1. 등장 배경
기존 DNN(Deep Neural Network)의 문제점.
- 이미지 처리시 입력 뉴런의 수와 파라미터 수가 급격하게 증가됨.
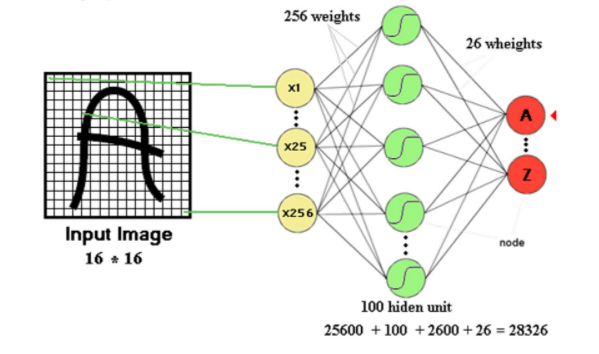
- 기본적으로 1차원 형태의 입력 데이터를 사용함. -> 1차원 형태의 입력 데이터를 사용하기 때문에 직렬화를 수행하면서 픽셀들의 상관관계를 잃게 됨.
-> 위와 같은 문제점 때문에 CNN(Convolutional Neural Networks)가 등장하게 됨.
2. Convolution 개념
이미지 2개를 합친다할때, 하나를 y축 기준으로 대칭 시킨 후 차례차례 곱해 나가는 것.
- f함수(이미지 1)와 g함수(이미지 2)가 있음.
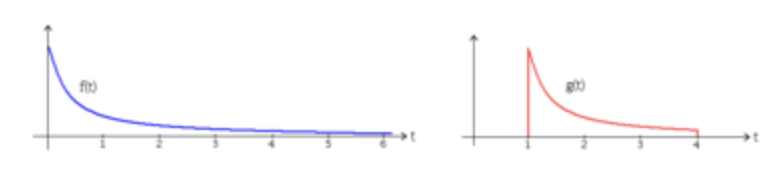
- g함수를 y축 기준으로 대칭시킨 후 차례차례 곱해나감.
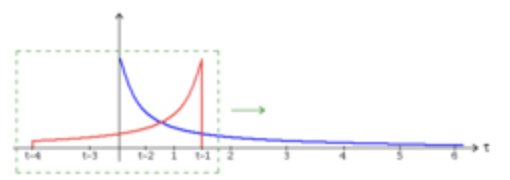
- 식으로 정리하면 아래와 같음.
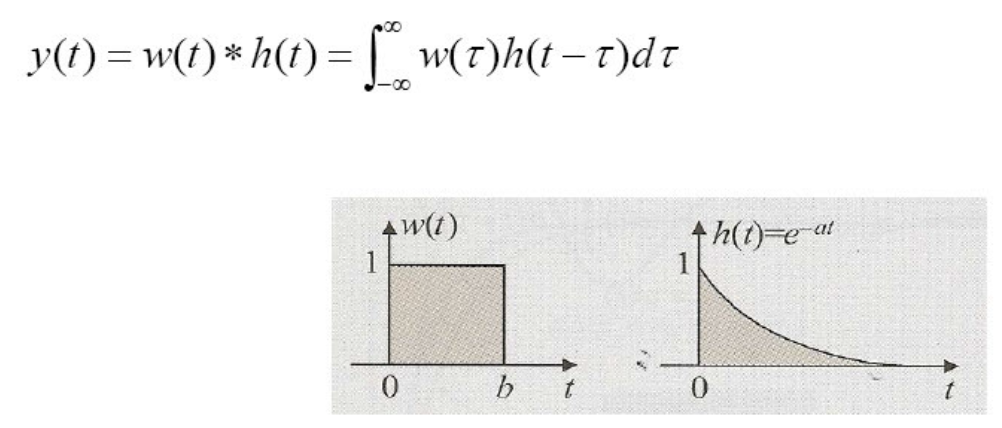
이런 원리를 토대로 Neural Network의 이미지 학습에도 적용한 것이 "CNN"이다!
3. 기초 용어
📌 합성곱 층(Convolutional Layer)
앞서 언급한 convolution 과정을 이미지로 표현하면 아래와 같다.
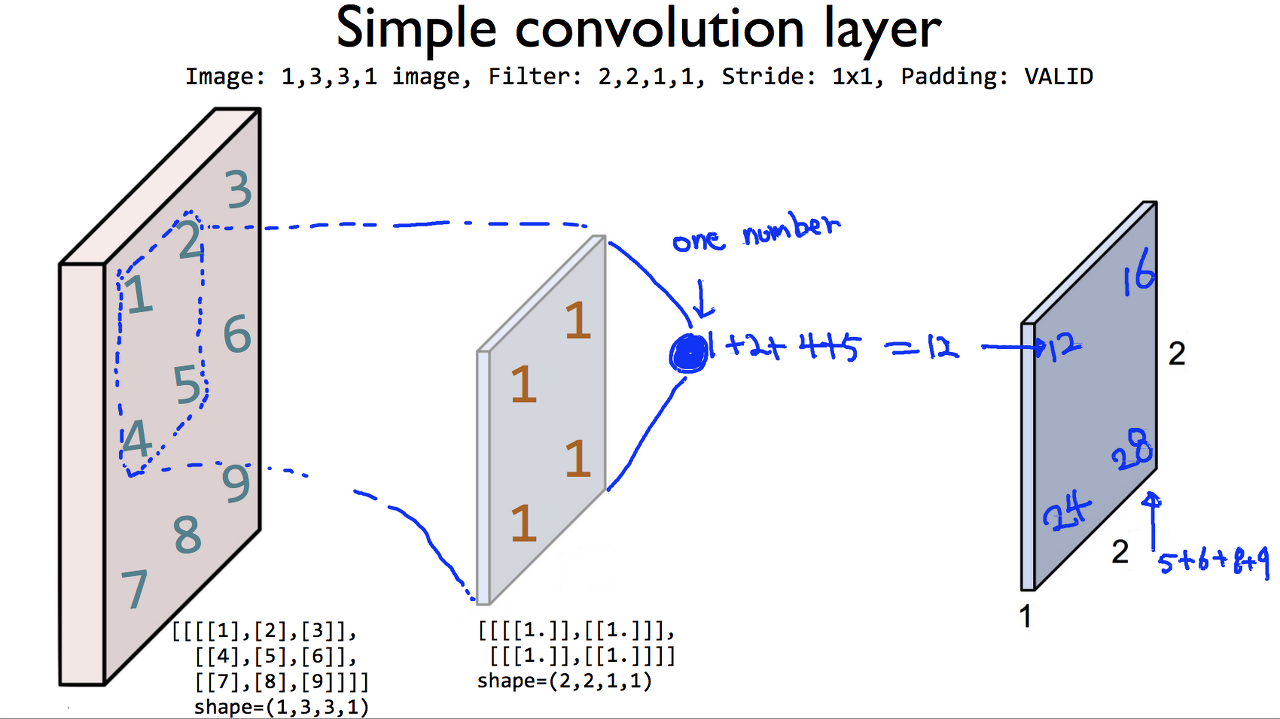
맨왼쪽 그림이 이미지, 중간 이미지는 [1 1, 1 1] 필터
필터와 각 위치에 해당하는 값들을 모두 곱하고 더해서 맨오른쪽 이미지처럼 만들어 주게 된다.
일반화시키면 아래와 같이 표현할 수 있다.
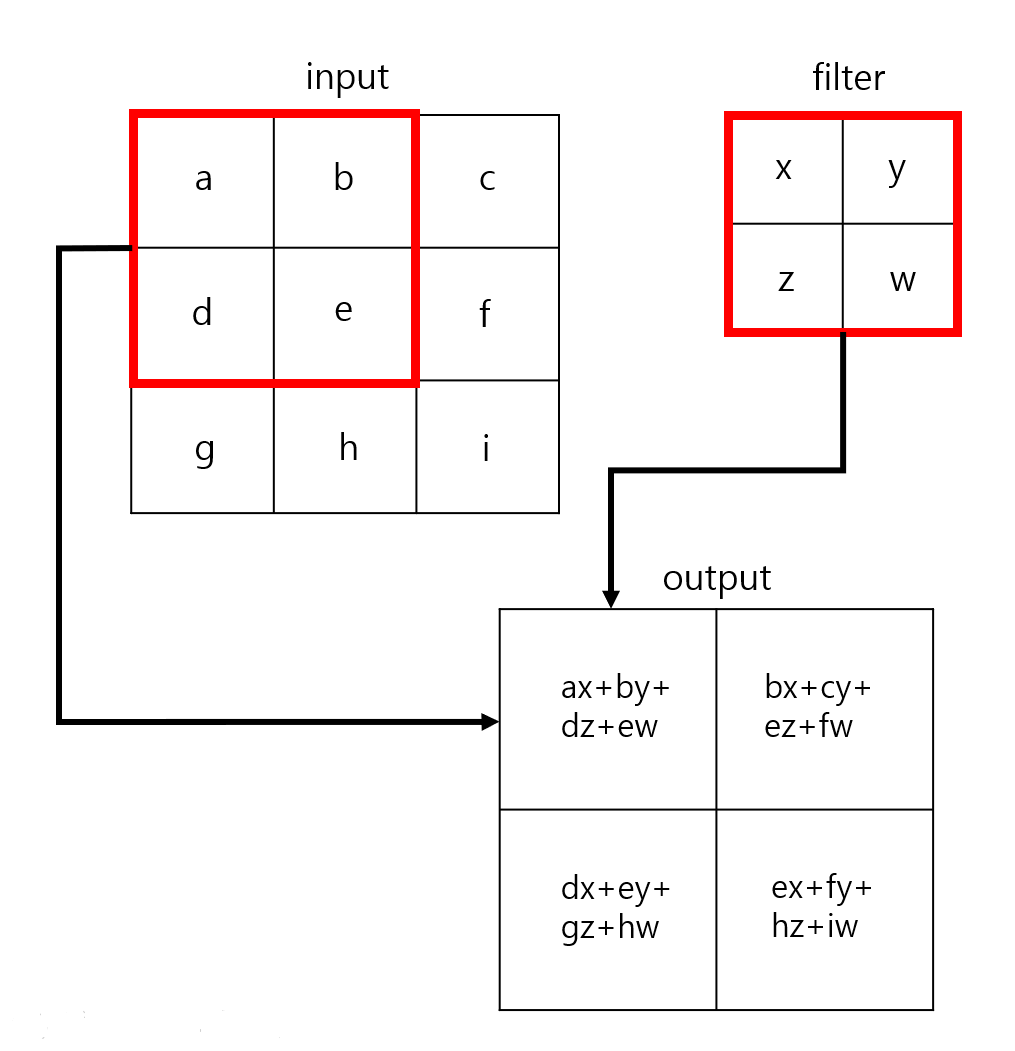
그런데, 이렇게 되면 기존의 3X3 이미지가 2X2로 줄어들게 된다.
정보의 손실이 일어남과 동시에 특징들을 뭉뚱그려서 더 작은값으로 저장하게 되는 것.
-> 이 "정보의 손실" 이라는것을 최소화 하고자 "Zero Padding"을 사용함.
🌱 제로 패딩 (zero padding)
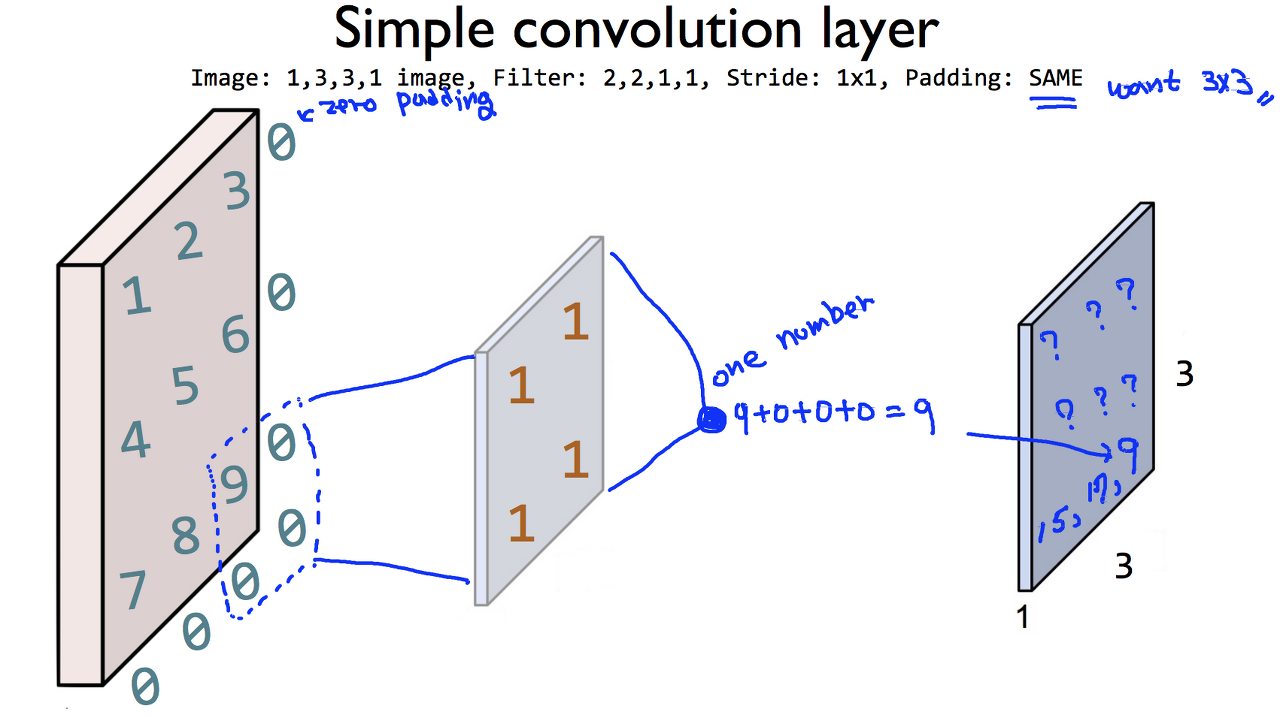
이렇게, 학습하는 이미지의 끝자락 부분을 0으로 채워(padding)서, 필터를 통과시킨 후에도 3X3의 사이즈를 유지하도록 하는 것.
padding을 하면 데이터의 손실을 줄여줄 수 있지만, 원래 데이터에 없던 데이터를 붙였기 때문에 noise가 발생. -> noise의 영향을 최소화하기 위해 padding 값을 0으로 하는 것.
🌱 filter와 feature map
여기서, filter가 무엇인가?
kernel이라고도 부르며, 층의 전체 뉴런에 적용된 하나의 필터(filter)는 하나의 특성맵(feature map)을 만듦.
합성곱 층은 여러 가지 필터를 가지고 필터마다 하나의 특성 맵을 출력.
하나의 합성곱 층이 입력에 여러 필터를 동시에 적용하여 입력에 있는 여러 특성을 감지할 수 있음.
아래 그림은 여러 가지 특성 맵으로 이루어진 합성곱 층과 3개의 컬러 채널임.
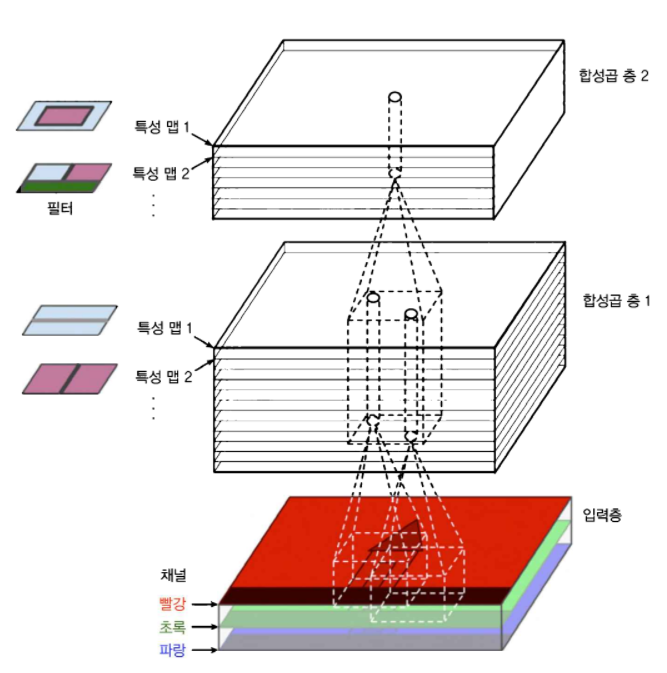
3D에서 특성맵들이 만들어지는 과정은 아래와 같음.
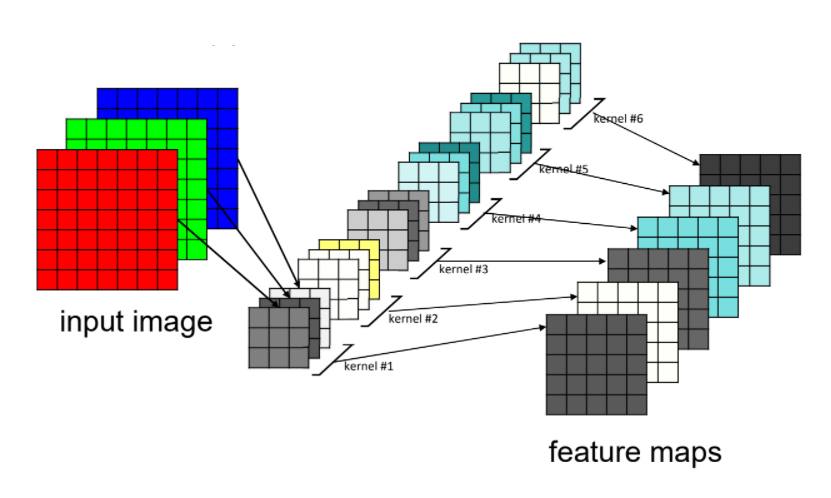
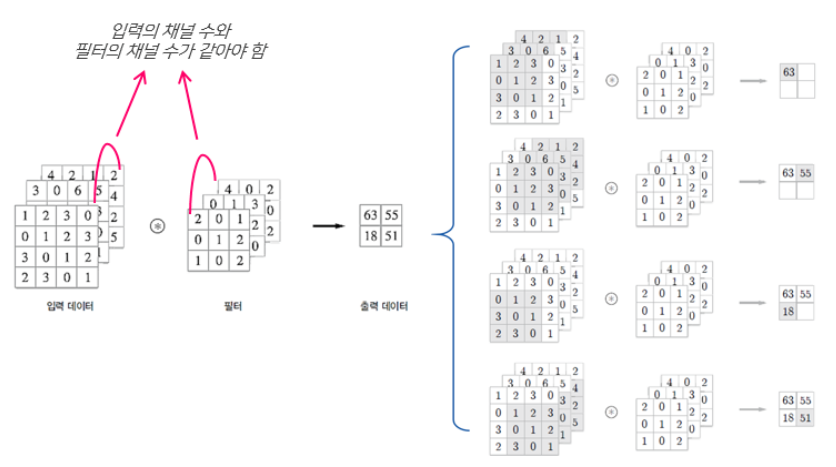
3개 채널의 입력 데이터와 3개 채널의 필터를 각각 Convolution하고 나온 3개의 출력값을 더함.
이렇게 나온 출력 데이터 = 하나의 feature map이 되는 것!!!
🌱 stride
filter가 이동하는 간격을 stride라고 함. 이 값은 임의로 지정할 수 있음.
🌱 출력 데이터의 크기
출력 데이터의 크기는 입력 데이터의 크기, 필터의 크기, stride 값, padding 값에 의해 결정됨.

📌 풀링(Pooling)
-> Max-pooling과 Average-pooling이 있음.
Max-pooling: 해당 구역의 최대값을 찾는 방식.
Average-pooling: 해당 구역의 평균값을 계산하는 방식.
예를 들어, max-pooling은 아래와 같이 [1,2,0,1]중 가장 큰 2가 선택되는 방식이다.
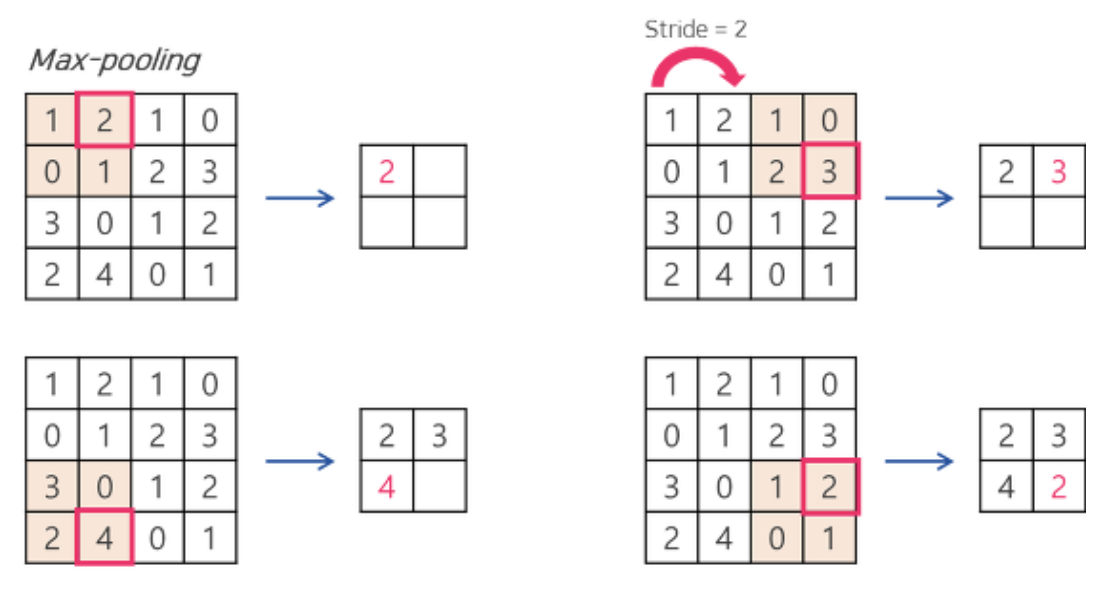
위와 같이 풀링은 정보 손실이 엄청나지만, 하는 이유가 있다.
-
overfitting 방지하기 위해
ex) 이미지: 64x64, 필터: 8x8이 300개, stride: 1, padding:0 이라면?
한 개의 특성맵에 (64-8+1)x(64-8+1) = 3349개의 feature가 존재, 이러한 특성맵이 합성곱 층에 300개 존재하므로 총 974,700개의 특성이 존재하게 됨.
이렇게 feature가 많다면 overfitting이 생길 가능성이 높음.
이를 pooling을 통해 데이터의 크기를 줄여 조절하는 것. -
평행이동이나 변형에 대해서 일정 수준의 불변성을 갖기 위해
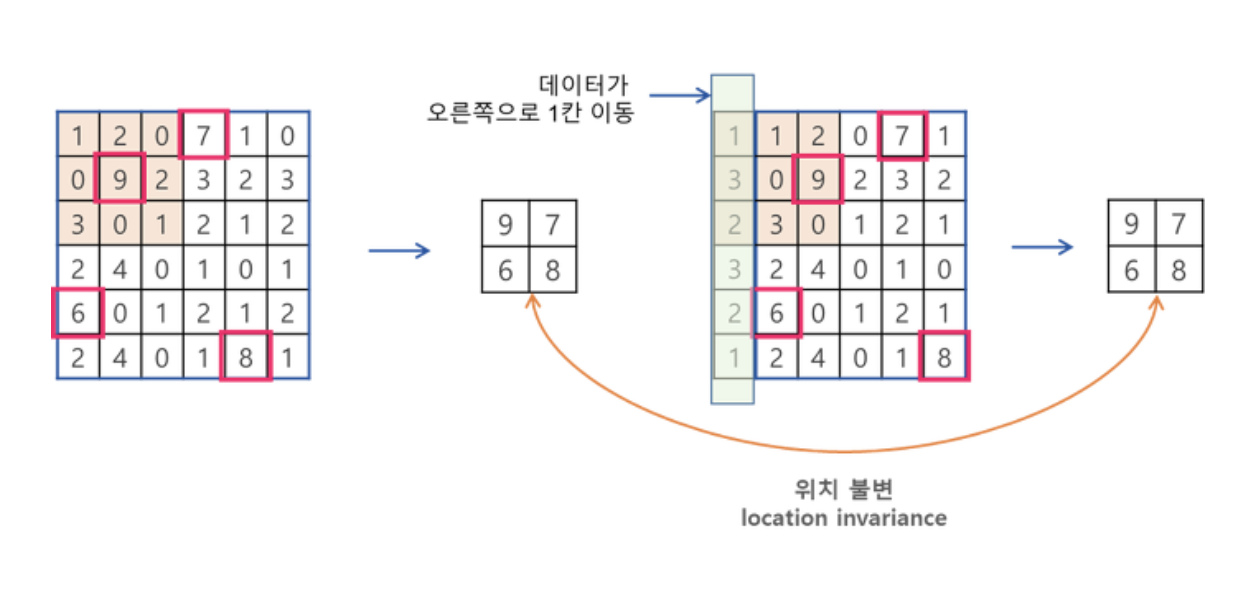 데이터가 오른쪽으로 1칸 이동하고 Max-pooling을 해도, 원래 데이터에서 Max-pooling을 한 결과와 동일함. -> 어떤 물체의 구체적인 위치가 아닌 존재 여부가 더 중요할 땐 이런 일정 수준의 이동에 대한 불변성이 유용하게 작용!
데이터가 오른쪽으로 1칸 이동하고 Max-pooling을 해도, 원래 데이터에서 Max-pooling을 한 결과와 동일함. -> 어떤 물체의 구체적인 위치가 아닌 존재 여부가 더 중요할 땐 이런 일정 수준의 이동에 대한 불변성이 유용하게 작용!
4. CNN의 전체 구조 및 과정
Convolution을 통한 filtering과 max pooling을 반복하여, 중요한 특징을 정제한 후, classification 하는 것.
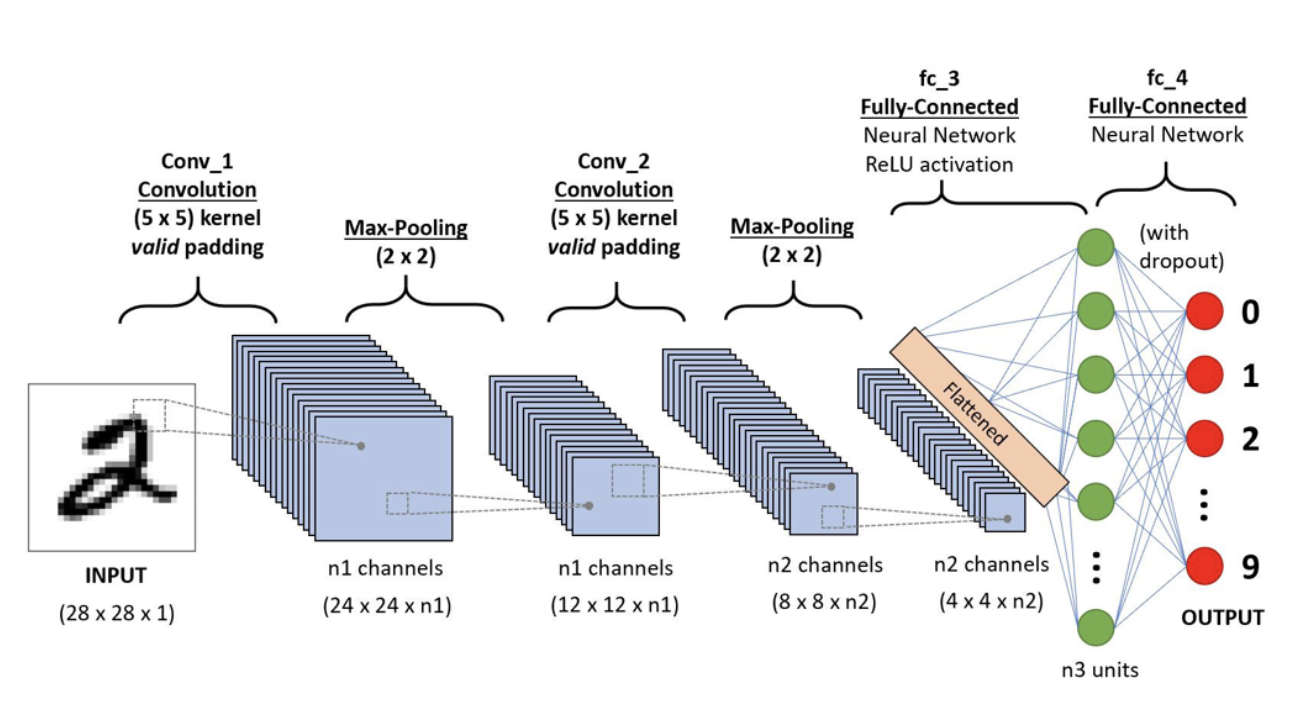
입력 이미지를 Convolution과 Max-Pooling을 통해 깊이를 깊게하고 size를 줄여준 후, 4x4xn2의 데이터를 1차원의 데이터로(Flatten) 만든다. -> 이렇게 1차원으로 만든 데이터를 DNN 네트워크를 통해 최종 output을 출력한다!
5. pytorch 코드
✔️ 필요한 라이브러리 가져오기
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.init as init
import matplotlib.pyplot as plt
import torchvision.datasets as dset
import torchvision.transforms as transforms
from torch.utils.data import DataLoaderMNIST라는 숫자 데이터셋 사용을 위해, torchvision 라이브러리를 미리 다운로드 하기.
✔️ 단계 1: 데이터 로딩 및 전처리
batch_size = 256
learning_rate = 0.0002
num_epoch = 10
mnist_train = dset.MNIST("./",train=True, transform = transforms.ToTensor(),target_transform=None, download = True)
mnist_test = dset.MNIST("./", train=False, transform = transforms.ToTensor(), target_transform=None, download = True)
train_loader = torch.utils.data.DataLoader(mnist_train,batch_size=batch_size,shuffle=True,num_workers=2,drop_last=True)
test_loader = torch.utils.data.DataLoader(mnist_test,batch_size=batch_size,shuffle=False,num_workers=2,drop_last=True)- batch_size = 256: 한번에 학습하는 이미지의 수. -> 256개씩 묶어서 학습 진행.
DataLoader 부분에서
- batch_size선언, shuffle : 데이터를 무작위로 섞을때
- num_workers : 데이터를 묶을때 사용하는 프로세스 갯수
- drop_last : 묶고 남은 자투리 데이터들은 버릴지 말지
✔️ 단계 2: CNN 모델 정의
class CNN(nn.Module):
def __init__(self) :
super(CNN,self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(1,16,5), # 이미지 크기: 28x28 -> 24x24
nn.ReLU(),
nn.Conv2d(16,32,5), # 이미지 크기: 24x24 -> 20x20
nn.ReLU(),
nn.MaxPool2d(2,2), # 이미지 크기: 20x20 -> 10x10
nn.Conv2d(32,64,5), # 이미지 크기: 10x10 -> 6x6
nn.ReLU(),
nn.MaxPool2d(2,2) # 이미지 크기: 6x6 -> 3x3
)
self.fc_layer = nn.Sequential(
nn.Linear(64*3*3,100),
nn.ReLU(),
nn.Linear(100,10)
)
def forward(self,x):
out = self.layer(x)
out = out.view(batch_size, -1) # 전결합층을 위해서 Flatten하는 과정.
out = self.fc_layer(out)
return outsuper(CNN,self).__init__()Super class로 지금 작성하고있는 클래스 자체를 초기화.nn.Conv2dConvolution Filtering이라는 Signal Processing적인 방법으로 이미지를 처리 하는것nn.Conv2d(1,16,5)
1: 입력 채널의 수. 흑백이미지라면 1
16: 출력 채널의 수. 이 레이어에서 생성된 필터의 수.
5: 합성곱 커널(필터)의 크기. 5x5 크기의 필터를 사용.
=> 1개 필터짜리 입력을 받아, 16개의 필터로 5x5 필터를 filtering 하는 것.
=> Kernel size가 5x5 인경우, Convoltuion을 하게 되면 4개의 pixel이 사라지게 되어(28x28)의 input 이미지가 (24x24)가 됨.
=> 이런식으로 CNN은 이미지의 사이즈를 줄여가며 강한 특징만을 추려나감.
=> MaxPooling을 중간중간 섞어줌으로써, Convolution보다 더욱 강하게 Feature들을 뽑아냄.self.layerCNN이 끝난 이후, 최종적으로 나오는 결과물은 [batch_size,64,3,3]
256개의 이미지 묶음씩 64개의 필터, (3x3)의 이미지가 남게 되는것으로, pixel갯수로 따지면 64*3*3이 나옴.nn.Linear(100,10)
64*3*3의 결과값을 nn.Linear(100,10)을 통해 최종적으로 10개의 값이 나오게 함. => 내가 넣은 이미지가 0~9(10개)중 어떤것일지에 대한 각각의 확률def forward(self,x)
CNN함수의 전체적인 그림으로, Conv2d -> Linear Regression -> 추정
✔️ 단계 3: 모델, 손실 함수, 최적화 기법 초기화
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = CNN().to(device)
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=learning_rate)✔️ 단계 4: 모델 훈련
loss_arr = []
for i in range(num_epoch):
for j,[image,label] in enumerate(train_loader):
x = image.to(device) # mnist 학습용 data(28x28)
y_ = label.to(device) # 각각의 data들이 0~9중 어떤숫자인지
optimizer.zero_grad() #optimizer 초기화
output = model.forward(x) # CNN 학습 시작.
loss = loss_func(output,y_) #학습해서 추정해낸 값과, 실제 라벨된 값 비교
loss.backward() #오차만큼 다시 Back Propagation 시행
optimizer.step() #Back Propagation시 ADAM optimizer 매 Step마다 시행
if j % 1000 == 0 : # 1000 미니 배치마다 출력.
print(loss)
loss_arr.append(loss.cpu().detach().numpy())loss = loss_func(output,y_)모델의 출력과 정답 레이블을 비교하여 손실을 계산한다. loss_func은 nn.CrossEntropyLoss()로, 크로스 엔트로피 손실 함수로 설정돼 있으므로, 모델이 예측한 확률 분포와 실제 레이블 간의 차이를 측정.loss.backward()역전파를 수행하여 각 파라미터에 대한 손실의 기울기(gradient)를 계산. 이는 모델의 파라미터를 업데이트하는데 사용되는 것.optimizer.step()역전파로 계산된 기울기를 사용하여 모델 파라미터를 조정. -> 만약 이 부분을 생략한다면 모델의 파라미터가 업데이트되지 않으며, 따라서 학습이 진행되지 않을 것- enumerate(train_loader)는 index,[image,label] 로 이루어져있다. 학습을 진행하며 index 1000번마다 loss 배열에 loss 값을 추가한다.
✔️ 단계 5: 성능 평가
correct = 0
total = 0
with torch.no_grad(): # 학습을 진행하지 않을 것이므로 torch.no_grad()
for image,label in test_loader :
x = image.to(device)
y_ = label.to(device)
output = model.forward(x)
_,output_index = torch.max(output,1)
total += label.size(0)
correct += (output_index == y_).sum().float()
print("Accuracy of Test Data : {}".format(100*correct/total))참고한 자료 목록
