Disney 데이터 설명
데이터 업로드
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns disney = pd.read_csv("/content/disney.csv")
데이터 내용 확인
# .columns : 컬럼명 확인 disney.columns
# .head(3) : 데이터의 상단 3개 행 출력 disney.head(3)
# .info() : 데이터에 대한 전반적인 정보 제공 disney.info()
결측치 비율 확인
for 반복문을 통해 각 컬럼별 결측치 비율을 계산하여 문자열로 출력
# .isna( ) : 결측 값은 True 반환, 그 외에는 False 반환 for i in disney.columns : missingValueRate = disney[i].isna().sum() / len(disney) * 100 if missingValueRate > 0 : print("{} null rate: {}%".format(i,round(missingValueRate, 2)))
결측치 처리
결측치 처리 (1) - fillna
# .fillna( ) : 결측치를 특정 값으로 채우거나 대체하여 처리 # 원본 객체를 변경하려면 inplace = True 옵션 추가 disney['director'].fillna('No Data', inplace = True)
결측치 처리 (2) - replace
# .fillna( ) : 결측치를 특정 값으로 채우거나 대체하여 처리 # 원본 객체를 변경하려면 inplace = True 옵션 추가 disney['country'].replace(np.nan, 'No Data',inplace = True) disney['cast'].replace(np.nan, 'No Data',inplace = True)
결측치 처리 (3) - dropna
# .dropna(axis = 0) : 결측치가 있는 행 전체 제거 # 원본 객체를 변경하려면 inplace = True 옵션 추가 disney.dropna(axis = 0, inplace=True)
결측치 개수 확인
결측치 개수를 출력하여 결측치가 잘 처리된지 확인
# 처리된 결측치 확인 - .isnull().sum() # 각 컬럼별 결측치 개수 반환 # .isnull() == .isna() : 결측 값은 True 반환, 그 외에는 False 반환하며 # 데이터프레임 내에 결측 값을 확인하기 위해 사용 disney.isnull().sum()
Feature Engineering
- date_added 변수를 이용하여 month_added(개봉한 월) 정보를 변수로 생성
date_added 변수를 시간 형식의 object 타입의 컬럼에서 datetime 타입으로 변환
# to_datetime( ) : 시간 형식의 object 타입의 컬럼을 datetime 타입으로 변환 disney["date_added"] = pd.to_datetime(disney['date_added']) disney["date_added"]
타입이 변환된 disney의 date_added 변수를 이용하여 month_added(개봉한 월) 변수 생성
# month_added 변수를 생성하여 개봉한 월 정보 저장 # .dt.month : datetime에서 월 정보 추출 disney['month_added'] = disney['date_added'].dt.month disney.head(3)
월별 Movie & TV show 수치 시각화
넷플릭스 브랜드 상징 색깔 시각화
sns.palplot(['#0E0F37','#335B92','#C6E8E5']) plt.title("Disney brand palette ", loc='left', fontfamily='serif', fontsize=15, y=1.2) plt.show()

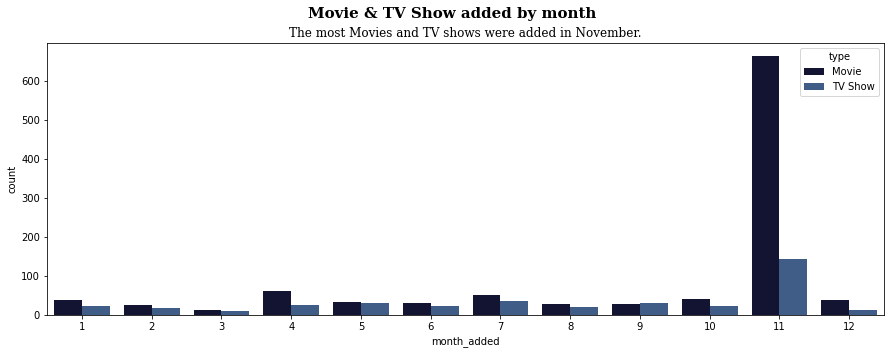
countplot 함수를 이용한 월별 Movies & TV shows 수치 시각화
# plt.figure 함수를 이용하여 figsize를 (15,5) 설정 plt.figure(figsize=(15, 5)) # countplot( ) : 각 범주에 속하는 데이터의 개수를 막대 그래프 시각화 # hue : 특정 열 데이터로 색상을 구분하여 출력 # sns.countplot 함수를 이용하여 월별 Movies & TV shows 수치 시각화하게끔 인수 삽입하여 완성하기 sns.countplot(x='month_added', hue='type', palette=['#0E0F37', '#335B92'], data=disney) # plt.suptitle : 전체 플롯의 제목 # suptitle에는 'Movie & TV Show added by month' 입력하여 그래프 전체 제목 출력하기 plt.suptitle('Movie & TV Show added by month', fontfamily='serif', fontsize=15, fontweight='bold') # plt.title : 서브 플롯의 제목 # title에는 'The most Movies and TV shows were added in November.' 입력하여 그래프 소제목 출력하기 plt.title('The most Movies and TV shows were added in November.', fontfamily='serif', fontsize=12) plt.show()
title 변수를 이용한 워드 클라우드 구현
# 워드 클라우드 생성에 필요한 모듈 선언 : from wordcloud import WordCloud # 워드 클라우드를 원하는 형태로 그리기 위해 그림을 불러오는 패키지 선언 : from PIL import Image import matplotlib.pyplot as plt from wordcloud import WordCloud from PIL import Image
Disney 데이터의 title 변수를 이용한 워드 클라우드 생성
plt.figure(figsize=(20, 10)) # wordcolud에서 작동할 수 있도록 데이터프레임을 list로 1차 변환시키고 str(문자열)로 2차 변환 text = str(list(disney['title'])) # mask : 단어를 그릴 위치 설정, 흰색(#FFFFFF) 항목은 마스킹된 것으로 간주 mask = np.array(Image.open('/content/disney.jpg')) # plt.matplotlib.colors.LinearSegmentedColormap.from_list( ) : 컬러맵 생성 cmap = plt.matplotlib.colors.LinearSegmentedColormap.from_list("", ['#0E0F37', '#335B92']) # WordCloud( ).generate(text) : 선언해준 text에서 wordcloud를 생성 wordcloud = WordCloud(background_color = 'white', width = 1000, height = 1000, max_words = 500, mask = mask, colormap=cmap).generate(text) # title로 'Keywords in the title of Movies and TV shows' 출력 plt.suptitle('Keywords in the title of Movies and TV shows', fontweight='bold', fontfamily='serif', fontsize=20) # plt.imshow( ) : array에 색을 채워서 이미지로 표시 plt.imshow(wordcloud) # plt.axis('off') : 축 삭제 plt.axis('off') plt.show()


가보자가보자~