우리 프로젝트에서는...
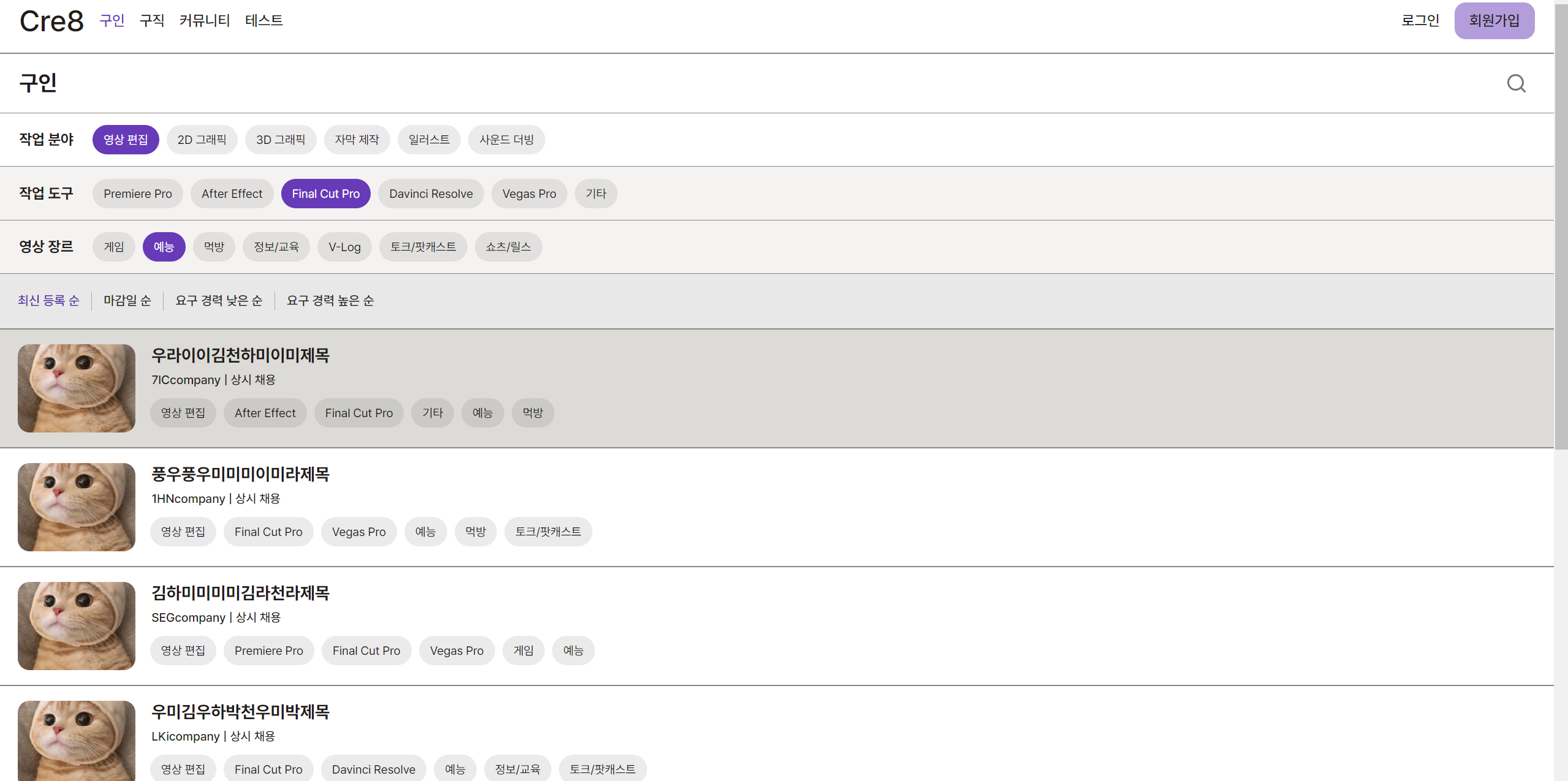
위 사진과 같이 동적으로 태그를 사용해서 구인 ,구직 게시글을 검색할 수 있다.
동적으로 태그를 사용해서 검색하기 위하여
MyBatis 나 ,Criteria, 등등을 사용할 수도 있지만
현재 프로젝트는 JPA 중심으로 구성되어 있다는 점,
문자열로 쿼리 등등을 적어주어야 하는 다른 방법과 달리 컴파일 시점에 오류 발생을 확인할 수 있는 점
의 장점을 가진 Query DSL 을 활용하였다.
기존 코드
아래에서 설명하는 WorkFieldTag 는 위 사진에서 작업분야를 의미하고,
WorkFieldChildTag 는 게임 예능 AfterEffect 등 작업분야의 자식들로 이루어 졌있다.
따라서 게시글 과 WorkFieldChildTag는 다대다 관계를 맺고 있고,
WorkFieldTag 와는 다대일 관계를 맺고 있다.(게시글 마다 하나의 작업분야만 등록 가능하므로)
어쨌거나 저쨌거나
위와 같이 태그별로 검색할 수 있게 하기 위해서
아래와 같은 코드를 작성하였다.
EmployeePostCustomRepositoryImpl
@Override
public Page<EmployeePost> showEmployeePostListWithPage(final EmployeePostSearch employeePostSearch,final Pageable pageable){
//workFieldChildTag 를 전부 포함하고 있는 EmployeePostID 리스트 추출
List<Long> employeePostTmpList = queryFactory
.select(employeePostWorkFieldChildTag.employeePost.id)
.from(employeePostWorkFieldChildTag)
.where(employeePostWorkFieldChildTag.workFieldChildTag.id.in(employeePostSearch.getWorkFieldChildTagId()))
.groupBy(employeePostWorkFieldChildTag.employeePost.id)
.having(employeePostWorkFieldChildTag.workFieldChildTag.id.count().eq((long) employeePostSearch.getWorkFieldChildTagId().size()))
.fetch();
//where 조건을 통해서 동적으로 결합이 가능
List<EmployeePost> content = queryFactory
.selectFrom(employeePost)
.leftJoin(employeePost.basicPostContent.workFieldTag).fetchJoin()
.join(employeePost.basicPostContent.member).fetchJoin()
.where(checkChildIdByEmployeePostId(employeePostTmpList,employeePostSearch.getWorkFieldChildTagId())
,greaterThanMinCareer(employeePostSearch.getMinCareer()),lowerThanMaxCareer(employeePostSearch.getMaxCareer())
,workFieldIdEqWithEmployeePostTmpList(employeePostSearch.getWorkFieldId()))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(employeePostSort(pageable))
.fetch();
Long count = queryFactory
.select(employeePost.count())
.from(employeePost)
.where(checkChildIdByEmployeePostId(employeePostTmpList,employeePostSearch.getWorkFieldChildTagId())
,greaterThanMinCareer(employeePostSearch.getMinCareer()),lowerThanMaxCareer(employeePostSearch.getMaxCareer())
,workFieldIdEqWithEmployeePostTmpList(employeePostSearch.getWorkFieldId()))
.fetchOne();
return new PageImpl<>(content,pageable,count);
}List<Long> employeePostTmpList를 통해서 사용자가 입력한 하위태그를 모두 가진 employeePost 만을 추출한다.List<EmployeePost> content는 내용을 담는데 그 내용은 동적으로 태그를 반영한 EmployeePost 이다.- 이 과정에서 빠른 조회 속도 향상을 위해서 member 와 상위태그(workfieldTag) 에 페치 조인을 적용한다. member는
inner join을 사용하였고, workFieldTag 는 상위 작업 태그가 없는 게시물도 존재가능하므로left outer join을 사용하였다. - 직접 count 쿼리를 작성하여 준다.
EmployeePostSearchService
public EmployeePostSearchWithCountResponseDto searchEmployeePost(final EmployeePostSearch employerPostSearch,
final Pageable pageable){
Page<EmployeePost> employeePostSearchResponseDtoPage =
employeePostRepository.showEmployeePostListWithPage(employerPostSearch,pageable);
return EmployeePostSearchWithCountResponseDto.of(employeePostSearchResponseDtoPage.getTotalElements(),
employeePostSearchResponseDtoPage.getContent().stream().map(employeePost -> {
List<String> tagNameList = getTagList(employeePost);
return EmployeePostSearchResponseDto.of(employeePost,tagNameList);
}).collect(
Collectors.toList()),employeePostSearchResponseDtoPage.getTotalPages());
}
private List<String> getTagList(final EmployeePost employeePost) {
List<String> tagNameList = new ArrayList<>();
if(employeePost.getBasicPostContent().getWorkFieldTag()!=null){
tagNameList.add(employeePost.getBasicPostContent().getWorkFieldTag().getName());
}
employeePost.getEmployeePostWorkFieldChildTagList().forEach(employeePostWorkFieldChildTag -> {
tagNameList.add(employeePostWorkFieldChildTag.getWorkFieldChildTag().getName());
});
return tagNameList;
}-
조회한 게시물을 사용자에게 전달하기 위해 DB로부터 가져와서 가공을 시작한다.
-
먼저 태그 이름을 생성한 이후
EmployeePostSearchResponseDto에서 아래와 같이 전달할 부분 전달 .
EmployeePostSearchResponseDto
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor(access = AccessLevel.PROTECTED)
public class EmployeePostSearchResponseDto {
private Long employeePostId;
private String title;
private String memberName;
private String sex;
private int year;
private List<String> tagNameList = new ArrayList<>();
private String accessUrl;
public static EmployeePostSearchResponseDto of(final EmployeePost employeePost,final List<String> tagNameList){
return new EmployeePostSearchResponseDto(employeePost.getId(),employeePost.getBasicPostContent().getTitle(),
employeePost.getBasicPostContent().getMember().getName(),
employeePost.getBasicPostContent().getMember().getSex().getName(),
employeePost.getBasicPostContent().getMember().getBirthDay().getYear(),
tagNameList,
employeePost.getBasicPostContent().getAccessUrl());
}
}기존 코드에 대한 의심
Fetch JOIN , batch fetch size 등을 이용해 쿼리를 최대한 줄였지만...
연관된 엔티티를 함께 영속성 컨텍스트에 저장하여 쿼리 실행 개수를 최대한 줄일 수 있는 Fetch JOIN 과
한번의 쿼리가 발생될 때마다 IN 쿼리가 발생되어 한번에 여러 인스턴스를 가지고 올 수 있는 batch fetch size 를 활용했다.
(위 쿼리에서는 영속성 컨텍스트에 이미 저장되어 있는 객체를 제외하고 객체로 인한 탐색이며 지연 로딩 전략일 떄 in 쿼리가 발생되며 성능이 최적화되는데 그 부분은
private List<String> getTagList(final EmployeePost employeePost) {
List<String> tagNameList = new ArrayList<>();
if(employeePost.getBasicPostContent().getWorkFieldTag()!=null){
tagNameList.add(employeePost.getBasicPostContent().getWorkFieldTag().getName());
}
employeePost.getEmployeePostWorkFieldChildTagList().forEach(employeePostWorkFieldChildTag -> {
tagNameList.add(employeePostWorkFieldChildTag.getWorkFieldChildTag().getName());
});
return tagNameList;
}이 부분이다.
나오는 쿼리를 통해서 설명하면
select
epwfctl1_0.employee_post_id,
epwfctl1_0.employee_post_work_field_child_tag,
epwfctl1_0.work_field_child_tag_id
from
employee_post_work_field_child_tag epwfctl1_0
where
epwfctl1_0.employee_post_id in (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)위 childtag 저장 부분에 대해 이런 쿼리가 나가는데 이 쿼리는 미리 지정해둔 사이즈 10개에 대해서 앞으로 나올 10개의 employeePost 에 연관된 모든 EmployeePostWorkFieldChildTag 를 미리 다 땡겨온다. )
아무튼 이런 과정을 통해서 성공적으로 속도를 최적화한 부분이 있지만 찜찜한 부분이 존재한다.
너무 많은 데이터양?
동적 쿼리 부분에서 fetch join 을 활용했는데
select
ep1_0.employee_post_id,
ep1_0.access_url,
ep1_0.contact,
ep1_0.contents,
ep1_0.member_id,
m1_0.member_id,
m1_0.access_url,
m1_0.authority,
m1_0.birth_day,
m1_0.email,
m1_0.login_id,
m1_0.name,
m1_0.nick_name,
m1_0.password,
m1_0.personal_link,
m1_0.personal_statement,
m1_0.sex,
m1_0.twitter_link,
m1_0.youtube_link,
ep1_0.payment_amount,
ep1_0.payment_method,
ep1_0.title,
wft1_0.work_field_tag_id,
wft1_0.name,
ep1_0.career_year,
ep1_0.created_at,
ep1_0.updated_at
from
employee_post ep1_0
left join
work_field_tag wft1_0
on wft1_0.work_field_tag_id=ep1_0.work_field_tag_id
join
member m1_0
on m1_0.member_id=ep1_0.member_id
where
ep1_0.employee_post_id in (?, ?, ?, ?, ?)
and wft1_0.work_field_tag_id=?
order by
ep1_0.created_at desc
limit
?, ?그 동적 쿼리 부분에서 이렇게 긴 쿼리가 발생된다.
심지어 member의 personal Statement 는

이렇게 대용량이 될 소지가 존재하며
employeePost의 contents 역시

매우 많은 글자를 가지고 있을 수 있다.
따라서 저렇게 검색 시에 필요한 부분이 아닌 칼럼들 역시 한번에 땡겨오는게 올바른가? 이에 대한 성능 하락이 우려되었다.
따라서 DTO 를 이용
따라서 DTO 로 필요한 필드만 조회한 것과 비교해보기로 하였다.
EmployeePostCustomRepositoryImpl
@Override
public Page<EmployeeSearchResponseDto2> testShowEmployeePostListWithPage2(final EmployeePostSearch employeePostSearch,final Pageable pageable){
List<Long> employeePostTmpList = queryFactory
.select(employeePostWorkFieldChildTag.employeePost.id)
.from(employeePostWorkFieldChildTag)
.where(employeePostWorkFieldChildTag.workFieldChildTag.id.in(employeePostSearch.getWorkFieldChildTagId()))
.groupBy(employeePostWorkFieldChildTag.employeePost.id)
.having(employeePostWorkFieldChildTag.workFieldChildTag.id.count().eq((long) employeePostSearch.getWorkFieldChildTagId().size()))
.fetch();
List<EmployeeSearchResponseDto2> content = queryFactory
.select(Projections.constructor(EmployeeSearchResponseDto2.class,employeePost.id,employeePost.basicPostContent.title,
employeePost.basicPostContent.workFieldTag,
employeePost.basicPostContent.member.name,employeePost.basicPostContent.accessUrl,employeePost.basicPostContent.member.sex,employeePost.basicPostContent.member
.birthDay))
.from(employeePost)
.leftJoin(employeePost.basicPostContent.workFieldTag)
.join(employeePost.basicPostContent.member)
.where(checkChildIdByEmployeePostId(employeePostTmpList,employeePostSearch.getWorkFieldChildTagId())
,greaterThanMinCareer(employeePostSearch.getMinCareer()),lowerThanMaxCareer(employeePostSearch.getMaxCareer())
,workFieldIdEqWithEmployeePostTmpList(employeePostSearch.getWorkFieldId()))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(employeePostSort(pageable))
.fetch();
Long count = queryFactory
.select(employeePost.count())
.from(employeePost)
.where(checkChildIdByEmployeePostId(employeePostTmpList,employeePostSearch.getWorkFieldChildTagId())
,greaterThanMinCareer(employeePostSearch.getMinCareer()),lowerThanMaxCareer(employeePostSearch.getMaxCareer())
,workFieldIdEqWithEmployeePostTmpList(employeePostSearch.getWorkFieldId()))
.fetchOne();
return new PageImpl<>(content,pageable,count);
}- 나머지는 동일하나 fetch join 대신 join 을 사용하였고, join 을 이용해서 검색 시 필요한 데이터만 DB에서 조회하도록 설정하였다.
위처럼 코드 설정시 쿼리는
select
ep1_0.employee_post_id,
ep1_0.title,
wft1_0.work_field_tag_id,
wft1_0.name,
m1_0.name,
ep1_0.access_url,
m1_0.sex,
m1_0.birth_day
from
employee_post ep1_0
left join
work_field_tag wft1_0
on wft1_0.work_field_tag_id=ep1_0.work_field_tag_id
join
member m1_0
on m1_0.member_id=ep1_0.member_id
where
ep1_0.employee_post_id in (?, ?, ?, ?, ?)
and wft1_0.work_field_tag_id=?
order by
ep1_0.created_at desc
limit
?, ?로써 select 절에 들어가는 부분은 최소한 적게 설정할 수 있다.
여기까지는 탄탄대로인데 그 이후에는 망망이다. 다음을 보자.
public TestEmployeePostSearchWithCountResponseDto searchEmployeePostTest2(final EmployeePostSearch employerPostSearch,
final Pageable pageable){
Page<EmployeeSearchResponseDto2> employeePostSearchResponseDtoPage =
employeePostRepository.testShowEmployeePostListWithPage2(employerPostSearch,pageable);
return TestEmployeePostSearchWithCountResponseDto.of(employeePostSearchResponseDtoPage.getTotalElements(),
employeePostSearchResponseDtoPage.getContent().stream().map(employeeSearchResponseDto-> {
List<String> tagNameList = testGetTagList2(employeeSearchResponseDto);
return TestEmployeePostSearchResponseDto.of2(employeeSearchResponseDto,tagNameList);
}).collect(
Collectors.toList()),employeePostSearchResponseDtoPage.getTotalPages());
}
private List<String> testGetTagList2(final EmployeeSearchResponseDto2 employeeSearchResponseDto){
List<String> tagNameList = new ArrayList<>();
if(employeeSearchResponseDto.getWorkFieldTag()!=null){
tagNameList.add(employeeSearchResponseDto.getWorkFieldTag().getName());
}
employeePostWorkFieldChildTagRepository.findByEmployeePost_IdWithFetchWorkFieldChildTag(employeeSearchResponseDto.getEmployeePostId()).
forEach(employeePostWorkFieldChildTag -> {
tagNameList.add(employeePostWorkFieldChildTag.getWorkFieldChildTag().getName());
}
);
return tagNameList;
}- 태그의 이름을 가져오는 코드가 바뀌었다. 이제는 DTO 로 전달받은 employeePostID 를 기반으로 하나하나
employeePostWorkFieldChildTag를 조회하여 batch fetch size 를 활용하지 못한다.
그래서
select
epwfct1_0.employee_post_work_field_child_tag,
epwfct1_0.employee_post_id,
epwfct1_0.work_field_child_tag_id,
wfct1_0.work_field_child_tag_id,
wfct1_0.name,
wfct1_0.work_field_sub_category_id
from
employee_post_work_field_child_tag epwfct1_0
join
work_field_child_tag wfct1_0
on wfct1_0.work_field_child_tag_id=epwfct1_0.work_field_child_tag_id
where
epwfct1_0.employee_post_id=?이런 긴 쿼리가 여러 개 생성이 된다.
(물론 이를 해결하기 위해
.transform(groupBy(employeePost.id).list(Projections.constructor(EmployeeSearchResponseDto.class,
employeePost.id,employeePost.basicPostContent.title,
employeePost.basicPostContent.workFieldTag
,employeePost.basicPostContent.member.name
,employeePost.basicPostContent.accessUrl
,employeePost.basicPostContent.member.sex
,employeePost.basicPostContent.member.birthDay
,list(Projections.constructor(
EmployeePostWorkFieldChildTagSearchResponseDto.class,
employeePostWorkFieldChildTag.id,employeePostWorkFieldChildTag.workFieldChildTag.name))
,employeePost.createdAt
)));쿼리 dsl 의 transform 의 사용을 고려해볼 수 있지만
이는 페이징 시에 오류가 발생할 가능성이 높아 보였다. 실제로 테스트 시에 태그와 join 된 employeepost를 size 만큼 가져오는게 아니라 이미 조인된 테이블에서 size 만큼 가져오기에 그 수가 맞지 않았다. 1대다 fetch join 과 상황이 유사하였다. )
더 응용해보기?
테스트를 위해 조회 방법 하나를 더 추가한다. 이번에는 DTO 를 통해 Member 는 필요한 부분만 사용하고 엔티티 EmployeePost 를 추가하여, getWorkFieldChildTag 를 사용하여 IN 쿼리를 사용할 수 있게 하였다.
@Override
public Page<EmployeeSearchResponseDto2> testShowEmployeePostListWithPage2(final EmployeePostSearch employeePostSearch,final Pageable pageable){
List<Long> employeePostTmpList = queryFactory
.select(employeePostWorkFieldChildTag.employeePost.id)
.from(employeePostWorkFieldChildTag)
.where(employeePostWorkFieldChildTag.workFieldChildTag.id.in(employeePostSearch.getWorkFieldChildTagId()))
.groupBy(employeePostWorkFieldChildTag.employeePost.id)
.having(employeePostWorkFieldChildTag.workFieldChildTag.id.count().eq((long) employeePostSearch.getWorkFieldChildTagId().size()))
.fetch();
List<EmployeeSearchResponseDto2> content = queryFactory
.select(Projections.constructor(EmployeeSearchResponseDto2.class,employeePost.id,employeePost.basicPostContent.title,
employeePost.basicPostContent.workFieldTag,
employeePost.basicPostContent.member.name,employeePost.basicPostContent.accessUrl,employeePost.basicPostContent.member.sex,employeePost.basicPostContent.member
.birthDay))
.from(employeePost)
.leftJoin(employeePost.basicPostContent.workFieldTag)
.join(employeePost.basicPostContent.member)
.where(checkChildIdByEmployeePostId(employeePostTmpList,employeePostSearch.getWorkFieldChildTagId())
,greaterThanMinCareer(employeePostSearch.getMinCareer()),lowerThanMaxCareer(employeePostSearch.getMaxCareer())
,workFieldIdEqWithEmployeePostTmpList(employeePostSearch.getWorkFieldId()))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(employeePostSort(pageable))
.fetch();
Long count = queryFactory
.select(employeePost.count())
.from(employeePost)
.where(checkChildIdByEmployeePostId(employeePostTmpList,employeePostSearch.getWorkFieldChildTagId())
,greaterThanMinCareer(employeePostSearch.getMinCareer()),lowerThanMaxCareer(employeePostSearch.getMaxCareer())
,workFieldIdEqWithEmployeePostTmpList(employeePostSearch.getWorkFieldId()))
.fetchOne();
return new PageImpl<>(content,pageable,count);
}public TestEmployeePostSearchWithCountResponseDto searchEmployeePostTest2(final EmployeePostSearch employerPostSearch,
final Pageable pageable){
Page<EmployeeSearchResponseDto2> employeePostSearchResponseDtoPage =
employeePostRepository.testShowEmployeePostListWithPage2(employerPostSearch,pageable);
return TestEmployeePostSearchWithCountResponseDto.of(employeePostSearchResponseDtoPage.getTotalElements(),
employeePostSearchResponseDtoPage.getContent().stream().map(employeeSearchResponseDto-> {
List<String> tagNameList = testGetTagList2(employeeSearchResponseDto);
return TestEmployeePostSearchResponseDto.of2(employeeSearchResponseDto,tagNameList);
}).collect(
Collectors.toList()),employeePostSearchResponseDtoPage.getTotalPages());
}
private List<String> testGetTagList2(final EmployeeSearchResponseDto2 employeeSearchResponseDto){
List<String> tagNameList = new ArrayList<>();
if(employeeSearchResponseDto.getWorkFieldTag()!=null){
tagNameList.add(employeeSearchResponseDto.getWorkFieldTag().getName());
}
employeePostWorkFieldChildTagRepository.findByEmployeePost_IdWithFetchWorkFieldChildTag(employeeSearchResponseDto.getEmployeePostId()).
forEach(employeePostWorkFieldChildTag -> {
tagNameList.add(employeePostWorkFieldChildTag.getWorkFieldChildTag().getName());
}
);
return tagNameList;
}성능 비교: 전체를 DTO VS DTO 이용X 대신 모두 batch fetch size VS 일부 DTO 일부 batch fetch size
테스트 방식 using apache jmeter
데이터 베이스에 각각 일만건 employeePost 정보 , 그 와 연관된 무작위 태그, 그 글을 작성한 1만명의 유저 를 저장해 놓았다.
실제와 같은 환경을 위해서 무작위 태그를 넣었고 employeePost 의 게시글 내용과 유저의 자기소개 글 과 같은 부분 역시 다른 구인구직글을 참고하여 충분히 넣었다.
테스트 환경
먼저 성능을 확인하기 위해 먼저 1명의 유저가 300번 시행했을 때 그 값을 보도록 하자 .
batch fetch size 만 이용
가장 처음에 작성했던 코드를 먼저 테스트 한다.
상위 작업 태그만 선택시
즉 /api/v1/employee-posts/search?workFieldId=18&minCareer=&maxCareer=&page=0&size=10&sort=createdAt,desc
이런 형식이다.

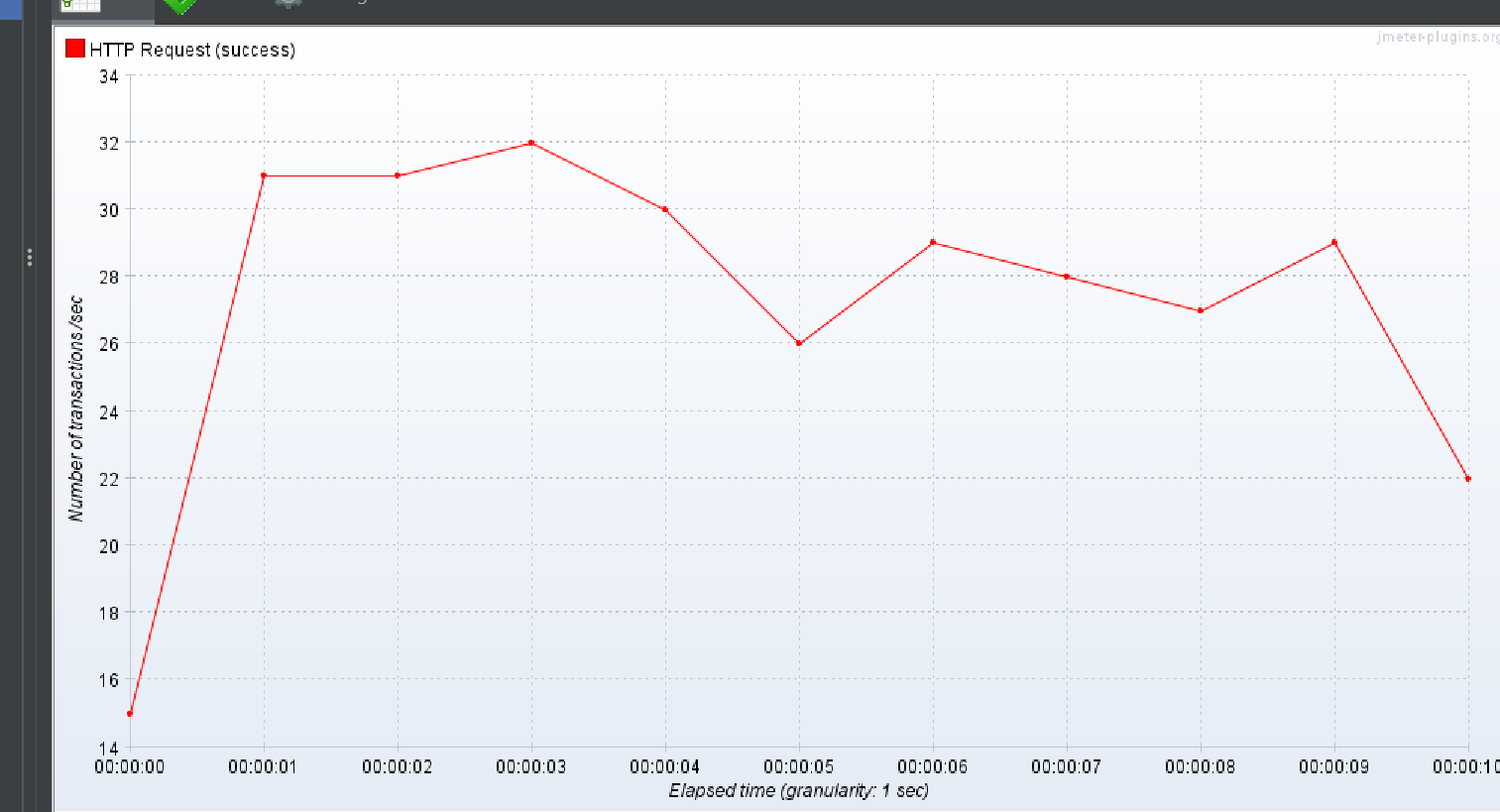
ResponseTime over time
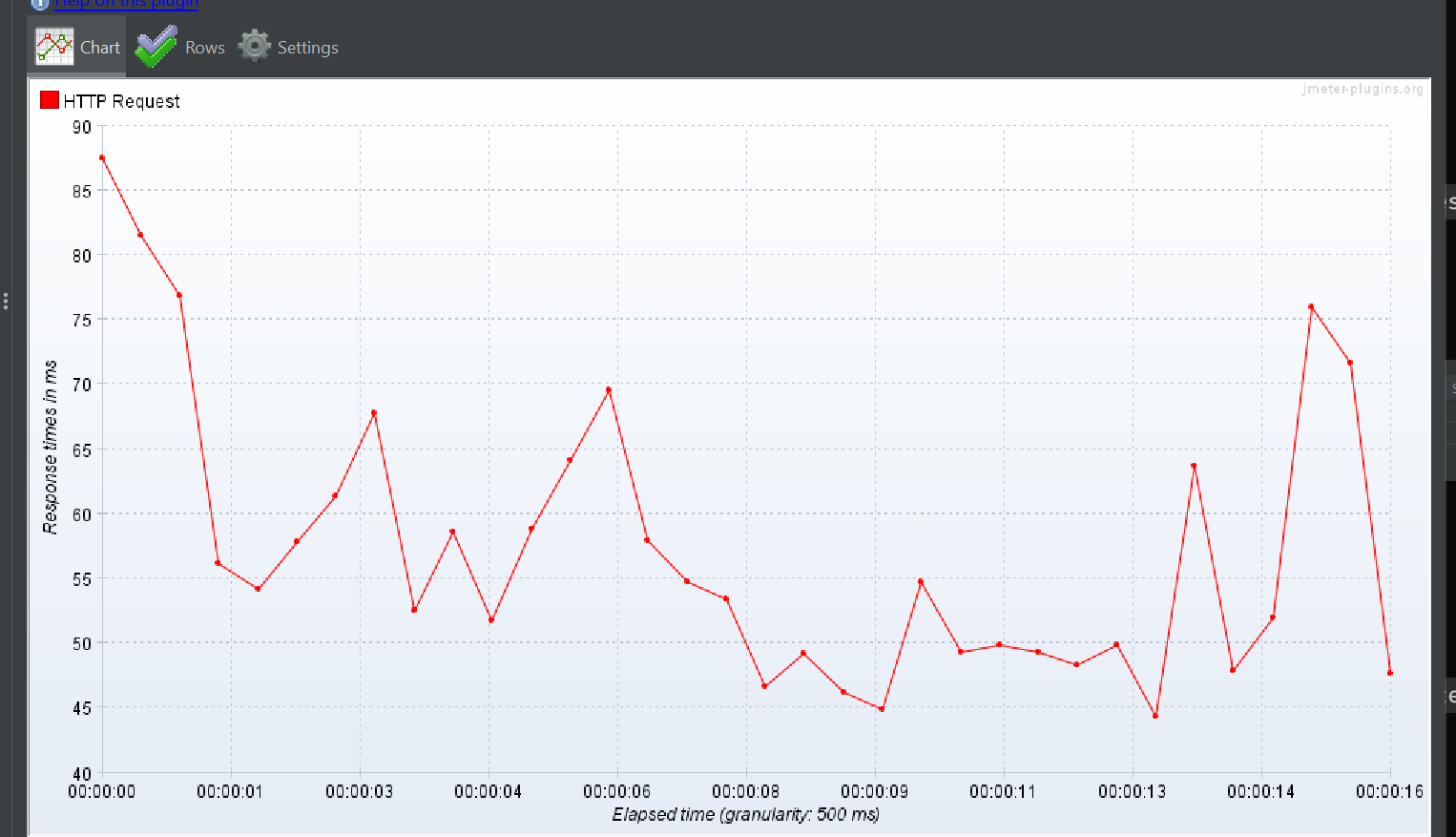
TPS
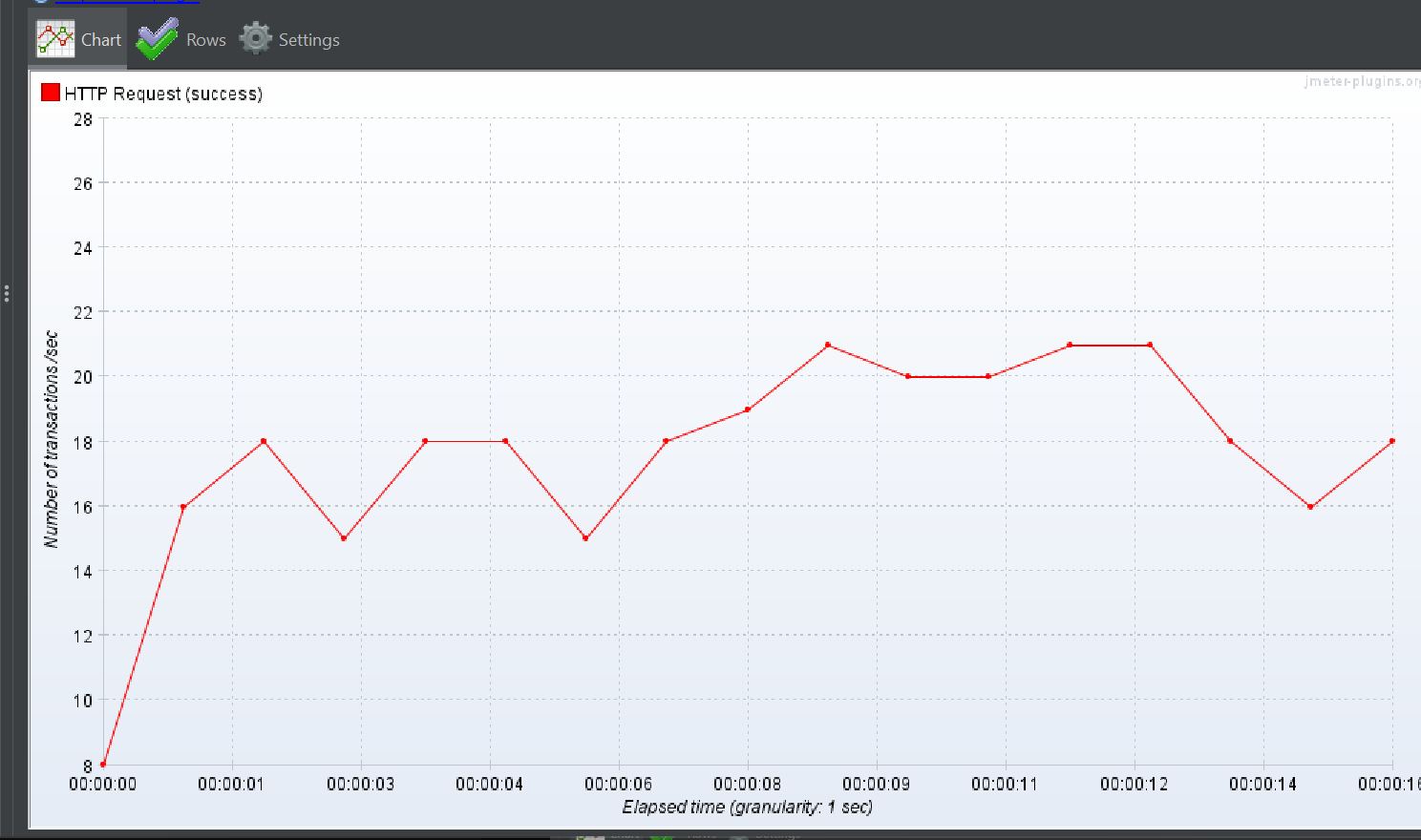
상위 작업 태그 + 하위 작업 태그 하나
즉 /api/v1/employee-posts/search?workFieldId=18&workFieldChildTagId=1&minCareer=&maxCareer=&page=0&size=10&sort=createdAt,desc
이런 형식이다.

Response Over time
TPS
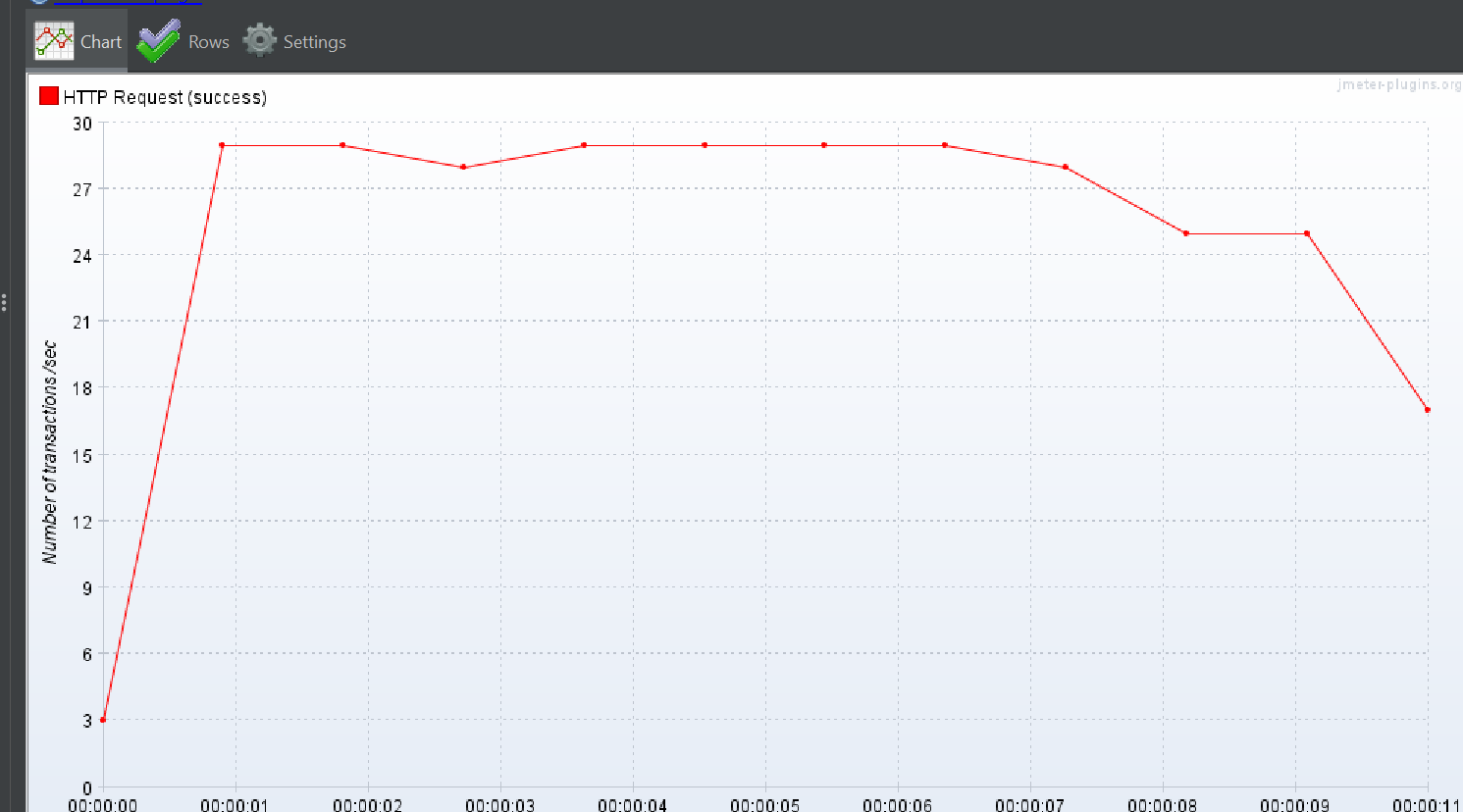
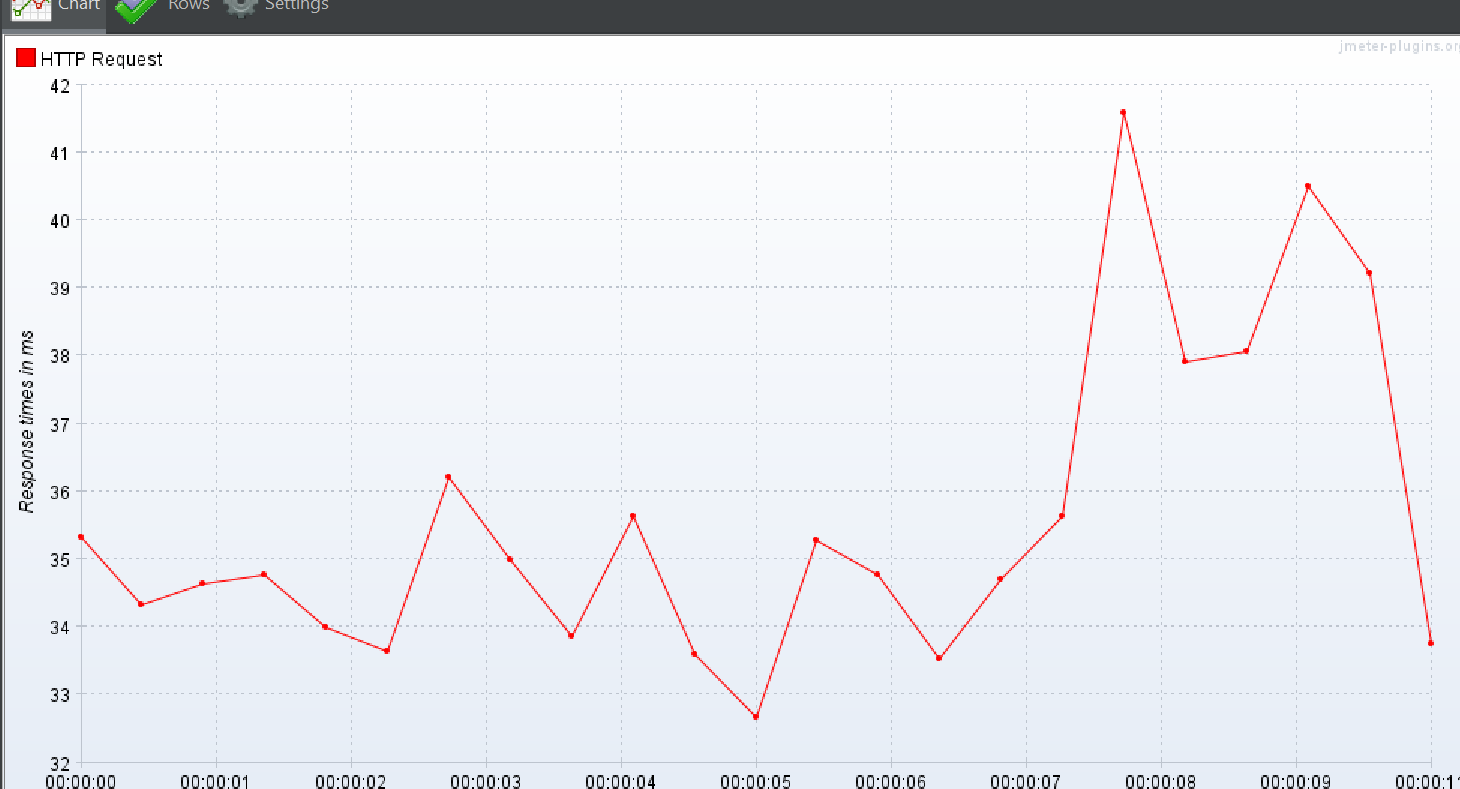
상위 작업 태그 + 하위 작업 태그 둘
즉 /api/v1/employee-posts/search?workFieldId=18&workFieldChildTagId=1&workFieldChildTagId=2&minCareer=&maxCareer=&page=0&size=10&sort=createdAt,desc
이런 형식이다.

Response Over time
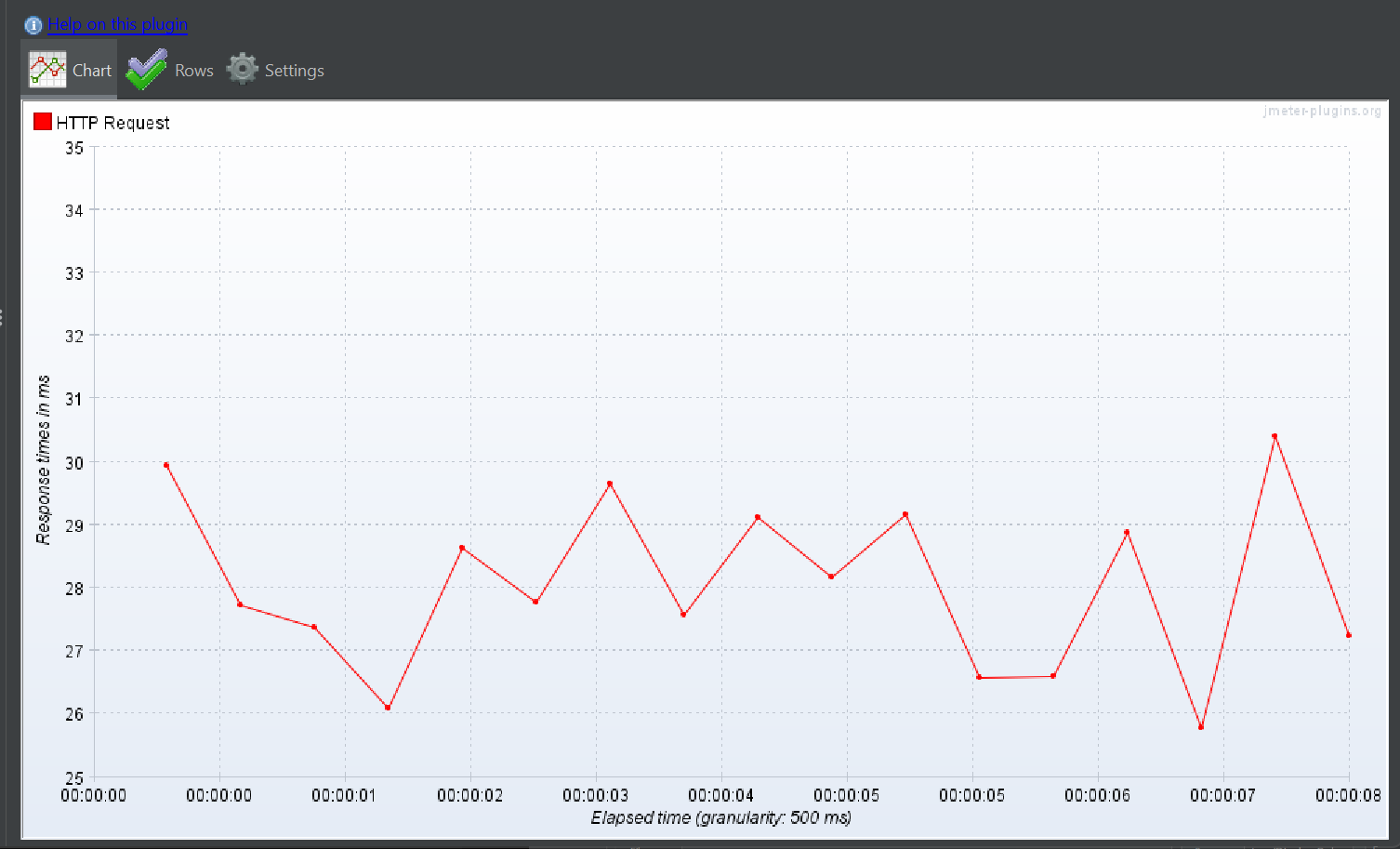
TPS
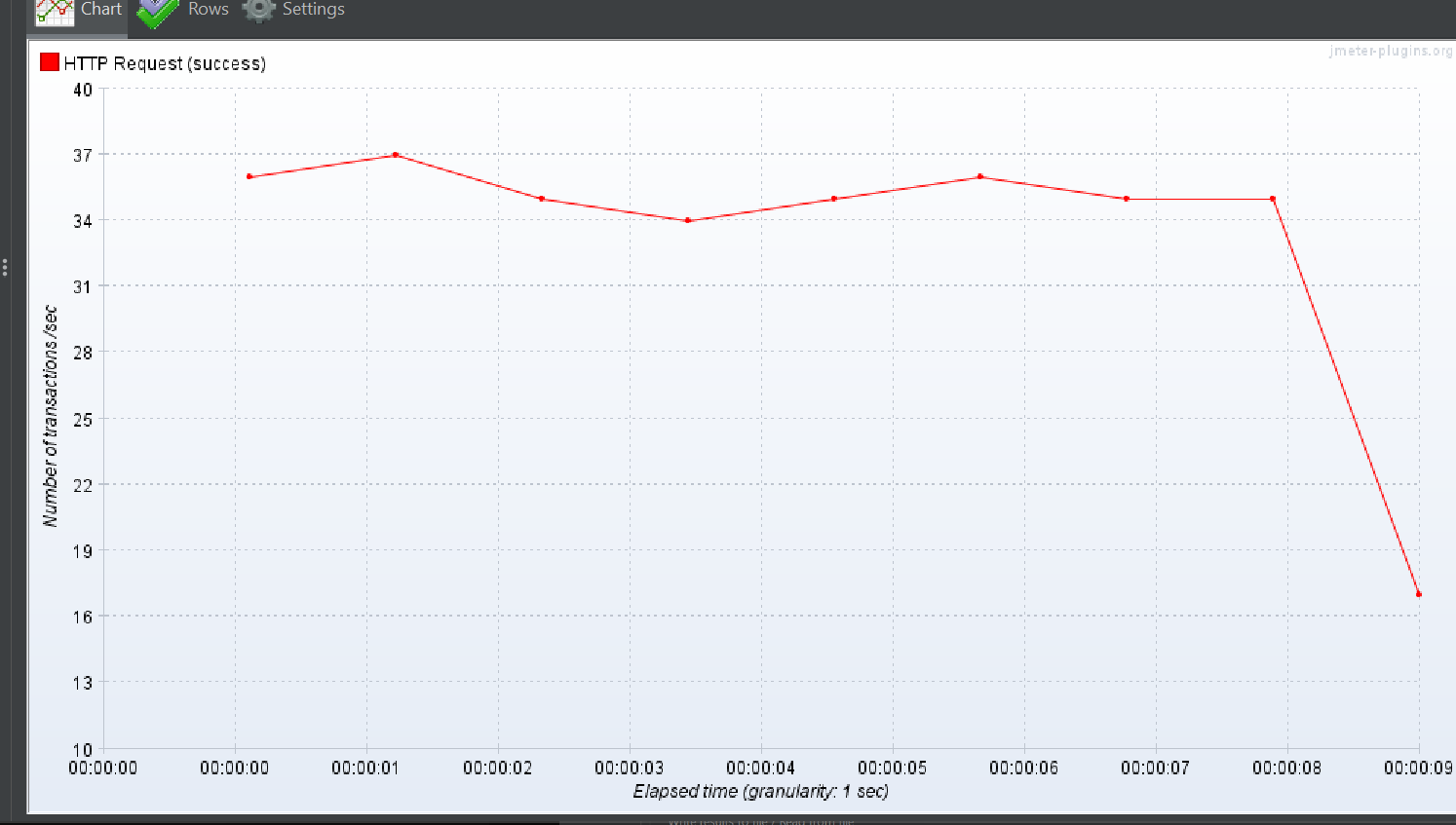
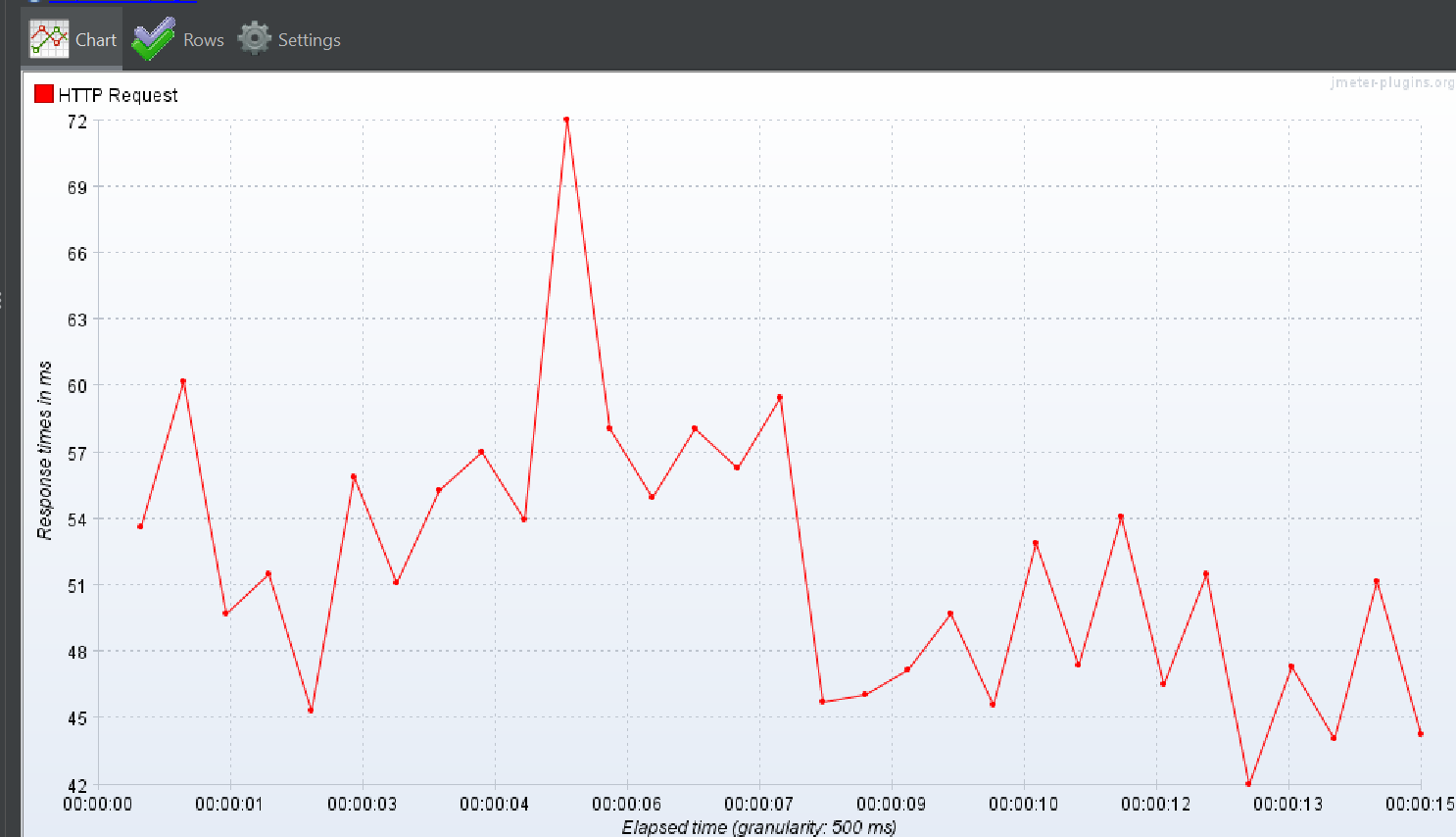
DTO 이용 방식
상위 작업 태그만 명시

Response Over time
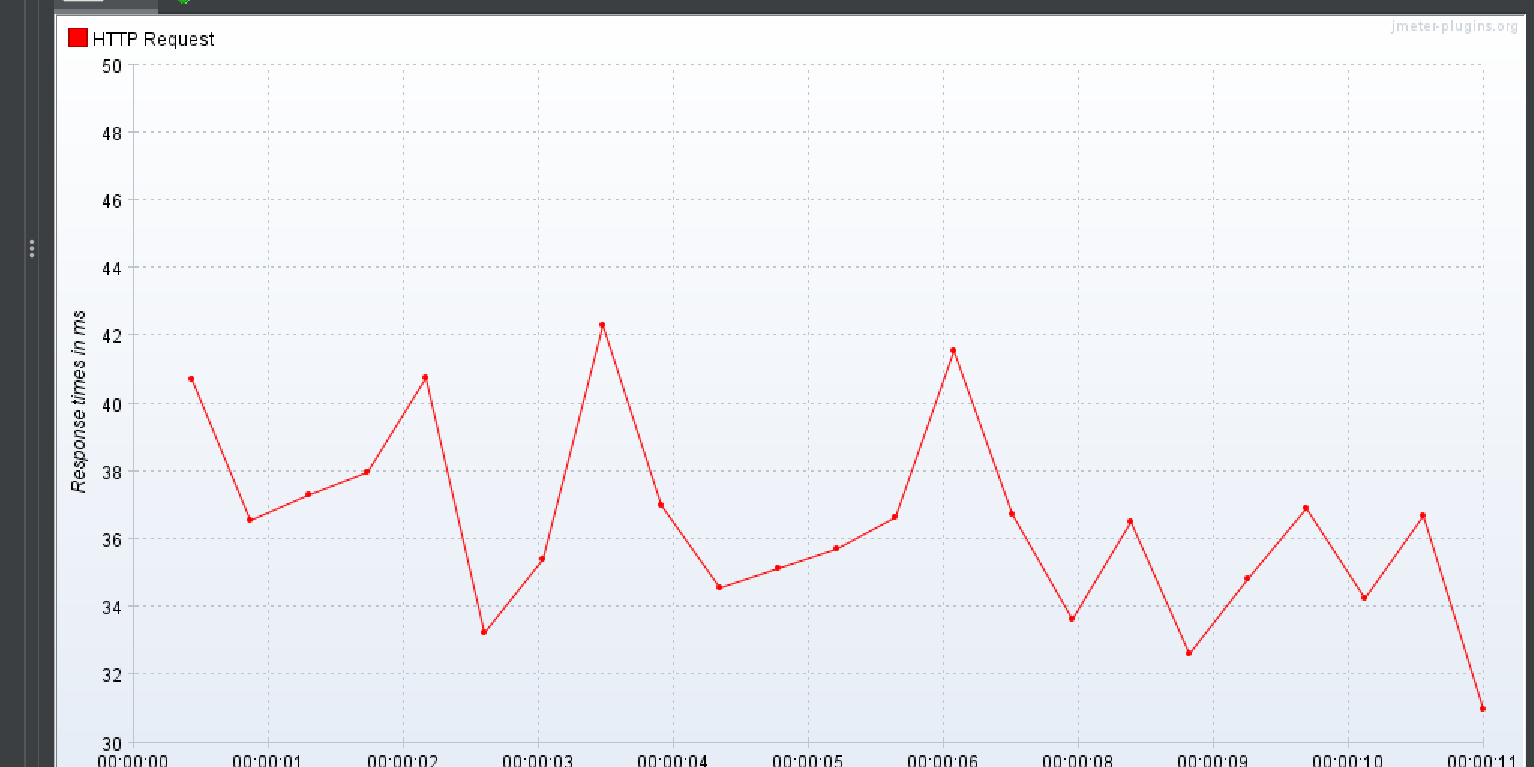
TPS
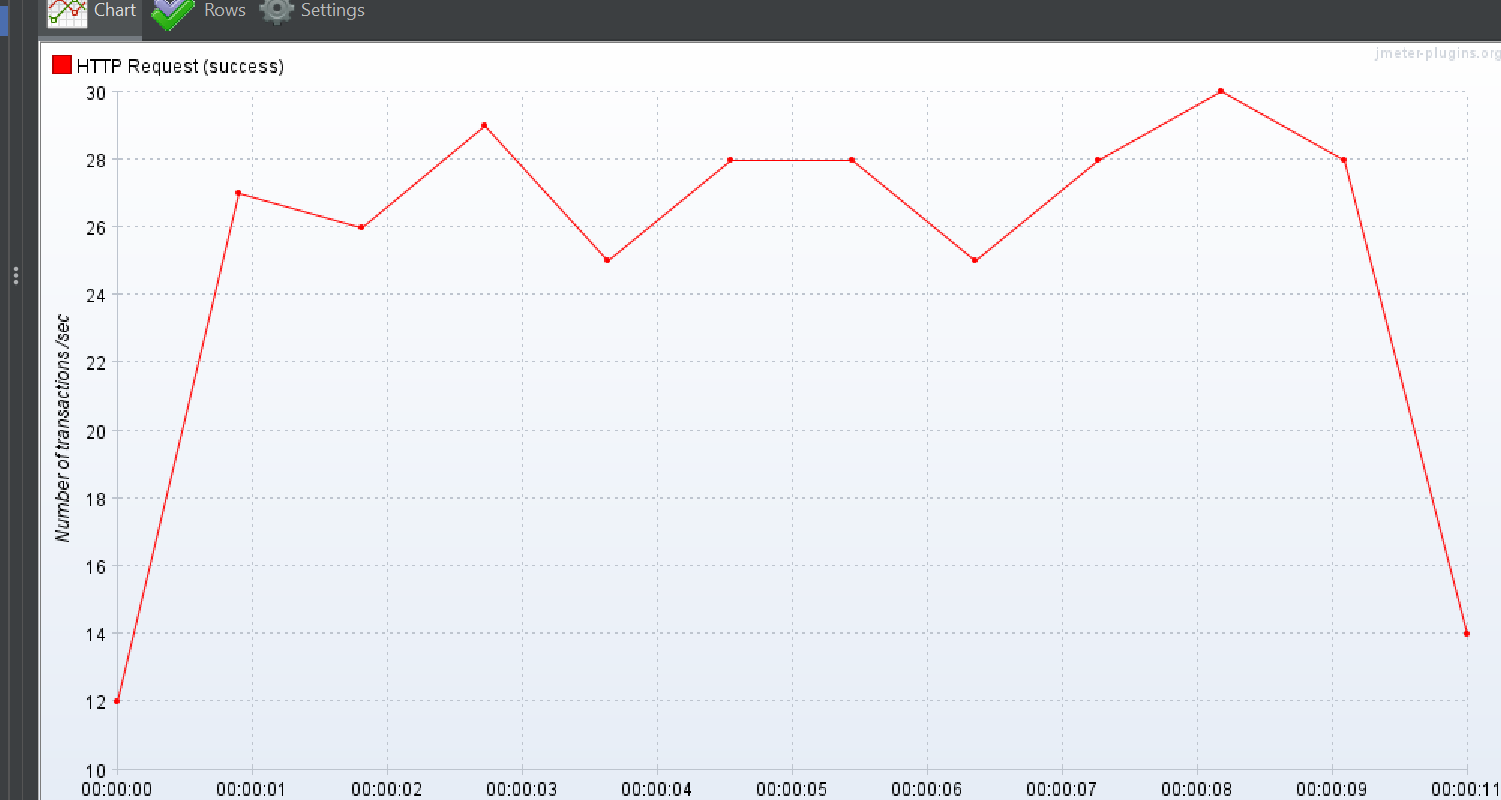
상위 작업 태그 + 하위 작업 태그 하나

Response Over time
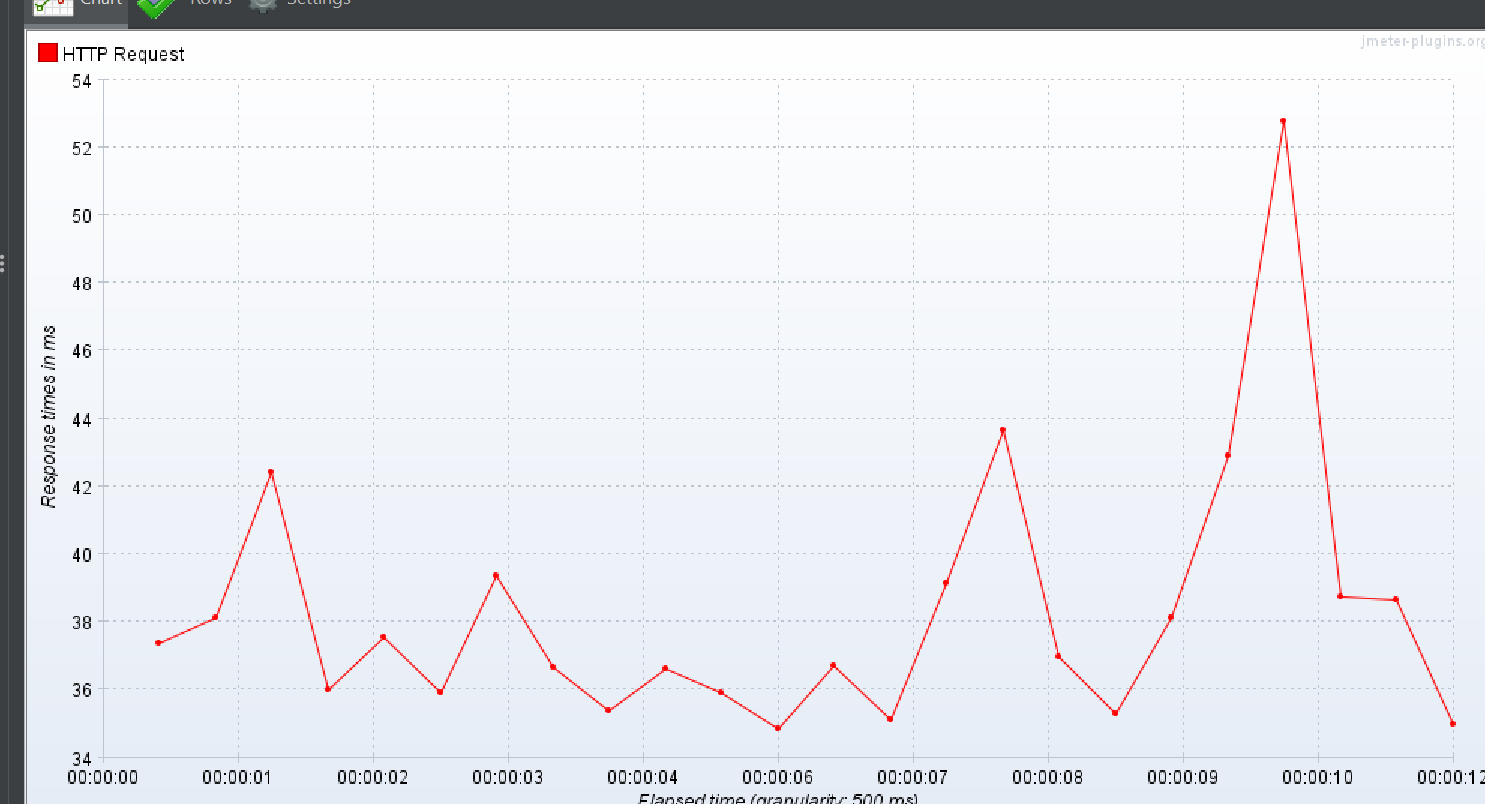
TPS
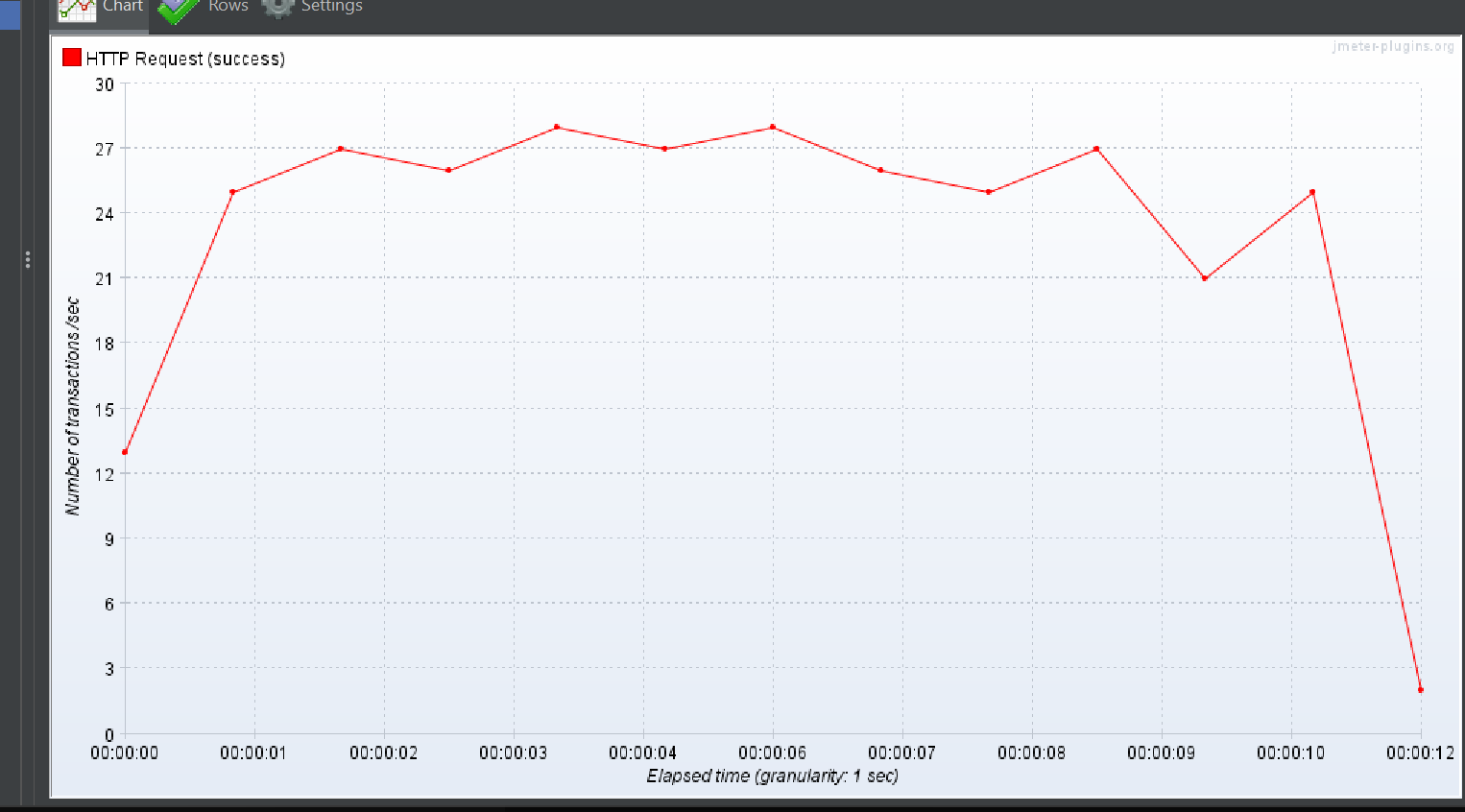
상위 작업 태그 + 하위 작업 태그 둘

Response Over time
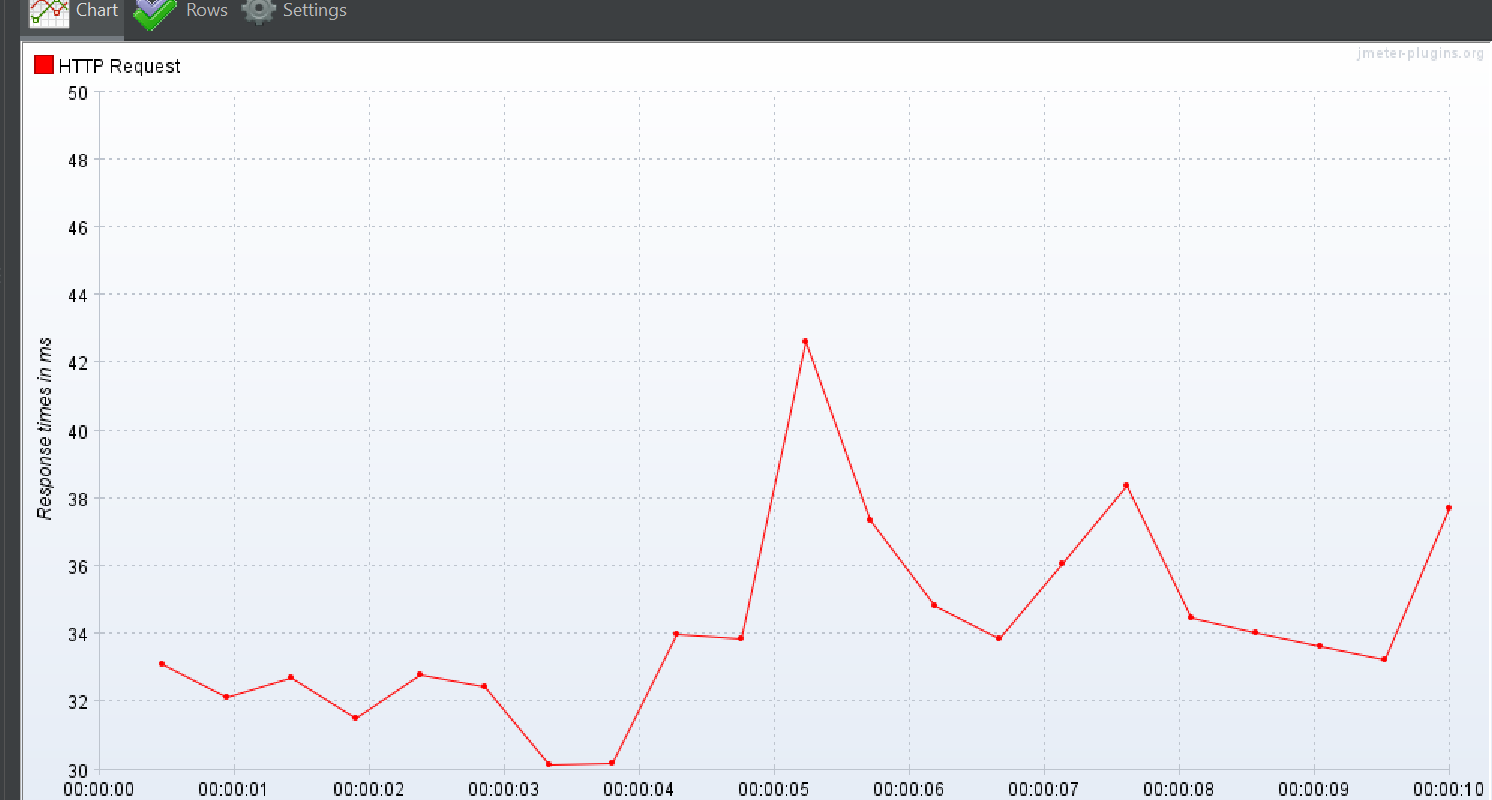
TPS
DTO + batch fetch size
상위 작업 태그만 명시

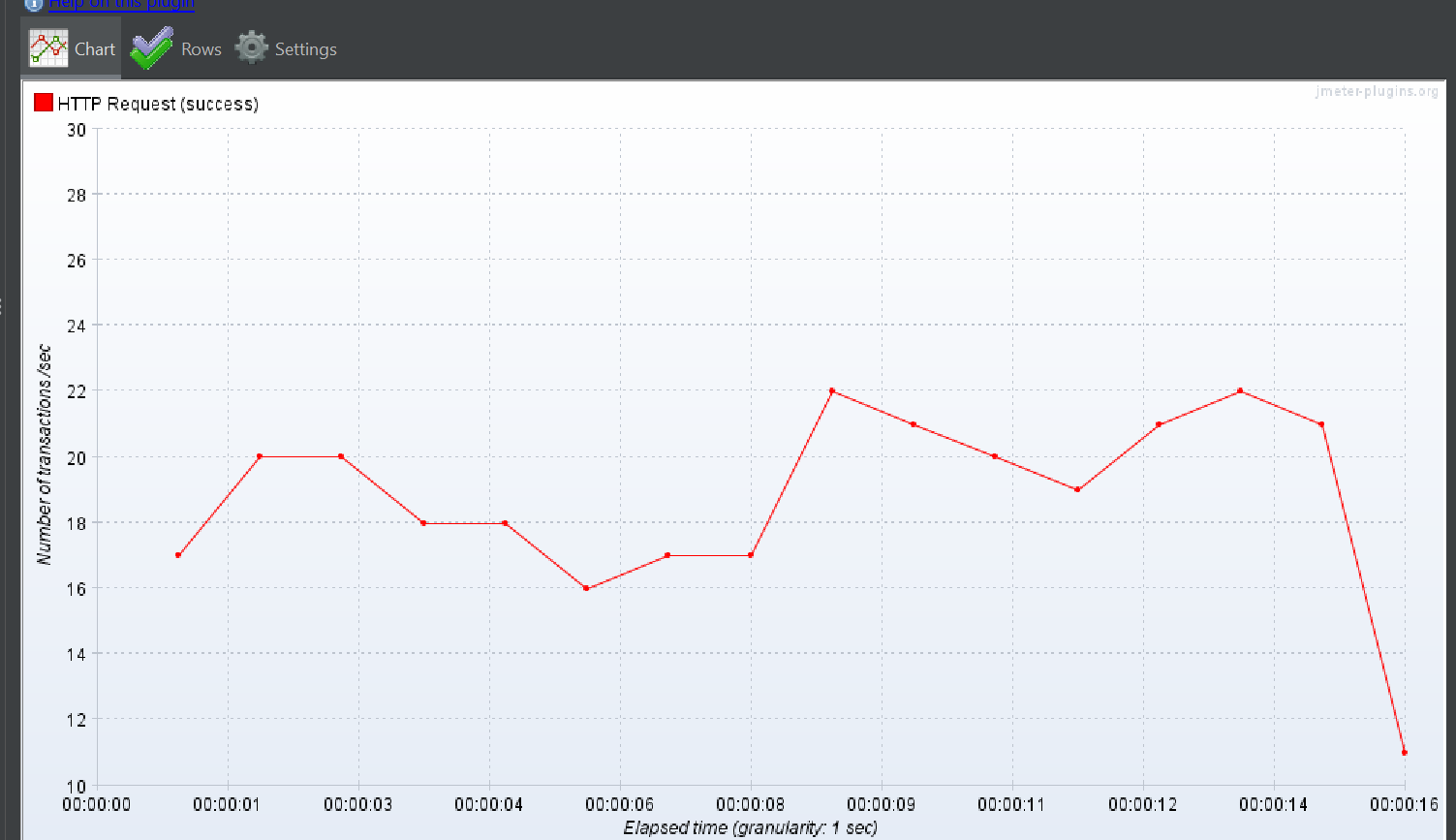
상위 작업 태그 + 하위 작업 태그 하나

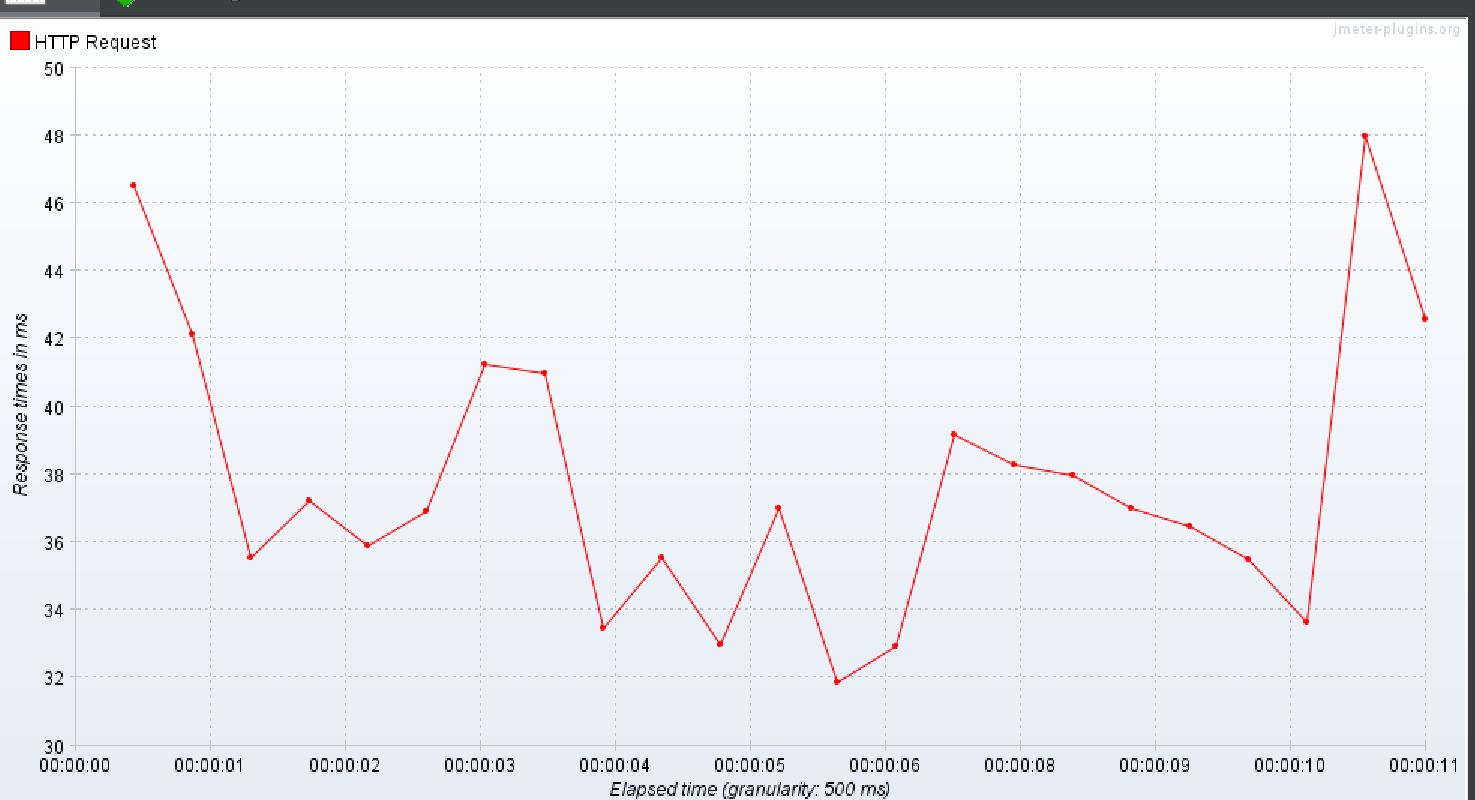
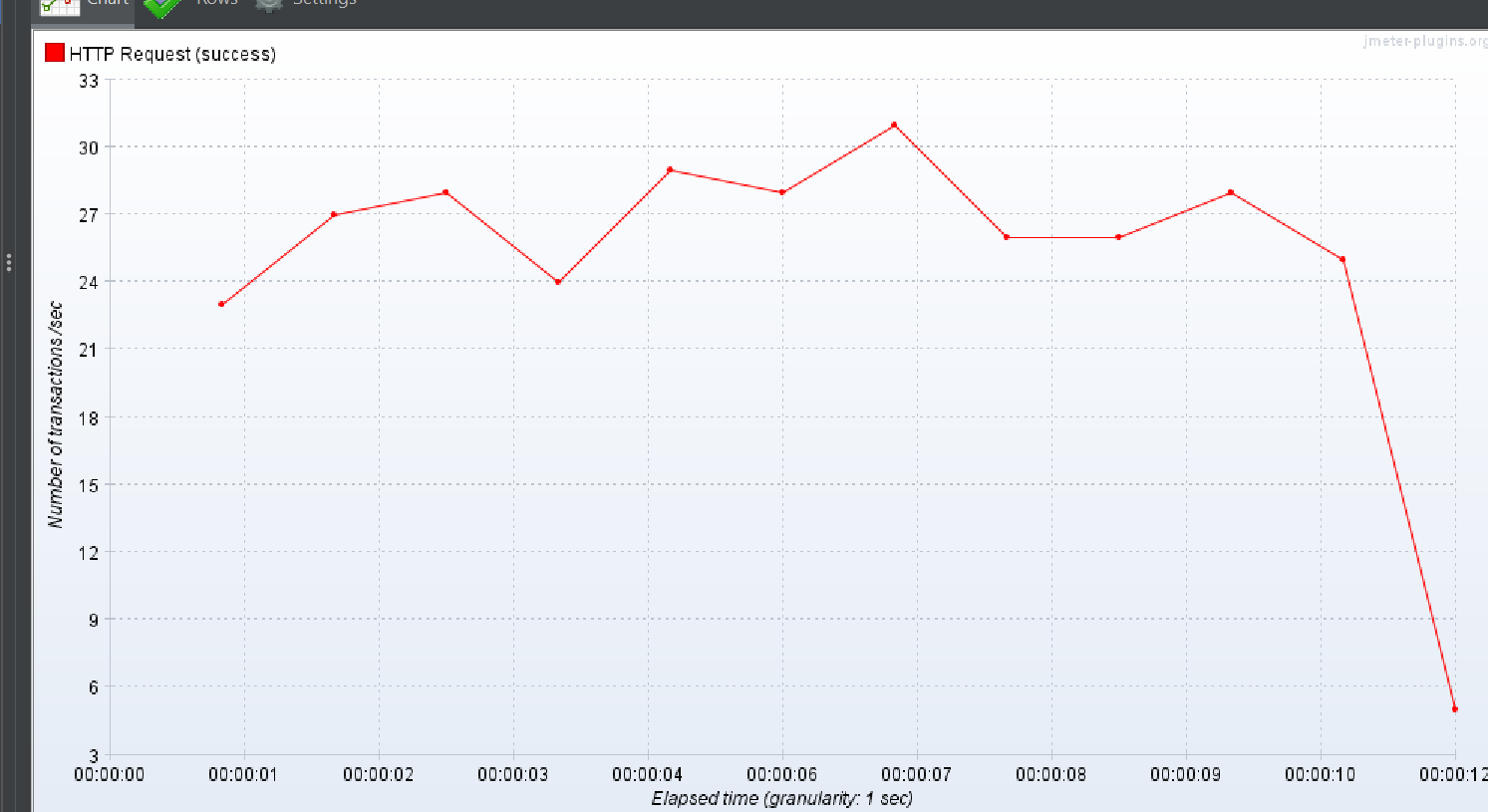
상위 작업 태그 + 하위 작업 태그 둘

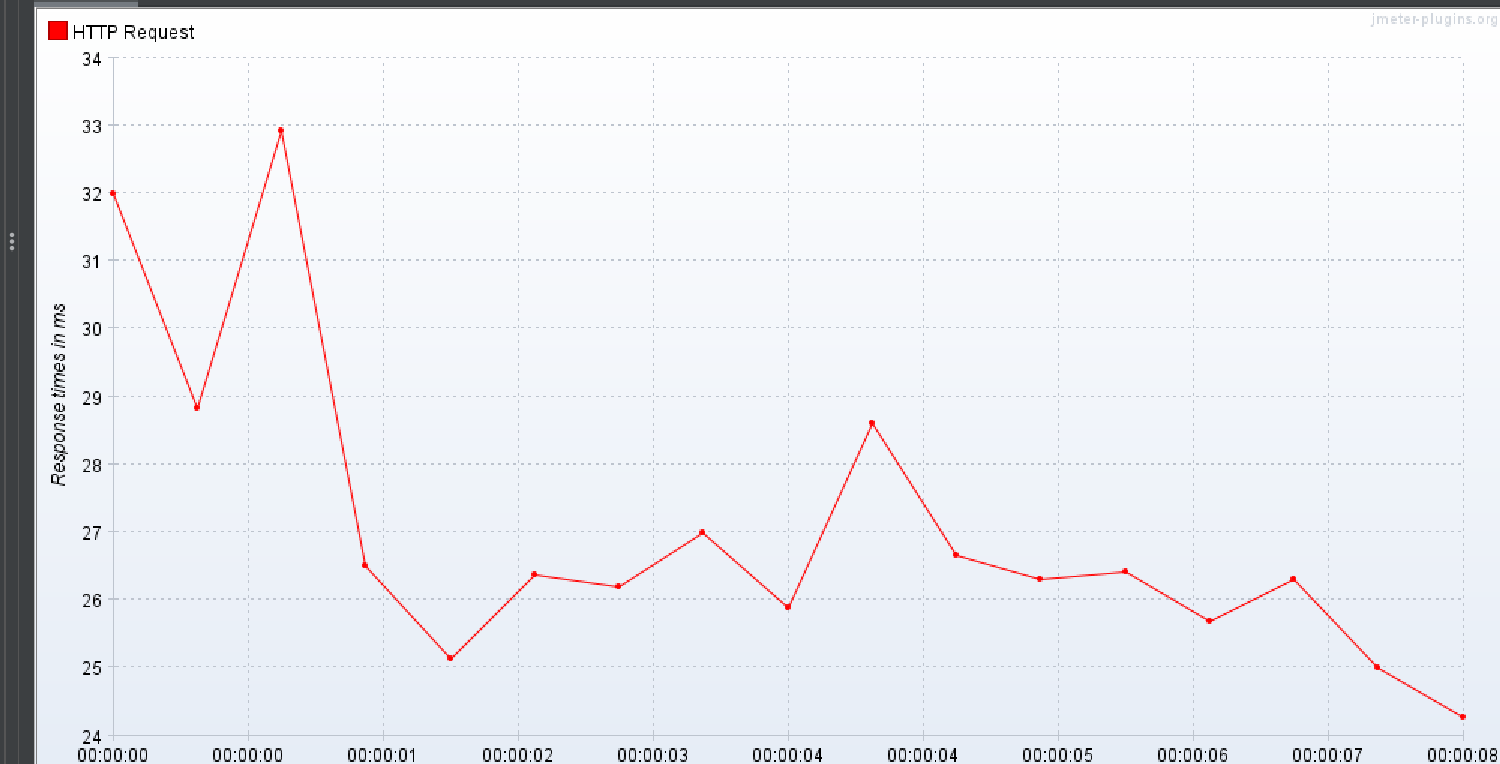
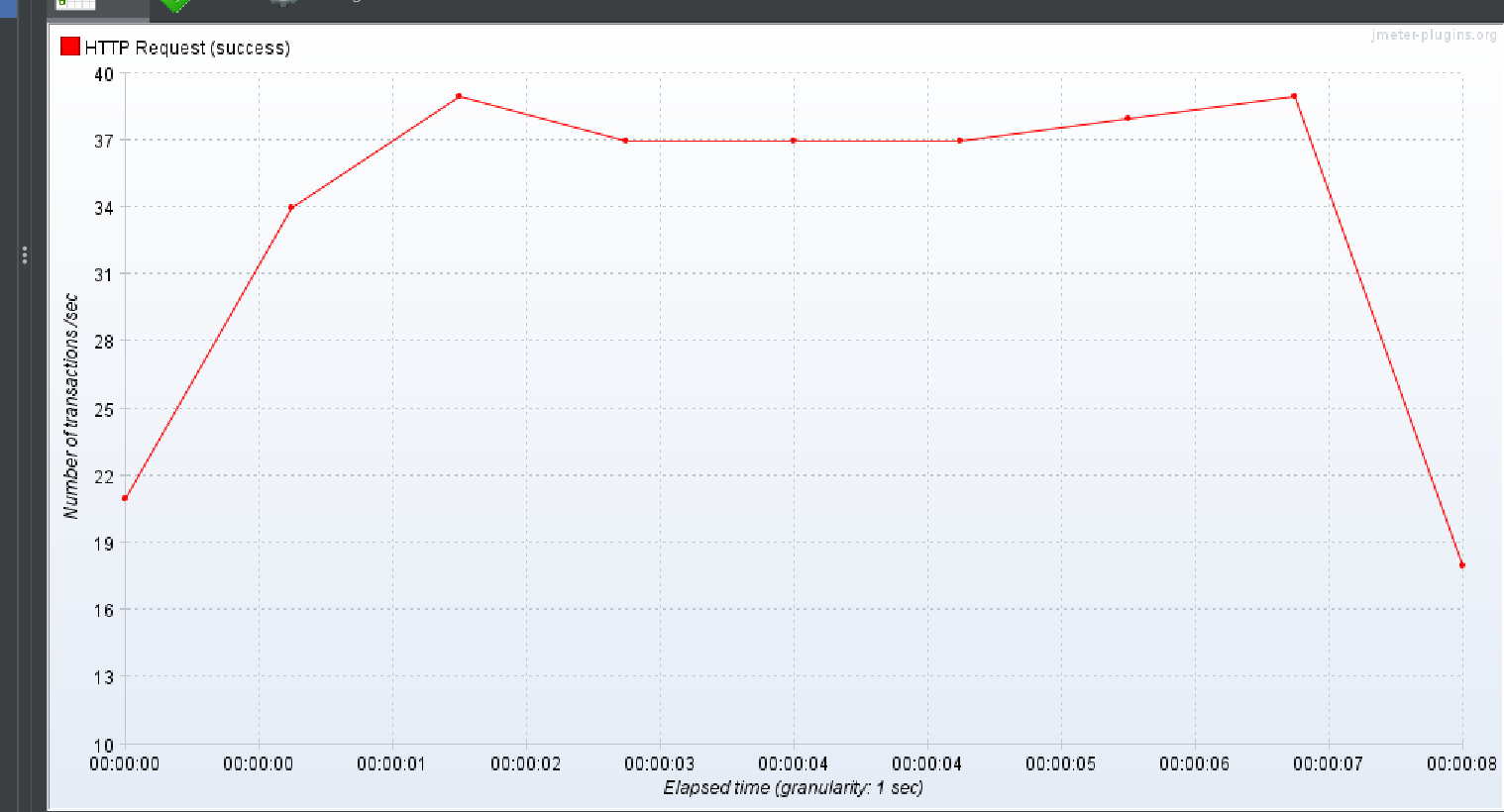
중간 결과
1명의 유저가 300번 반복해서 실행되는 상황을 가정했을 때
평균적인 응답속도 기준으로 다들 그게 그거라는 결론을 얻었다.
다만 DTO 만으로 조회하는 2번쨰 테스트 방식을 제외하고
검색된 데이터 양이 많아짐에 비례하여 평균적인 응답 시간은 증가하고 과 전체적인 TPS 감소하는 결과가 나온다는 것을 깨달았다.
이번에는 다른 환경으로 테스트 하고자한다.
30 명의 유저가 1초동안 각각 10번씩 조회
1초에 30명의 유저의 쓰레드가 각각 실행된다.
이제부터
작업태그(상위태그)만 이용한 테스트를 1번
작업태그 + 하나의 하위태그만 이용한 테스트를 2번
작업태그 + 두개의 하위태그를 이용한 테스트를 3번이라고 가정한다
batch fetch size 만 이용
1번 실행 결과

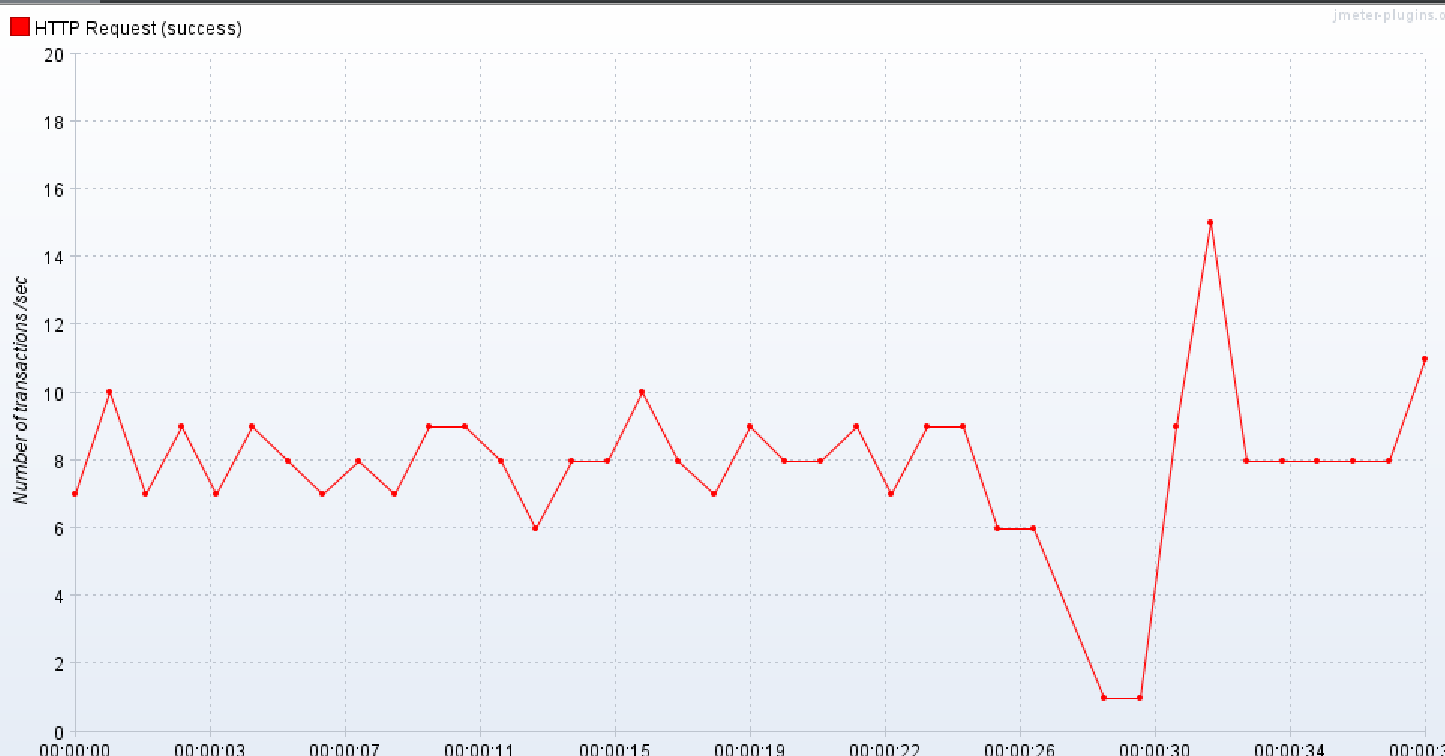
2번 실행 결과

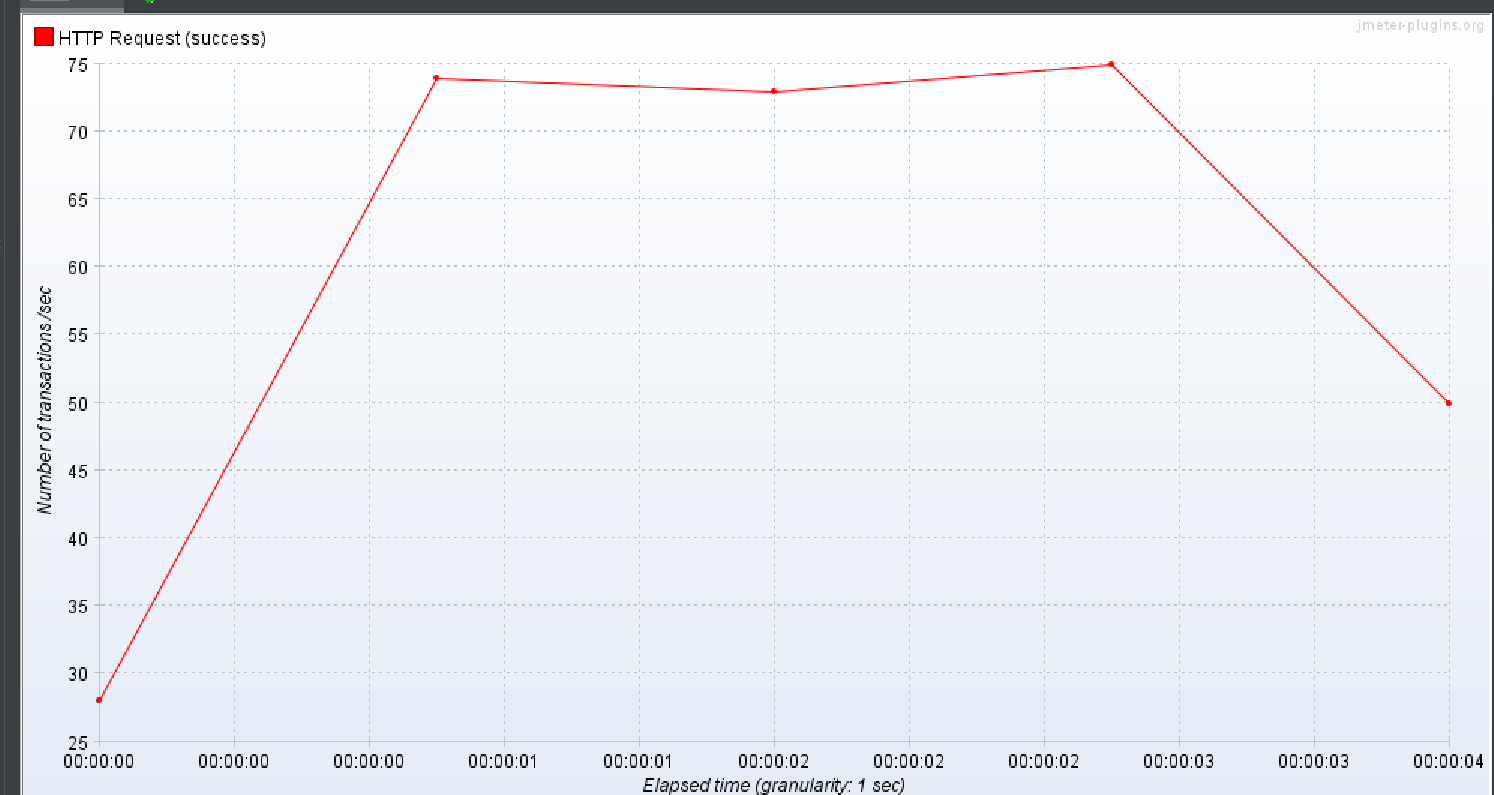
3번 실행 결과

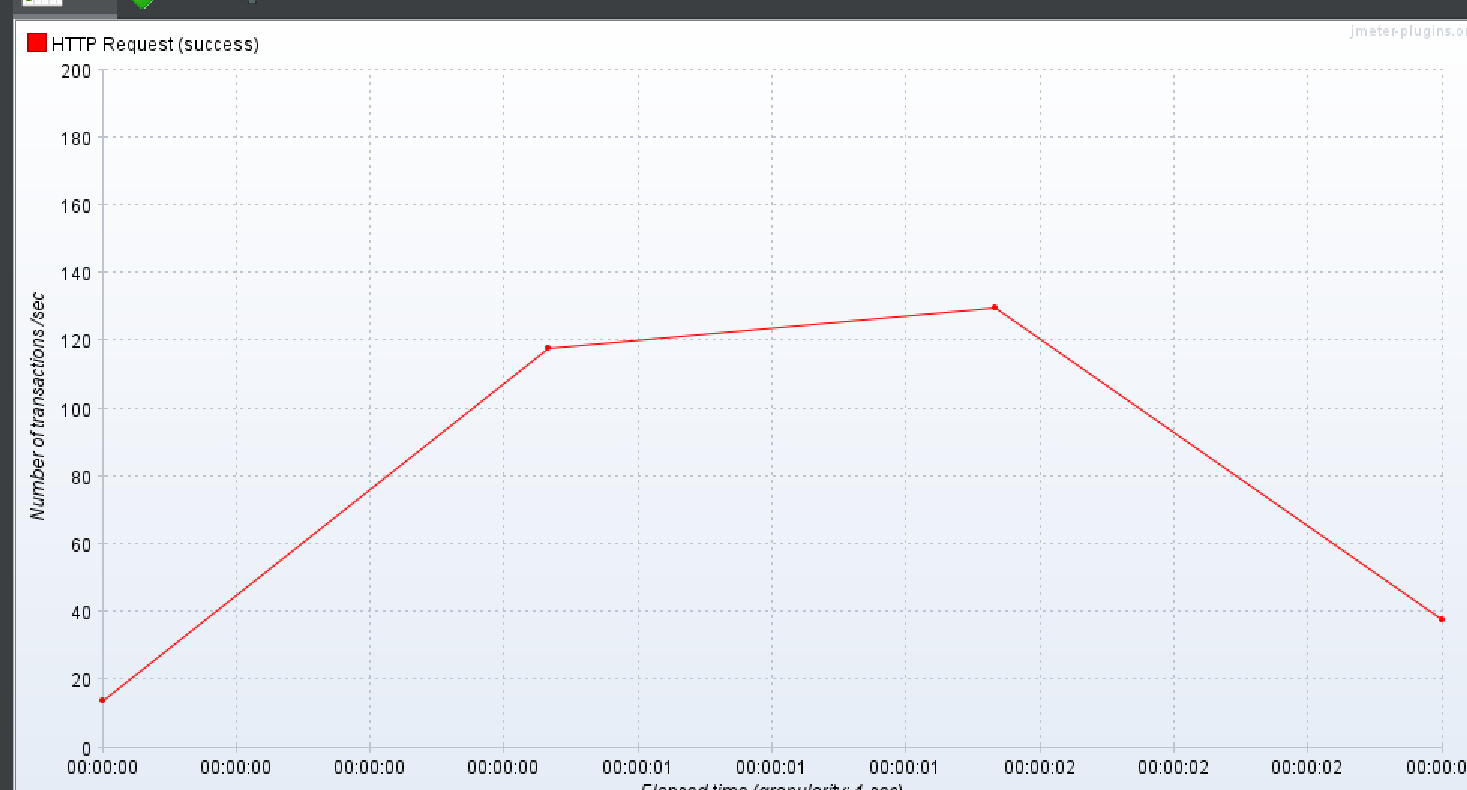
DTO 만 이용
1번 실행 결과

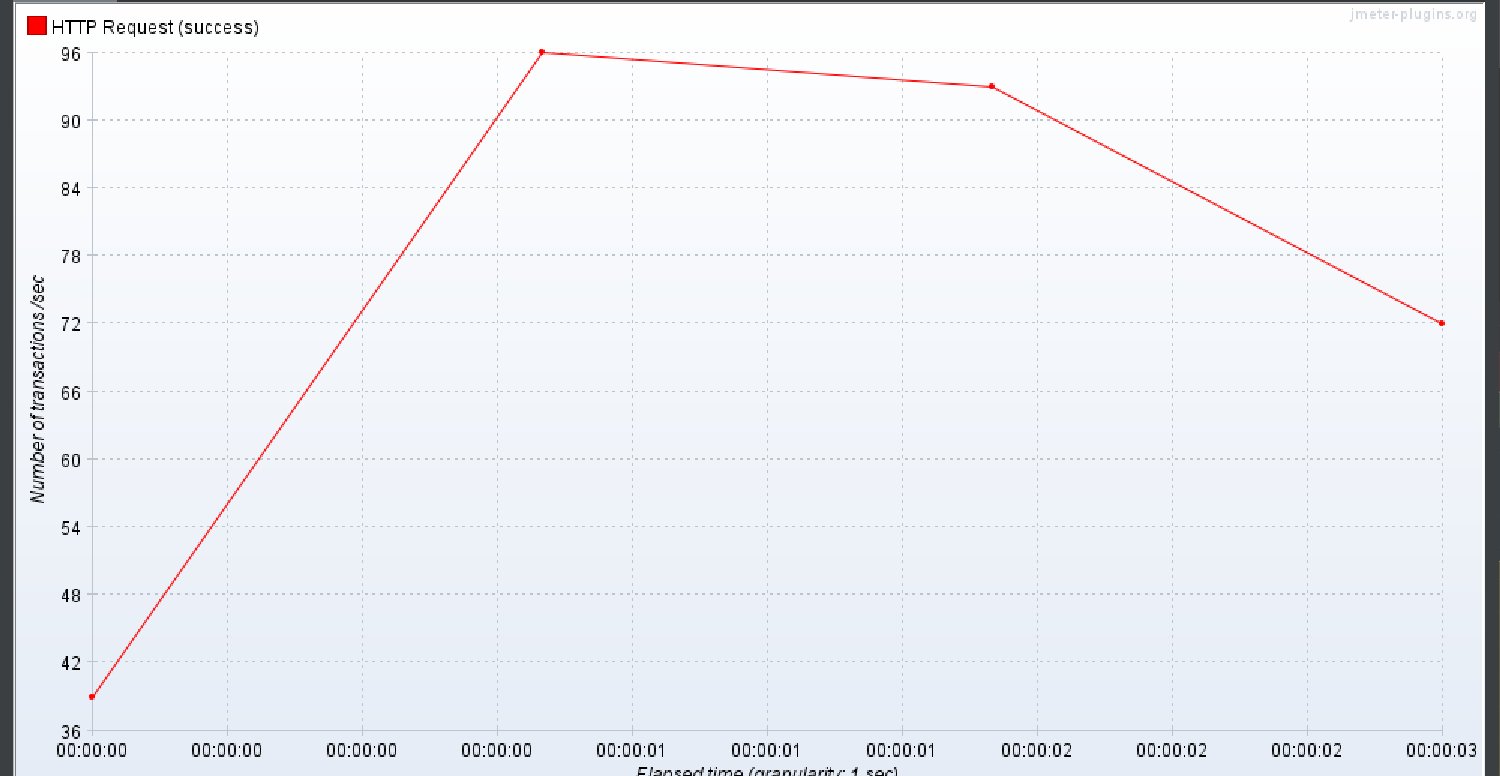
2번 실행 결과

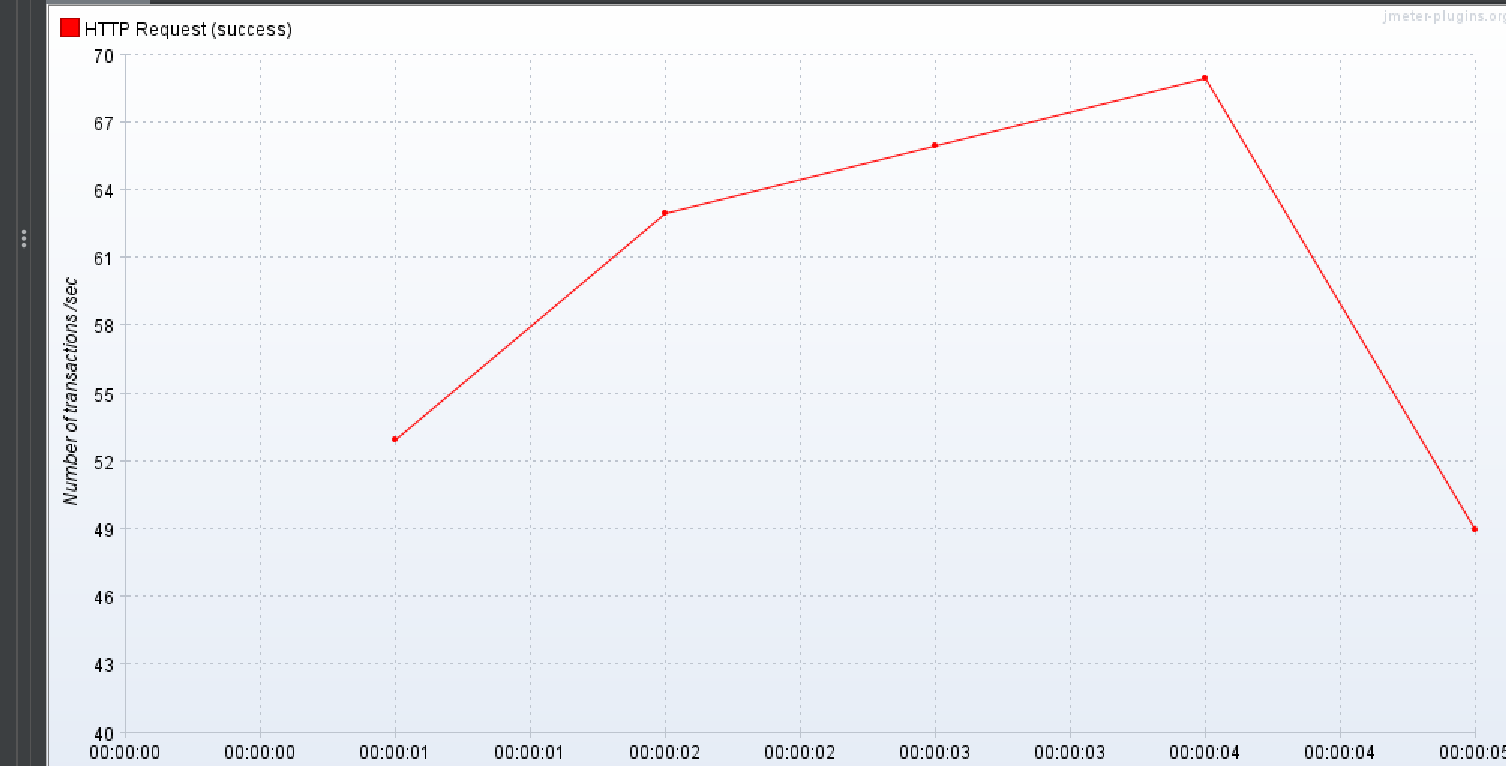
3번 실행 결과

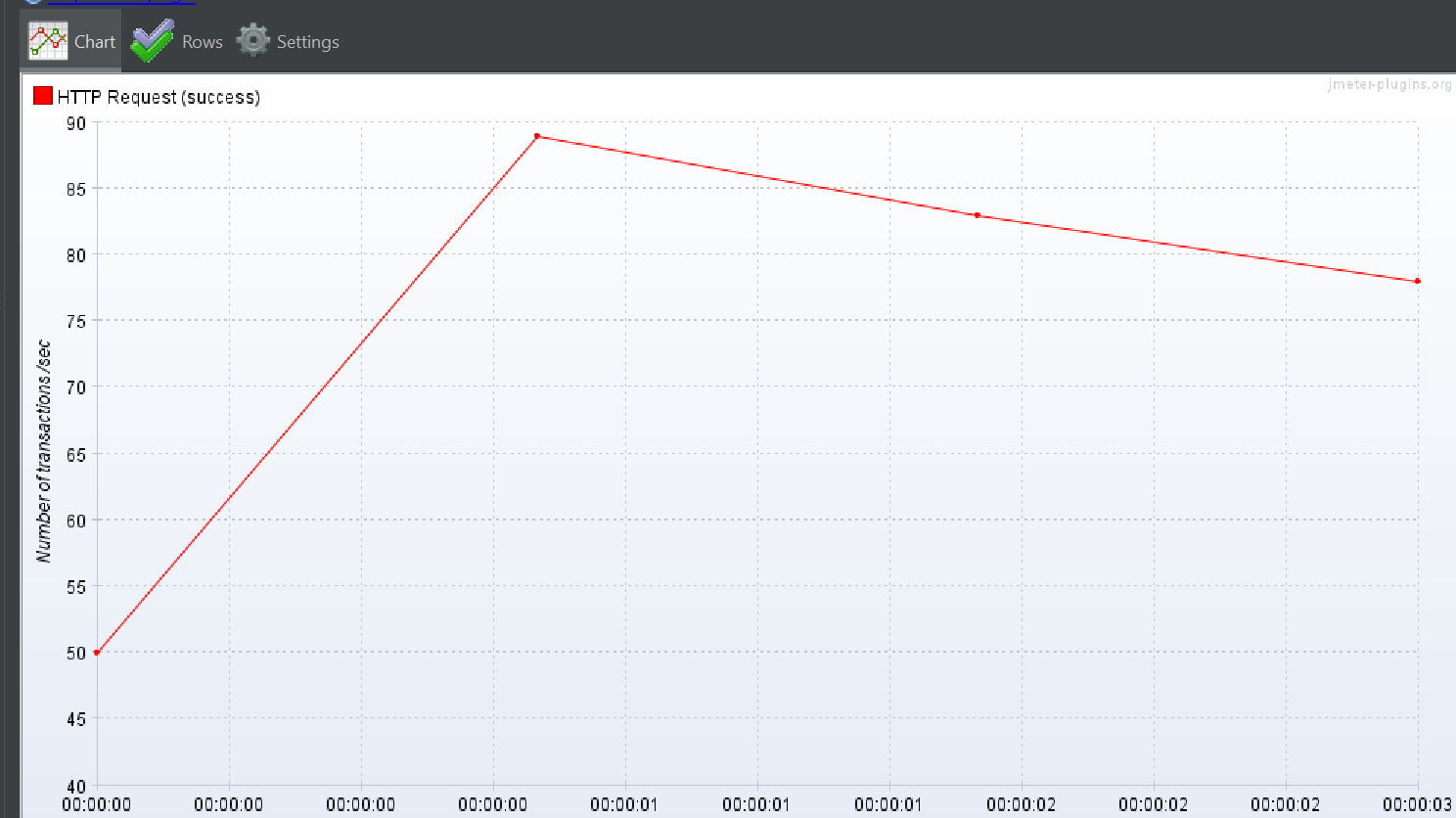
DTO + batch fetch size 혼합
1번 결과

2번 결과

3번 결과

실수로 그래프를 못적었다. ㅠ
중간 결과 2
이번에도 DTO 만을 이용해서 조회하는 방식을 제외하고는
나머지 방식은 데이터가 많을 수록 TPS가 폭발적으로 감소하고 average 는 폭발적으로 증가하는 결과가 생성되었다.
하 원인이 뭘까 찾아보자
이대로 DTO 만을 이용하는 것이 동시에 많은 부하가 있을 수 있는(30명의 유저가 작업 태그를 한번 눌러보는 것) 이 더 TPS 가 좋았고 효율이 좋았기에 채택했다. 라고 하고 끝내고 싶지만 batch fetch size 만 이용한 것과 DTO +batch fetch size 를 이용한 것의 TPS 가 낮은 이유가 뭘까 찾으면 소중한 경험이 되겠다는 생각을 하였다..
가정을 세우자!
아직 경험이 부족하여 ( Member 와 EmployeePost 의 Join, 대용량 칼럼 중심으로 )여러 가정을 세운 이후 테스트를 진행하였댜.
가정 1. Member 와 Employee 가 join 을 하고 페이징을 하는 것이 문제이다.
가정 2. select 절에 칼럼이 많은게 문제이다.
가정 3. select 절에 employeePost 의 contents 와 Member 의 자기소개서 즉 DB에 쿼리 날리기 부담스러운 2개의 대용량 데이터가 있는 것이 문제이다.
가정 4. member 를 join 하면서 employeePost 의 contents가 존재하는게 문제이다.
가정 5. select 절에 employeePost 의 contents 가 존재하는게 문제이다.
1. Batch fetch Size에서 Member 에 대한 fetch join 삭제
EmployeePost 에서 쿼리를 하나라도 덜 날리기 위해서 Member 에 대해서 fetch join 을 진행하였는데
이때
- 대량의 데이터가 조인된 이후에야 페이징 처리가 된다는 점
- select 절에 대량의 데이터가 존재하는 (Employee의 contents, Member 의 자기 소개 ) 상황
을 피하려고
fetch join 을 제거하였다.
이를 통해 TPS 가 향상되면 가정 1, 가정 2, 가정 3, 가정 4 모두 참이 되고 가정 5를 제외할 수 있다.
결과

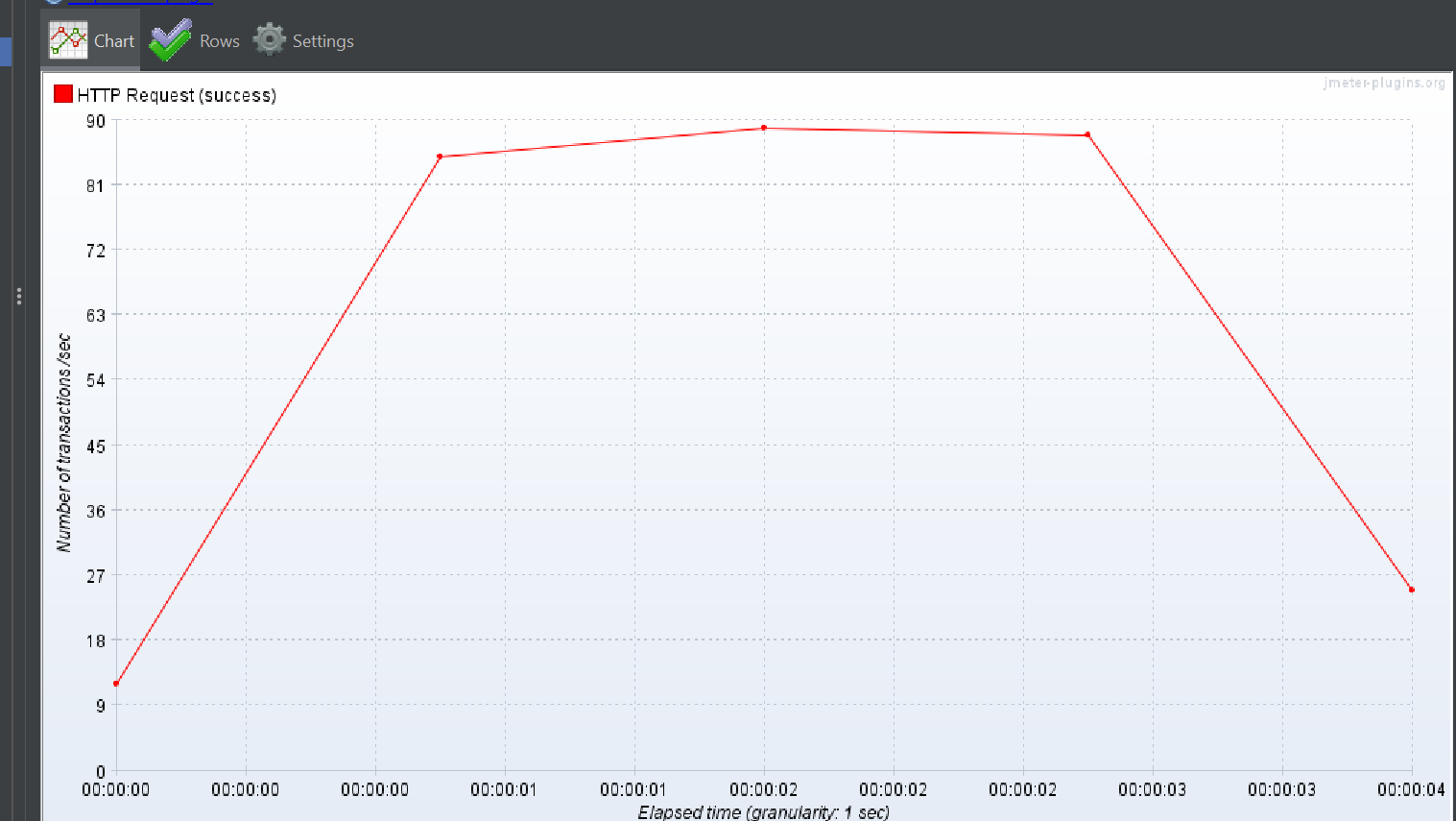
위 와 같이 TPS 가 크게 향상 되었기 때문에 가정 5롤 제외할 수 있습니다.
2. DTO 만을 통한 조회에서 대용량 칼럼인 contents 를 select 절에 삽입
사이즈 큰 칼럼을 가져오는 작업은 힘든 작업일 수 밖에 없다.
만약 이를 시도하였을 때
TPS 가 낮아진다면
위에서 가정 1 , 3을 제외할 수 있다.
따라서 아래와 같이 쿼리를 수정한다.
.select(Projections.constructor(EmployeeSearchResponseDto2.class,employeePost.id,employeePost.basicPostContent.title,
employeePost.basicPostContent.workFieldTag,
employeePost.basicPostContent.member.name,employeePost.basicPostContent.accessUrl,employeePost.basicPostContent.member.sex,employeePost.basicPostContent.member
.birthDay,employeePost.basicPostContent.contents))기존과 달라진점은 contents 가 추가되었다는 점
결과

tps 가 크게하락했다. 이 결과는 위의 가정 1,3을 제외할 수 있다.
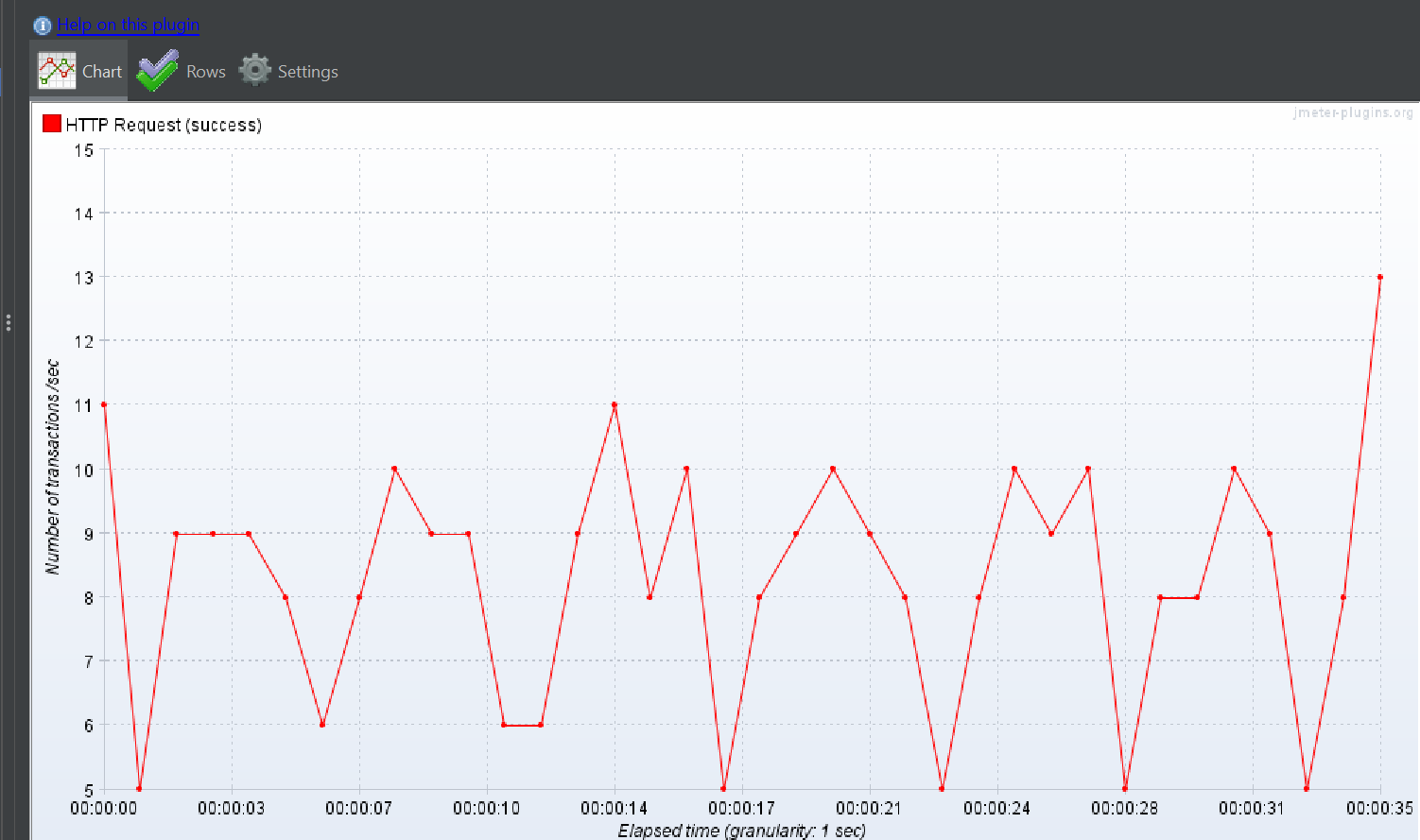
3. DTO + batch fetch size 를 통한 조회에서 칼럼을 대용량 데이터(contents)를 제외한 전부를 추가한다.
이를 통해 성능이 개선되면 , TPS 가 증가하면
가정 2를 날릴 수 있다.
칼럼 자체의 개수는 더 많으니까!!
결과

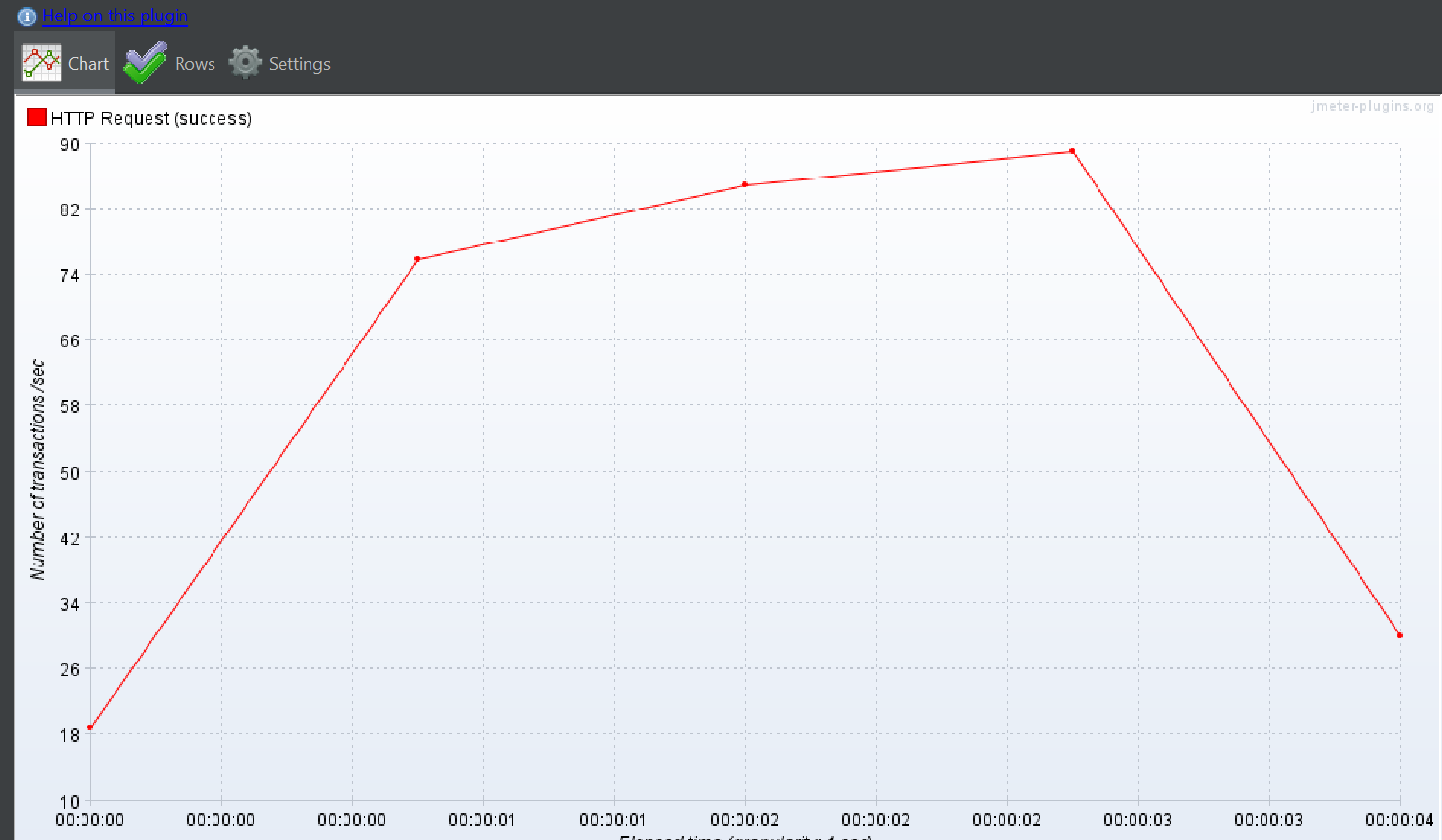
성능이 미친듯이 향상되었다. TPS 또한 마찬가지이다.
결론
기존에는 쿼리를 하나라도 더 줄이는 것이 성능과 속도에 직결 되는 문제라고 생각했다.
하지만 이번 실험을 통해 쿼리를 하나라도 더 줄이는 것보다 즉 fetch join 을 붙여 select 절에 함께 조회하여 쿼리 갯수를 하나라도 더 줄이는 것보다
그로 인해 발생할 수 있는 join 과 select 절에 포함되는 대용량 칼럼이 존재하였을 때
유저가 20~30 명이 1초에 동시에 조회하였을 때
TPS가 급속하게 낮아질 수 있고 이로 인해 사용자는 쿼리 조회만 하더라도 3초이상의 시간이 걸릴 수 있다는 것을 깨달았다.
