스택과 큐
스택과 큐의 핵심 이론
스택
스택은 삽입과 삭제 연산이 후입 선출로 이루어지는 자료구조이다. 후입선출은 삽입과 삭제가 한 쪽에서만 일어나는 특징이 있습니다.
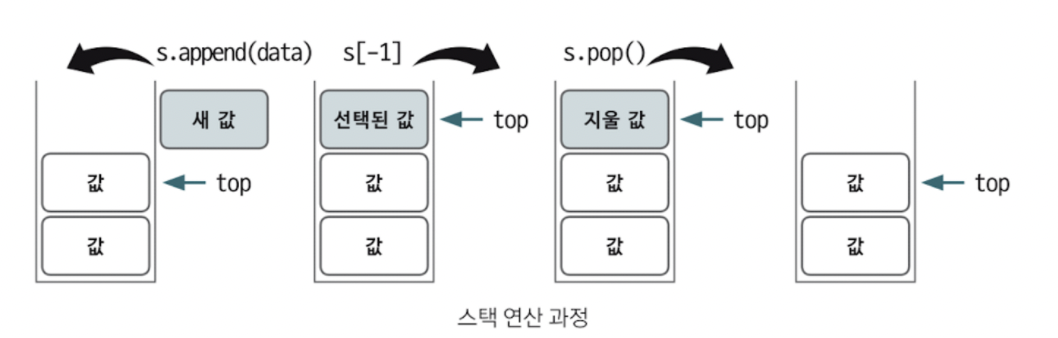
새 값이 스택에 들어가면 top이 새 값을 가리킨다. 스택에서 값을 빼낼 때 pop을 하면 top 이 가리키는 값을 스택에서 빼게 되어있기 때문에 결과적으로는 가장 마지막에 넣었던 값이 나오게 되는 것이다.
파이썬에서의 스택
위치
top : 삽입과 삭제가 일어나는 위치를 뜻한다연산
s.append(data) : top 위치에 새로운 데이터를 삽입하는 연산이다.
s.pop() : top 위치에 현재 있는 데이터를 삭제하고 확인하는 연산이다.
s[-1] : top 위치에 있는 현재 데이터를 단순 확인하는 연산이다.스택은 깊이 우선 탐색,백트래킹 종류의 코딩테스트에 효과적이므로 반드시 알아두어야 한다. 후입선출 개념자체가 재귀함수 알고리즘 원리와 일맥상통하기 때문이다.
→ 재귀함수의 경우 타고타고타고, 쭈욱 들어가서 결과를 뽑아낼때는 가장 최근에 들어간 값부터 빼낸다.
큐
큐는 삽입과 삭제 연산이 선입선출로 이루어지는로 이루어지는 자료구조입니다. 스택과 다르게 먼저 들어온 데이터가 먼저 나간다. 그래서 삽입과 삭제가 양방향에서 이루어집니다.
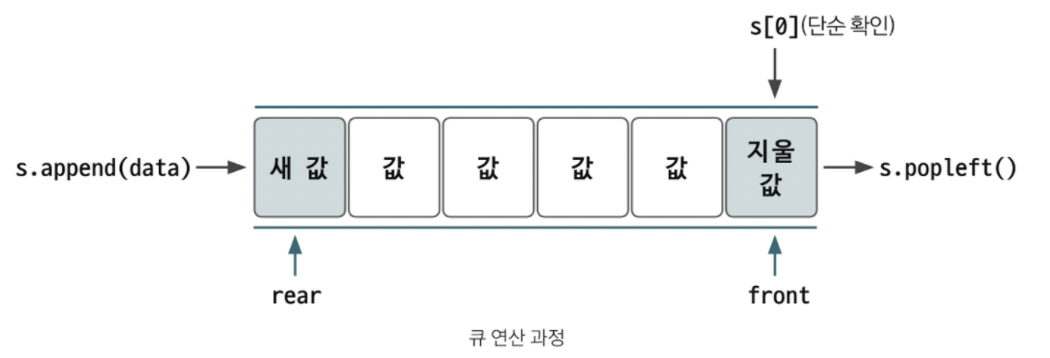
그림을 보면 새 값 추가는 큐의 rear에서 이루어지고, 삭제는 큐의 front에서 이루어진다. 파이썬에서는 일반적으로 디큐를 이용하여 큐를 구현한다.
파이썬의 큐
위치
rear : 큐에서 가장 끝 데이터를 가리키는 영역이다.
front : 큐에서 가장 앞의 데이터를 가리키는 영역이다.연산 (리스트 이름이 s일때)
s.append(data) : rear 부분에 새로운 데이터를 삽입하는 연산이다.
s.popleft() : front 부분에 있는 데이터를 삭제하고 확인하는 연산이다.
s[0] : 큐의 맨 앞(front)에 있는 데이터를 확인할 때 사용하는 연산이다큐는 너비 우선 탐색에 자주 사용하므로 이 역시도 스택과 함께 잘 알아두어야 하는 개념이다.
- 우선순위 큐 ? 우선순위 큐는 값이 들어간 순서와 상관없이 우선순위가 높은 데이터가 먼저 나오는 자료구조이다. 큐 설정에 따라 front 에 항상 최댓값 또는 최솟값이 위치한다.
스택으로 수열 만들기
이해하는데 조금 힘들었던 문제다. 일단 문제에 대해서 이해를 해보자.
1~n 까지의 수를 스택에 저장하고 스택에서 값을 뺄때마다 나오는 값으로 수열을 만드는 것이다.
인풋값을 이용하여 얘기를 해보자면 다음과 같다.
예제 입력 1번의 경우 1~8까지의 수를 스택에 저장하고 스택에서 값을 뺄때마다(pop) 나오는 값으로 수열을 만들어야 한다.
첫번째 입력값인 4가 들어왔다. 현재 수열의 값은 1이기 때문에 즉, 입력값 ≥ 수열값 인 상태가 된다.4 ≥ 1 이기 때문에 수열값은 입력값을 따라잡아야 한다. pop했을때 입력값이 나올때까지 말이다.
num = int(stdin.readline())
#입력받은 자연수
if num >= value:
#value : 수열값
while num >= value:
#원하는 값에 도달할때까지 append한다 !
arr.append(value)
answer+= "+\n"
value += 1
#도달한 이후 pop을 해준다
arr.pop()
answer+="-\n"다음 로직은 수열의 값보다 입력값이 작은 경우이다. 예제 2번의 경우 1~5까지의 수를 스택에 저장하고 스택에서 값을 뺄때마다(pop) 나오는 값으로 수열을 만들어야한다.
첫번째 입력값인 1이 들어오면 현재 수열의 값과 동일하기 때문에 pop을 한다. 2또한 똑같이 진행된다. 입력값과 수열의 값이 동일하기 때문이다.
현재 스택은 두번의 pop으로 비어있는 상태이며, 수열의 값 은 3이다. 입력값 인 5에 맞추기 위해서 수열의 값을 추가한다 스택은 다음과 같은 상태를 가진다
[3,4,5] 이 상태에서 pop을 하면 [3,4]가 된다.
다음 입력값 은 3이며, 수열의 값은 6이다.
n = arr.pop() //수열의 값
if n > num:
print("NO")
result = False
break
else:
answer +="-\n"해당 코드를 보면 pop한 값인 n은 4이다. 4는 입력값인 3보다 큰 값이다.
그 말은 즉슨, 이미 차 떠낫다는 소리다. 이 상태에서 pop한 값이 크면 append하는 방식으로는 pop해서는 수열을 만들 수 없기 때문이다.
import java.io.*;
import java.util.*;
public class Main {
public static void main(String[] args) throws IOException {
//스택으로 수열 만들기
//bj 1874
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
Stack<Integer> stack = new Stack<>();
int N = Integer.parseInt(br.readLine());
int value = 1; //현재 수열
String answer = "";
Boolean result = true;
//입력받는 부분
for(int i=0;i<N;i++){
int number = Integer.parseInt(br.readLine());
if (number >= value){
while(number>=value){
stack.add(value);
answer+= "+\n";
++value;
}
stack.pop();
answer+= "-\n";
}else{
int item = stack.pop();
if(item>number){
bw.write("NO");
result = false;
break;
}else{
answer+="-\n";
}
}
}
if(result == true){
bw.write(answer);
}
bw.flush();
}
}자바의 경우 메모리 초과가 계속 떠서 왜 뜨는지 찾아보니까 String 대신 StringBuilder를 사용해주어야했다.
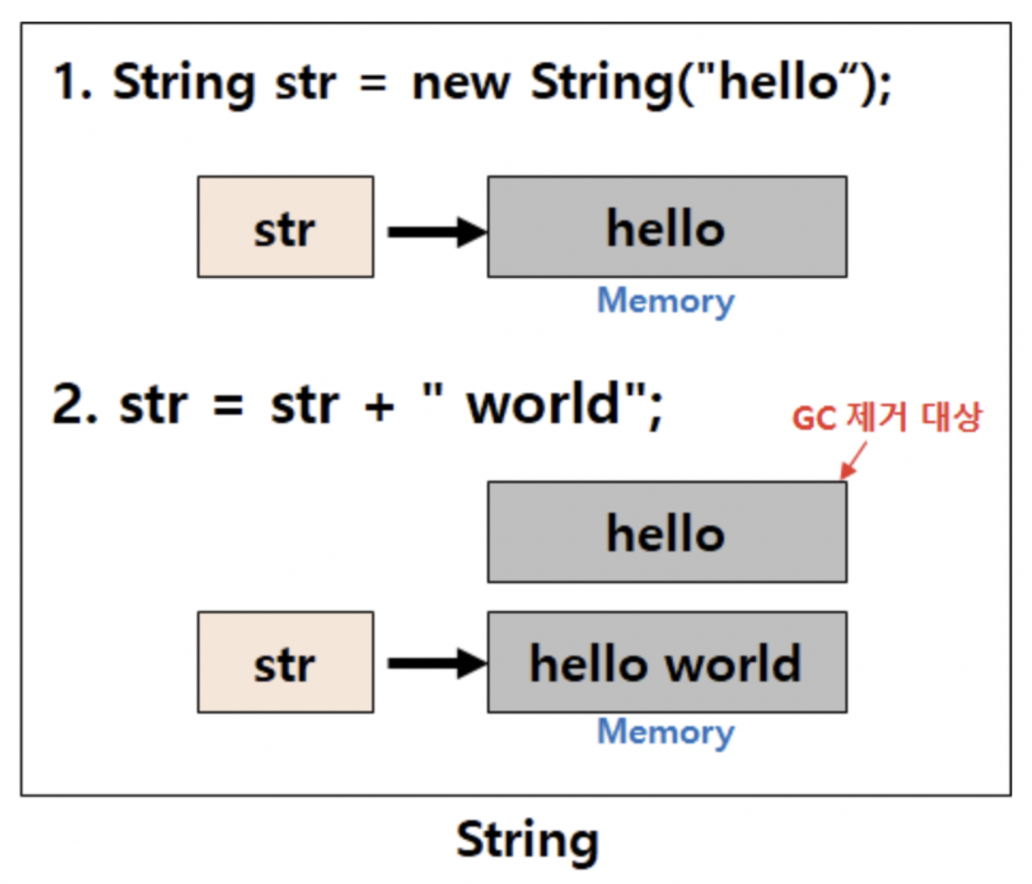
String의 경우 불변성을 가지기 때문에 변하지 않는 문자열을 자주 읽어들이는 경우 String을 사용하면 괜찮지만, 문자열 추가,수정,삭제 등의 연산이 빈번하게 발생하는 알고리즘에 String 클래스를 사용하면 힙메모리에 많은 임시 가비지가 생성되어 힙메모리 부족으로 어플리케이션 성능에 치명적인 영향을 끼치게 된다.
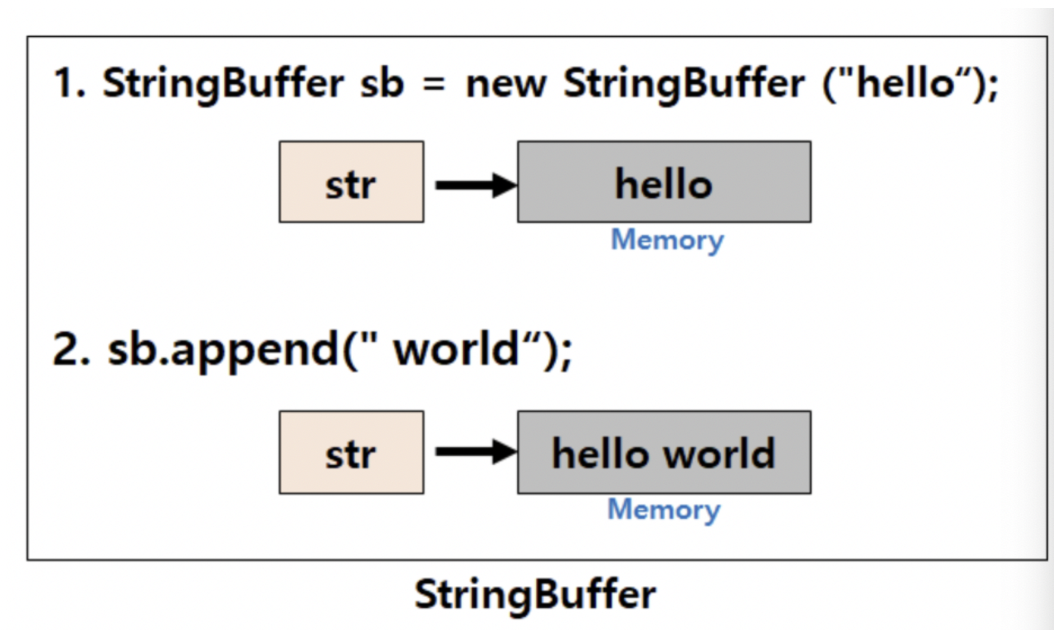
이러한 문제를 해결하기 위해 가변성 을 가지는 StringBuffer / StringBuilder 클래스를 도입했다. 문자열의 추가,수정,삭제가 빈번하게 발생할 경우라면 이걸 사용해야한다!
[Java] String, StringBuffer, StringBuilder 차이 및 장단점
import java.io.*;
import java.util.*;
public class Main {
public static void main(String[] args) throws IOException {
//스택으로 수열 만들기
//bj 1874
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
Stack<Integer> stack = new Stack<>();
int N = Integer.parseInt(br.readLine());
int value = 1; //현재 수열
StringBuilder answer = new StringBuilder();
Boolean result = true;
//입력받는 부분
for(int i=0;i<N;i++){
int number = Integer.parseInt(br.readLine());
if (number >= value){
while(number>=value){
stack.push(value);
answer.append("+\n");
++value;
}
stack.pop();
answer.append("-\n");
}else{
int item = stack.pop();
if(item>number){
bw.write("NO");
result = false;
break;
}else{
answer.append("-\n");
}
}
}
if(result == true){
System.out.println(answer);
}
bw.flush();
}
}오큰수
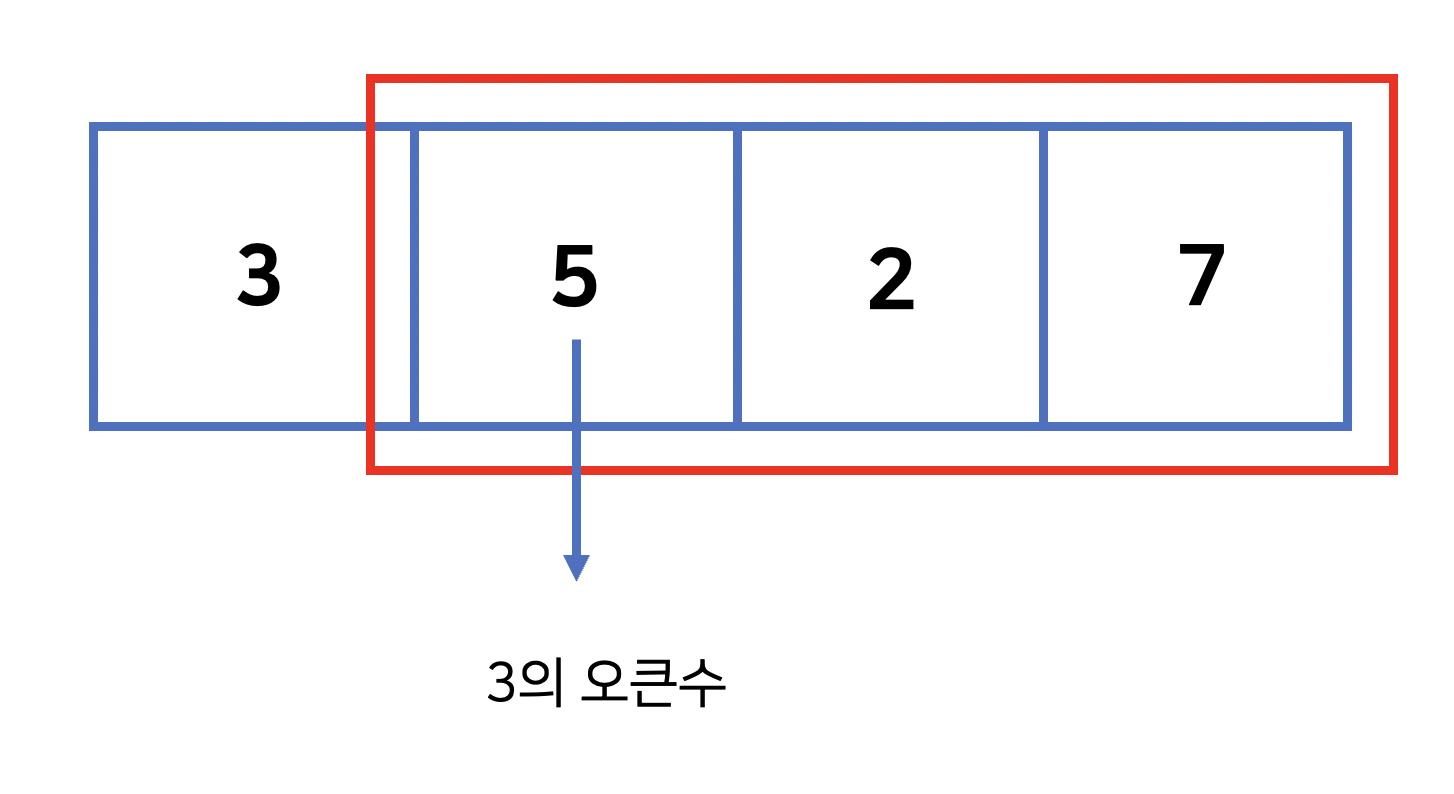
사진에서 보다싶이 오큰수는 주어진 수의 오른쪽에 있는 배열 중 가장 왼쪽에 있으면서 주어진 수 보다 큰 수를 말한다.
오 오른쪽에 있는 수를 확인하면서 주어진 수보다 크면 바로 그것이 오큰수라는 것이다.
이 로직의 경우 N이 1,000,000이기 때문에 반복문으로 오큰수를 찾으면 제한시간을 초과하게 된다.
제일 처음으로 찾은 주어진 수 보다 큰 수 라는 관점에서 보면, 주어진 수 보다 작은 수는 무시해도 된다.
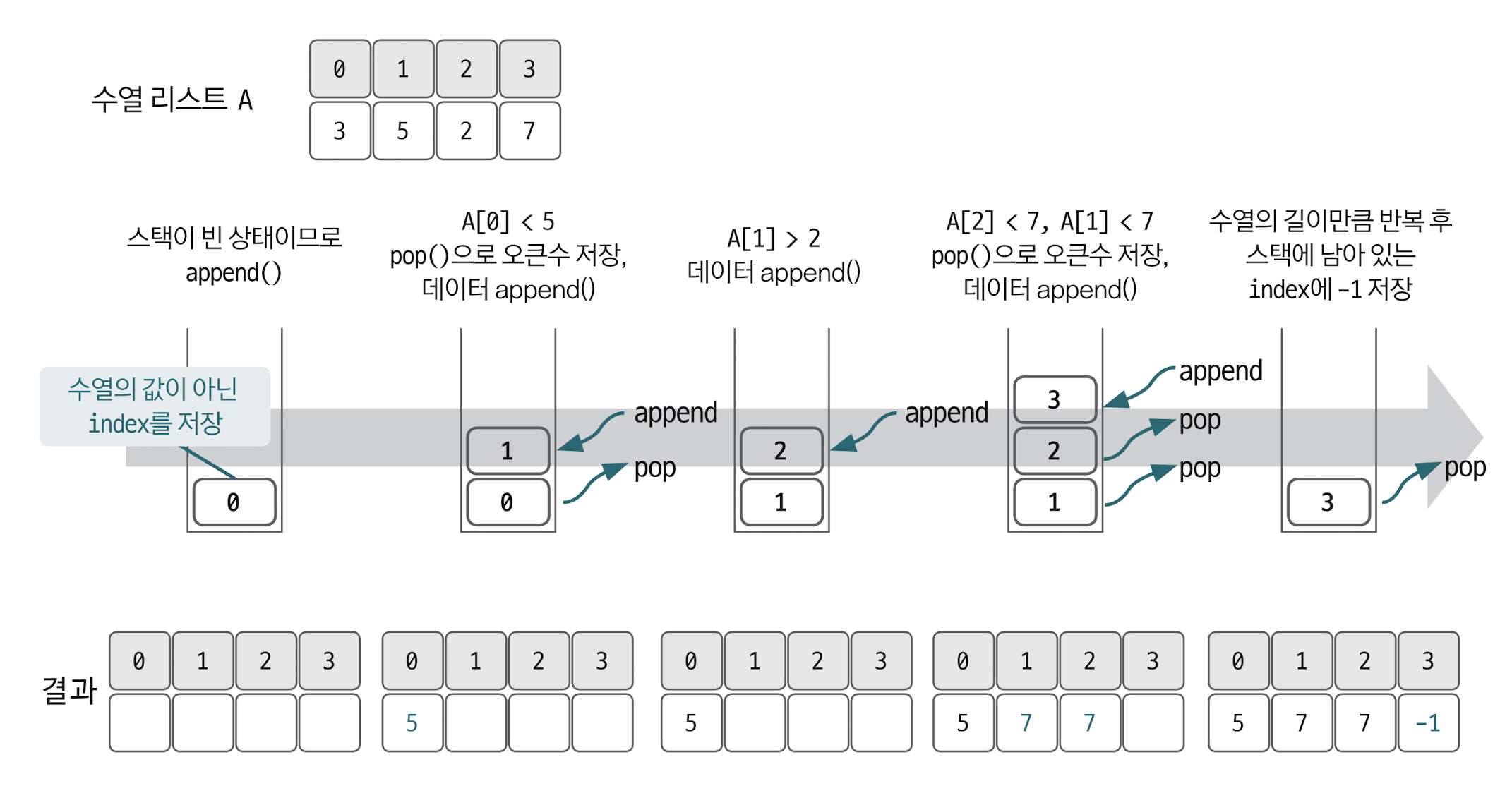
일단,배열의 인덱스와 값 두개를 이용하여 스택을 구현할 것이다.
주어진 수 보다 작은 수는 무시해도 된다는 말은 어디에서 쓰이느냐 ?
바로 append 하는 과정이다.
스택의 top 보다 큰값이 나올때까지 스택에 수열의 인덱스를 추가할 것이다.
이 인덱스를 이용하여 결과 배열에 0번째 수의 오큰수를 넣어주는 방식으로 정답을 작성해줄 것이다.
코드를 보면
while stack and (arr[i] > arr[stack[-1]]):
answer[stack.pop()] = arr[i]top 보다 큰 값(주어진 값)이 나오면 top에 있던 값은 반환한다. 이때 주어진 값이 top 의 오큰수가 된다.
즉, top에 있던 값 (인덱스 위치에 있던 수)의 오큰수를 해당 인덱스에 저장한다는 뜻이다.
from sys import stdin
N = int(stdin.readline())
arr = list(map(int,stdin.readline().split()))
stack = []
answer = [-1] * N
# -1로 초기화 하면 없는애들은 자동으로 -1 배정
for i in range(N):
while stack and (arr[i] > arr[stack[-1]]):
answer[stack.pop()] = arr[i]
#pop()한 것의 자리에 오큰수가 들어가는 것
stack.append(i)
print(*answer)import java.io.*;
import java.util.*;
public class Main {
public static void main(String[] args) throws IOException {
//오큰수 구하기
//bj 17298
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st;
Stack<Integer> stack = new Stack<>();
int N = Integer.parseInt(br.readLine());
int[] arr = new int[N];
int[] answer = new int[N] ;
st = new StringTokenizer(br.readLine()," ");
for(int i=0;i<N;i++){
int num = Integer.parseInt(st.nextToken());
arr[i] = num;
while(!stack.isEmpty() && (num > arr[stack.peek()])){
answer[stack.pop()] = num;
}
stack.add(i);
}
while(!stack.isEmpty()){
answer[stack.pop()] = -1;
}
for(int i=0;i<N;i++){
bw.write(answer[i]+" ");
}
bw.flush();
}
}카드2
from sys import stdin
from collections import deque
N = int(stdin.readline())
que = deque()
for i in range(N):
que.append(i+1)
while len(que) > 1:
que.popleft()
front = que.popleft()
que.append(front)
print(que.popleft())그냥 조건에 충실하게 구현하면되는 문제였다.
위 , 아래를 front 와 rear로 생각하고 큐로 풀었다.
절댓값 힙
데이터가 새로 삽입될 때 마다 절댓값과 관련된 정렬이 필요하므로 우선순위 큐로 문제를 쉽게 해결할 수 있다. 단, 이 문제는 절댓값 정렬이 필요하기 때문에 우선순위 큐의 정렬 기준을 직접 정의해야 한다.
절댓값이 같을 때는 음수를 우선하여 출력해야 하는 사실을 주의해야함
그렇다면 우선순위 큐가 무엇인지에 대해서 알아보자
우선순위 큐
데이터를 추가한 순서대로 제거하는 선입선출 특성을 가진 일반적인 큐의 자료구조와는 달리, 데이터 추가는 어떤 순서로 해도 상관이 없지만 제거될 때는 가장 작은 값을 제거하는 특징을 가진 자료구조이다.
이 말은 내부적으로 데이터를 정렬된 상태로 보관하는 매커니즘이 있다는 뜻입니다 (heaq 모듈을 통해 구현되어 있습니다)
우선순위큐의 정렬 기준을 설정하려면 (우선순위,값) 의 튜플 형태로 데이터를 추가하고 제거하면 된다
que.put((3,”apple)) 이런식으로 !
from sys import stdin
from queue import PriorityQueue
N = int(stdin.readline())
que = PriorityQueue()
for _ in range(N):
number = int(stdin.readline())
if not que.empty():
if number != 0:
que.put((abs(number),number))
else :
print(que.get())
else :
print(0)→ 처음에 작성한 코드 empty 검사를 입력할때 하면 초반 큐가 생성되지 않는다. 한번 넣은 상태에서 해줄라면 아래와 같이 empty검사를 0일때 해주는 것이 좋다.
왜냐하면 0을 넣을 때 출력하기 때문에 출력할게 없다면 0을 리턴하게 해주기 위함
from sys import stdin
from queue import PriorityQueue
N = int(stdin.readline())
que = PriorityQueue()
for _ in range(N):
number = int(stdin.readline())
if number != 0:
que.put((abs(number), number))
else:
if not que.empty():
print(que.get()[1])
else:
print(0)