AI_tech_5기
1.Pytorch 모듈 이해하기

Parameter는 일반적으로 weight나 bias를 설정할 때 tensor 대신에 이용되는 type. parameter을 이용해야만 gradient를 계산하는 grad_fn이 생성되기 때문tensor는 gradient 계산도 x, 값 업데이트도 x, 모델을 저장할
2.Pytorch 학습 과정

Autograd & Backward 모델이 학습을 하기 위해서는 일련의 과정이 필요하다. >
3.Pytorch 학습하기
Model의 정보를 보기 위해서는 model의 state_dict를 보면 된다. 리턴은 order_dict 타입으로 이렇게 하면 다음과 같다. 아니면 summary를 이용해도 된다. 다만 summary를 이용할 경우 input의 모양을 넣어줘야한다. 다른 데이터셋으로
4.Transfer Learning & Hyperparameter Tuning
ImageNet은 1000개의 클래스로 이루어져있다. 또한 input image도 3 채널. 따라서 첫 conv 레이어와 마지막 fc 레이어의 수정이 필요하다. 그리고 이제 weight와 bias를 초기화해야하는데 bias는 해당 1/math.sqrt(layer.w.s
5.Multi_GPU 학습하기
모델을 나누거나 데이터를 나눠서 병렬적으로 처리를 할 수 있는데 모델의 병렬화는 병목과 파이프라인 설계의 어려움 때문에 섣불리 건드리기는 쉽지 않은 과제다. 데이터를 나눠서 GPU에 할당 후, 결과의 평균을 취하는 방식DataParallel단순히 데이터를 분배 -> 평
6.Optimizer
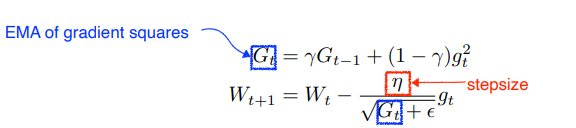
Gradient Descent > $Wt+1 $Wt+1 $a_t$라는 현재 grad로 방향을 진행하고 그 곳에서 grad를 계산한다. 그렇게 조금 더 빠르게 converge하게 된다. Adagrad > $Wt+1 = Wt - gt*n/(G_t + \epsilon)$
7.Regularization

Augmentation의 방법론 중 하나로 일반적으로 노이즈를 주거나 rotate, crop과 다르게 input을 섞거나 편집해서 output이 0, 1이 아니라 0.5, 0.5 형식으로 soft labels을 갖게해 성능을 올리는 방법이다.
8.CNN
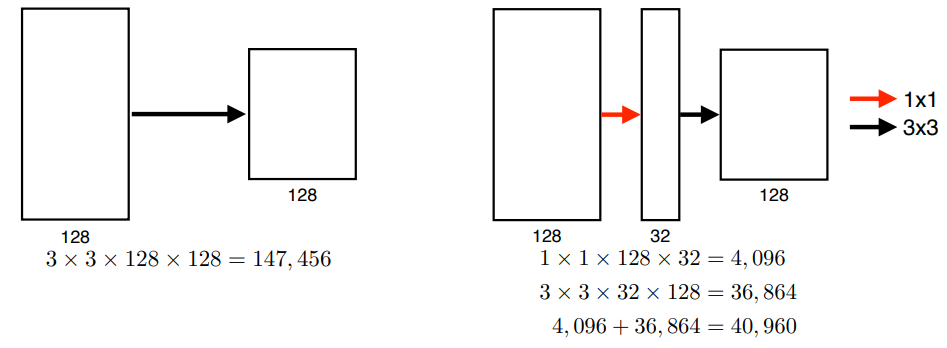
ReLU activationGPI implementationsLocal response normalization, Overlapping poolingPreserves properties of linear modelsEasy to optimizeOvercom the va
9.Sequential Model
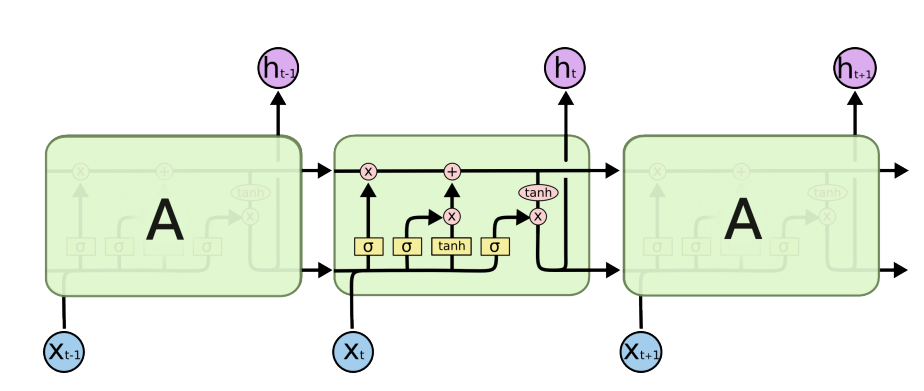
$x_t-\_1, x_t-\_2, x_t-\_3, x_t-\_4$가 주어지고 $x_t$를 예측을 하는 문제가 주어졌을 때 가장 간단한 방법은 결합확률분포를 이용하는 것일 것이다. 하지만 현재는 바로 전의 과거(very short term)에만 dependent하다는 문
10.RecSys Overview
user id, device id, browser cookiegender, age, interestpage view, item rate, interactive feedbackitem iditem featuresExplicit FeedbackImplicit Feedbac
11.Data Viz 기초
12 -> row 1, col2121 -> row1, col2 개 중 인덱스 1122 -> row1, colr2 개 중 인덱스 2plt.plot(데이터) 혹은 ax.plot(데이터)로 그린다ax는 객체이다. 객체에 직접 plotax.plot(x1, color = 'r'
12.Bar plot
데이터를 정확히 전달하기 위해서는 정렬이 필수sort_values(), sort_index()와 같이 미리 정렬을 하고 plot을 하면 좋다. 여백과 공간, 그리고 두께와 같은 것들을 적절히 조절해야 가독성이 더 높아진다.필요없는 복잡함은 X, 예를 들어 무의미한 3D
13.ANNOY & FAISS Serving
추천 시스템을 실제 적용하기 위해서는 cost efficiency가 중요하다. MF나 Item2Vec을 이용해서 구했다고 하더라도 모든 아이템에 대해서 유사도를 구하면 정확도는 높을 수 있어도 시간 효율 측면에서 매우 비효율적. 그런 측면에서 ANN이 고안이 되었다.
14.MBCF
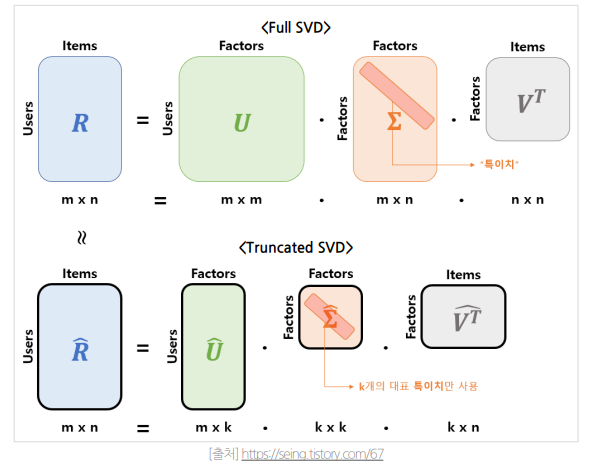
NBCF는 Sparsity와 Scalability에 대해서 한계점이 존재한다. 따라서 MBCF 기법이 등장하게 되었다항목 간 단순 유사성을 비교하는 것에 벗어나 내재된 패턴을 이용데이터 정보가 파라미터의 형태로 모델에 압축(아이템 벡터, 유저 벡터)모델의 파라미터는 데
15.RecSys with GNN
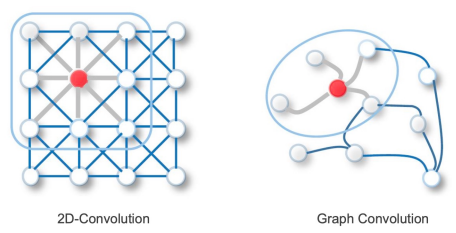
관계, 상호작용과 같은 추상적인 개념을 다루기에 적합Non-Euclidean Space의 표현 및 학습이 가능이웃 노드들 간의 정보를 이용 -> 특정 노드를 잘 represent하는 벡터를 찾는 것이 GNN의 Goal노드가 많아질수록 연산량이 많아지고 노드의 순서가 바
16.비정형 데이터 추천 시스템
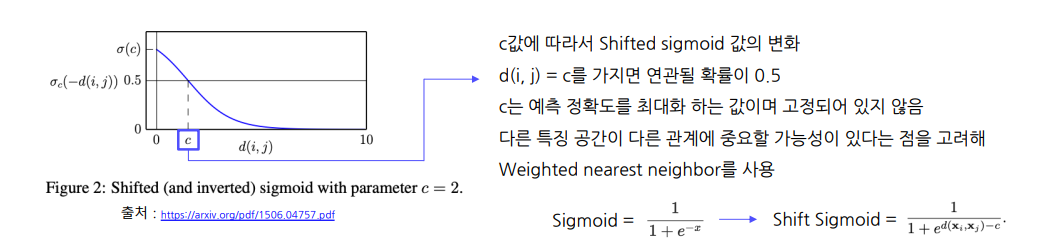
cold start problem취향이 독특한 사용자 -> feedback 분포에 악영향을 끼침사용자의 feedback을 동일하게 해석(같은 4점이여도 개개인마다 다름)근본적인 이유는 신규 유저와 아이템이 지속해서 증가하고 변화하기 때문과거 아이템의 이미지를 활용하여
17.DKT 대회 회고
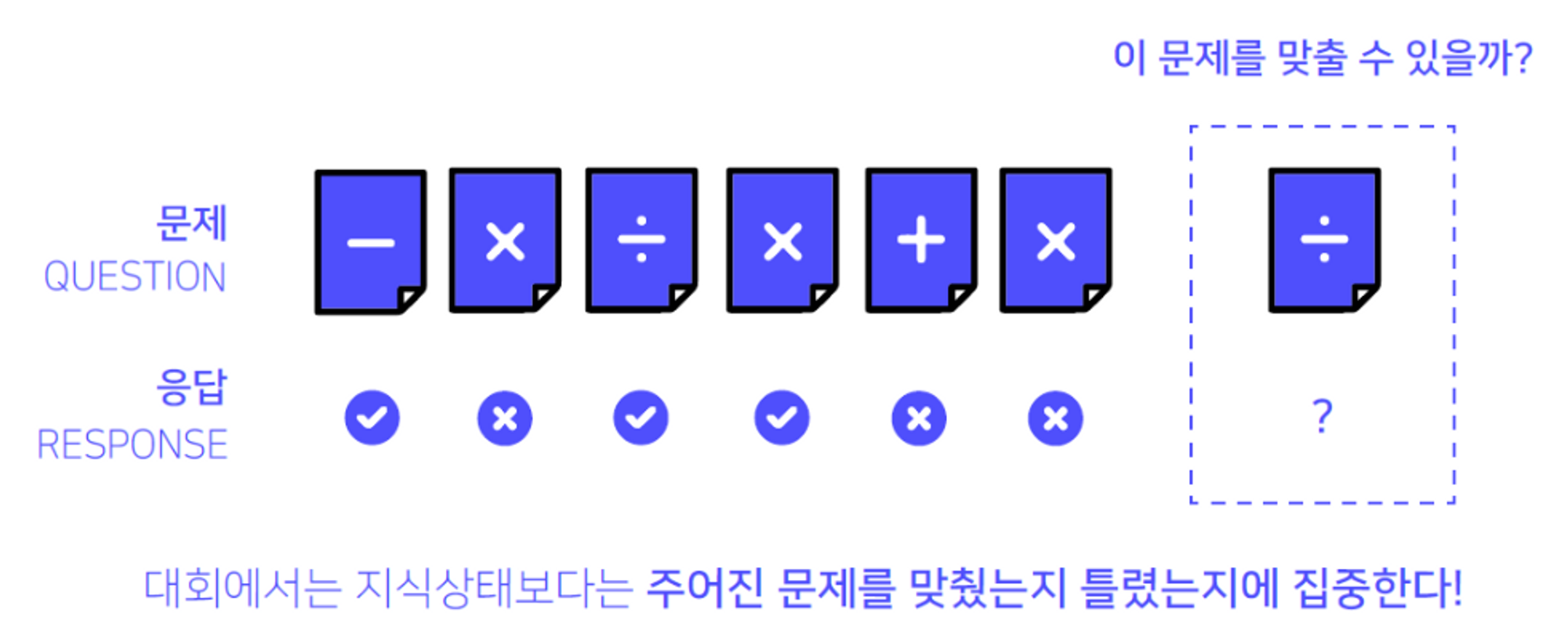
프로젝트 주제DKT는 Deep Knowledge Tracing의 약자로 “지식 상태”를 추적하는 딥러닝 방법론임. 이번 DKT대회에서는 학생들의 과거 문제 풀이 리스트와 정답여부가 담긴 Iscream 데이터셋을 이용하여 최종 문제를 맞출지 틀릴지 예측하는 것이 목표(팀
18.[논문리뷰]Bert4Rec
기존의 Sequential 방법론들은 단방향으로만 학습이 이루어져 몇가지 제한사항이 있다고 한다. 실제 유저의 행동 sequence가 꼭 한 방향으로만 이루어진다고 장담할 수도 없고 hidden representation이 효과적으로 이루어지지 않을 수도 있다. 그렇기