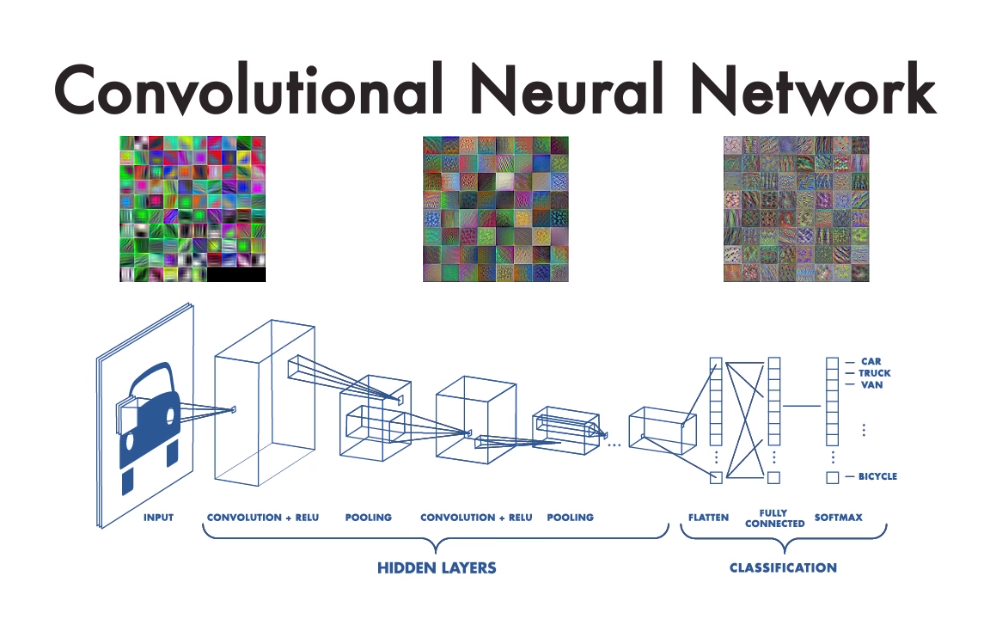
이번 시간엔 이미지 인식의 꽃, CNN에 대해서 알아보겠다.
True color, Grey color
CNN에 알기전, True color와 Grey color에 대해서 알아보자.
True color는 이름부터 짐작할 수 있을 것이다.
True color
- 컬러 이미지를 나타낼 수 있다.
- RGB 사용함.
- 이 방법에서는 각 픽셀이 RGB 표현하게 됨.
- 각 픽셀이 256가지 색상을 나타낼 수 있음
Grey color
- 흑백 이미지를 나타낼 때 사용.
- 8비트 그레이스케일을 사용함.
- 각 픽셀은 0부터 255까지의 값으로 나타나게 됨.
CNN을 왜 사용할까?
CNN은 주로 이미지와 관련된 작업에 사용되는 신경망이다. CNN은 이미지 처리에 특화된 구조와 알고리즘을 갖추고 있어서 이미지 인식, 객체 감지, 분할 등의 작업에서 뛰어난 성능을 보인다.
또한 다음과 같은 장점을 가지고 있으므로 사용된다.
공간 구조 인식
CNN은 이미지의 공간적인 구조를 인식하는 데 탁월한 성능을 보인다. 이미지에서 특징을 추출하기 위해 컨볼루션 계층을 사용하며, 이러한 계층은 이미지의 지역 패턴을 인식하고 전체 이미지에 적용할 수 있다.
특징 추출
CNN은 다른 종류의 이미지 특징, 예를 들어 선, 모서리, 질감 등을 자동으로 학습할 수 있는데, 이를 통해 복잡한 이미지에서 유용한 정보를 추출하여 더 높은 수준의 추론과 판단을 할 수 있다.
파라미터 공유
CNN은 이미지의 지역적인 특징을 공유 파라미터로 인식하며, 이는 신경망의 학습 파라미터 수를 크게 줄여줍니다. 이는 학습 과정을 더 효율적으로 만들어줍니다.
CNN에서 convolution layer 동작원리
CNN은 이미지의 특징을 추출하는 부분과 클래스를 분류하는 부분으로 나뉘어지는데, 특징 추출 영역에서 Convolution Layer가 여러 겹을 쌓는 형태로 구성된다.
Convolution Layer는 입력된 데이터에 필터를 적용시킨 후, 활성화 함수를 반영한다.
Convolution Layer의 역할은 뭘까?
1. Color 이미지를 3D로
이미지 데이터는 그림 4와 같이 높이X너비X채널의 3차원 텐서 (tensor)로 표현될 수 있다. 만약, 이미지의 색상이 RGB 코드로 표현되었다면, 채널의 크기는 3이 되며 각각의 채널에는 R, G, B 값이 저장된다.
2. Filter 적용
하나의 합성곱 계층에는 입력되는 이미지의 채널 개수만큼 필터가 존재하며, 각 채널에 할당된 필터를 적용함으로써 합성곱 계층의 출력 이미지가 생성된다.
예를 들어, 높이X너비X채널이 4X4X1인 텐서 형태의 입력 이미지에 대해 3X3 크기의 필터를 적용하는 합성곱 계층에서는 이미지와 필터에 대한 합성곱 연산을 통해 2X2X1 텐서 형태의 이미지가 생성된다. 그리고 한 번씩 합성곱을 통해 생성된 행렬 형태의 이미지에 bias라는 스칼라값을 동일하게 더하도록 구현되기도 한다.
3. Stride
이미지에 대해 필터를 적용할 때는 필터의 이동량을 의미하는 스트라이드(stride)를 설정해야한다. CNN을 구현할 때 보통 1로 설정된다고 한다.
4. Padding
입력 이미지에 대해 합성곱을 수행하면, 출력 이미지의 크기는 입력 이미지의 크기보다 작아지게 된다. 4x4 였던 입력 이미지가 합성곱을 수행하여 2x2 의 출력 이미지의 크기를 갖는다. 그러므로 합성곱 계층을 거치면서 이미지의 크기는 점점 작아지게 되고, 이미지의 가장자리에 위치한 픽셀들의 정보는 점점 사라지게 된다. 이러한 문제점을 해결하기 위해 이용되는 것이 패딩 (padding)이다.
패딩은 입력 이미지의 가장자리에 특정 값으로 설정된 픽셀들을 추가함으로써 입력 이미지와 출력 이미지의 크기를 같거나 비슷하게 만드는 역할을 수행한다. 이미지의 가장자리에 0의 값을 갖는 픽셀을 추가하는 것을 zero-padding이라고 하며, CNN에서는 주로 이러한 zero-padding이 이용된다.
pooling layer 동작원리
Pooling Layer는 입력된 특징 맵을 작은 영역으로 나누고, 각 영역에서 특정 값을 선택하여 특징 맵의 크기를 줄이는 역할을 한다. 최대 풀링은 각 영역에서 가장 큰 값을 선택하고, 평균 풀링은 각 영역의 평균 값을 계산한다. 이를 통해 공간적인 정보를 보존하면서 계산 효율성을 높이고, 불필요한 세부 정보를 제거한다.
flatten 이란?
다차원 배열을 1차원으로 변환하는 작업을 의미한다. 이를 통해 다차원 배열의 구조를 평탄화하여 입력으로 사용할 수 있는 형태로 변환하는 것이다.
CNN예제 코드 작성 및 첨부
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
import numpy as np
# 데이터를 불러옵니다.
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32') / 255
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32') / 255
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# 컨볼루션 신경망의 설정
model = Sequential()
model.add(Conv2D(32, kernel_size=(3,3), input_shape=(28,28,1), activation='relu'))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
# 모델의 실행 옵션을 설정합니다.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델 최적화를 위한 설정 구간입니다.
modelpath = "./MNIST_CNN.hdf5"
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, save_best_only=True)
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=10)
# 모델을 실행합니다.
history = model.fit(X_train, y_train, validation_split=0.25, epochs=30, batch_size=200, verbose=0, callbacks=[early_stopping_callback, checkpointer])
# 테스트 정확도를 출력합니다.
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, y_test)[1]))
# 검증셋과 학습셋의 오차를 저장합니다.
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
# 그래프로 표현해 봅니다.
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
# 그래프에 그리드를 주고 레이블을 표시하겠습니다.
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()CNN 활용
1.이미지 생성 및 스타일 변환
CNN은 이미지 생성 작업에도 사용된다. 생성적 적대 신경망(GAN)을 사용하여 새로운 이미지를 생성하거나, 스타일 변환을 수행하여 이미지에 다른 스타일을 적용할 수 있다. 예를 들어, 딥페이크 이미지 생성이나 예술 작품 스타일의 적용 등이 있겠다.
2.음성 처리
CNN은 음성 인식과 음성 분류 작업에도 사용되기도 한다. 오디오 신호를 입력으로 받아 음성 명령 인식, 화자 분류, 음악 장르 분류 등을 수행할 수 있다.
3.자연어 처리
CNN은 자연어 처리 작업에서도 활용된다. 문장 분류, 감성 분석, 텍스트 분류 등의 작업에서 텍스트 데이터의 특징을 추출하는 데 사용될 수도 있다. 예를 들어, 트위터 텍스트 분류에서 긍정/부정 감성을 판별하거나, 스팸 메일 필터링 등에 활용된다.
