5월 31일자 머신러닝 수업 내용을 정리하여 올린 글입니다.
1절. 머신러닝 개요
1.1. 데이터 분석에서 가장 중요한 것은?
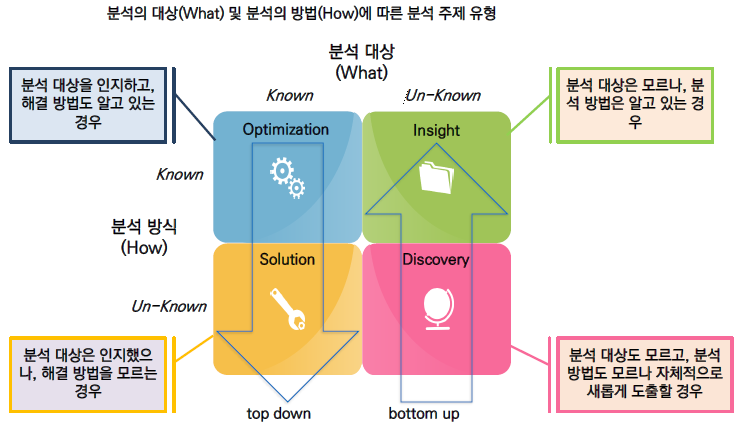
1.2. 데이터 분석을 잘 하려면?
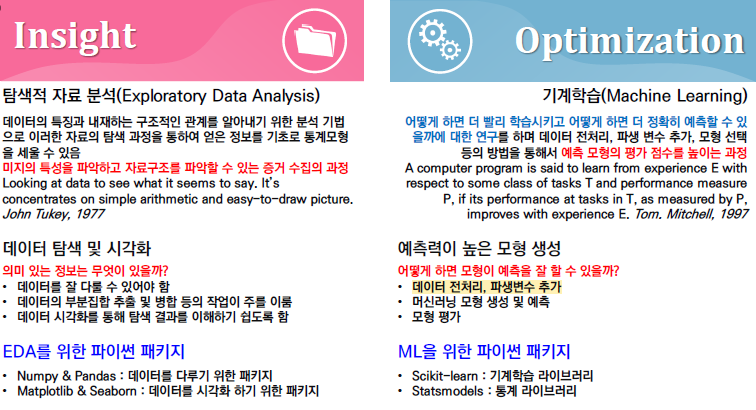
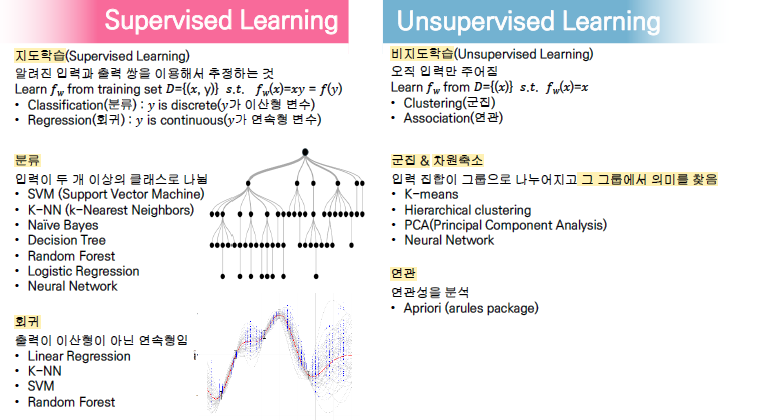
1.4. 지도학습과 비지도 학습
1.5. 데이터 분석 단계에서 머신러닝
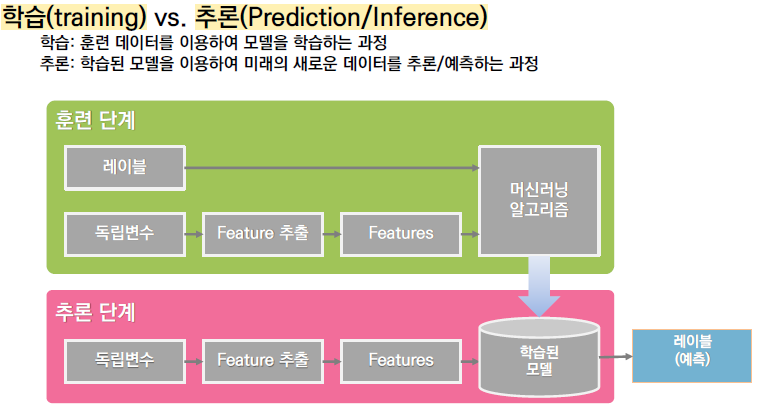
1.6. Scikit-learn 패키지
예측분석을 위한 간단하고 효율적인 도구
상업적으로 사용 가능한 오픈소스 BSD 라이센스이므로 모든 사람이 사용할 수 있음
NumPy(넘파이), SciPy(사이파이) 및 matplotlib(맷플롯립) 기반
2절. 데이터 탐색
2.1. 변수와 통계량
1) 변수의 종류
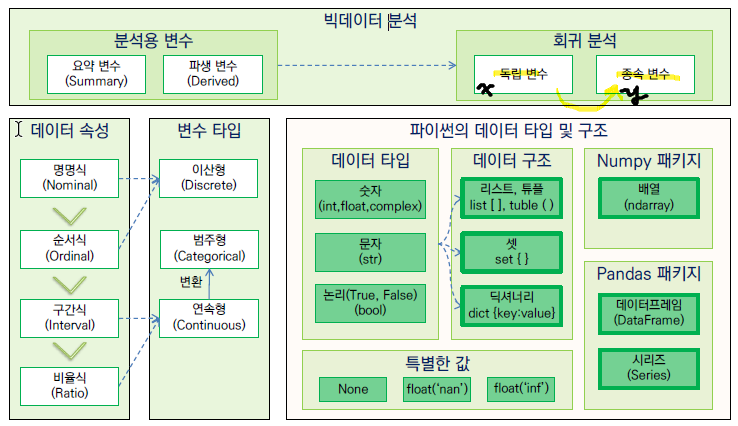
2) 기초통계량
기초통계, missingno() 등을 이용해 결측치 등을 파악한다.
scatter plot() 는 이변량이라 x,y가 필요하다. → 두 변수간의 관계성을 파악하는 것이 목적
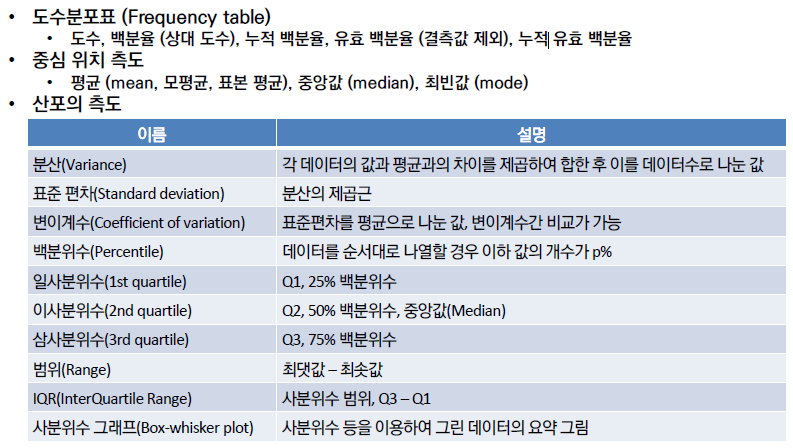
3) 왜도와 첨도
왜도 : 표본 데이터의 대칭성 측정, 음수. 왼 꼬리, 0. 대칭, 양수. 오른 꼬리
첨도 : 음수. 낮은 봉우리, 0. 정규분포와 같은 봉우리 높이, 양수. 높은 봉우리

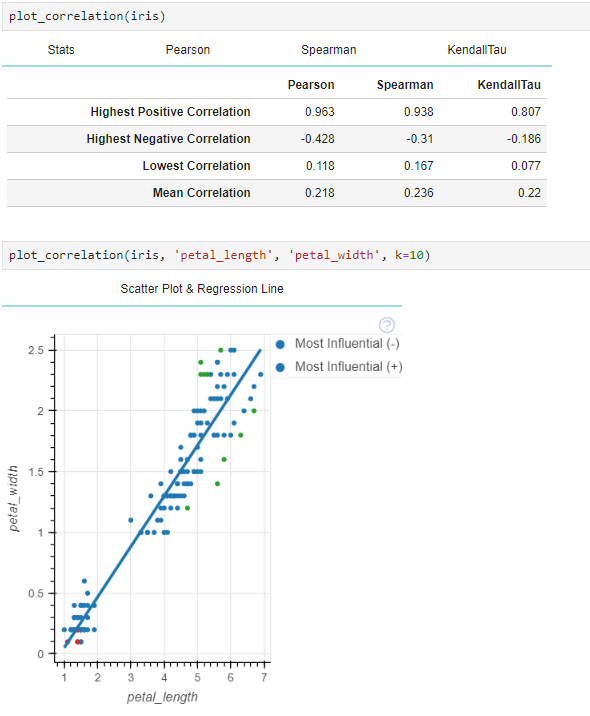
4) 공분산과 상관계수
공분산 (Covariance) : 양수. 양의 상관관계, 음수, 음의 상관관계(두 변수 간 관계의 강도)
- 두 개의 확률변수의 분포가 결합된 결합확률분포의 분산
- 방향성은 나타내지만, 결합 정도에 대한 정보로서는 유용하지 않음
- 공분산이 0보다 크면 두 변수는 같은 방향으로 움직이고, 0보다 작으면 다른 방향으로 움직임
- 공분산이 0이면 두 변수간에는 아무런 선형관계가 없으며 두 변수는 서로 독립적인 관계에 있음
- 두 변수가 독립적이면 공분산은 0이 되지만, 공분산이 0이라고 해서 항상 독립적이라고 할 수 없음
상관계수(Correlation coefficient) : -1 ~ 1, 공분산을 단위와 상관없는 형태로 가공한 값
- 두 개의 확률변수 사이의 선형적 관계 정도를 나타내는 척도
- 방향성과 선형적 결합 정도에 대한 정보를 모두 포함하고 있음
- 공분산은 원래의 단위의 곱이 되기 때문에 경우에 따라서 이를 표준화할 필요가 있음
- 공분산을 표준화한 결과가 상관계수
- 두 변수의 공분산을 각 변수의 표준편차로 모두 나누어 구할 수 있음
- -1과 1사이 값을 가짐
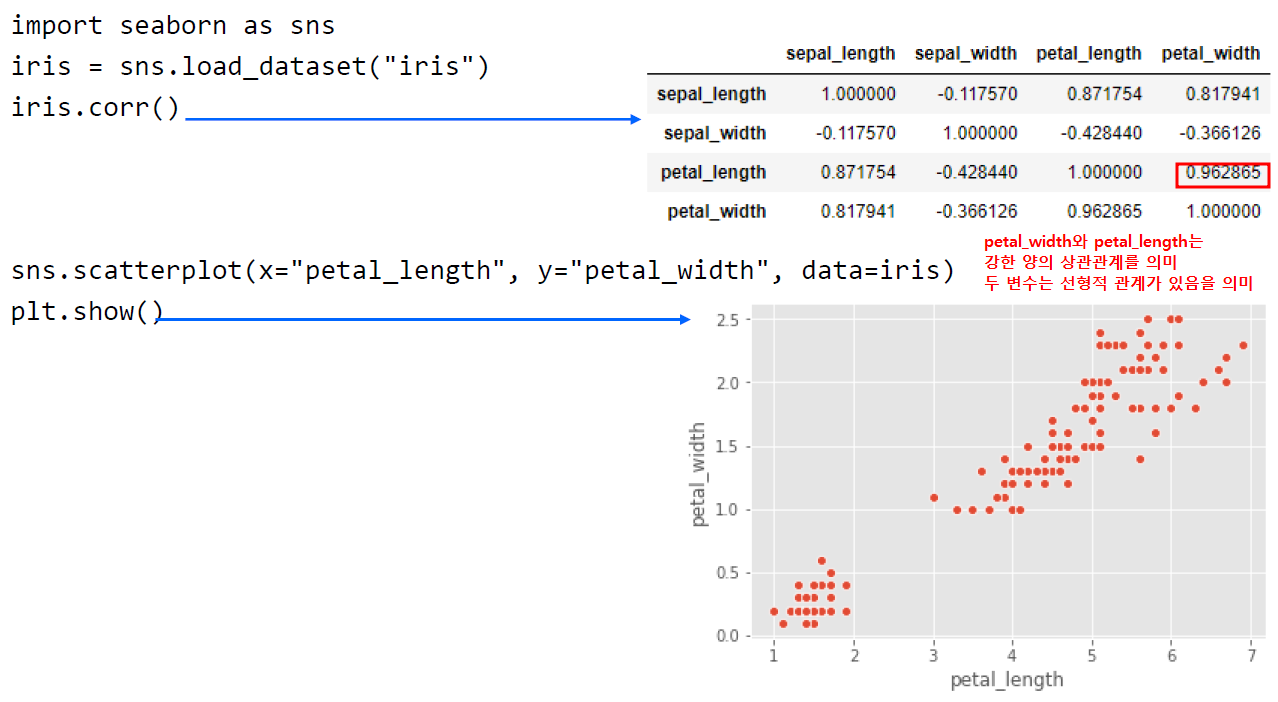
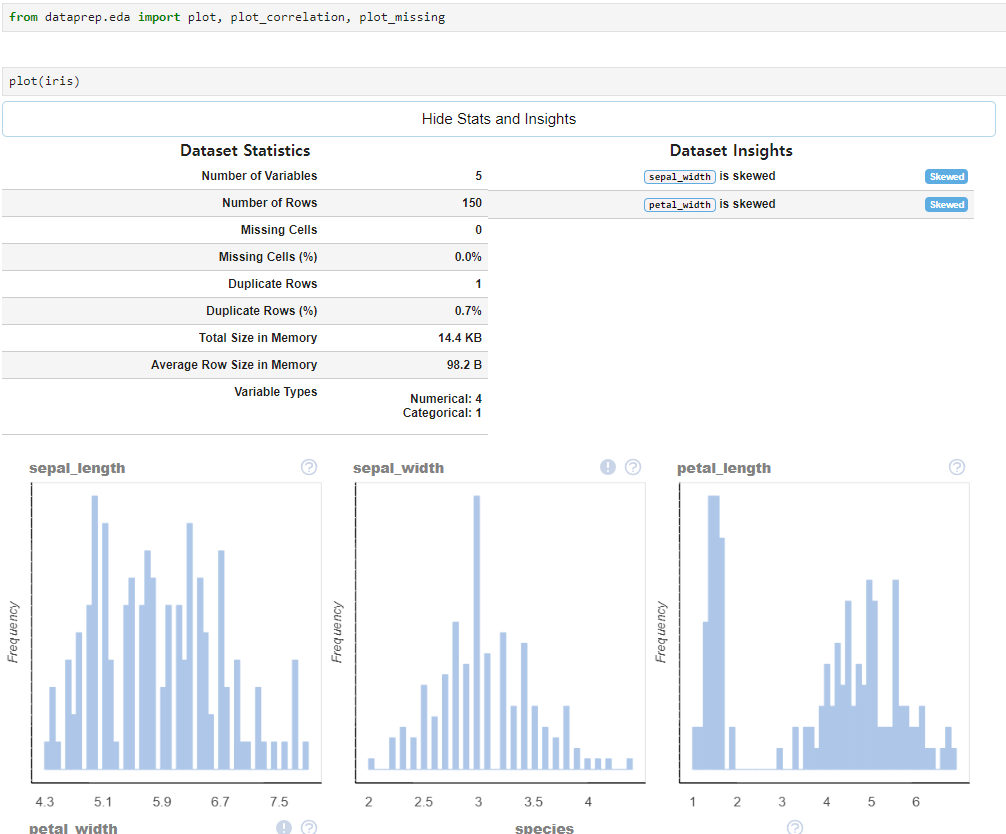
2.2. 데이터 EDA 가속화
# anaconda pormpt 에서 실행
# https://anaconda.org/conda-forge/dataprep
conda install conda-forge::dataprep비주얼스튜디오 c++ 이 설치되어있지 않다면 에러가 발생할 수도 있다.
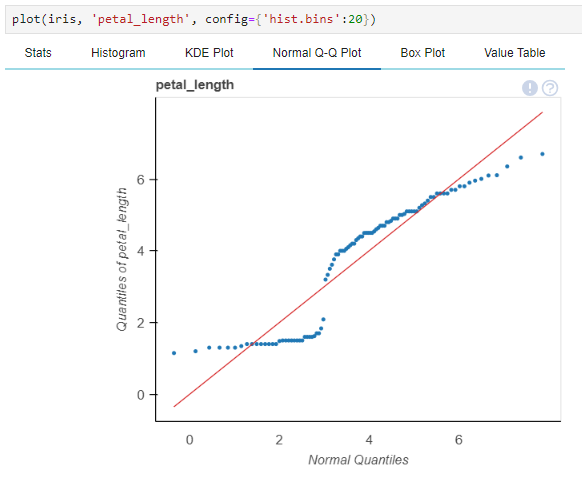
QQ 플롯(Quantile-Quantile Plot)의 Quantile은 분위수라는 의미로, 데이터를 오름차순(or 내림차순) 정렬한 뒤, 전체 데이터를 특정 개수로 나눌 때 기준이 되는 수이다.
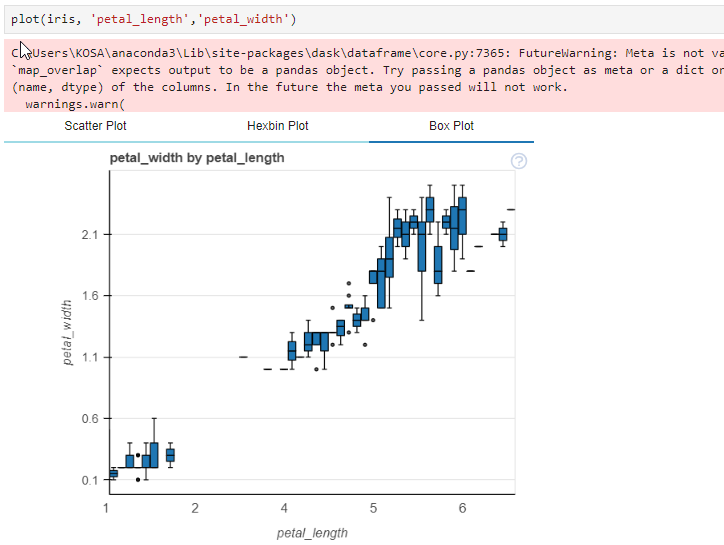
3절. 데이터 전처리
3.1. 표준화
데이터를 정해진 구간 사이의 값으로 표준화(Standardzation)한다.
1) 표준화 함수들
데이터를 정해진 구간 사이의 값으로 표준화(Standardization)
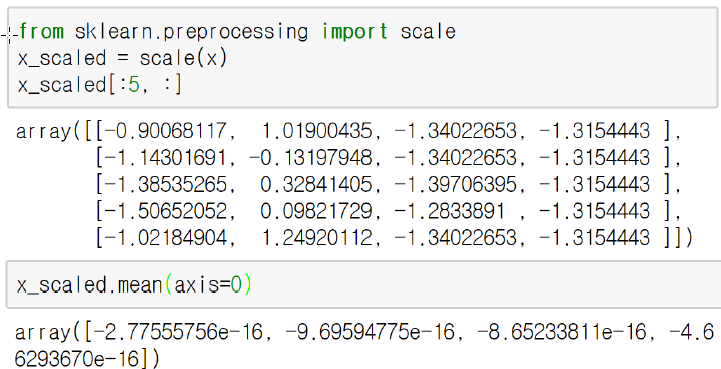
2) scale()
표준 정규분포를 사용해 표준화, 평균이 0, 표준편차가 1이 되도록 표준화해준다.
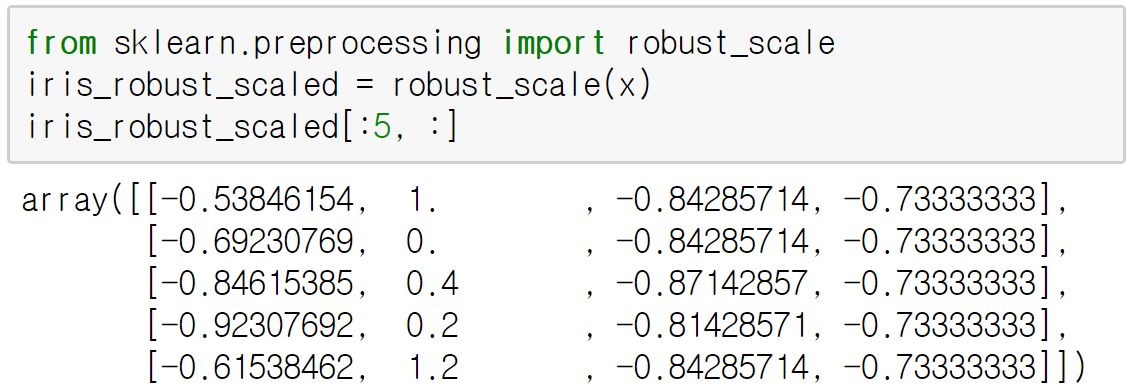
3) robust_scale()
중위수와 사분위범위(interquartile range)를 사용하여 표준화
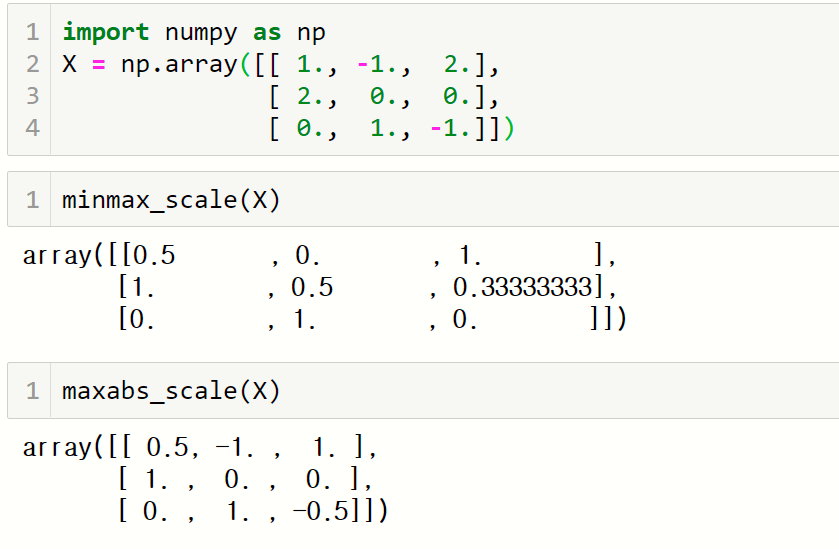
4) minmax_scale()
최솟값을 0, 최댓값을 1에 매핑시켜 표준화

5) maxabs_scale()
절댓값이 가장 큰 값을 1로 정하면서 0부터 1사이의 값에 매핑

음수는 부호를 그대로 유지하는 것이 minmax_scale() 함수와 다른 점임
6) 표준화 클래스
StandardScaler, MinMaxScaler, MaxAbsScaler 클래스를 이용해서 표준화
표준화 방법은 scale(), minmax_scale(), maxabs_scale() 함수와 같음
이들 클래스를 이용하면 표준화 후 표준화한 값을 원래의 값 범위로 되돌릴 수 있음
7) StandardScaler
StandardScaler 객체를 이용해 표준화
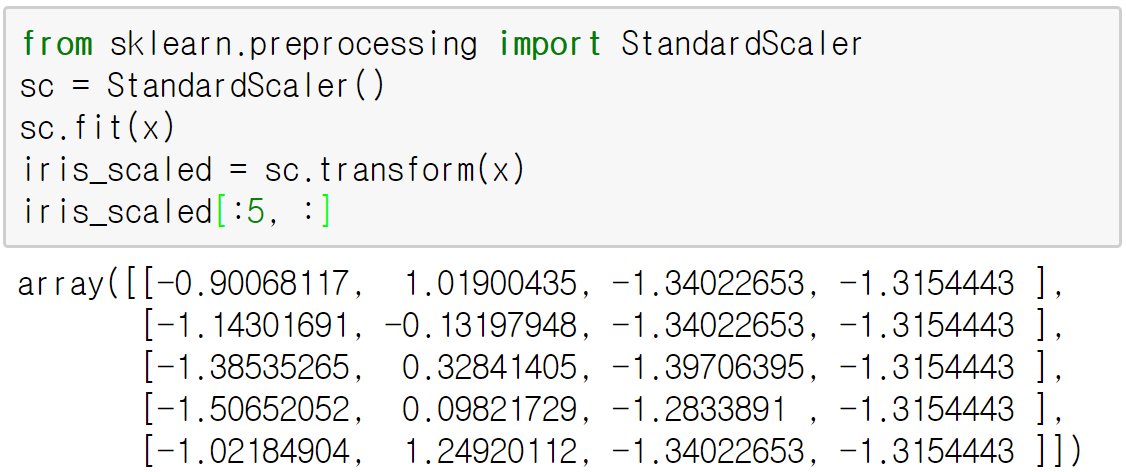
StandardScaler 객체를 이용해 스캐일백
3.2. 인코딩(Encoding)
기계학습에 사용할 데이터가 범주형 데이터(텍스트 데이터 포함)일 경우 인코딩을 통해 숫자로 변환해주어야 한다.
1) 레이블 인코딩
레이블 인코딩(Label Encoding)은 실제 값에 상관없이 0~K-1까지의 정수로 변환하는 것
지역 또는 성별 등 문자로 되어있는 데이터를 숫자로 변환해야 함
레이블 인코딩은 preprocessing 모듈의 LabelEncoder 클래스를 이용

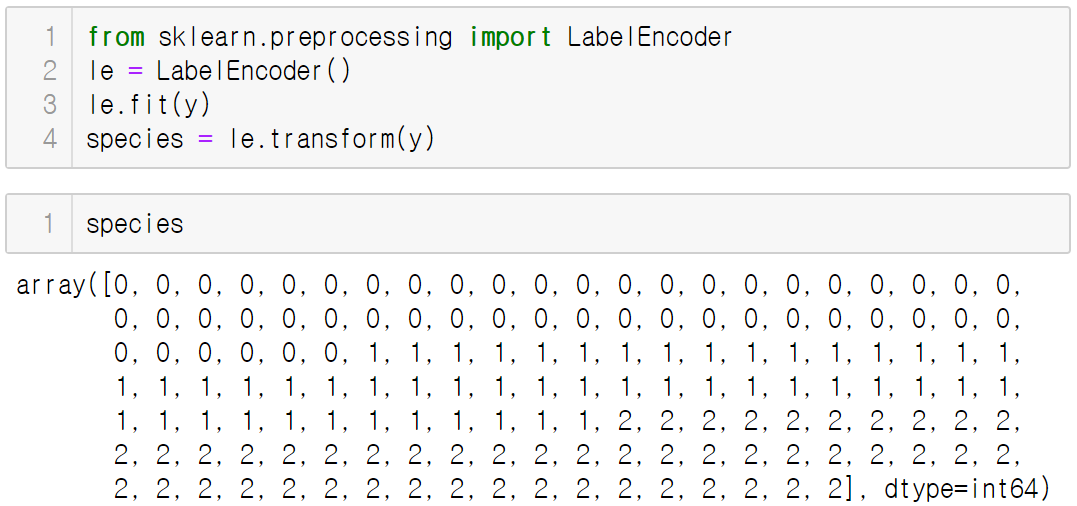
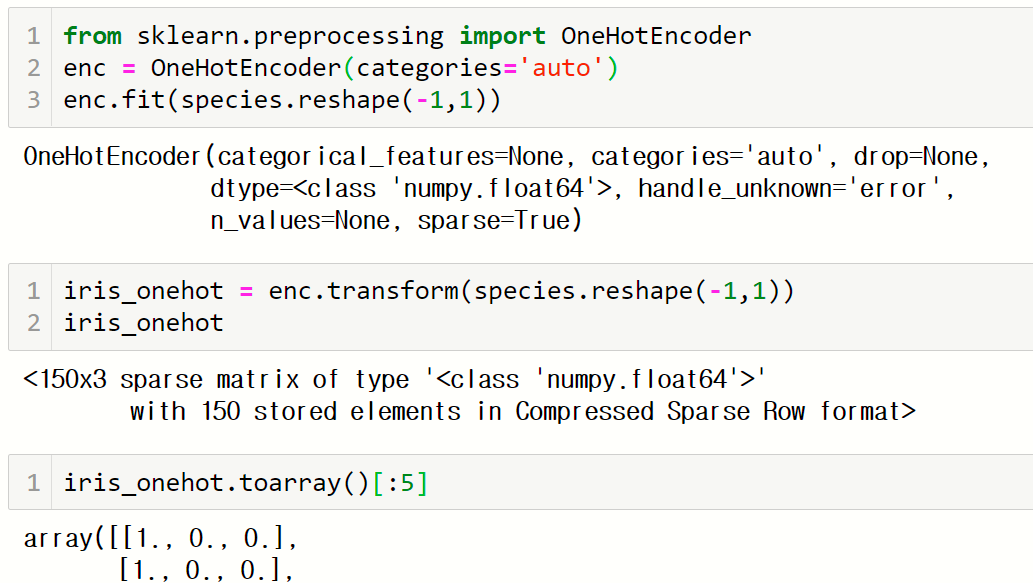
2) 원-핫 인코딩
원-핫(one-hot) 인코딩은 클래스의 수만큼 0 또는 1을 갖는 열을 이용해서 데이터를 표현
성별(sex)을 저장하는 변수가 male, female을 가진다면 sex_male, sex_female이라는
두 개의 변수가 만들어지고 male일 경우 두 변수가 각각 1, 0값을 가지며, female일 경우
두 변수가 각각 0, 1값을 가짐
원-핫 인코딩은 preprocessing 모듈의 OneHotEncoder 클래스를 이용
3) 평균값 인코딩(Mean Encoding)
레이블에 따른 예측값의 평균은 레이블 값에 따라 달라질 수 있음
평균값 인코딩은 레이블 값을 수치적으로도 표현하면서도 서로 구분할 수 있음
이렇게 인코딩한 값은 예측값과 수치적인 면에서 연관이 있다.

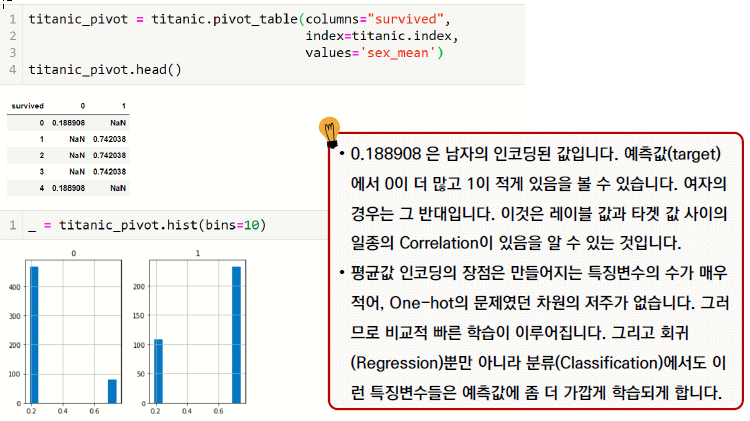
평균값 인코딩의 단점은 구현과 검증이 조금 까다롭고 과적합(Overfitting)의 문제가 있다는 것이다.
그래서 평균값 인코딩에서는 특히 데이터 누수와 과적합을 최소화하려는 다양한 기법들이 존재한다.
그 대표적인 기법에는 Smoothing, CV Loop, Expanding mean이 있다.
3.3. 평균값 인코딩의 과적합 해결
1) Smoothing
학습 데이터셋과 평가 데이터셋의 레이블 분포가 다를경우 치우친 평균을 전체 평균에 가깝도록 만듬
def smoothing(n_rows, target_mean):
return (target_mean*n_rows + global_mean*alpha)/ (n_rows+alpha)
titanic['sex_mean_smoothing']=titanic.apply(
lambda x:smoothing(x['sex_n_rows'], x['sex_mean']), axis=1)
titanic[['sex_mean','sex_mean_smoothing']].head()2) CV Loop
CV Loop은 학습 데이터셋 내에서 교차검증을 통한 평균값 인코딩을 통해 데이터 누수를 줄이고 이전보다 레이블 값에 따른 인코딩 값을 다양하게 만드는 시도를 한다.
from sklearn.model_selection import train_test_split
import numpy as np
pd.options.mode.copy_on_write=True
train, test=train_test_split(titanic, test_size=0.2,random_state=42, shuffle=True)
# train -> train_new 로 될 예정. 미리 데이터프레임 만들어주기
train_new=train.copy()
train_new[:]=np.nan
train_new['sex_mean']=np.nan
from sklearn.model_selection import StratifiedKFold
# Kfold 만들어주기
train_X=train.drop('survived', axis=1)
train_y=train['survived']
skf=StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# 각 Fold iteration
for tr_idx, val_idx in skf.split(train_X, train_y):
train_X, X_val=train.iloc[tr_idx], train.iloc[val_idx]
#train set에서 구한 mean encoded값을 validation set에 매핑해줌
means = X_val['sex'].map(train_X.groupby('sex')['survived'].mean())
X_val['sex_mean']=means
train_new.iloc[val_idx]=X_val
# 폴드에 속하지 못한 데이터들은 글로벌 평균으로 채워주기
global_mean=train['survived'].mean()
train_new['sex']=train_new['sex'].fillna(global_mean)
train_new[['sex', 'sex_mean']].head()3) Expanding Mean
누적합과 누적계수를 이용하여 인코딩된 값의 특성은 지니면서, 값을 좀 더 잘게 나누는 기술
3.4. 결측값 처리
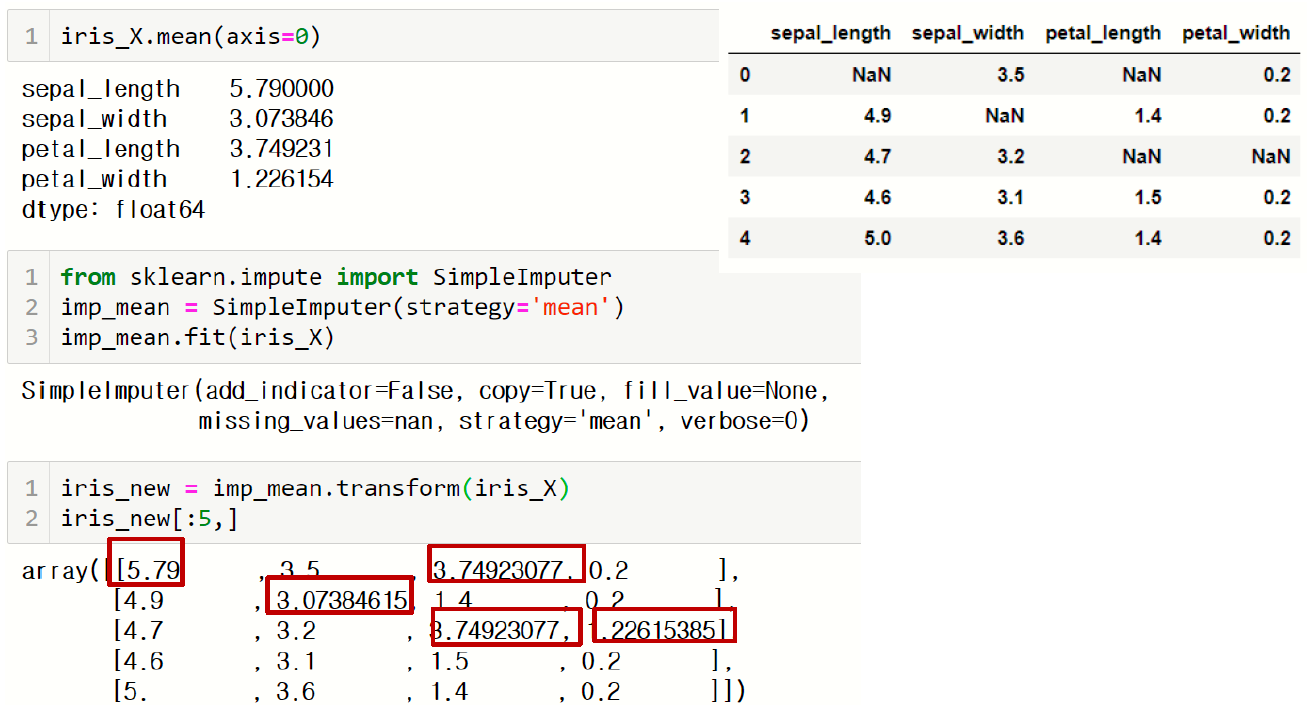
데이터에 누락된 정보(결측값, Missing Value)가 있을 경우 이 값을 다른 값으로 채워야 함
impute 모듈의 SimpleImputer 클래스를 이용하면 데이터의 평균, 중앙값, 최빈값 또는
상수값 중 하나로 결측값을 채울 수 있음
1) 평균으로 채우기
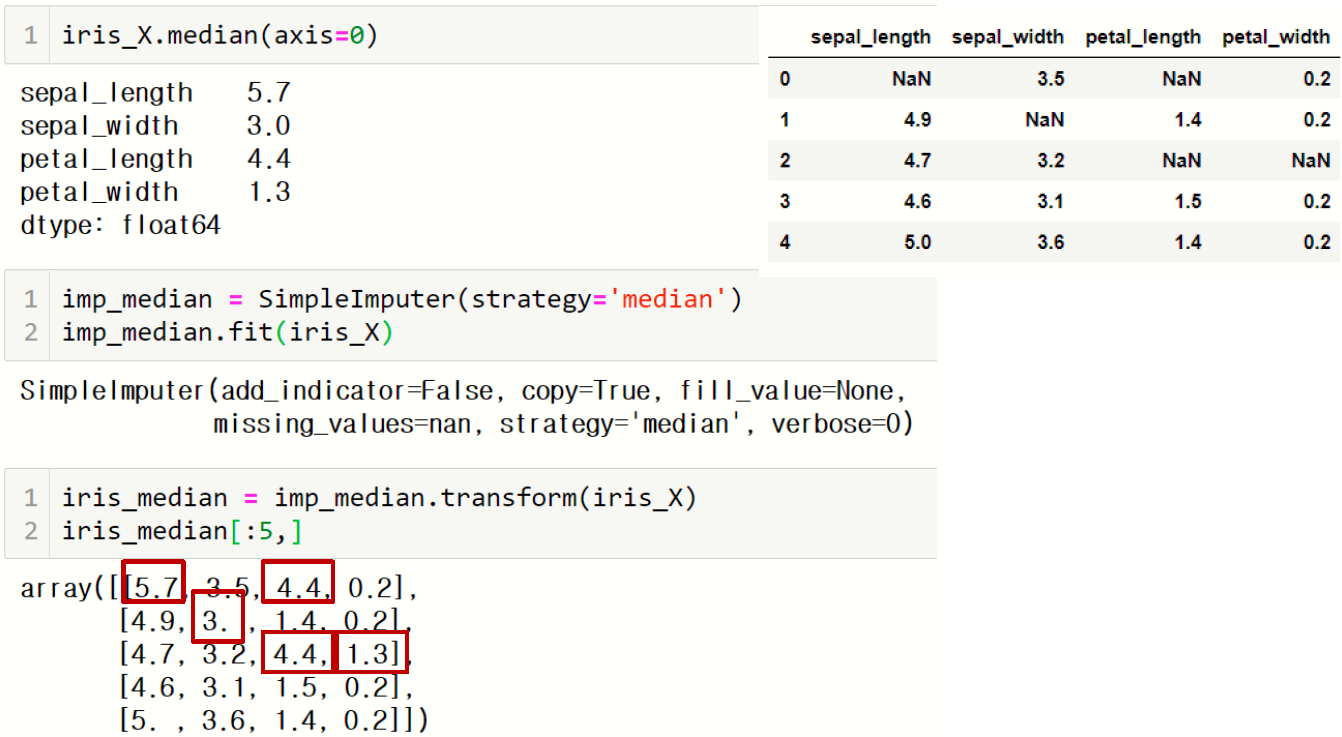
2) 중앙값으로 채우기
3) 최빈값으로 채우기
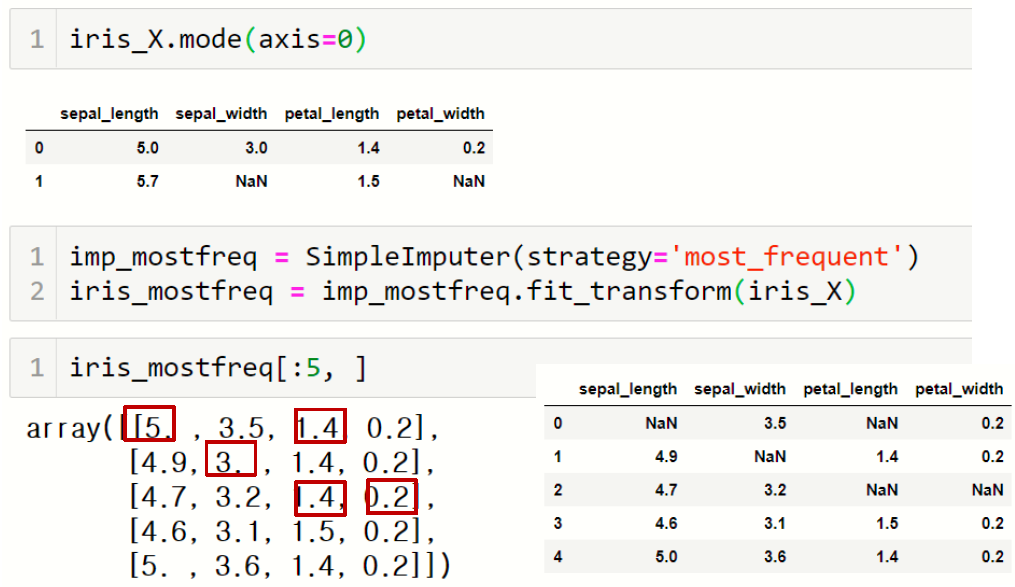
3.5. 판다스를 이용한 결측치 처리
판다스의 데이터프레임을 다루는데 익숙하다면 fillna(), apply() 등의 함수를 이용해서 결측치 처리하는 것이 더 편할 수 있다.
앞에서 난수를 이용해서 결측값을 포함시켰던 데이터셋을 결측치 처리해 보자.
각 종별 평균값을 이용해 처리
import pandas as pd
iris_n=pd.concat([iris_x, iris_y], axis=1)다음코드는 종별로 열 평균을 계산
