논문 요약
초록
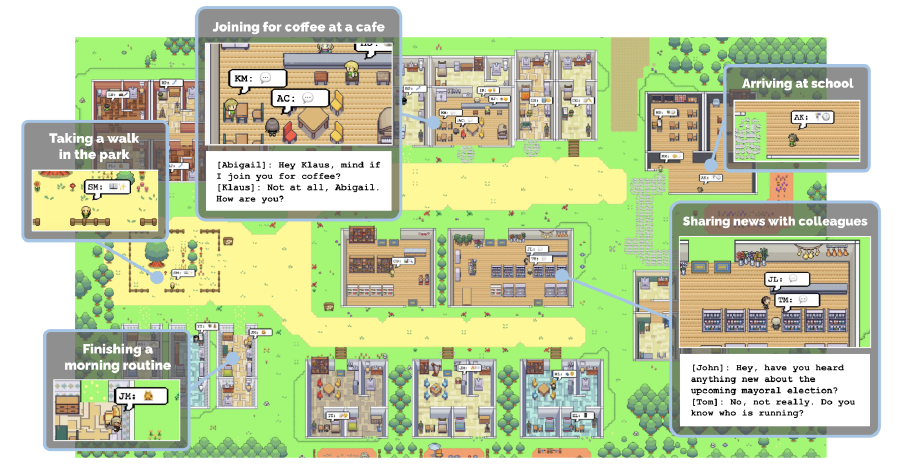
논문에 사용된 figure 1 그림이다. 해당 연구가 어떤 환경 위에서 동작하는지 한눈에 알 수 있다. 마치 게임 SIMS(개더타운 같기도 하고)를 연상시키는 위 환경이 주어지며, 25명의 agent가 존재한다고 한다. 사용자는 위 세상에 개입하거나 관찰할 수 있다고 한다.
각 agent들은 실제 사람들처럼 주어진 환경 내에서 말을 하거나 요리를 하거나 자신의 직업에 따른 일을 할 수 있다고 한다. LLM에 각 agent별로 자신의 경험을 자연어로 저장/기록이 가능한 기능을 붙여 그 경험들을 토대로 고도화된 학습이 가능하며 동적으로 자신의 미래 할 일을 계획하는 일을 할 수 있다(Auto-GPT?). 상당히 흥미로운 부분이다. 이런 형식의 기능은 앞으로 multi-agent 연구에서 상당히 많이 활용될 것 같고, 이 저장 장치를 여러 agent들이 함께 공유하는 식으로 구현해도 재밌는 결과가 많이 나올 것 같다(프로토스?).
어떤 이벤트(발렌타인 데이)를 연다고 하면, 점점 초대장이 전달되고 모여서 파티를 하는 모습을 확인할 수 있다고 한다. 이렇게 관찰->계획->반영 이러한 3가지 단계를 통해 목적을 스스로 찾고 그것을 이루어 가면서 주변 환경에 능동적으로 영향을 끼치는 사람의 행동과 비슷한 세계를 구현한 것으로 보인다.
서론
지난 수십년간 동안 다양한 분야에서 컴퓨터사이언스 학자들은 실제 세계를 반영하는 가상 사회를 만들기 위해 노력해 왔다. 실제 사회현상을 반영하기도 해보고, 사회과학 이론을 테스트도 해보았으며 이런 노력들이 오픈월드의 복잡한 인간 관계를 구축하는 길로 이끌었다.
하지만 사람 행동의 범위는 정말 다양하고 복잡하다. LLM으로 인한 엄청난 진전으로 인해 단일한 시점에 대한 인간의 행동을 시뮬레이션하는 것은 가능할지 몰라도, multi-agent를 기반으로 한 지속적이고 장기적인 실제 세계 형성은 아직 미흡하다. 긴 시간을 아우르는 범위 내에서 상호작용과 이벤트 사이의 인과관계를 되찾고 이 일들을 기억한 뒤 반영하여 고도의 추론을 해내고 계획과 행동을 에이전트가 해낼 수 있는 시뮬레이션의 구현이 필요하다.
저장하고, 합성하고, 적용하는 기억 체계를 LLM을 이용해 만들었으며, 이 논문에서 제시하고 있다.
그 체계의 구조는 3개의 요소로 이루어지는데, 첫 번째는 memory stream: 긴 기간 동안의 경험의 종합적인 리스트를 자연어 형태로 저장하며 이 기억을 꺼내는 검색 모델은 연관성, 새로움, 중요성 이 3가지가 종합되어 구성된다. 두 번째는 reflection: 고도화된 추론을 위해 그간의 기억을 합성하는 것이며 에이전트가 스스로 결론을 내리고 그의 행동으로 다른 이들에게 좋은 가이드가 될 수 있도록 한다. 세 번째는 planning: 환경과 자신의 결론을 해석하여 그 환경에 맞는 디테일한 행동을 계획할 수 있다. 이러한 것들은 다시 memory stream에 들어가서 결론을 reflection하고 다음 행동을 planning하게 된다.
에이전트들의 행동과 상호 작용
에이전트들의 아바타와 에이전트간 의사 소통
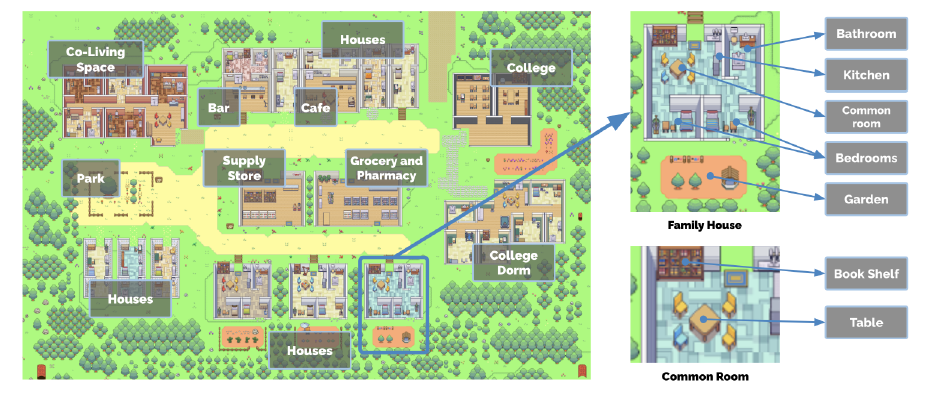
SIMS에서 착안한 가상 세계와 에이전트들에 대한 환경. 에이전트는 그들이 목격한 object들을 기억한다.
25명의 에이전트가 Smallville에 산다. 한 에이전트는 자연어 형태의 글로 그의 정보가 묘사된다. 에이전트는 환경에 존재하는 정보들과 그 자신의 상호작용을 표현할 수 있는 언어로 자신의 행위를 출력한다. 예를 들어, ‘OOO이 그의 저널을 쓰고 있다.’와 같은 방식으로 말이다. SIMS에서는 실제로 캐릭터가 행위하는 것을 캐릭터가 움직이는 방식으로 직접 볼 수 있다면, 이 연구에서는 자연어로 그것을 대체하는 것으로 보인다. 그리고 이것을 Smallville의 환경에서 이모티콘으로 요약하여 표시한다. 조금 더 직관적으로 관찰할 수 있는 방법으로 보인다. 여기서 클릭하면 자세한 설명을 자연어로 들을 수 있다고 한다. 실제 SIMS 게임 UI처럼 구현되어 있다고 생각하면 이해가 쉽다.
각 에이전트들은 자연어를 통해 의사소통할 수 있다. 또한 자신의 생각 (논문에서는 inner voice라고 표현했다) 또한 자연어 표현을 통해 알 수 있다.
에이전트와 환경의 상호 작용
위에도 언급했듯 에이전트들은 환경과 상호작용할 수 있다. 논문을 읽어보면 환경에 대한 정보(위치, 오브젝트, 오브젝트의 상태) 등등의 자유도를 정해 두고, 그 자유도 내에서 에이전트가 그 환경과 상호작용하는 시스템으로 보인다.
만약 어떤 object의 상태에 문제가 생긴다면, 에이전트는 그것을 수리 혹은 해결하러 온다. 예를 들어, 수도관에 물이 새고 있다면 수도관을 수리하러 온다는 의미다.
예시
이 논문에서는 이 모델에서 행해진 에이전트들의 일상 중 하나를 제시한다.

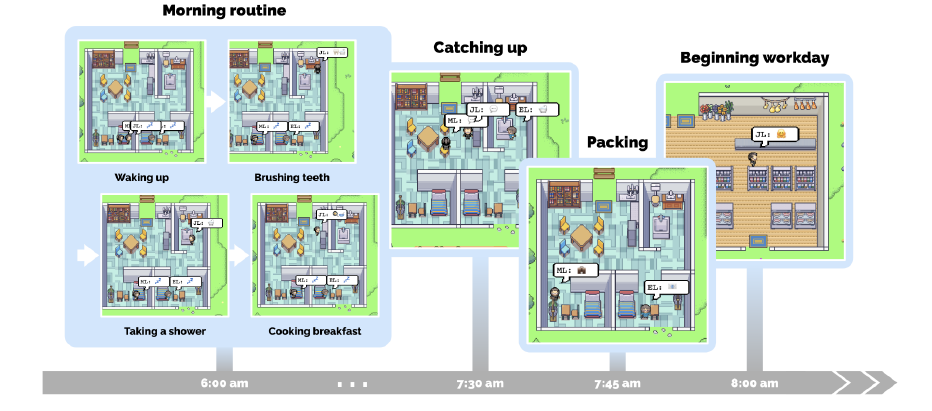
새로운 사회적 행동
상호작용하면서, 미리 정해져 있던 사회적 행동 (대화, 직업적 일) 그 이상의 새로운 사회 행동들이 발견된다고 한다.
1. information diffusion: 정보의 확산
에이전트들이 서로 대화하며 정보를 공유하면서, 정보들이 에이전트 사이에서 퍼져 나간다고 한다.
발렌타인데이 행사를 열도록 설정된 에이전트가 있었다. 이 에이전트가 실패할 여러 가지 경우의 수들이 있었음에도 불구하고, 몇 명의 에이전트들을 모아 실제로 발렌타인데이 행사가 이루어졌다고 한다. 이때 분명 발렌타인데이 행사에 대한 정보의 확산이 있었을 것이다.
2. 관계에 대한 기억
실제로 사람의 사회에서 그러하듯, 한 말을 기억하고 나중의 대화에서 써먹었다. 사진 프로젝트에 대해 A가 언급하자 B는 이것을 기억하고는, 나중의 대화에서 B가 “프로젝트 잘돼 가요?”라고 말했다고 한다.
3. 협동/협조
에이전트들은 서로 협동했다. 발렌타인데이 행사를 계획하는 과정에서, 그들은 각자의 역할에 대해 협동을 제안하고 실제로 그것을 받아들이며 함께 발렌타인데이 행사에 참여했다.
생성 에이전트의 구조
생성 에이전트는 오픈 월드에서의 행동에 대한 프레임워크를 제공하는 것을 목표로 한다. 이 연구는 Generative NLP AI를 활용해서 만들어지지만, GPT-4와 같은 가장 최신 모델들도 앞서 기술되었듯이, 사람의 것을 최대한 모방하듯 기억을 통해 자신의 행동과 얻은 정보들을 보존하고, 그것을 다시 다음 행동에 반영하는 것은 힘들다. 그래서 이 기억을 저장하고, 기억들을 합성하여 새로운 결론을 도출해 내는, 인간에 있어서는 전두엽과 같은 기능을 하는 모델이 필요했음을 알 수 있다.
memory stream(기억 흐름)이라는 것이 이 구조의 중심에 있다. 이 메모리 스트림으로부터 기억을 검색하고, 그 검색된 기억이 당시에 주어진 환경에 따라 어떤 행동을 할지 결정하는 데 영향을 미친다.
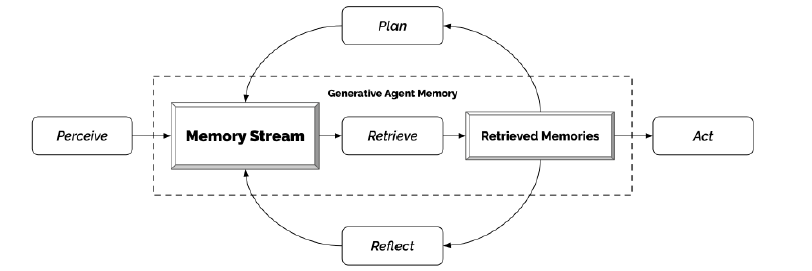
기억과 검색
문제: 단순히 모아진 기억을 구축하는 것이 아니라, 특정 환경이나 특정 질문에 대하여 검색 후 검색된 데이터에 대해서만 아웃풋을 낼 수 있는 모델이 필요했다.
접근: 메모리 스트림의 기본적인 요소는 관찰이다. 이것은 에이전트가 환경을 인식하는 과정에서 바로 얻어진다. 공통적인 관찰로 인한 기억은 에이전트 자신에게 주어진 환경을 인식하는 것에서 얻어지거나, 다른 에이전트와의 정보 공유 및 관찰을 통해 얻어진다. 논문에서 만들어낸 구조 중 검색 함수는 메모리 스트림 중에서 일부를 취하는 함수다. 이 논문에서는 그것을 추출하기 위해서 3개의 요소를 정의하였다.
- Recency: 가장 최근의 정보에 대해 높은 점수를 부과한다. exponential decay function을 설정하였고 그 계수를 0.99로 하였으니, e^(-0.99t) 꼴로 기억의 중요도가 감소할 것이다(시간은 리얼타임일까?).
- Importance: 평범한 기억과 핵심 기억을 비교하여 중요한 기억에 더 높은 점수를 부여한다. 평범한 기억: 양치, 잠자기, 핵심 기억: 대학 입학, 창업 시작 이러한 방식으로 어떤 개인에게 특별하고 개인별로 다를 수 있는 기억들을 핵심 기억이라 분류했다. Scoring 또한 이러한 Scoring 룰에 대한 정보를 주고 ChatGPT에게 분류하라고 시켰다고 한다.
- Relevance: 현재 상황과 가장 연관 있는 기억에 대해 점수를 부여한다. LM을 사용하여 기억의 설명에 대한 임베딩 벡터를 만들고 코사인유사도를 구했다고 한다.
이렇게 요소들에 대한 값이 나오면 값들을 0과 1 사이의 값으로 minmax 처리한 뒤 더하여 가장 점수가 높은 것을 선택했다고 한다.
반영
문제: 기억을 조합하여 새로운 결론을 만들어내는 것, 논문의 예시를 참고하자면 한 에이전트에게 ‘시간을 써야 하는데 누구와 시간을 쓸래?’에 대해 질문하는 것을 의미한다. 관찰 메모리에만 의하면 에이전트는 가장 물리적으로(공간적으로) 가까이 있는 자신의 기숙사 이웃를 구했겠지만, 실제로 그들은 지나가면서 인사하는 거 이외에는 큰 교류가 없었으므로 사회적으로 이웃을 택한다는 건 말이 안 된다. 그러나 아래의 접근법을 통해, 같은 연구 관심사가 있는 친구를 선택하도록 모델을 만들었다고 한다.
접근: reflection이라고 불리는 새로운 타입의 기억을 정의한다. 관찰을 통해 수집된 데이터는 observation이다. 이 reflection 기억은 고도화된 기억이며, 에이전트가 추상적 추론을 통해 스스로 만들어낸 것이다. 이 기억을 만들기 위해서는 어떤 기억을 기반으로 추론을 할 것인지 결정해야 한다. 100개의 최근 기억을 추출하고, ChatGPT에게 “Given only the information above, what are 3 most salient high-level questions we can answer about the subjects in the statements?” 라고 묻는다. 이렇게 하면 여기서 질문들이 추출되고, 각 질문에 대해 reflection 기억을 포함한 연관 있는 기억들(추출하는 방법은 검색-relevance에 나온 방법론과 같을 것으로 추측함)을 모은다. 그렇게 하고 나서 그 기억들에 대한 인사이트를 뽑아내도록 LLM에게 묻는다. 이러고 나서의 결과를 메모리 스트림에 저장하고, 이 기억들을 reflection 기억이라 정의한다.
계획과 반응
문제: LLM이 행동을 말로써 정의하면 에이전트는 이것을 상황 정보에 따라 작은 행동들로 쪼개어 자신이 주어진 환경에 맞추어 세부적인 행동들의 연속으로 계획할 수 있어야 한다.
접근: ‘계획’이라는 것은 시간에 따라 에이전트가 그 행동을 꾸준히 행하도록 돕고 연속적인 행위에 대한 정보가 표현되어 있어야 한다. ‘계획’은 장소, 행위의 시작 시간, 행위 기간에 대한 정보를 포함한다. 이 계획을 좀 더 각 에이전트들에게 make sense하게 작성하기 위해서, top-down 방식으로, 그리고 재귀적 구현을 통해 점점 디테일을 갖춰 나가게 한다. 첫 번째 단계는 대강 하루의 의제를 잡는 것이다.
"에이전트의 이름+타고난 특성 요약 설명 자료+어제의 일들의 요약 자료" 를 LLM에게 주면, 오늘 할 일에 대한 대강의 스케치를 5~8개의 행위 단위로 LLM이 도출해 준다. 이 정보를 메모리 스트림에 저장하고 재귀적으로 좀 더 자세한 정보를 도출하도록 5개~8개의 행위 단위를 분해한다. 이때 5분~15분 단위의 일로 분해하게 된다. 이 프로세스는 재귀적 구현을 통해 원하는 만큼의 세분성을 띠도록 조정할 수 있다.
- 반응과 계획의 수정: 에이전트는 이 행위들을 할 때마다 세상에 대한 정보를 수용하고 이 관찰은 다시 메모리 스트림에 들어간다. 그리고 이 관찰은 에이전트가 계획을 계속 진행할지, react(반응)할지 결정하는 데 활용된다고 한다.
LLM 프롬프팅에 전달되는 두 개의 문장을 통해 이 결정을 내리는데, 하나는 “What is [observer]’s relationship with the [observed entity]?”이고 다른 하나는 “[Observed entity] is [action status of the observed entity]”이다. 응답은 함께 요약되어 다음 계획에 대한 수정을 계획한다.
최종적으로, 행위가 에이전트 간의 상호작용을 지시할 때, 그들 간의 대화를 생성해 낸다. - 대화: 에이전트들은 다른 이들과 대화한다. 한 에이전트는 상대 에이전트에 대한 요약된 기억을 바탕으로 첫 대화를 발화한다.

위와 같은 프롬프팅으로 첫 대화의 시작말을 얻어온다. 이제 이 대화들은 각자의 기억을 바탕으로 하여 서서히 쌓이면서, LLM에 보내는 프롬프트에 반영된다.

이 반복은 한 사람이 대화를 끝내기로 결정할 때까지 지속된다.
모델 평가
정성적인 평가를 진행했는데, 지식 유지, 기억 검색, 계획 생성, 반응, 반영. 각각에 대해, 5개의 질문을 직접 에이전트에게 질문하는 방식으로 진행하였다.
100명의 사람(18세 이상 영어에 유창한 조건의)이 이 질답을 평가했다.
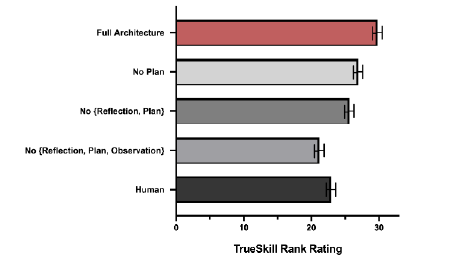
END-TO-END 평가
이틀 동안의 샌드박스 게임일 기간 동안, 25명의 에이전트의 상호작용을 평가한다.
즉각적인 사회 행동
정보 전달, 관계 형성, 에이전트간 협동 이렇게 3가지로 평가했다.
-
측정
정보 전달은 사회과학에서 흔히 연구되는 사회 현상이다. 각 에이전트가 정보를 온전히 전달받고 자신의 지식으로 만들었는가에 대해서 실제로 에이전트에게 질문하는 방식으로 측정했다.
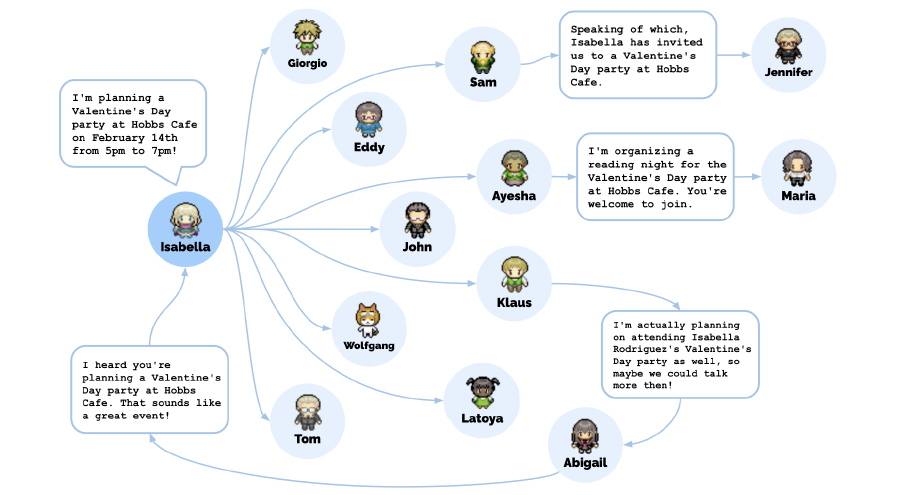
위 그림은 발렌타인데이 파티에 대한 정보가 어떻게 전달되었는지를 나타내는 그래프이다.
어떤 사람을 아는지, 또 이것이 환각이 아닌지 다시 한 번 재질문하여 에이전트들의 인간관계를 분석했다.또, 발렌타인데이 파티에서 그룹 활동을 어떻게 협동하는지를 토대로 에이전트간 협동에 대해 평가했다. 발렌타인데이에 대해 듣고 그 활동을 하기 위한 일에 대해 계획을 하는지 하지 않는지를 기록했다.
-
결과
정보 전달:
시장 선거에 대해 – 4% -> 32% (1명에서 8명)
이사벨라의 파티에 대해 -> 4% -> 48% (1명에서 12명)사회관계 형성
0.167 -> 0,74사회 협동
12명 중 5명이 발렌타인데이 행사에서 함께 일을 했다.
개인 의견
LLM을 활용해서, DB 같은 것들을 붙이고 LLM에 파이프라인 형식으로 다양한 아키텍처를 붙여 실제 사람처럼 행동하고, Agent끼리 Interaction하는 아키텍처를 만든 논문이다. 평가 방식도 정성적이기만 하고, GPT의 잠재력에만 의존하기 때문에 고전적인 학자들 중에서는 이 논문을 깊게 인정하지는 않는 사람도 있다고 한다.
하지만 적어도 LLM이 AGI로 향하는 방향에 있어서, 전이학습적인 측면에서 다양한 가능성을 보여줄 수 있고 Agent 간 상호작용으로써 집단적인 행동이 얼마나 잘 나오는지를 잘 보여주는 사회실험이자 인사이트라고 생각한다.
