Gradient Descent
적절한 lr을 찾는게 중요
Momentum
B는 momentum으로 는 현재의 grad와 모멘텀이 포함된 새로운 grad로 전체적인 방향성을 유지하면서 업데이트가 진행이 된다.
Nesterov Accelerated Gradient
라는 현재 grad로 방향을 진행하고 그 곳에서 grad를 계산한다. 그렇게 조금 더 빠르게 converge하게 된다.
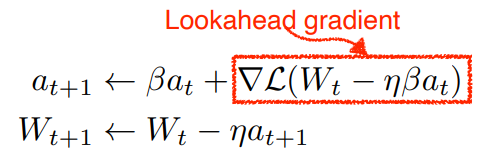
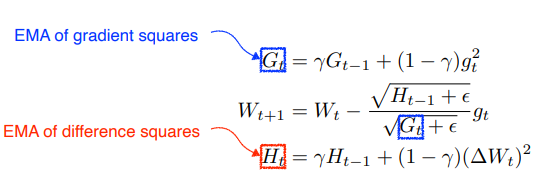
Adagrad
는 sum of grad squares로 이 값이 커지면 많이 변한 파라미터이므로 적게 변화가 된다. 결국 많이 변한 param은 적게 적게 변한 것은 크게 업데이트가 된다. 다만 결국에는 업데이트가 안 이루어지기도 adadelta는 이를 해결하기 위해 EMA를 사용(Exponential moving average)
RMSprop
Adagrad에서 stepsize를 추가하고 를 EMA로 구하기만 한 정도
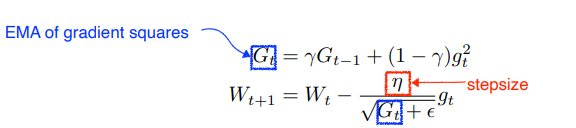
Adam
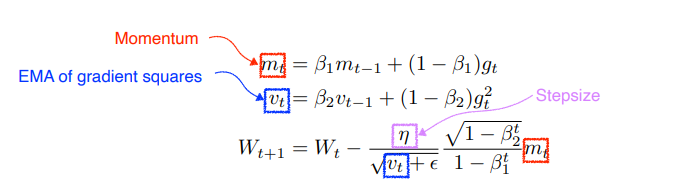
Adam은 lr을 EMA of grad square를 이용해서 adaptive하게 조정함과 동시에 momentum도 취하는 방식이다.

AI Engineer