K 교차검증?
k 교차검증은 가장 널리 사용되는 교차 검증 방법의 하나로, 데이터를 k개로 분할한 뒤, k-1개를 학습용 데이터 세트로, 1개를 평가용 데이터 세트로 사용하는데, 이 방법을 k번 반복하여 k개의 성능 지표를 얻어내는 방법을 말한다.
어떻게?
from sklearn.model_selection import KFold
k = 5
kfold = KFold(n_splits=k, shuffle=True)
acc_score = []
for train_index, test_index = in kfold.split(X):
X_trian, X_test = X.iloc[train_index, :], X.iloc[test_index, :]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
다음과 같이 k 교차검증을 사용할 수 있다.
몇 개의 파일로 나눌 것인지 정해 k에 값을 넣고, 사이킷런의 KFold() 함수를 불러와준다. 샘플이 어느 한쪽에 치우치지 않도록 shuffle 옵션을 True로 설정해준다. 정확도가 채워질 acc_score이라는 이름의 빈 리스트를 준비하고, split()에 의해 k개의 학습셋, 테스트셋으로 분리되며 for문에 의해 k번 반복한다.
특징
K 교차검증은 하이퍼파라미터나 모델의 최적화 시, 최적의 조건을 찾는 데에 활용할 수 있다. 또 모든 데이터를 평가와 학습에 사용할 수 있어 알고리즘의 일반화 정도를 평가할 수 있다.
업그레이드
https://velog.io/@digyrh456789/Train-set-Test-set <- 앞 글
앞 글에서 사용했던 Train set과 Test set 코드를 K 교차검증 코드로 업그레이드 해보겠다.
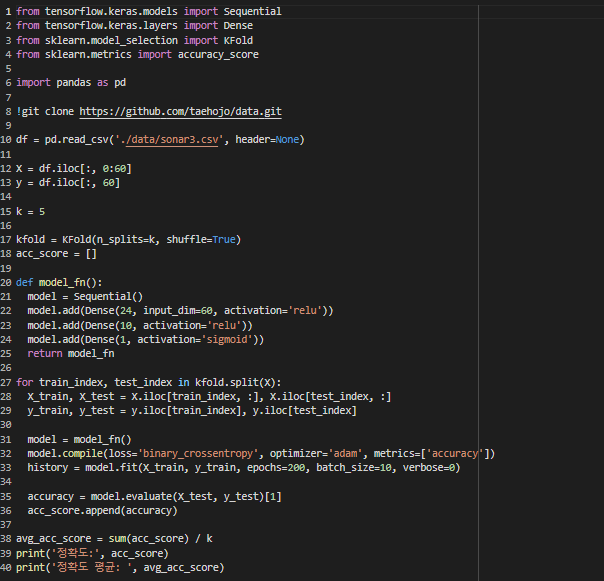
다음과 같이 데이터를 불러오고 몇 겹으로 나눌 것인지 정한다. 그리고 정확도가 채워질 빈 리스트를 준비하고 k 교차검증을 위해 k번의 학습을 실행하고, for문에 의해 k번 반복하면 split()에 의해 k개의 학습셋, 테스트셋으로 분리된다. 그리고 k번 실시된 정확도의 평균을 구한다.
마지막으로 결과물을 출력 해보면 끝이다.
