지난 포스팅 요약
지난 포스팅에서 주로 여러 실험 과정을 위주로 소개하였기 때문에
이번에는 조금 더 요약 및 보완을 하여서 포스팅을 작성한다.
우리 서비스에서..
이와 같이 동적으로 쿼리 DSL 을 활용하여
태그 기반으로 게시글을 검색할 수 있는데
fetch Join 을 통해서 쿼리를 하나라도 더 줄이려고 노력한 상태였다.
@Override
public Page<EmployeePost> showEmployeePostListWithPage(final EmployeePostSearch employeePostSearch,final Pageable pageable){
//workFieldChildTag 를 전부 포함하고 있는 EmployeePostID 리스트 추출
List<Long> employeePostTmpList = queryFactory
.select(employeePostWorkFieldChildTag.employeePost.id)
.from(employeePostWorkFieldChildTag)
.where(employeePostWorkFieldChildTag.workFieldChildTag.id.in(employeePostSearch.getWorkFieldChildTagId()))
.groupBy(employeePostWorkFieldChildTag.employeePost.id)
.having(employeePostWorkFieldChildTag.workFieldChildTag.id.count().eq((long) employeePostSearch.getWorkFieldChildTagId().size()))
.fetch();
//where 조건을 통해서 동적으로 결합이 가능
List<EmployeePost> content = queryFactory
.selectFrom(employeePost)
.leftJoin(employeePost.basicPostContent.workFieldTag).fetchJoin()
.join(employeePost.basicPostContent.member).fetchJoin()
.where(checkChildIdByEmployeePostId(employeePostTmpList,employeePostSearch.getWorkFieldChildTagId())
,greaterThanMinCareer(employeePostSearch.getMinCareer()),lowerThanMaxCareer(employeePostSearch.getMaxCareer())
,workFieldIdEqWithEmployeePostTmpList(employeePostSearch.getWorkFieldId()))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(employeePostSort(pageable))
.fetch();
Long count = queryFactory
.select(employeePost.count())
.from(employeePost)
.where(checkChildIdByEmployeePostId(employeePostTmpList,employeePostSearch.getWorkFieldChildTagId())
,greaterThanMinCareer(employeePostSearch.getMinCareer()),lowerThanMaxCareer(employeePostSearch.getMaxCareer())
,workFieldIdEqWithEmployeePostTmpList(employeePostSearch.getWorkFieldId()))
.fetchOne();
return new PageImpl<>(content,pageable,count);
}따라서 EmployeePost 를 조회할 때 member 와 작업 태그를 fetch join 하여 select 절에 member 에 대한 정보를 함께 영속성 컨텍스트에 저장하여 나중에 member 에 대해 DB를 조회하지 않아도 되는 이점을 가질 수 있다.
만약 fetch join 을 적용하지 않는다면 검색 결과에 member 에 대한 정보인 memberNickName 등을 조회할 경우 그제서야 DB에 쿼리를 날리기 때문에 쿼리의 개수 측면에서는 확실히 이득이라고 생각했고 지금까지 이런 경우에는 무조건 fetch join 을 깔다 싶이 하였다.
하지만 저번 포스팅을 통해 그것이 아니라는 것을 느꼈다.
실험 방식 및 결과
30명의 유저가 1초에 태그를 검색하는데 각각의 유저가 10번씩 조회하는 상황을 가정하여 보자.
상황은 상위 작업 태그만 검색한 상태여서
검색 결과가 2000건 정도 나오는 상태였다.
그 결과를 살펴보자.
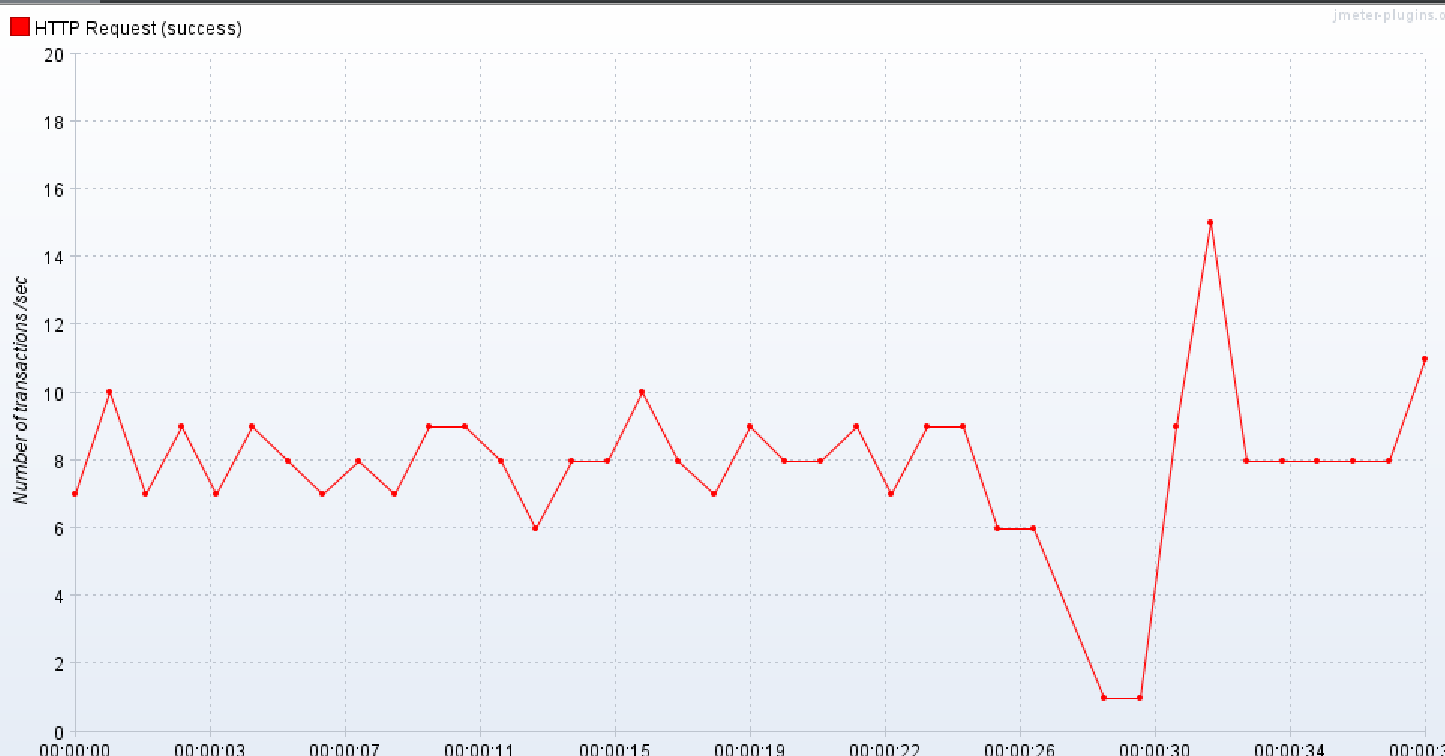

평균적인 응답 시간은 3초이고 TPS가 매우 낮은 것을 확인할 수 있다.
1명의 유저가 300번 조회하는 경우는

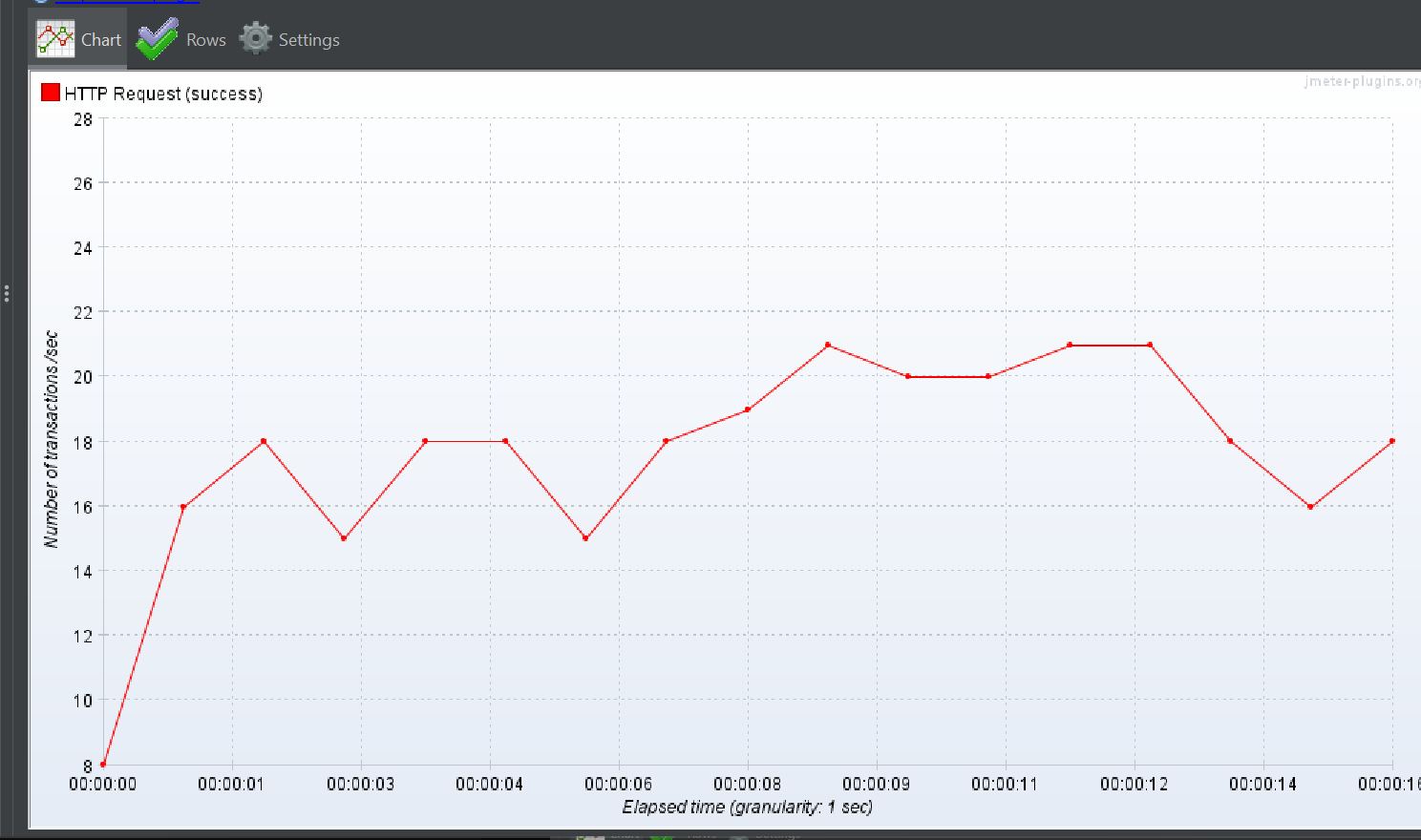
상황이 그나마 나은데 말이다.
그래서 이렇게 생각했다.
총 요청 횟수는 300개로 같으나
유저가 동시에 조회를 했을 때는 더 성능과 TPS 가 낮은 것으로 보아
그 원인은 어떤 한 쿼리에 집중되어 있는 것 같았다.
그 증거로 아래 사진처럼 RDS Queue Depth 에 상당히 많은 count 가 쌓여있는 것을 볼 수 있었다.
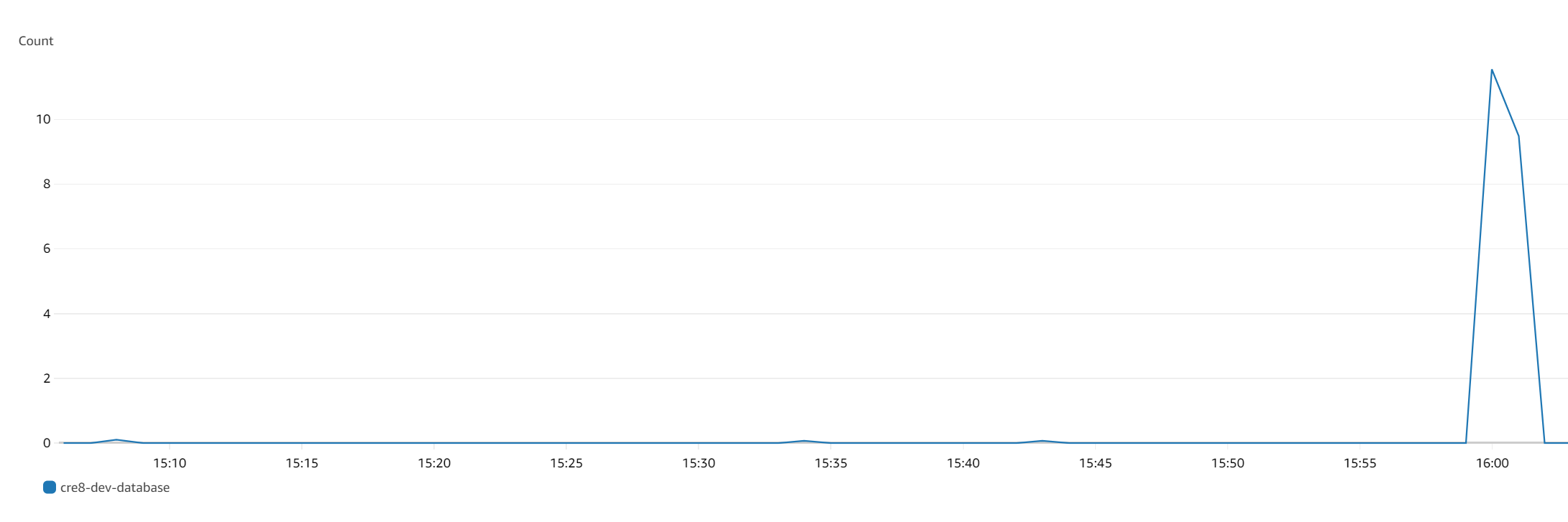
해결 방법 1: 무작정 fetch join 을 제거해요!
RDS 의 Queue Depth 의 설명을 보면 아래와 같이 나와있다.
디스크 엑세스를 위해 대기중인 대기중인 미처리 IO(읽기/쓰기) 요청입니다.따라서 fetch join 을 한 번 빼보기로 결정하였다.
결과

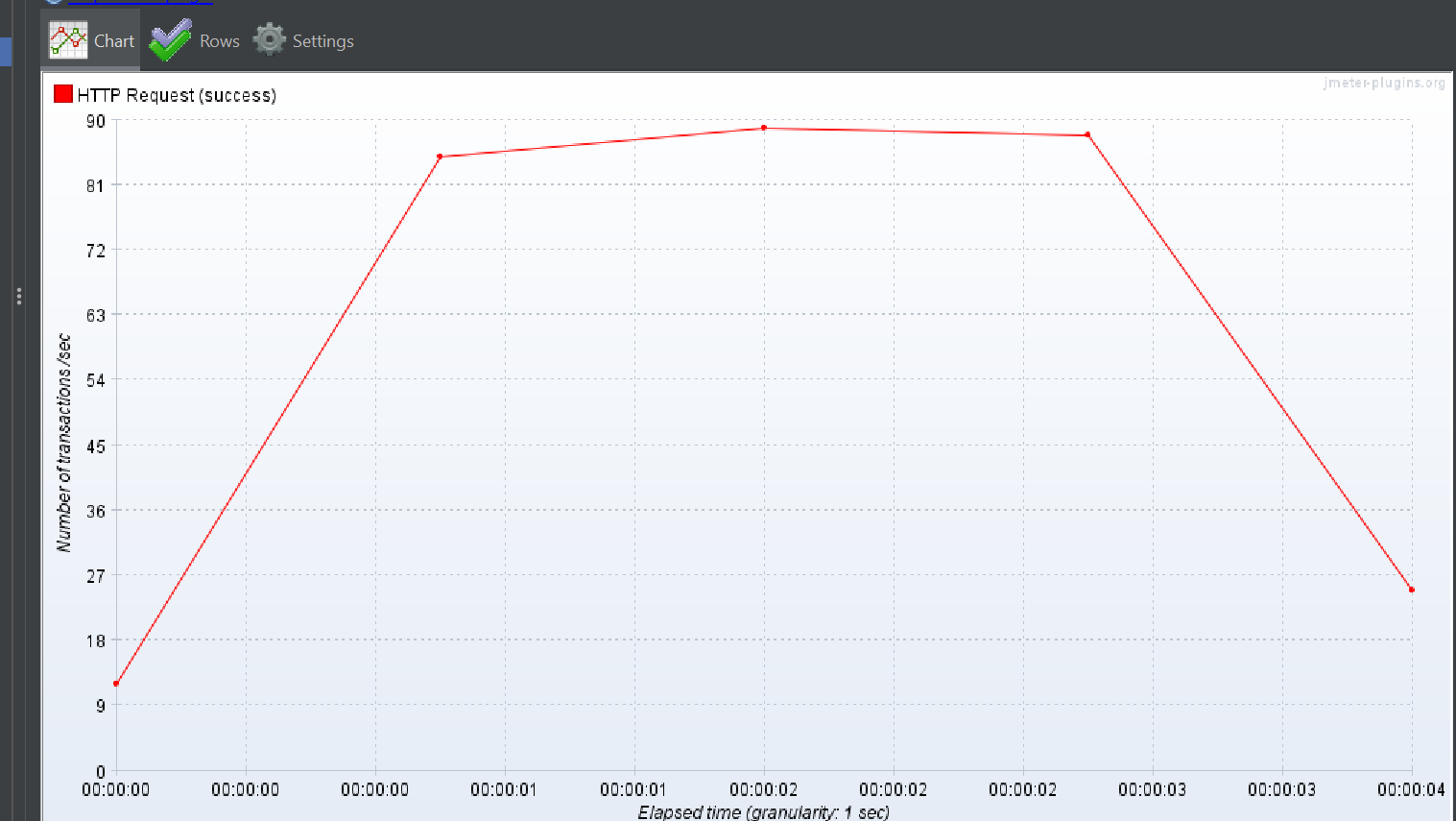
이대로 끝낼 순 없어!
단순히 JOIN 빼더니 잘 되는데? ㅇㅇ
이렇게 끝낼 수는 없다.
미친개마냥 원인을 파악하기 위한 긴 여정을 떠나 보자
해결 방법 2: order by 칼럼에 INDEX 를 적용
그 부하의 원인을 찾기 위해서
부하 쿼리에 대한 explain analyze ,explain 키워드를 통해서 분석을 시도하였다.
부하 쿼리
explain select
ep1_0.employee_post_id,
ep1_0.access_url,
ep1_0.contact,
ep1_0.contents,
ep1_0.member_id,
m1_0.member_id,
m1_0.access_url,
m1_0.authority,
m1_0.birth_day,
m1_0.email,
m1_0.login_id,
m1_0.name,
m1_0.nick_name,
m1_0.password,
m1_0.personal_link,
m1_0.personal_statement,
m1_0.sex,
m1_0.tmp_password,
m1_0.twitter_link,
m1_0.youtube_link,
ep1_0.payment_amount,
ep1_0.payment_method,
ep1_0.title,
wft1_0.work_field_tag_id,
wft1_0.name,
ep1_0.career_year,
ep1_0.created_at,
ep1_0.updated_at
from
employee_post ep1_0
left join
work_field_tag wft1_0
on wft1_0.work_field_tag_id=ep1_0.work_field_tag_id
join
member m1_0
on m1_0.member_id=ep1_0.member_id
where
wft1_0.work_field_tag_id=18
order by
ep1_0.employee_post_id desc
limit
0,10;부하쿼리 analyze
-> Limit: 10 row(s) (cost=1088 rows=10) (actual time=39.1..39.1 rows=10 loops=1)
-> Nested loop inner join (cost=1088 rows=1968) (actual time=39.1..39.1 rows=10 loops=1)
-> Sort: ep1_0.created_at DESC, ep1_0.employee_post_id DESC (cost=399 rows=1968) (actual time=39..39 rows=10 loops=1)
-> Index lookup on ep1_0 using FK_work_field_tag_TO_employee_post (work_field_tag_id=1) (cost=399 rows=1968) (actual time=0.0949..7.91 rows=1968 loops=1)
-> Single-row index lookup on m1_0 using PRIMARY (member_id=ep1_0.member_id) (cost=0.25 rows=1) (actual time=0.011..0.011 rows=1 loops=10)부하 쿼리 explain

해석
- mysql 에서 FK_work_filed_tag_To_employee_post 를 이용해서 1968 개의 행 반환
- 이 테이블 (employee_post 약어:ep1_0) 을 filesort 를 통해 1968개의 행을 정렬
- 10개 반환
- 이 10개에 대해서 JOIN 수행
- limit 마지막 수행(별 의미는 없음)
해석 주의
https://blog.naver.com/ontow/140193959200
를 참고하였을 때
쿼리의 실행 순서는
마치 정해져 있는 것 같아 한참을 해맸다.
나도 학부 시간에 DB를 배웠을 때는 from -> join -> where -> order by -> limit 이 정해져있는 줄 알았으나
where 와 join 이 optimizer 의 판단 아래에 순서가 바뀔 수 있고
또 위와 같이 analyze 키워드를 사용하면 몇 개의 행이 실제로 조인 되는지 확인할 수 있다.
join 이후 limit 을 수행한다면
실제로 nested loop innerjoin 이후 10개의 행을 조인하고 반환하는게 아니라 모두 조인을 수행했을 것이다.
Using filesort
위에서 첫 행을 읽어 오는 시간이 드라마틱하게 증가하는 구간을 보인다.
바로 정렬 수행 구간이다.
왜 이러는 것일까?
explain 키워드의 Extra 부분에 Using FileSort 에 주목할 필요가 있다.
fileSort 의 의미는 정렬이 필요한 데이터를 메모리에 올리고 작업을 수행하겠다는 의미이다.
extra 칼럼이 Using temporary,Using filesort 가 아니라
Using filesort 하나만 있을 때 드라이빙 테이블 (위에서 employee_post) 을 sort_buffer 로 옮겨 정렬을 수행한다.
이렇게 정렬을 수행할 때
만약 옮기는 데이터의 크기가 sort_buffer_size 의 크기를 초과한다면 문제가 심각해진다.
이때 mysql 은 정렬해야 할 레코드를 여러 조각으로 나누어서 처리하는데 이 과정에서 임시 저장을 위해 디스크를 사용한다 .
메모리의 소트 버퍼에서 정렬을 수행하고, 그 결과를 임시로 디스크에 기록해 둔다. 그리고 그다음 레코드를 가져와서 다시 정렬해서 반복적으로 디스크에 임시 저장한다. 이처럼 각 버퍼 크기 만큼씩 정렬된 레코드를 다시 병합하면서 정렬을 수행해야 한다. 이 병합 작업을 멀티 머지(Multi-merge)라고 표현하며, 수행된 멀티 머지 횟수는 Sort_merge_passes라는 상태 변수(SHOW STATUS VARIABLES; 명령 참조)에 누적된다.
검증
검증 1: Sort merge passes 관찰
SHOW SESSION STATUS;
select
ep1_0.employee_post_id,
ep1_0.access_url,
ep1_0.contact,
ep1_0.contents,
ep1_0.member_id,
m1_0.member_id,
m1_0.access_url,
m1_0.authority,
m1_0.birth_day,
m1_0.email,
m1_0.login_id,
m1_0.name,
m1_0.nick_name,
m1_0.password,
m1_0.personal_link,
m1_0.personal_statement,
m1_0.sex,
m1_0.tmp_password,
m1_0.twitter_link,
m1_0.youtube_link,
ep1_0.payment_amount,
ep1_0.payment_method,
ep1_0.title,
wft1_0.work_field_tag_id,
wft1_0.name,
ep1_0.career_year,
ep1_0.created_at,
ep1_0.updated_at
from
employee_post ep1_0
left join
work_field_tag wft1_0
on wft1_0.work_field_tag_id=ep1_0.work_field_tag_id
join
member m1_0
on m1_0.member_id=ep1_0.member_id
where
wft1_0.work_field_tag_id=1
order by
ep1_0.created_at desc,
ep1_0.employee_post_id desc
limit
0,10;
SHOW SESSION STATUS;
위 과정을 통해서 sort_merge_passes(sort merge 횟수) 를 추적 관찰해보자
쿼리 시작전

쿼리 시작 후

실제로 sort_merge_passes 가 일어난 것을 볼 수 있고,
sort_rows 도 대략 2000개 정렬 되었다는 것을 파악할 수 있다.
참고로 select 절에 칼럼이 많을 수록, 대용량일 수록
sort_merge_pass 가 많이 발생하는데 이는
현재 mysql 이 single-pass 전략을 취한다는 방증이다.
Single-pass 전략을 자세히 공부하고 싶다면 아래 블로그 참고
검증 2: profiling
profiling 을 통해서 쿼리의 성능을 눈으로 확인해보자.
show profiles;
show profile for query 237;이렇게 쿼리를 입력해주면
아래와 같은 결과를 확인할 수 있다.
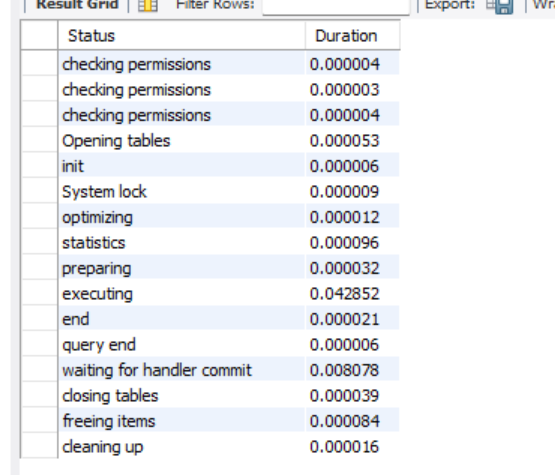
executing 의 duration 이 매우 높은 것을 볼 수 있다.
검증 3: show profile all for query X
위와 같은 명령어를 통하면

이전 쿼리에서 Block_ops_out 이 많이 발생하는 것을 알 수 있다.
Block_ops_out 은 데이터를 디스크에 쓰는 작업을 의미하는데
이 과정은 index 를 사용하지 않은 order by 때문에 발생하는 것으로 추정된다.
참고: JOIN 이 없다면 Sort merge pass는?
그러면 이렇게 해석할 수 있다.
sort buffer 에서 대략 2000개의 정렬을 수행하고 이후 member 와 10번 조인하며 10개의 행을 반환한다.
그러면 JOIN 이 없으면 똑같은 성능이 나오는 것일까?
어차피 filesort 는 조인 이전에 수행되는 것이잖아!
analyze
-> Limit: 10 row(s) (cost=398 rows=10) (actual time=10.5..10.5 rows=10 loops=1)
-> Sort: ep1_0.created_at DESC, ep1_0.employee_post_id DESC, limit input to 10 row(s) per chunk (cost=398 rows=1968) (actual time=10.5..10.5 rows=10 loops=1)
-> Index lookup on ep1_0 using FK_work_field_tag_TO_employee_post (work_field_tag_id=1) (cost=398 rows=1968) (actual time=0.0712..6.03 rows=1968 loops=1)10 개를 chunk 단위로 반환하면서 merge_pass 가 일어나지 않는 것으로 추측된다.
쿼리 실행 전

쿼리 실행 후

sort_merge_passes 가 증가하지 않을 뿐더라 sort_rows 도 10개밖에 증가하지 않는다.
Index 적용
그렇다면 created_at 칼럼에 index 를 적용한다면 어떻게 될까?
explain

analyze explain
-> Limit: 10 row(s) (cost=494 rows=9.78) (actual time=0.634..0.806 rows=10 loops=1)
-> Nested loop inner join (cost=494 rows=9.78) (actual time=0.633..0.804 rows=10 loops=1)
-> Filter: (ep1_0.work_field_tag_id = 1) (cost=1 rows=9.78) (actual time=0.0829..0.23 rows=10 loops=1)
-> Index scan on ep1_0 using idx_created_at (reverse) (cost=1 rows=40) (actual time=0.0798..0.225 rows=52 loops=1)
-> Single-row index lookup on m1_0 using PRIMARY (member_id=ep1_0.member_id) (cost=0.25 rows=1) (actual time=0.057..0.057 rows=1 loops=10)sort merge pass
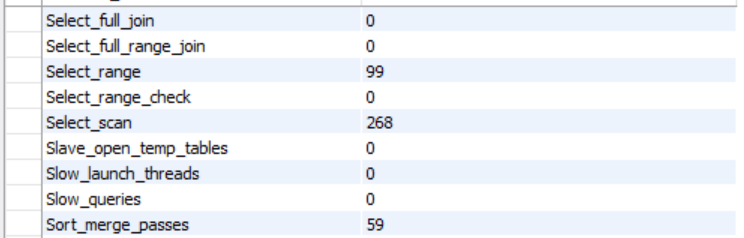
executing
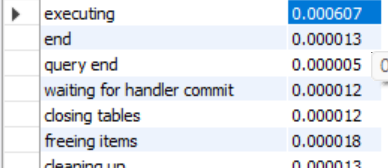
해석
- cost 전체적으로 감소
- 정렬 과정에서 actual time 감소
- sort merge pass 일어나지 않음
- executing 매우 감소
이 방법은 못써요!
이 방법을 왜 못쓸까?
현재 나는 동적 쿼리를 사용하며 , 정렬 순서가 매우 다양해 질 가능성이 존재한다.
그 많은 칼럼에 index 를 적용하라고?
사실상 불가능해질 수 있다.
해결 방법 3: 무거운 쿼리 1개를 가벼운 쿼리 2개로!
위 과정에서 참고란을 보면 정렬 기준에 따른 ID 만을 추출하면,
sort_merge_pass 가 발생하지 않고
limit 절에 의하여 10개만 정렬을 수행한다는 것을 파악할 수 있었다.
따라서 아래와 같이
먼저 조건에 만족하는 페이징 처리가 완료된 employeePostID 리스트를
where in 쿼리 조건절로 가지고 있게 하여 이후에 필요한 칼럼을 select 절에 입력하고 JOIN 을 수행한다.
이 과정에서
대용량 칼럼의 값은 가지고 오지 않게 DTO를 통해 select 에 선별적으로 가지고 오며,
추후 batch fetch size 를 위해 TagList 를 가진 연관관계까지 포함할 수 있게 했다.
@Override
public Page<EmployeeSearchResponseDto> testShowEmployeePostListWithPage(final EmployeePostSearch employeePostSearch,final Pageable pageable){
//child Tag 를 포함하는 emplyoeePost 를 가져옴
List<Long> employeePostTmpList = queryFactory
.select(employeePostWorkFieldChildTag.employeePost.id)
.from(employeePostWorkFieldChildTag)
.where(employeePostWorkFieldChildTag.workFieldChildTag.id.in(employeePostSearch.getWorkFieldChildTagId()))
.groupBy(employeePostWorkFieldChildTag.employeePost.id)
.having(employeePostWorkFieldChildTag.workFieldChildTag.id.count().eq((long) employeePostSearch.getWorkFieldChildTagId().size()))
.fetch();
//where 절을 만족하는 employeePost 를 가져오되 페이징 처리까지 완료한다.
List<Long> employeePostTmpTmpList = queryFactory
.select(employeePost.id)
.from(employeePost)
.where(checkChildIdByEmployeePostId(employeePostTmpList,employeePostSearch.getWorkFieldChildTagId())
,greaterThanMinCareer(employeePostSearch.getMinCareer()),lowerThanMaxCareer(employeePostSearch.getMaxCareer())
,workFieldIdEqWithEmployeePostTmpList(employeePostSearch.getWorkFieldId()))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(employeePostSort(pageable),employeePost.id.desc())
.fetch();
List<EmployeeSearchResponseDto> content2 = queryFactory
.selectFrom(employeePost)
.leftJoin(employeePost.employeePostWorkFieldChildTagList
,employeePostWorkFieldChildTag)
.where(employeePost.id.in(employeePostTmpTmpList))
.transform(groupBy(employeePost.id).list(Projections.constructor(EmployeeSearchResponseDto.class,
employeePost.id,employeePost.basicPostContent.title,
employeePost.basicPostContent.workFieldTag
,employeePost.basicPostContent.member.name
,employeePost.basicPostContent.accessUrl
,employeePost.basicPostContent.member.sex
,employeePost.basicPostContent.member.birthDay
,list(Projections.constructor(
EmployeePostWorkFieldChildTagSearchResponseDto.class,
employeePostWorkFieldChildTag.id,employeePostWorkFieldChildTag.workFieldChildTag.name))
)));
Long count = queryFactory
.select(employeePost.count())
.from(employeePost)
.where(checkChildIdByEmployeePostId(employeePostTmpList,employeePostSearch.getWorkFieldChildTagId())
,greaterThanMinCareer(employeePostSearch.getMinCareer()),lowerThanMaxCareer(employeePostSearch.getMaxCareer())
,workFieldIdEqWithEmployeePostTmpList(employeePostSearch.getWorkFieldId()))
.fetchOne();
return new PageImpl<>(orderByAccordingToIndex(content2,employeePostTmpTmpList),pageable,count);
}
public List<EmployeeSearchResponseDto> orderByAccordingToIndex(List<EmployeeSearchResponseDto> employeeSearchResponseDtoList,
List<Long> indexList) {
HashMap<Long, EmployeeSearchResponseDto> hashMap = new HashMap<>(employeeSearchResponseDtoList.size());
employeeSearchResponseDtoList.forEach(employeeSearchResponseDto -> hashMap.put(employeeSearchResponseDto.getEmployeePostId(), employeeSearchResponseDto));
List<EmployeeSearchResponseDto> output = new ArrayList<>(employeeSearchResponseDtoList.size());
for (Long index : indexList) {
output.add(hashMap.get(index));
}
return output;
}위 쿼리를 수행하면
개선 쿼리 성능 결과
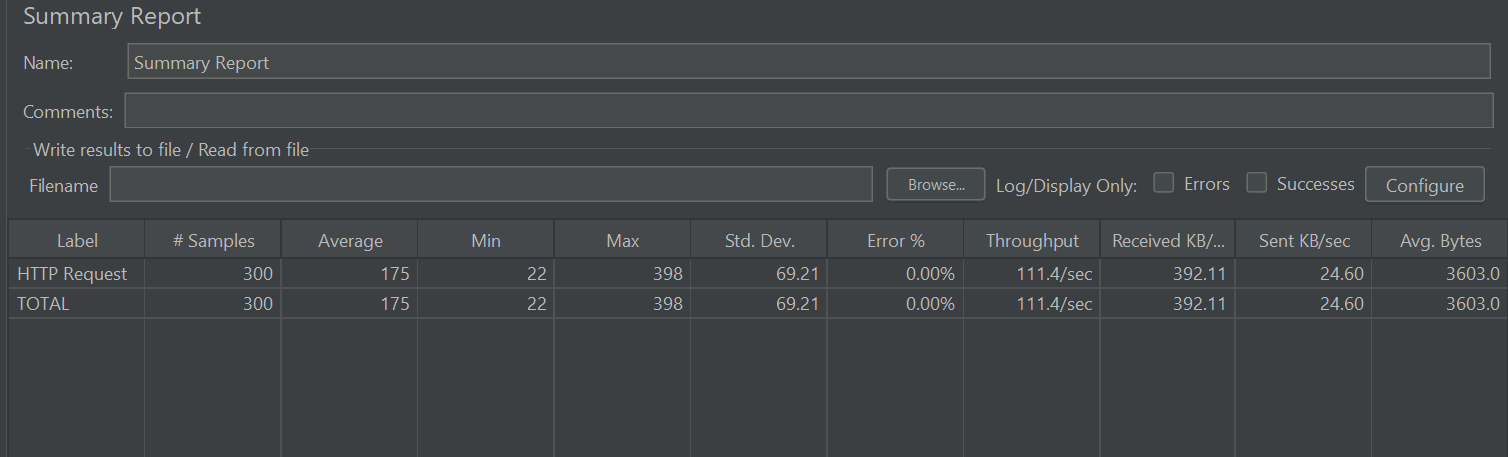
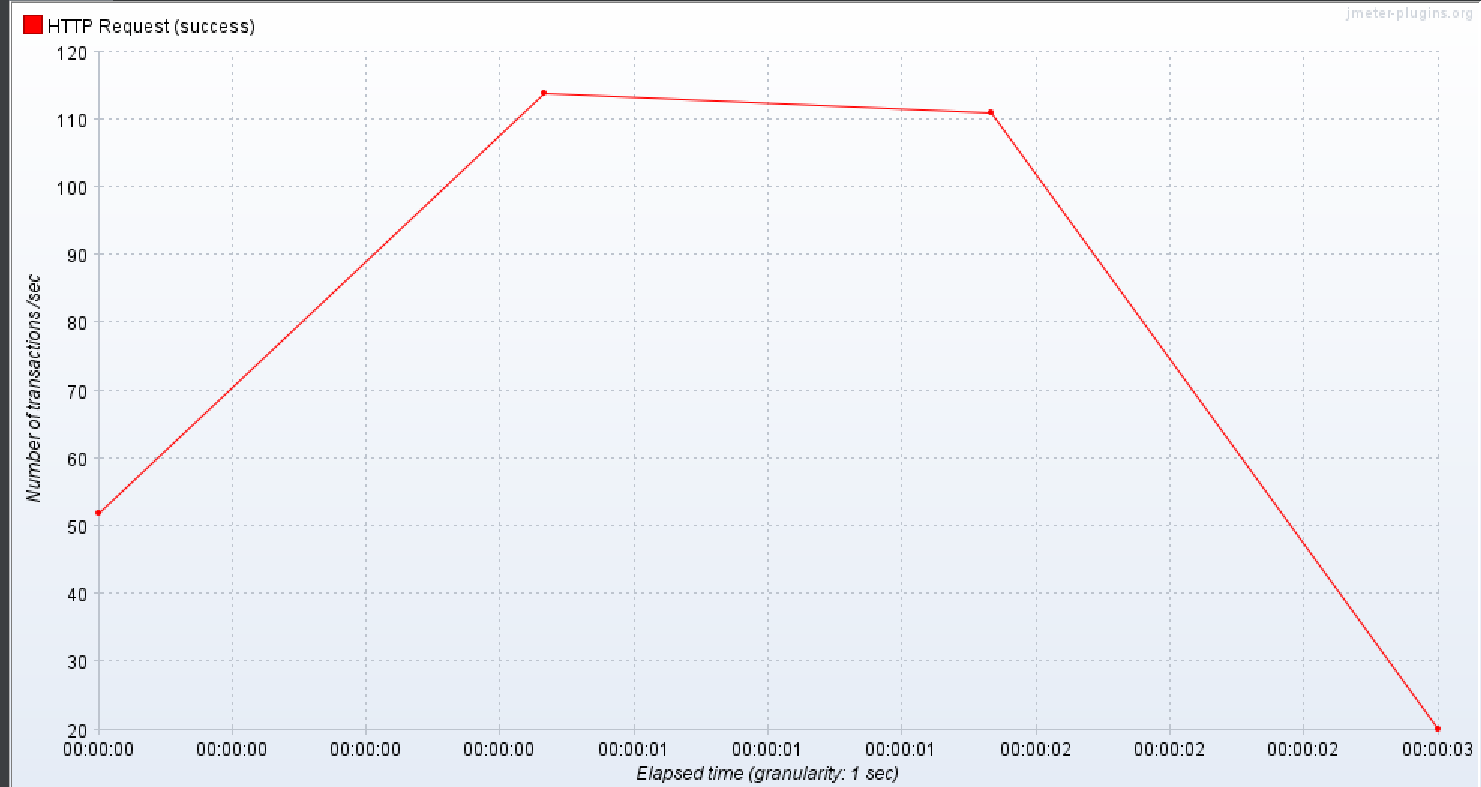
TPS 는 초당 114 로 이전 보다 14배 향상 시켰으며
응답 반환시간 역시 175 ms 로 이전 20배 향상 시켰다.
explain 및 analyze 결과
explain analyze select
ep1_0.employee_post_id
from
employee_post ep1_0
where
ep1_0.work_field_tag_id=1
order by
ep1_0.created_at desc,
ep1_0.employee_post_id desc
limit
0,10;-> Limit: 10 row(s) (cost=399 rows=10) (actual time=3.94..3.94 rows=10 loops=1)
-> Sort: ep1_0.created_at DESC, ep1_0.employee_post_id DESC, limit input to 10 row(s) per chunk (cost=399 rows=1968) (actual time=3.94..3.94 rows=10 loops=1)
-> Index lookup on ep1_0 using FK_work_field_tag_TO_employee_post (work_field_tag_id=1) (cost=399 rows=1968) (actual time=0.0551..3.66 rows=1968 loops=1)

explain analyze select
ep1_0.employee_post_id,
ep1_0.title,
wft1_0.work_field_tag_id,
wft1_0.name,
m1_0.name,
ep1_0.access_url,
m1_0.sex,
m1_0.birth_day,
epwfctl1_0.employee_post_work_field_child_tag_id,
wfct1_0.name
from
employee_post ep1_0
left join
employee_post_work_field_child_tag epwfctl1_0
on ep1_0.employee_post_id=epwfctl1_0.employee_post_id
left join
work_field_child_tag wfct1_0
on wfct1_0.work_field_child_tag_id=epwfctl1_0.work_field_child_tag_id
left join
work_field_tag wft1_0
on wft1_0.work_field_tag_id=ep1_0.work_field_tag_id
join
member m1_0
on m1_0.member_id=ep1_0.member_id
where
ep1_0.employee_post_id in (5019, 7211, 1448, 1155,7680, 4954, 6523, 3202, 1511, 1148)
order by
ep1_0.created_at desc,
ep1_0.employee_post_id desc;
-> Nested loop left join (cost=25.7 rows=19) (actual time=0.112..0.232 rows=30 loops=1)
-> Nested loop left join (cost=21.3 rows=19) (actual time=0.108..0.22 rows=30 loops=1)
-> Nested loop left join (cost=14.7 rows=19) (actual time=0.104..0.188 rows=30 loops=1)
-> Nested loop inner join (cost=8.02 rows=10) (actual time=0.0912..0.116 rows=10 loops=1)
-> Sort: ep1_0.created_at DESC, ep1_0.employee_post_id DESC (cost=4.52 rows=10) (actual time=0.0802..0.0829 rows=10 loops=1)
-> Filter: (ep1_0.employee_post_id in (5019,7211,1448,1155,7680,4954,6523,3202,1511,1148)) (cost=4.52 rows=10) (actual time=0.0296..0.0597 rows=10 loops=1)
-> Index range scan on ep1_0 using PRIMARY over (employee_post_id = 1148) OR (employee_post_id = 1155) OR (8 more) (cost=4.52 rows=10) (actual time=0.0281..0.0566 rows=10 loops=1)
-> Single-row index lookup on m1_0 using PRIMARY (member_id=ep1_0.member_id) (cost=0.26 rows=1) (actual time=0.00299..0.00301 rows=1 loops=10)
-> Index lookup on epwfctl1_0 using FK_employee_post_TO_employee_post_work_field_child_tag (employee_post_id=ep1_0.employee_post_id) (cost=0.493 rows=1.9) (actual time=0.00532..0.00692 rows=3 loops=10)
-> Single-row index lookup on wfct1_0 using PRIMARY (work_field_child_tag_id=epwfctl1_0.work_field_child_tag_id) (cost=0.255 rows=1) (actual time=853e-6..878e-6 rows=1 loops=30)
-> Single-row index lookup on wft1_0 using PRIMARY (work_field_tag_id=ep1_0.work_field_tag_id) (cost=0.137 rows=1) (actual time=213e-6..238e-6 rows=1 loops=30)
참고
JOIN 수행했는데 Chunk 단위로 짜를 때?
explain analyze select
ep1_0.employee_post_id,
ep1_0.access_url,
ep1_0.contact,
ep1_0.contents,
ep1_0.member_id,
ep1_0.payment_amount,
ep1_0.payment_method,
ep1_0.title,
wft1_0.work_field_tag_id,
wft1_0.name,
ep1_0.career_year,
ep1_0.created_at,
ep1_0.updated_at
from
employee_post ep1_0
left join
work_field_tag wft1_0
on wft1_0.work_field_tag_id=ep1_0.work_field_tag_id
where
wft1_0.work_field_tag_id=1
order by
ep1_0.created_at desc,
ep1_0.employee_post_id desc
limit
0,10;을 수행하면
-> Limit: 10 row(s) (cost=398 rows=10) (actual time=22.6..22.6 rows=10 loops=1)
-> Sort: ep1_0.created_at DESC, ep1_0.employee_post_id DESC, limit input to 10 row(s) per chunk (cost=398 rows=1968) (actual time=22.6..22.6 rows=10 loops=1)
-> Index lookup on ep1_0 using FK_work_field_tag_TO_employee_post (work_field_tag_id=1) (cost=398 rows=1968) (actual time=0.109..17.5 rows=1968 loops=1)이 처럼 chunk 단위로 짜르는 것을 볼 수 있다.
즉 left outer join 을 수행하면 Chunk 단위로 잘라 정렬을 PriorityQueue 형식의 최적화를 시도하지만 그냥 Inner join 인 경우 모두 메모리에서 정렬 (이 과정에서 퀵정렬 , 특히 디스크를 이용하는 합병정렬) 을 수행하므로 부하가 걸린다.
어떻게 보면 당연한 일이다.
left outer join 은 join table을 크게 신경쓰지 않고 정렬해도 상관이 없지만,
inner join 은 조인 되는 테이블이 있냐 없냐가 결과가 달라질 수 있기 때문이다.
하지만 left outer join의 최적화 역시 문제가 있는데
이는 page의 크기가 크다면 offset+limit 만큼을 가지고 있는 과정에서 테이블의 크기가 크기에(Single - Pass 전략)
페이지의 크기가 커질 수록 응답속도가 증가하고 TPS가 하락한다.
즉 정렬할 때 select 절에 칼럼을 최대한 작게 두기 위해서 처음과 같이 구현하였다.
