현상황
open api 를 통해 영화 및 프로그램을 검색하고
open api 를 통해 영화 데이터를 미리 저장하기 보다(open api의 데이터가 9999개의 데이터가 넘어오면 오류)
사용자가 검색을 수행했을 때 그것이 이미 DB에 저장된 경우 그 값을 반환하고, 저장되지 않은 경우 저장 후 반환을 하는 상태입니다.
DB에 저장하는 이유는 DB에 저장하여 다른 로직에서 api 호출을 조금이라도 더 줄이고자 하는 목적도 있으며 무엇보다 다른 비즈니스 로직을 수행하는데 필요하기 때문입니다.
문제점
여러 영화 및 프로그램 정보를 검색하고 검색한 프로그램 list 데이터가 DB에 저장되어 있지 않은 경우 저장하고 반환. 이미 저장된 경우 그 프로그램을 반환
@Override
@Transactional
public SearchResponseDto searchByName(String name) {
//tvResponse 를 검색한 DTO 를 반환합니다.
SearchTvResponseDto searchTvResponseDto = searchByTvName(name, 1);
//영화를 검색하며 DB에 저장하되 반환하는 것은 갯수 뿐입니다.
OpenApiSearchTrendingDto movieSearchList = getSearchProgram("movie", name, 1);
movieSearchList.getResults().stream().forEach(openApiProgram -> {
saveProgramAndGetProgram(openApiProgram, ProgramType.Movie);
});
int movieCount = movieSearchList.getTotal_results();
return new SearchResponseDto(movieCount, searchTvResponseDto.getTotalResults(),
searchTvResponseDto);
}
//영화를 page 별로 검색할 수 있습니다.
@Override
@Transactional
public SearchMovieResponseDto searchByMovieName(String name, int page) {
//movieSearchInfos 에 관련 내용을 담습니다
List<ProgramSearchInfo> movieSearchInfos = new ArrayList<>();
//open api를 통해 검색 결과를 받아옵니다.
OpenApiSearchTrendingDto movieSearchList = getSearchProgram("movie", name, page);
//저장하고 DTO를 설계합니다
movieSearchList.getResults().stream().forEach(movieProgramInfo -> {
Program program = saveProgramAndGetProgram(
movieProgramInfo,
ProgramType.Movie);
String firstGenreName = getProgramFirstGenre(movieProgramInfo.getGenre_ids());
movieSearchInfos.add(new ProgramSearchInfo(program.getId(), program.getTitle(),
movieProgramInfo.getRelease_date(), firstGenreName, program.getPosterPath(),
movieProgramInfo.getOverview()));
});
return new SearchMovieResponseDto(movieSearchInfos, movieSearchList.getPage(),
movieSearchList.getTotal_pages(), movieSearchList.getTotal_results());
}
데이터가 저장되어 있으면 그 program 을 반환하고 그렇지 않으면 저장해서 반환하는 메서드
public Program saveProgramAndGetProgram(
SearchTrendingOpenApiProgramInfo searchTrendingOpenApiProgramInfo,
ProgramType programType) {
Program program = programRepository.findByTmDbProgramIdAndType(
searchTrendingOpenApiProgramInfo.getId(), programType).orElseGet(() -> {
Program newProgram = apiProgramToProgram(searchTrendingOpenApiProgramInfo, programType);
programRepository.save(newProgram);
return newProgram;
});
return program;
}serachByName 과 SearchByMovieName을 동시에 호출하였을 때 영화데이터가 중복 되는 현상이 일어났습니다.
원인
searchByName 과 serachByMovieName이 동시에 실행된다면 바로 위 메서드(saveProgramAndGetProgram) 에서 일어나는 일을 설명해 보겠습니다.
searchByMovieName에서saveProgramAndGetProgram->select쿼리 실행->데이터가 없다고 판단했기에 DB에 저장.searchByName에서saveProgramAndGetProgram->select쿼리 실행->데이터가 없다고 판단했기에 DB에 저장.
위 1번 2번에 동시에 실행 됬기 때문에 이런 현상이 발생하게 되었습니다.
아래 테스트 코드를 보면
@SpringBootTest
public class ProgramTest {
@Autowired
private ProgramShowAndSaveService programShowAndSaveService;
@Test
@Rollback(value = false)
@Transactional
void testing() throws InterruptedException {
int numberOfThreads = 2;
ExecutorService executorService = Executors.newFixedThreadPool(numberOfThreads);
CountDownLatch latch = new CountDownLatch(numberOfThreads);
executorService.execute(() -> {
programShowAndSaveService.searchByName("겨울");
latch.countDown();
});
executorService.execute(() -> {
programShowAndSaveService.searchByMovieName("겨울", 1);
latch.countDown();
});
latch.await();
}
}이렇게 해봅니다. 만약 동시에 호출되면 각각의 메서드가 쓰레드 별로 실행되니 위와 같이 코드를 작성해보았습니다.
이를 Run 해보고 DB를 확인해보겠습니다.


위와 같이 DB에 동시에 2개가 저장되며
select tm_db_program_id,type,count(*) as count
from program
group by tm_db_program_id,type
having count>1;
위와 같이 쿼리를 실행시켜보면
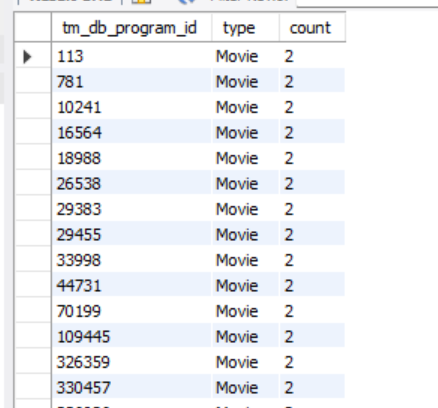
수많은 데이터가 중복 저장됨을 알 수 있습니다.
쓰레드가 여러개다?
확실하진 않지만 제가 이해한 바를 적어보겠습니다. !동시성 문제는 여러 쓰레드가 같은 자원에 접근 할 때 사용됩니다.
그러나 현재 EC2는 1코어로 하나의 쓰레드만 가지고 있는데 어떻게 여러 쓰레드가 같은 자원에 접근하는 경우가 있는지 궁금했었는데
소프트웨어 쓰레드는 하드웨어 쓰레드를 사용하지만 그 개수는 여러개로 늘어날 수 있으며 하드웨어 쓰레드를 여러 쓰레드가 돌아가며 참조하는 느낌인 것 같습니다.
해결방법
1.Redisson 을 사용해서 Lock 해보기
build.gradle 추가
implementation group: 'org.redisson', name: 'redisson', version: '3.24.3'오류
기존 swagger 와 같이 세팅 시 오류가 발생할 수 있습니다.
org.springframework.context.ApplicationContextException: Failed to start bean 'documentationPluginsBootstrapper'; nested exception is java.lang.NullPointerException위와 같은 오류가 발생하면
위를 참고해서 해결하거나
redisson 버젼을 사람들이 많이 쓰는 것으로 바꿔보시기 바랍니다. ㅎ
코드
테스트를 위해 아래의 코드를 그대로 사용했습니다
https://devoong2.tistory.com/entry/Spring-Redisson-%EB%9D%BC%EC%9D%B4%EB%B8%8C%EB%9F%AC%EB%A6%AC%EB%A5%BC-%EC%9D%B4%EC%9A%A9%ED%95%9C-Distribute-Lock-%EB%8F%99%EC%8B%9C%EC%84%B1-%EC%B2%98%EB%A6%AC-1
부가적인 이해
@Component
public class AopForTransaction {
@Transactional(propagation = Propagation.REQUIRES_NEW)
public Object proceed(final ProceedingJoinPoint joinPoint) throws Throwable {
return joinPoint.proceed();
}
}위 코드에서 Propagation.REQUIRES_NEW 를 해주는 이유는
부모 트랜잭션으로 부터 분리하기 위함입니다.
만약 부모 트랜잭션으로 부터 분리하지 않으면 어떤 일이 발생할 수 있을까요??
1)사용자 A의 코드실행->2)트랜잭션 시작->3)Lock 잡기 -> 4) select 쿼리 실행해서 없는 경우 DB에 써주기 ->5)Lock해제 ->6) 변경사항 커밋
만약 사용자 B의 코드가 실행되어서 A의 Lock에 의해서 기다리고 있습니다.
Lock 이 해제 되어서 B의 코드가 Lock을 잡고 select 쿼리를 실행해서 보면 아직 A의 변경사항이 커밋되지 않았기 때문에 없다고 생각해서 DB에 다시 저장하는 경우가 생길 수 있습니다.
물론 이는 부모 트랜잭션이 있을 때의 일을 가정한 것입니다.
주의점
위를 바탕으로 코드를 수정해봅니다.
ProgramShowAndService
@Override
@Transactional
public SearchResponseDto searchByName(String name) {
//tvResponse 를 검색한 DTO 를 반환합니다.
SearchTvResponseDto searchTvResponseDto = searchByTvName(name, 1);
//영화를 검색하며 DB에 저장하되 반환하는 것은 갯수 뿐입니다.
OpenApiSearchTrendingDto movieSearchList = getSearchProgram("movie", name, 1);
movieSearchList.getResults().stream().forEach(openApiProgram -> {
saveProgramAndGetProgram(openApiProgram, ProgramType.Movie);
});
int movieCount = movieSearchList.getTotal_results();
return new SearchResponseDto(movieCount, searchTvResponseDto.getTotalResults(),
searchTvResponseDto);
}
//영화를 page 별로 검색할 수 있습니다.
@Override
@Transactional
public SearchMovieResponseDto searchByMovieName(String name, int page) {
//movieSearchInfos 에 관련 내용을 담습니다
List<ProgramSearchInfo> movieSearchInfos = new ArrayList<>();
//open api를 통해 검색 결과를 받아옵니다.
OpenApiSearchTrendingDto movieSearchList = getSearchProgram("movie", name, page);
//저장하고 DTO를 설계합니다
movieSearchList.getResults().stream().forEach(movieProgramInfo -> {
Program program = saveProgramAndGetProgram(
movieProgramInfo,
ProgramType.Movie);
String firstGenreName = getProgramFirstGenre(movieProgramInfo.getGenre_ids());
movieSearchInfos.add(new ProgramSearchInfo(program.getId(), program.getTitle(),
movieProgramInfo.getRelease_date(), firstGenreName, program.getPosterPath(),
movieProgramInfo.getOverview()));
});
return new SearchMovieResponseDto(movieSearchInfos, movieSearchList.getPage(),
movieSearchList.getTotal_pages(), movieSearchList.getTotal_results());
}
@DistributeLock(key = "T(java.lang.String).valueOf(#searchTrendingOpenApiProgramInfo.getId()).concat('-').concat(#programType)")
public Program saveProgramAndGetProgram(
SearchTrendingOpenApiProgramInfo searchTrendingOpenApiProgramInfo,
ProgramType programType) {
Program program = programRepository.findByTmDbProgramIdAndType(
searchTrendingOpenApiProgramInfo.getId(), programType).orElseGet(() -> {
Program newProgram = apiProgramToProgram(searchTrendingOpenApiProgramInfo, programType);
programRepository.save(newProgram);
return newProgram;
});
return program;
}
이렇게 한 클래스내에서 말입니다.
이를 실행시켜보면 여전히 데이터가 중복 저장되는 것을 볼 수 있는데
그 이유는 Aop 의 내부 호출문제입니다.
간단히 말하면 searchByMovieName을 호출해서 AOP가 적용되길 바라는 saveProgramAndGetProgram을 호출할 때 Proxy를 통해 실행되는 AOP 가 실객체를 주입받아 더이상 proxy 가 아니기 때문에 AOP를 호출한 메서드가 실행되지 않고 AOP 가 적용되지 않은 그냥 변한것 하나 없는 saveProgramAndGetProgram 이 실행되기에 기존과 결과는 똑같습니다. 실제로 디버깅을 해도 AOP에는 접근하지 못합니다.
이를 해결하려면 ObjectProvider 를 사용하거나 saveProgramAndGetProgram을 다른 서비스 계층으로 전환시켜주면 됩니다.
참고:https://hoonsmemory.tistory.com/11
코드 수정
@Service
@RequiredArgsConstructor
public class ProgramSaveService {
private final ProgramRepository programRepository;
private final GenreRepository genreRepository;
@DistributeLock(key = "T(java.lang.String).valueOf(#searchTrendingOpenApiProgramInfo.getId()).concat('-').concat(#programType)")
public Program saveProgramAndGetProgramTest(
SearchTrendingOpenApiProgramInfo searchTrendingOpenApiProgramInfo,
ProgramType programType) {
Program program = programRepository.findByTmDbProgramIdAndType(
searchTrendingOpenApiProgramInfo.getId(), programType).orElseGet(() -> {
Program newProgram = apiProgramToProgram(searchTrendingOpenApiProgramInfo, programType);
programRepository.save(newProgram);
return newProgram;
});
return program;
}
//받아온 api 정보를 이용해 우리가 만든 Program 에 필요한 값을 넣어줍니다.
public Program apiProgramToProgram(
SearchTrendingOpenApiProgramInfo searchTrendingOpenApiProgramInfo,
ProgramType programType) {
// 공통 관련 빌드
Program.ProgramBuilder programBuilder = Program.builder()
.tmDbProgramId(searchTrendingOpenApiProgramInfo.getId())
.type(programType)
.posterPath(searchTrendingOpenApiProgramInfo.getPoster_path());
//영화일 경우
if (programType == ProgramType.Movie) {
programBuilder.title(searchTrendingOpenApiProgramInfo.getTitle());
String createdDate = searchTrendingOpenApiProgramInfo.getRelease_date();
programBuilder.createdYear(
createdDate.length() >= 4 ? createdDate.substring(0, 4) : null);
}
//tv 일 경우
else {
programBuilder.title(searchTrendingOpenApiProgramInfo.getName());
String createdDate = searchTrendingOpenApiProgramInfo.getFirst_air_date();
programBuilder.createdYear(
createdDate.length() >= 4 ? createdDate.substring(0, 4) : null);
}
Program program = programBuilder.build();
//연관관계 편의 메서드를 통한 장르 저장
searchTrendingOpenApiProgramInfo.getGenre_ids().forEach(gi -> {
Genre genre = genreRepository.findByTmDbGenreId(gi)
.orElseThrow(() -> new NotFoundException(ErrorCode.PROGRAM_GENRE_NOT_FOUND));
program.addGenre(genre);
});
return program;
}
}위와 같이 saveProgramAndGetProgramTest 부분과 그가 사용하는 메서드만 따로 추출해서 다른 클래스에 집어 넣습니다. 나머지는 전과 동일합니다.
결과 확인
select tm_db_program_id,type,count(*) as count
from program
group by tm_db_program_id,type
having count>1;위 쿼리를 통해 결과를 확인하면
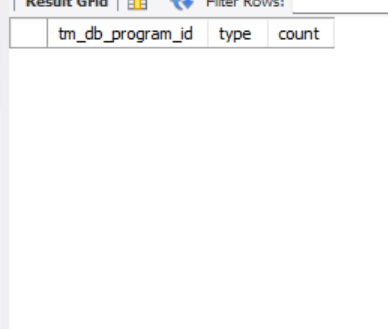
데이터가 중복 저장되는 문제는 사라졌습니다.
다른 방식을 선택한 이유
사실 저의 경우 위에서 했던 방식은 매우 비효율적이라고 생각합니다.
데이터가 저장되는 문제에 초점을 맞추었지만 사실 위 코드의 핵심은 데이터를 저장하는 것보다는 데이터를 그냥 반환하는 경우가 훨씬 많을 것입니다.
인기있는 프로그램들은 이미 한번 이상 검색되어서 select 쿼리만 나오기 때문에 더이상 lock을 사용할 이유가 없습니다 .
우연히 인기 없는 프로그램 같은 데이터를 동시에 두번 이상 검색할 경우(인기있는 프로그램은 이미 저장되어 있으니까) 만을 위해서 Lock을 사용하는 것은 부담스럽습니다.
단순히 인기있는 데이터를 검색하는 것도 쓰레드별로 Lock이 걸릴 테니까 말이죠!!
2.그냥 unique 제약 조건 사용하기
DB의 unique 제약 조건을 사용하기만 하면 기존에 데이터가 중복적으로 저장되는 현상은 더 이상 일어나지 않습니다.
각 program마다 고유한 
tm_db_program_id 와 type 이 존재하니 이를 묶어 unique 제약조건으로 걸어주면 됩니다.
ALTER TABLE `program`
ADD CONSTRAINT `unique_tm_db_program_id_type`
UNIQUE (`tm_db_program_id`, `type`);위와 같이 UNIQUE 제약 조건을 설정할 수 있으며,
ALTER TABLE `program` DROP INDEX `unique_tm_db_program_id_type`;을 통해서 기존 UNIQUE 제약 조건을 삭제할 수 있습니다.
코드 변경
private Program saveProgramAndGetProgram(
SearchTrendingOpenApiProgramInfo searchTrendingOpenApiProgramInfo,
ProgramType programType) {
Program program;
try {
program = programRepository.findByTmDbProgramIdAndType(
searchTrendingOpenApiProgramInfo.getId(), programType).orElseGet(() -> {
Program newProgram = apiProgramToProgram(searchTrendingOpenApiProgramInfo,
programType);
programRepository.save(newProgram);
return newProgram;
});
} catch (DataIntegrityViolationException e) {
throw new InternalServerErrorException(ErrorCode.DATA_SAVING_ERROR);
}
return program;
}위와 같이 try catch 로 서버 내부에 문제가 있으니 다시 시도해 달라고 예외 처리를 적용했습니다.
이전에 말했던 대로 데이터가 동시에 저장되는 경우는 매우 흔한 일이기에 이렇게 해도 별 문제 없다고 생각했습니다.
참고하면 좋은 velog
참고할만한 내용 -Stream forEach
위에서 stream.forEach() 가 매우 의심스러웠기 때문에 이 부분에 대한 정보를 모아보았습니다.
Stream.forEach()
https://docs.oracle.com/javase/8/docs/api/java/util/stream/package-summary.html#StreamOps ==>스프링 공식 문서
Side-effects 항목을 참고하였을 때 forEach 내부에 로직이 있으면 동시성 보장이 어려워 진다고 함.
https://ssdragon.tistory.com/143 ==>side Effect 에 관한 고찰
https://www.baeldung.com/java-collection-stream-foreach
==>collection stream 과 그냥 forEach 차이점
위는 데이터가 중복적으로 저장되는 직접적인 원인이 아니였지만
side - effect 로 동시성 보장이 어려워질 수 있다는 것을 참고할 수 있었다.
