CNN
이미지 분류
이미지를 넣었을 때 그 이미즈의 class를 분류해내는 작업
- 사람은 쉽게 분류할 수 있는 작업이 컴퓨터에게는 어려울 수 있다
- 사람은 이미지 전체를 한 눈에 보고 전반적인 경험에 비추어 물체를 분류해 낸다.
- 컴퓨터는 이미지를 구성하고 있는 pixel 값들을 받아 분류하며 관측한 위치(viewpoin). 빛(illumination), 자세(deformation), 가려짐(Occlusion), 생김새의 차이(intra-class variation)등에 따라 다르게 볼 수 있다.
- 단순 pixel값 만으로 물체를 분류하는 것은 바람직하지 않을 수 있다.
- 물체를 분류하는데 필요한 특징들 이외에 배경 등에 영향을 많이 받게 된다.
- 사람이 물체를 인식하는데 필요한 여러 특성들을 많은 데이터를 통해 축적하며 이를 바탕으로 물체를 분류한다.(딥러닝)
Rule Based
- 개의 눈, 코, 입, 귀 등과 같은 특징들의 존재여부 등으로 규칙을 세우고 그 규칙에 부합하는가의 여부로 개를 분류한다
- 단점
- 불안정
- 분류를 위한 규칙을 정하기 어려움
- 각 class를 분류하는 모델을 따로 만들어야함 (= 각 class마다 rule을 따로 정해야함)
Data Driven
데이터를 기반으로 모델을 만들어 문제 해결
데이터 증강(Data Augmentation) 기법
- 컴퓨터는 이미지를 구성하고 있는 pixel 값들을 받아 분류하며 관측한 위치(viewpoin). 빛(illumination), 자세(deformation), 가려짐(Occlusion), 생김새의 차이(intra-class variation)등에 따라 다르게 볼 수 있다.
- 원본 데이터에 변화를 가하여 학습에 활용할 수 있는 새로운 데이터를 만드는 기법
- Overfitting을 막기 위한 방법으로 Regularization/Normalization 등 이외에 데이터 수를 늘리는 방법이 있다.
- Data Augmentation도 데이터 수를 늘림으로써 Overfitting을 막기 위한 방법 중 하나
- 너무 과한 Data Augmentation 기법을 적용할 경우 오히려 학습에 혼동을 줄 수 있다.
CNN
- CONV layer - ReLU - CONV layer - ReLU - Pooling layer - CONV layer ... - FC Layer
- 마지막 Output feature map을 FC Layer에 넣어 class 수 만큼의 차원으로 바꿈
- softmax를 사용하여 최종 classification score를 뽑아냄
Spatial / Locality
- 단순히 눈 2개, 코 1개, 입 1개가 있다는 사실을 인지하는 것 뿐 아니라 두 눈이 코 위에 있으며 입이 코 아래에 있다는 공간 정보를 네트워크가 인지하길 바람
- 이미지를 구성하는 특징들은 이미지 전체가 아닌 일부 지역에 근접한 픽셀들로만 구성되어 근접한 픽셀들끼리만 의존성을 가짐 (Spatial/Locality)
- 위와 같은 insight를 통해 나온 방법이 CNN(Convolutional Neural Network)
Convolution Layer
- Filter와 input Feature map간의 convolution 연산이 filter단위로 '내적'을 함
- 차원(depth)은 input feature map과 filter가 동일해야 함
- Filter의 수는 Output feature map의 차원(depth)이 됨
stride
- 모든 spatial locations에 대해 convolution 연산 진행
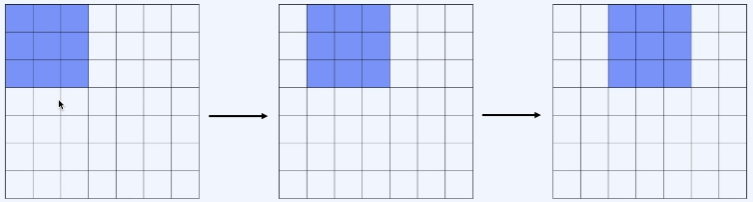
- 1칸씩 움직인다 했을 경우(stride = 1)
- 파란색 filter가 5 x 5 output feature map을 만듦
- 이 때 1칸 씩을 stride라고 함
- 2칸씩 움직인다 했을 경우(stride = 2)
- 파란색 filter가 3 x 3 output feature map을 만듦
padding
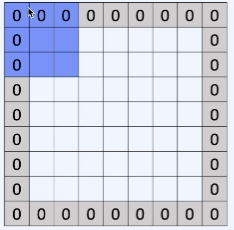
- convolution layer를 쌓을수록 input feature의 크기가 작아지는데, 이를 유지하기 위함
- input feature의 중앙 부분은 filter가 많이 보이지만 side 부분은 덜 보게 되는데, side 부분의 정보도 더 잘 이용하기 위함
Pooling Layer
- Convolution Layer는 각 filter당 하나의 feature map이 형성되며 이 feature map들을 쌓아 output feature map이 구성됨
- Filter가 많을 경우 많은 weight(parameter)를 필요로 하게 되며 이 경우 over-fitting을 초래할 수 있음
- 따라서 feature map의 크기를 감소시키는 방법으로 over-fitting을 방지하려 함
- Pooling layer를 도입
- Convolution layer에서 이미지에서 어떤 특징이 얼마나 있는지를 구한 후 Pooling layer에서 이미지의 뒤틀림이나 크기 변화에 따른 왜곡의 영향을 축소
parameter(weight) sharing
- 두 귀를 하나의 특징으로 취급하여 위치에 상관없이 귀 2개 추출(귀가 2개)
- 위치를 고려하여 서로 다른 2개의 귀로 인식하는 것(귀1, 귀2 각각 1개씩)
- 2의 경우 동일한 특징이라도 위치가 다르면 다른 특징으로 인식해야하기 때문에 모두 다른 filter를 사용 -> 비효율
- 1을 위해 parameter(weight) sharing방법을 사용
- MLP보다 더 적은 파라미터를 사용화여 메모리를 아끼고 연산량도 더 효울적이게 됨
Translation Equivariance
입력의 위치가 변하면 출력도 동일하게 위치가 변한 상태로 나옴
- Equivariance : 함수의 입력이 바뀌면 출력도 바뀜
- Conv Layer의 특징
- 앞서 다뤘던 Spatial 정보를 고려하는 것과 특징이 유사
Translation Invariance
입력의 위치가 변해도 출력은 위치가 변하지 않음
- invariance : 함수의 입력이 바뀌어도 출력은 유지되어 바뀌지 않음
- Convolution + Parameter(Weight) Sharing을 통해 갖게되는 특성
- Max Pooling : small translation invariace
- 여러 픽셀 중 최댓값을 가진 픽셀 하나를 출력
- 위치 정보를 특히 중요하게 쓰고 싶을 경우 translation invariance를 막아야 한다.
MLP와 CNN 비교
MLP
- Fully connected layer : 각 perceptron이 다른 모든 perceptron과 연결된
- 모든 것에 연결되어 있기 때문에 총 aprameter 수가 매우 많고 따라서 메모리를 많이 차지함
- Spatial 정보를 고려하지 않음 - 이미지 처리에 적절하지 않음
- 단순한 이미지에서 어느정도 작동함
- 1차원으로 펴진 flatten vector(matrix to vector)만 입력으로 받음
- CNN에 비해 구조가 간단하고 단순함
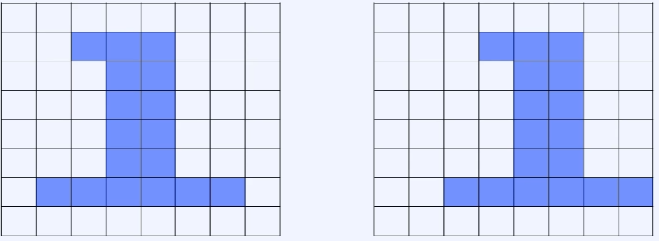
- 두 이미지 모두 1을 의미하는 같은 모양이지만 픽셀 값의 위치가 달라짐에 따라 모델이 다른 값으로 인식함
- 왼쪽 이미지 위주로 학습된 웨이트를 가진 모델일 경우 이미지를 인식하는데 어려움을 겪음
- 모든 입력이 위치와 상관없이 동일한 수준의 중요도를 가짐
CNN
- 컴퓨터 비전 알고리즘에서 가장 많이 쓰임
- Parameter(weight) sharing으로 인해 연산량 및 메모리를 많이 아낄 수 있음
- Spatial 정보를 고려함
- 벡터, 행렬 등을 input으로 받을 수 있음
Hyper Parameter
Parameter : 모델 내부에서 결정되는 변수
- 딥러닝의 경우 학습되는 weight
- 통계의 경우 추정되는 값
- 데이터로부터 결정
- 사람이 임의로 결정할 수 없음
Hyper Parameter
모델링할 경우 사용자가 직접 결정해주는 것
- Heuristic한 방법으로 결정됨
learning rate
너무 클 경우 minimum에 도달하지 못할 가능성이 크고 작을 경우 학습이 느리게 됨
Epoch 수
너무 많이할 경우 모델이 overfitting이 될 수 있으며 적게 할 경우 학습이 덜 될 수 있ㅇ므
CNN에서 layer의 수, Filter의 수
너무 많을 경우 overfitting 밒 과한 메모리와 느린 속도로 이어질 수 있으며 적을 경우 학습이 덜 될 수 있음
activation function으로 어떤 것을 사용할 지
- 목적에 따라 다양한 activation fucntion을 사용할 수 있음
어떤 손실 함수를 사용할지
- 목적에 다라 다양한 손실 함수를 사용할 수 있음
- e.g. MSE, Cross Entropy
어떤 최적화 기법을 사용할지
- SGD, Nesterov, Momentum, Adam optimization
Mini batch size
- 너무 클 경우 메모리가 많이 들 수 있으며 너무 작을 경우 학습이 느리게 됨
Weight Initualization
- 초기 weight를 어떻게 설정하느냐에 따라 학습에 영향을 미치게 됨
Hyper Parameter search
Manual search
- 모델링을 하는 사람의 직관이나 경험에 의존하여 결정
- 사람이 직접 시행착오의 반복을 통해 결정
Grid Search
- 주어진 후보군에 대해 일정 간격의 값을 순차적으로 대입하며 최적의 hyper parameter를 찾음
- 후보군이 많을수록 시간이 오래 걸림
- Manual search와 크게 다르지 않음
Random Search
- 일정한 간격이 아니라 무작위로 최적값을 찾는 방법

가보자가보자~