딥러닝에서 신경망 모델을 학습하고 평가하기 위해 dataset을 필요로 한다.
이때 dataset을 성질에 맞게 보통 다음 3가지로 분류한다.
- Train set
- Validation set
- Test set
오늘은 Train set과 Test set에 대해 알아볼 것이다.
Train set
모델을 학습하기 위한 dataset이다. 한 가지 계속 명심해야할 중요한 사실은
"모델을 학습하는데에는 오직 유일하게 Train dataset만 이용한다"
보통 train set을 이용해 각기 다른 모델을 서로 다른 epoch로 학습을 시킨다.
Test set
test set은 학습과 검증이 완료된 모델의 성능을 평가하기위한 dataset입니다.
Test set은 학습에 전혀 관여하지 않고 오직 '최종 성능'을 평가하기 위해 쓰입니다.
Trainset과 Test Set 사용
사이킷런의 train_test_split() 함수를 이용해서 사용해보겠습니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True)
다음과 같이 사용할 수 있습니다. 그리고 만들어진 모델을 이용하려면 model.evaluate()함수를 사용하면 됩니다.
Train 예측률, Test 예측률
제가 앞에서 지금까지 정리해왔던 글들에서는 테스트셋을 만들지 않고 학습을 해 왔습니다. 그런데도 매번 정확도를 계산할 수 있었습니다. 이런것들이 가능한 이유는 지금까지 데이터에 들어 있는 모든 샘플을 그대로 테스트에 활용한 결과입니다.
테스트셋이 없을 때, 층을 더하거나 Epoch값을 높여서 실행 횟수를 늘려 정확도를 올려왔으나, 이 정확도가 테스트셋에서는 그대로 나타나지 않습니다. 테스트셋에서는 효과가 없을 수도 있다는 것입니다. 그럼 은닉층의 개수에 따른 각각의 예측률을 한 번 알아보겠습니다.
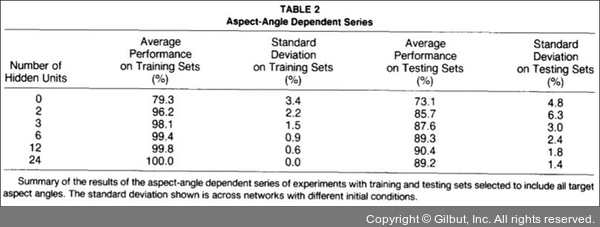
다음과 같은 그림을 보면 은닉층이 0개 부터 12개 일 때 까지는 학습셋과 테스트셋의 예측률이 같이 올라가는 것을 볼 수 있습니다. 하지만 은닉층 개수가 24개일 때 부터는 학습셋은 높아지지만, 테스트셋의 예측률은 낮아지는 것을 볼 수 있습니다.
Test 예측률이 가장 높도록 해보기
광물 데이터를 활용해 초음파 광물 예측 모델을 만들어보았다.

우선 다음과 같이 해 주었다.

테스트 예측률이 0.92로 높게 나오는것을 확인할 수 있다.
은닉층을 조절하면 더 높게 나올 수도 있을 것 같다.
