검정(test)
- 내가 세운 가설이 통계적으로 유의한지 살펴보는 것
- 검정순서
- 1. 귀무가설과 대립가설을 설정한다.
- 2. p-value를 구한다.
- 3. p-value를 기준으로 가설의 채택/기각 여부를 결정한다
- p-value가 0.05(유의수준)보다 크면 귀무가설을 채택
- p-value가 0.05(유의수준)보다 작으면 귀무가설을 기각
귀무가설(Null hypothesis :H0)
- 검정 대상이 되는 가설
- 관습적이고 보수적인 가설
- 표본을 보고 "이러할 것이다."라고 세운 가설
- 연구자가 주장하고 싶은 대립가설과 반대되는 진술
- 귀무가설은 기각(Reject)이 목표
대립가설 (Alternative hypothesis : H1)
- 귀무가설에 대립되는 가설
- 지금까지 알려지지 않은 새로운 주장
- 연구자가 원하는 주장 혹은 가설
- 대립가설은 채택(accept)이 목표
단측검정, 양측검정
단측검정(one-tailed test)
- 한 방향성으로 가능성이 크다고 생각될 때
양측검정(two-tailed test)
- 방향성은 모르겠지만 차이가 있다고 생각될 때
검정에서 조심해야할 두가지 실수
제 1종 오류
- "귀무가설"이 옳은데도 불구하고 이를 기각
- 우연에 의한 효과를 실제 효과라고 잘못 결론 내리는 것
제 2종 오류
- "귀무가설"이 옳지 않은데도 이를 채택
- 실제 효과를 우연에 의한 효과라고 잘못 결론 내리는 것
t 검정(t test)
- 모집단의 분산이나 표준편차를 알지 못할 때 모집단을 대표하는 표본으로부터 추정된 분산이나 표준편차를 가지고 검정하는 방법
- "두 모집단의 평균간의 차이는 없다" 라는 귀무가설
- "두 모집단의 평균 간에 차이가 있다" 라는 대립가설
t 값(t-value)
- t 검정에 이용되는 검정통계량
- 두 집단의 차이의 평균(X)을 표준오차(SE)로 나눈 값
- [표준오차와][표본평균사이의 차이]의 비율
기각역(Critcal Region)
- 귀무가설이 기각되기 위한 검정통계량(t값)이 위치하는 범위, 면적(유의수준)과 자유도(n-1)에 의해 결정된다
- 단측검정의 경우 기각역이 한쪽에 존재
- 양측검정의 경우 기각역이 양쪽에 존재
순서
- if 표본의 크기가 10~30이면,
- 정규성 검정
- 정규성이라면, 등분산 검정
- 정규성이 아니라면, 순위합 검정
- 정규성 검정
- if 표본의 크기가 30이상이면,
- 등분산 검정
- 등분산이라면, 등분산 가정 독립표본 t test
- 아니라면, 이분산 가정 독립표본 t test
- 등분산 검정
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import scipy.stats as stats # 수도권 normal(x,y,z) x -> 평균, y-> 분산, z -> 갯수 house_a = np.random.normal(6, 5, 40) # 지방 house_b = np.random.normal(5.5, 5, 40) # array를 list로 변환후 데이터프레임으로 감싸기 pd.DataFrame(house_a.tolist()) tmp1 = pd.concat([pd.DataFrame(['B']*40), pd.DataFrame(house_b.tolist())],axis=1) tmp2 = pd.concat([pd.DataFrame(['A']*40), pd.DataFrame(house_a.tolist())],axis=1) df = pd.concat([tmp1, tmp2], axis=0) # 데이터의 열 이름 변경 df.columns = ['grp', 'value'] sns.boxplot(x='grp', y='value', data=df) plt.show()
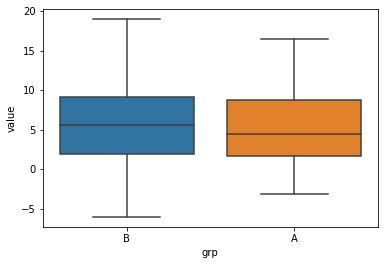
# 등분산성 검정 # 귀무가설: 수도권(grp A), 지방(grp B) 집값의 분산이 같다 # 대립가설: 수도권(grp A), 지방(grp B) 집값의 분산이 다르다 stats.levene(np.array(df[df['grp'] == 'A']['value']), np.array(df[df['grp'] == 'B']['value'])) # t검정 stats.ttest_ind(np.array(df[df['grp'] == 'A']['value']), np.array(df[df['grp'] == 'B']['value']), equal_var=True)
등분산 결과 pvalue=0.702027608205829 로 유의수준 0.05보다 큼으로 귀무가설을 기각해 등분산성이 없다고 판단된다 .
t 검정 결과 pvalue=0.9330675569599344 로 유의수준 0.05보다 큼으로 귀무가설을 기각해 모집단 간의 평균의 차이가 있다고 판단된다.

가보자가보자~