이 사용 시에 성능이 향상된 것으로 보임
- 결과적으로 가장 성능이 좋았던 SAKTLSTM 과 TRANSLSTM, Bert를 채택
- Transformer의 Attention 기법이 Input의 특성을 다른 모델보다 효과적으로 포착하는 것 같았음
- Boosting 계열 모델에서는 리더보드 결과 성능이 가장 좋았던 LGBM을 채택
-
시연 결과
- 각 모델 별 Valid 결과
Model AUROC ACC LSTM 0.8337 0.7324 LSTMAttn 0.8287 0.7453 Bert 0.849 0.7945 LGBM 0.8496 0.7727 XGBoost 0.8473 0.7727 SAKTLSTM 0.8368 0.7859 TransLSTM 0.8405 0.7852 LightGCN 0.9343 0.8820 LastQuery 0.7740 0.4960 TabNet 0.8093 0.7623 CatBoost 0.8412 - LightGCN 의 경우 과적합이 매우 심하여 제외
- 각 모델 별 Valid 결과
4.4 하이퍼파라미터 튜닝
- WandB 의 내장 Library 인 Sweep 사용
- 각 모델별 돌아가는 main function 을 변형하여 objective function 구현
- 전체 Epoch 동안 측정된 AUROC 값 중 best 값이 최대값이 되도록 metric 설정
- 튜닝 방법은 Bayesian Optimization 으로 진행
- 여러번의 튜닝중 제일 높은 값의 AUROC 를 갖는 Hyperparameter 값 별도로 저장
5 자체 평가 의견
- 잘했던 점
- 다양한 모델을 시도 구현해보았고 이를 빠르게 할 수 있도록 Model Base 코드를 수정해 상속받아 이루어질 수 있게 하였음
- LGCN의 Graph embedding을 사용하여 거의 모든 모델의 성능을 향상시켰음
- 기존 Embedding과 다르게 정오답 여부 및 위치에 따라 다르게 embedding이 될 수 있게 시도하였고 좋은 성능을 얻었음
- Git 협업을 통해 변경 사항을 바로바로 공유받았고 적용할 수 있었음
- 시도했으나 잘 되지 않았던 것들
- Long term 효과와 Short term 효과 모두 고려할 수 있도록 Longshort 모델을 고안해보았지만 몇 epochs 이후에 Cuda OOM이 발생하게 되어 사용해보지 못했음
- SAKTLSTM에 임베딩을 정오답 여부 및 위치에 따라 다르게 임베딩이 되도록 했는데 성능은 좋게 나왔으나 학습 시간이 너무 오래 걸려 제대로 된 튜닝이 이루어지지 못했음
- Pull Request 시, 관련 내용의 코드리뷰를 다 같이 진행하고자 했으나, 시간에 쫓겨 제대로 진행되지 않음
- 아쉬웠던 점들
- k-fold에 오류가 있어서 제대로 성능 향상이 이루어지지 않았음
- 모델 구현 및 수정함에 있어서 명확한 이론적인 근거를 가지고 이루어지지 않아 아쉬움이 있었음
- Sweep 관리 및 Git 협업 관리가 원활하게 되지 않아 시간을 많이 소비되었음
- Valid에서 과적합되었으며 리더보드에서 성능이 많이 떨어지는 이유에 대해서 찾지 못했음
