Abstract
GLM 같은 linear model의 경우 feature 간 cross product를 통해 쉽게 memorization 특성을 얻을 수 있지만, generalization을 얻기 위해서는 feature engineering이라는 노력을 들여야한다.
반면 DNN 모델의 경우 generalization에 이점(deep)이 있다.
그렇기에 둘을 합친 wide and deep learning model을 제안하고 이를 구글 플레이 추천에 적용해보았다.
Recommender system overview
- 추천 시스템은 search ranking system으로 바라볼 수 있다.
- query : user 와 contextual information
- output : 클릭할 만한 아이템 리스트
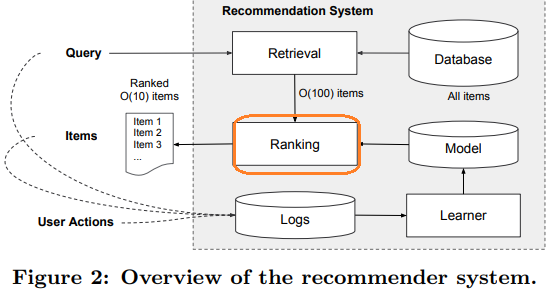
- 그림과 같이 사용자의 query가 들어오면 모든 앱 (백만 개)에 대해 순위를 매기기 어렵기때문에 retrieval 단계에서 query와 맞는 앱을 추려 후보 목록을 ranking 단계로 보낸다.
- ranking 단계는 user 및 contextual 정보를 활용해서 후보 목록의 앱을 사용자가 클릭할 확률이 높은 순으로 정렬 - 이때 wide and deep learning model 적용
Model
-
wide model과 deep model 비교에 앞서 공통 구조는
input으로 사용자가 설치했던 앱과 이후 클릭할 지 궁금한 앱이 들어가고
ouput으로는 사용자가 해당 앱을 클릭할 지 말지에 대한 확률이 나오는 구조 -
물론 학습시에는 impression app과 그렇지 않은 앱 데이터 모두 사용.
wide model
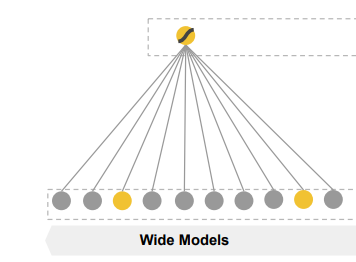
- regression과 같은 linear model은 binarized sparse features with one-hot encoding을 input으로 받으며 학습된다.
- binary feature 예시로는 "user installed app == 넷플릭스" 라는 feature는 사용자가 넷플릭스를 설치했으면 1, 그렇지 않으면 0을 갖는다.
- memorization은 이러한 binary feature들을 cross-product 하면서 실현된다.
- "user installed app == 넷플릭스" 와 "user impression app == 멜론" 두 binary feature를 cross product transformation 시키면 두 feature값이 모두 1일때 1을 갖는 feature를 만들 수 있음.
- 이렇게 되면 모델은 두 feature의 동시 출현(co - occurrence)를 보며 target에 대한 두 feature의 상관관계를 학습할 수 있다.
- generalization은 feature engineering을 통해 얻을 수 있다.
- "user installed category == 비디오" 와 "user impression category == 음악" 를 cross product transformation한 후 input으로 넣어주면 돼 -> 귀찮음... 그래서 deep model 제안
deep model
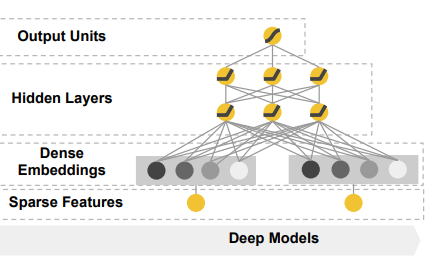
- nerual network의 경우 categorical 변수는 동일한 latent space의 embedding vector로 mapping된 후 input으로 들어간다. (반드시는 아님!)
- "user installed app == 넷플릭스" 와 "user impression app == 멜론" 의 경우 latent space에서 넷플릭스를 표현하는 embedding vector, 멜론을 표현하는 embedding vector로 mapping 된 후 hidden layer에 들어간다.
- 이후 "user installed app == 왓챠" 와 "user impression app == 바이브" 데이터가 input으로 들어오면 마찬가지로 latent space에서 넷플릭스를 표현하는 embedding vector, 멜론을 표현하는 embedding vector로 mapping 된 후 hidden layer에 들어간다.
이때 latent space에서 왓챠를 표현하는 embedding vector는 넷플릭스를 표현하는 embedding vector와 가까이 위치하고, 멜론을 표현하는 embedding vector는 바이브를 표현하는 embedding vector와 가까이 위치하게 된다. '즉, 모델은 자연스레 비디오 관련 앱을 설치한 사용자는 음악관련 앱을 클릭할 것이다' 라는 generalization을 학습한다.
정리하면, 넷플릭스를 설치하고, 멜론을 클릭한 사용자의 데이터를 가지고
- wide model은 동시 출현으로 해당 데이터를 암기하여 사용자의 고유 특성이라 학습하고,
- deep model은 사용자의 고유 특성이라 해석하지 않고, 전체 사용자들은 비디오관련 앱을 설치한 후에 음악관련 앱을 클릭하는 경향성을 학습한다.
- ex) 넷플릭스를 설치하고, 바이브를 클릭할지 말지에 대한 확률에 대해 wide model보다 deep model이 큰 값을 부여.
두 모델의 단점은
wide model의 경우 기존 데이터를 가지고 암기하다보니 새로운 조합이 왔을 때 잘 예측할 수 없다.
deep model의 경우 과도한 generalization을 통해 overfitting이 발생할 수 있다.
그렇기에 두 모델을 합친 wide and deep model로 두 모델의 장점을 취하고 약점은 보완하겠다!
wide and deep model
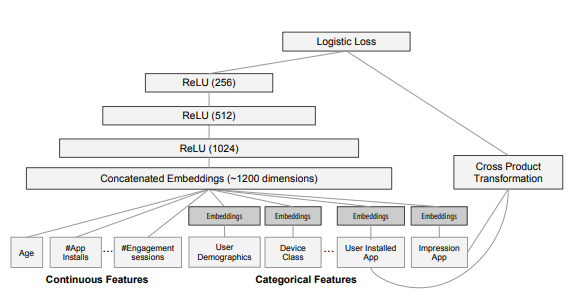

- 모델 구조는 심플 -> wide model과 deep model을 concatenate!
