초록
Voyager(보이저)는 LLM-powered한 마인크래프트에서의 플레잉 agent이다. 논문에서는 LLM-powered embodied lifelong learning agent in Minecraft that continuously explores the world, acquires diverse skills, and makes novel discoveries 라는 표현을 썼는데, 쉽게 말해서 마인크래프트를 플레이하는 agent이다.
보이저는 3개의 구성 요소로 이루어져 있다. 1) 탐험을 극대화하는 자동 커리큘럼, 2) 복잡한 행동을 저장하고 검색할 수 있는 지속적으로 성장하는 스킬들의 라이브러리, 3) 환경 피드백, 실행 오류, 프로그램 개선을 위한 자체 검증 시스템이 그것이다.
보이저라는 모델은 위 3개의 구성 요소를 바탕으로 마인크래프트라는 환경에서 할 수 있는 스킬(나무 캐기, 화로 만들기 등)들을 활용하여 매크로 코드를 작성하는 방식으로 구동되는 것으로 보인다.
서론
마인크래프트는 매우 자유도가 높고 목적이 불분명한 게임이다. 이 게임에서는 embodied AI가 작동할 만한 환경을 제공해 줄 수 있다.
마인크래프트를 플레이하는 모델은 사람처럼 3가지의 기능을 만족해야 한다. 1) 적합한 task를 제안하고, 2) 환경의 피드백을 고려해 스킬들을 refine하고, 3) 지속적으로 세상을 탐험하는 것이 그것이다.
Automatic Curriculum
Automatic Curriculum은 GPT-4를 통해 환경의 상황을 인풋으로 받아, subtask를 output한다.
Skills Library
그리고 이런 식으로 구성된 스킬들은 skills library에 저장되고, 추후 비슷한 행동을 해야 할 때 비슷한 skill들을 꺼내어 쓰게 된다.
iterative prompting mechanism
액션을 매개하는 매크로 코드는 한번에 성공할 수 없다. 따라서 발생하는 에러를 수정할 수 있는 부분이 필요한데, 이것이 바로 그 부분이다. 이 부분은 다음과 같은 3단계로 작동한다: 1) 생성된 프로그램을 실행하여 오류를 trace한다. 2) 피드백을 코드 개선을 위해 GPT-4 프롬프트에 통합한다. 3) 자체 검증 모듈이 확인할 때까지 프로세스를 반복한다. 작업이 완료되면 스킬 라이브러리에 커밋한다.
구현 방법
Automatic Curriculum
GPT-4의 거대한 규모의 지식을 활용하여 꾸준히 새로운 task를 생성할 수 있다. 즉, GPT-4의 거대한 Corpus(사전 지식)로부터 skill library에 들어갈 skill들의 아이디어를 get해온다. GPT 프롬프팅은 다음과 같은 단계를 밟는다.
1) 사전 프롬프팅: 다양한 행동을 장려한다는 all-bound 룰을 만든다. 예를 들어, 첫 프롬프트로 “저의 최종 목표는 가능한 한 다양한 것을 발견하는 것입니다…” 등의 문장을 넣어준다.
2) The agent’s current state, including inventory, equipment, nearby blocks and entities, biome, time, health and hunger bars, and position; 게임상에서 존재하는 상황의 정보들이다. (F3 누르면 확인 가능 ㅋㅋ)
3) 이전에 완료한 작업과 실패한 작업
4) 추가적인 내용: 위키 지식을 기반으로 하여 GPT-3.5를 사용해 자가 질문 후 자가 답변하는 과정을 거친다.
Skills Library
액션들을 저장하고 꺼내 쓰며, 진화하는 모델을 만들기 위해 Skill을 저장하고 업데이트할 수 있는 Skills Library를 만든다. Skill들은 그 skill을 수행할 수 있는 코드로 저장된다. 이 프롬프팅은 다음과 같은 조건이 존재한다.
1) 사전 프롬프팅: all-bound 룰을 만든다. 이를테면 “당신의 기능은 더 복잡한 기능을 만드는 데 재사용될 것입니다. 따라서 일반적으로 재사용할 수 있도록 만들어야 합니다.” 등의 문장을 넣는다.
2) 원시 API를 제어하고 스킬 라이브러리에서부터 비슷한 스킬을 검색한다. in-context(문맥) 학습이 잘되기 위해선 필수적이다.
3) GPT-4가 자체적으로 개선할 수 있는 환경 피드백, 실행 오류 및 비평의 마지막 라운드에서 생성된 코드
4) 인벤토리, 장비, 주변 블록 및 엔티티, 바이오메, 시간, 건강 및 헝거 바 및 위치를 포함한 에이전트의 현재 상태
5) Chain-of-thought prompting to do reasoning before code generation.
위 스텝을 보면 알 수 있듯 iterative prompting mechanism이 위 프롬프팅 방식에 적용되어 있음을 알 수 있다.
Iterative prompting mechanism
반복적으로 수행 가능한 프롬프팅 매카니즘에 관하여 서술한다. 이는 GPT가 만들어낸 코드의 오류를 인정하고 더 나은 코드를 반복적으로 만들어낼 수 있도록 하기 위하여 만들어진 방법론이다. 3가지의 스텝을 만족하여야 한다:
1) 환경 피드백: 마인크래프트에서 output한 오류 메시지(철이 부족해서 철 흉갑을 만들 수 없습니다)를 받아들여 피드백한다.
2) Execution Error: 컴파일 에러 등에 대해 오류 메시지를 받아 피드백한다.
3) Task 성공여부 판단: 실제로 task를 수행해 보고, 성공 여부를 판단한다. 실패했을 경우, 개선점을 제공한다.
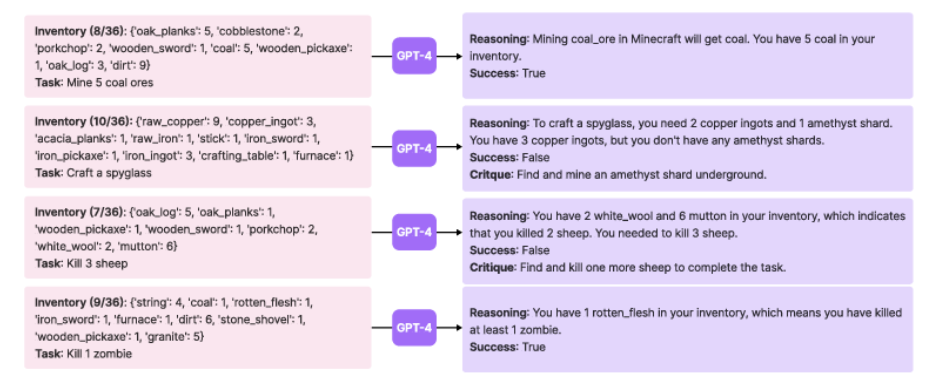
실험
환경 정보
GPT4-0314와 GPT3.5-turbo0301을 텍스트 완성을 위해 사용, 텍스트 임베딩을 위해서는 text-embedding-ada-002 API를 사용했다고 한다.
기존에 마인크래프트를 위한 embodied LLM-based agent가 없었으므로 기존의 LLM-based model들을 인터프리팅하는 방식으로 성능을 비교했다고 한다. ReAct, Reflexion, AutoGPT 등의 모델들을 사용했다고 한다.
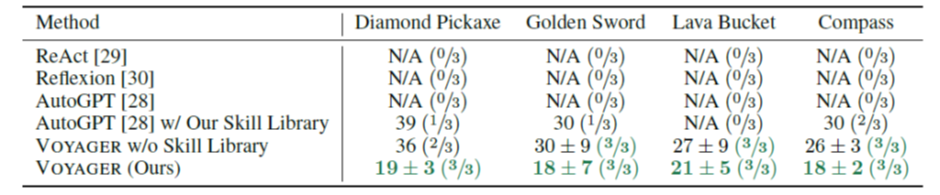
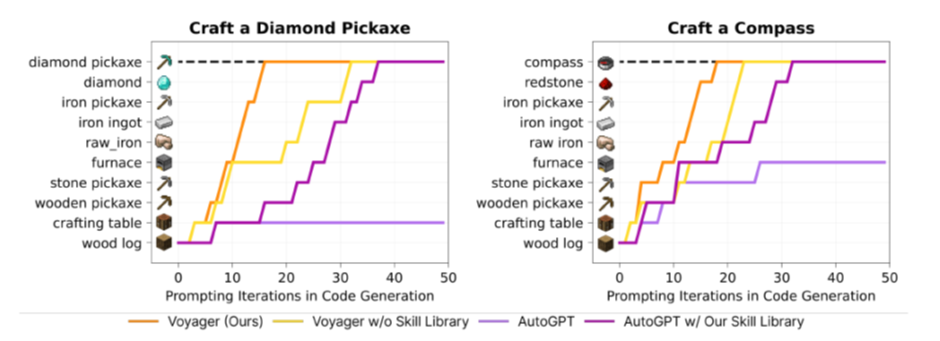
두 그림 다, 몇 번의 반복 프롬프팅이 있었던 후에야 학습되지 않은(zero-shot) 성과를 마인크래프트의 대표적인 아이템으로 설정한 목표치에 대해 냈는지 표시한 것이다. 보이저가 상당히 빠르게 다이아몬드 곡괭이에 도달한다는 것을 알 수 있다.
skill-library라는 방법론 자체가 상당히 고무적인 것이, task 분배기에 보이저 뿐만 아니라 AutoGPT를 사용한 모델도 상당히 성능이 오르는 것을 알 수 있다고 한다.
제한 연구(기능을 하나씩 제한하여 성능을 트래킹하는 기법)
‘자동 커리큘럼, 기술 라이브러리, 환경 피드백, 실행 오류, 자체 검증, 코드 생성을 위한 GPT-4’ 이렇게 6가지 기능들을 제거해 가면서 각각의 기능이 성능에 미치는 영향을 연구한다.
- 자동 커리큘럼은 매우 중요하다. 자동 커리큘럼을 빼고 랜덤한 모듈을 넣으면 agent가 획득하는 아이템이 93% 이상 떨어진다고 한다. 수동 커리큘럼을 넣으면 그것은 마인크래프트의 전문 지식이 필요하고 다양한 상황의 반영이 어려워진다.
- 스킬 라이브러리가 없는 보이저는 후반으로 갈수록 성장하지 못하고 고원 현상을 보인다. 이는 스킬 라이브러리가 보다 복잡한 스킬을 만들어내는 데 기여하고 있음을 알 수 있는 증거가 된다.
- 자체 검증을 빼면 agent가 획득하는 아이템이 73% 이상 감소한다. 자체 검증이 차지하는 역할 또한 매우 중요하다고 할 수 있다. 자체 검증은 스킬을 재시도할지 혹은 다른 일로 넘어갈지 결정하기 때문에 매우 중요한 역할을 담당한다.
- GPT-4는 GPT-3.5에 비해 5.7배 다양한 코드를 작성해 준다. 이는 GPT-4의 성능이 코드 생성 부분에서 비약적으로 발전했음을 보여 주며, GPT-4에 대한 최근의 연구 결과를 입증해 주는 증거가 된다.
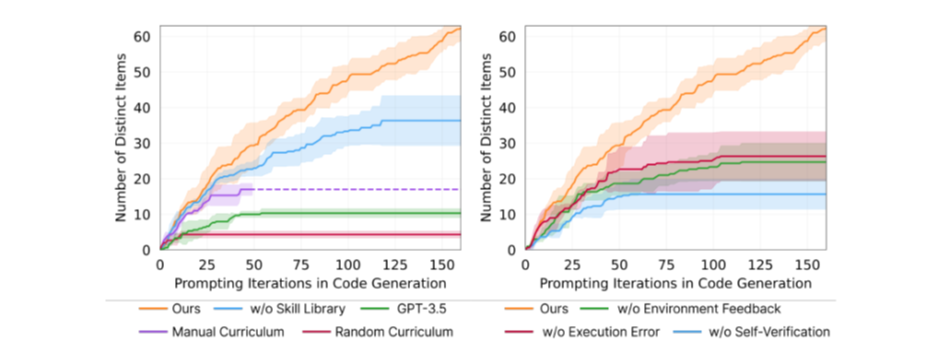
위는 그래프이다. 스킬 라이브러리가 없어도 꽤 좋은 성능을 내는 것 같지만, plateau 현상(학습이 더 이상 진행되지 않아 iteration이 진행되어도 Mark가 동일한 현상)이 벌어짐을 알 수 있다.
멀티모달 모델로써의 발전 가능성
GPT-4는 기본적으로 멀티모달 모델이 아닌지라 이미지를 인식할 수는 없으나, 사람의 피드백을 통해 멀티모달 모델로써의 발전 가능성을 시사한다:
1) 보이저 모델의 자체검증 기능과 2) 자동 커리큘럼 기능을 인간의 이미지 인식 능력을 활용하여 인간에게 critic 역할을 부여하는 방법들을 제시하고 있다.
한계와 발전 방안
비용. GPT-4의 비용이 너무 비싸다는 단점이 있다. 하지만 보이저는 GPT-4 성능 수준의 코드 생성력을 요구한다.
부정확성. 올바르지 못한 스킬들을 생성하는 경우가 여전히 있다.
환각 현상. 게임 내에 존재하지 않는 구리 검을 생성하도록 코드를 생성하거나, 잘못된 원시 API를 가져오는 경우도 있다고 한다.
결론
오늘은 마인크래프트를 플레이할 수 있도록 고안된 Voyager라는 논문에 대해 리뷰해 보았다. 기본적으로 강화학습적인 측면에서 게임플레이를 할 수 있도록 접근한다는 점에서는 일반적인 강화학습 논문 같지만, 모든 구현을 GPT 중심적으로 자연어 모델을 통해 구현하였다. 하지만 놀라울 정도로 이전의 강화학습 모델들보다 더 나은 성능을 보여주었고, Skill Library처럼 GPT에 다양한 기능을 붙이는 것이 얼마나 강력한 일반성을 제공하는지 제시한 좋은 논문이라고 생각한다.
