해시 맵을 사용하다 보면 알 수 밖에 없는데
Hash function을 이용해 나온 해시값을 capacity 를 활용해
모듈러 연산 후 나온 값을 해시테이블에 저장한다.
이 때 . 발생 하는 문제를 Collision이라고 한다.
이 때 해결하는 알고리즘이 대표적으로 2종류가 있다.
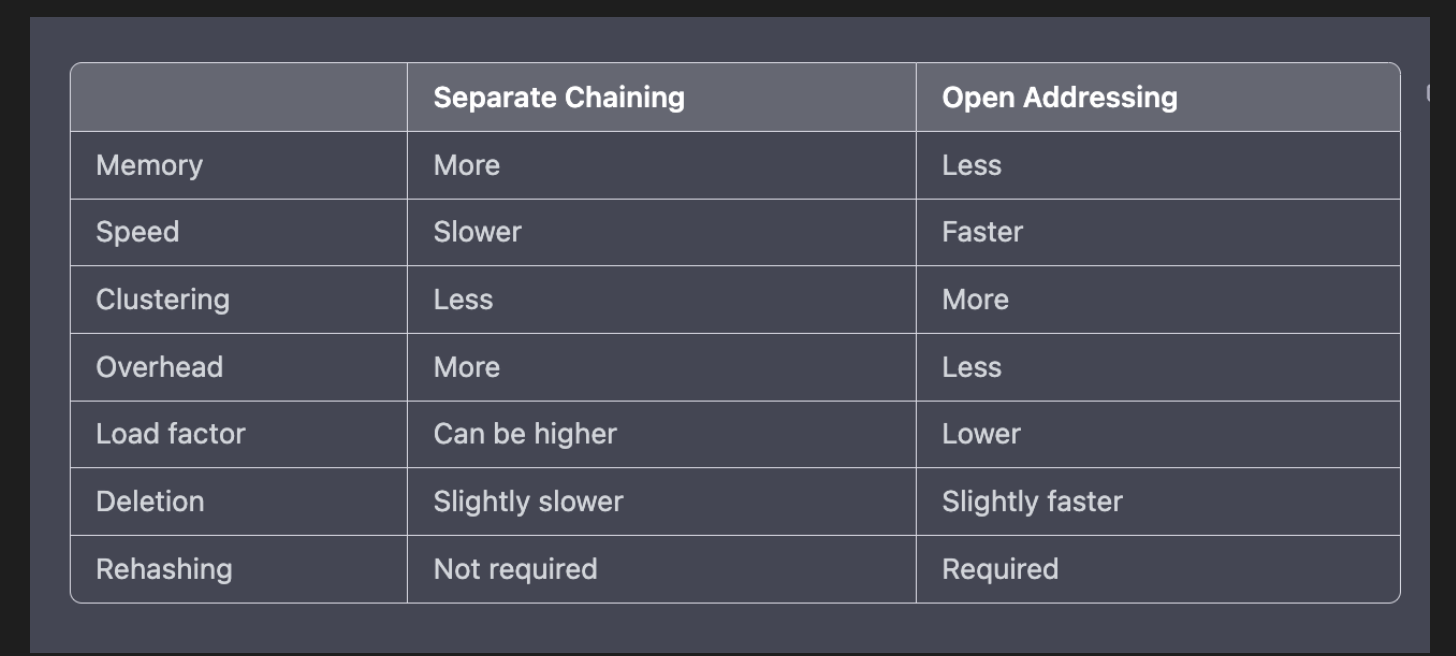
Separate Chaining
한국말로 분리 연결법이라고도 하며 해시 충돌이 발생하게 되면.
같은 해시 값을 가지는 노드들을 하나의 링크드 리스트로 관리하게 된다.
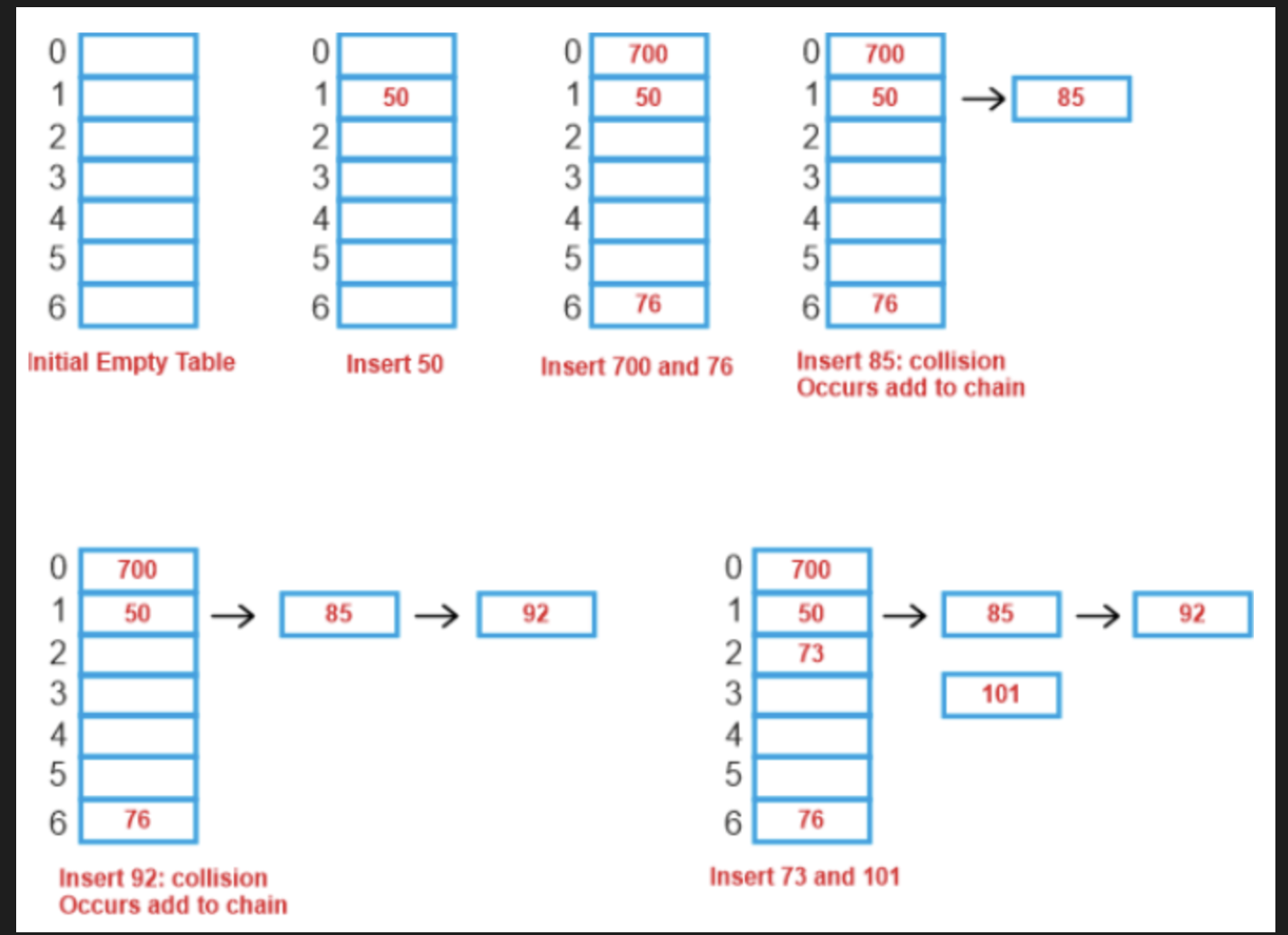
장점으로는 삽입 , 삭제 , 검색 연산들이 모두 링크드 리스트에서 사용되어
링크드리스트에 노드를 관리하다 보니
충돌로 위한 해시 테이블의 구조 변경을 위한 메모리를 사용하지 않고
그냥 해당 인덱스의 링크드 리스트에 삽입하기만 하면 되서 메모리 사용이 비교적 효율적이다.
적은 수에 충돌에 대해서는 높은 성능을 보장한다.
말은 즉슨 리스트가 길어질 경우 ( 충돌이 많이 발생한 경우 )
검색 시간이 늘어나고, 최악의 경우에는 O(n)의 효율성을 가지게 된다.
성능이 떨어지게 된다.
또한 해시테이블의 크기 조절에 주의해야한다.
capacity를 적게 유지하면 충돌량이 많아지고 , 너무 크게 유지하면 메모리 사용량에 주의해야한다.
모든 해시 알고리즘이 주의해야하긴 하지만 Separate Chaining에서 더욱 단점이 된다고 생각한다.
다른 알고리즘과 다른 개성를 정리해보자면
- 충돌이 발생한 경우 링크드 리스트를 관리한다.
- 충돌 이전에는 단순히 노드만 저장한다. - 충돌에 대한 해결 속도가 빠르다
- 노드를 링크드리스트에 추가만 하면 되기 때문. - 유연한 크기 조절이 가능하다
- 개인적으로 해시 값의 capacity의 변경 임계점이 더 길다고 생각한다.
- 링크드리스트에 계속 삽입하다가 . 특정 수치 이상을 리스트에서 관리하게 되면
그때서야 테이블 자체를 확장하면 되서 더 빠르다 생각했다.
자바진영은 왜 Separate Chaining을 선택했을까?
여자친구의 마음을 이해하는 것 처럼 자바의 마음을 이해보자.
자바는 다양한 플랫폼에서 동작할 수 있는 프로그래밍 언어로 탄생했다. ( Write Once, Run Anywhere )
자바는 기존 언어 들과 다르게 GC를 이용해 메모리를 관리하도록 구현되었다.
이와 비슷하게 다양한 플랫폼에서 동작할 수 있는
대용량 데이터 처리를 위한 효율적인 해시 충돌 해결 방법을 선택하고 싶었던것 같다.
Separate Chaining은 공간복잡도(메모리할당량)가 높은 대신
각각의 슬롯에서 저장되는 값이 적어서 메모리 사용량이 적다.
반면 Open Addressing 기법은 해시 충돌이 발생하면
해시 테이블 내의 슬롯을 일정한 간격으로 건너뛰며 탐색하는 방식을 사용하는데,
이 때문에 해시 테이블의 크기를 유연하게 조절하기 어렵고.
(모든 요소를 다시 생성-> 재할당해야해서)
탐색을 해야함으로 메모리 사용량이 높다.
Separate Chaining은 공간복잡도가 다른 알고리즘에 비해 높은편이다
하지만 자바를 활용하는 환경은 주로 공간 복잡도보다 시간 복잡도가 중요하기 때문에 큰 문제는 아니라 판단된다.
이 글의 주제는 파이선과 자바의 선택의 차이 이기 때문에 후반부에 좀더 자세하게 설명하겠다.
Open Addressing
한국말로 개방 폐쇄 이라고 하며 해시 충돌이 발생하게 되면.
같은 해시 값을 가지는 노드의 다음 인덱스에 저장하게 된다.
자바또한 Open Addressing으로 구현이 가능하기도 하다
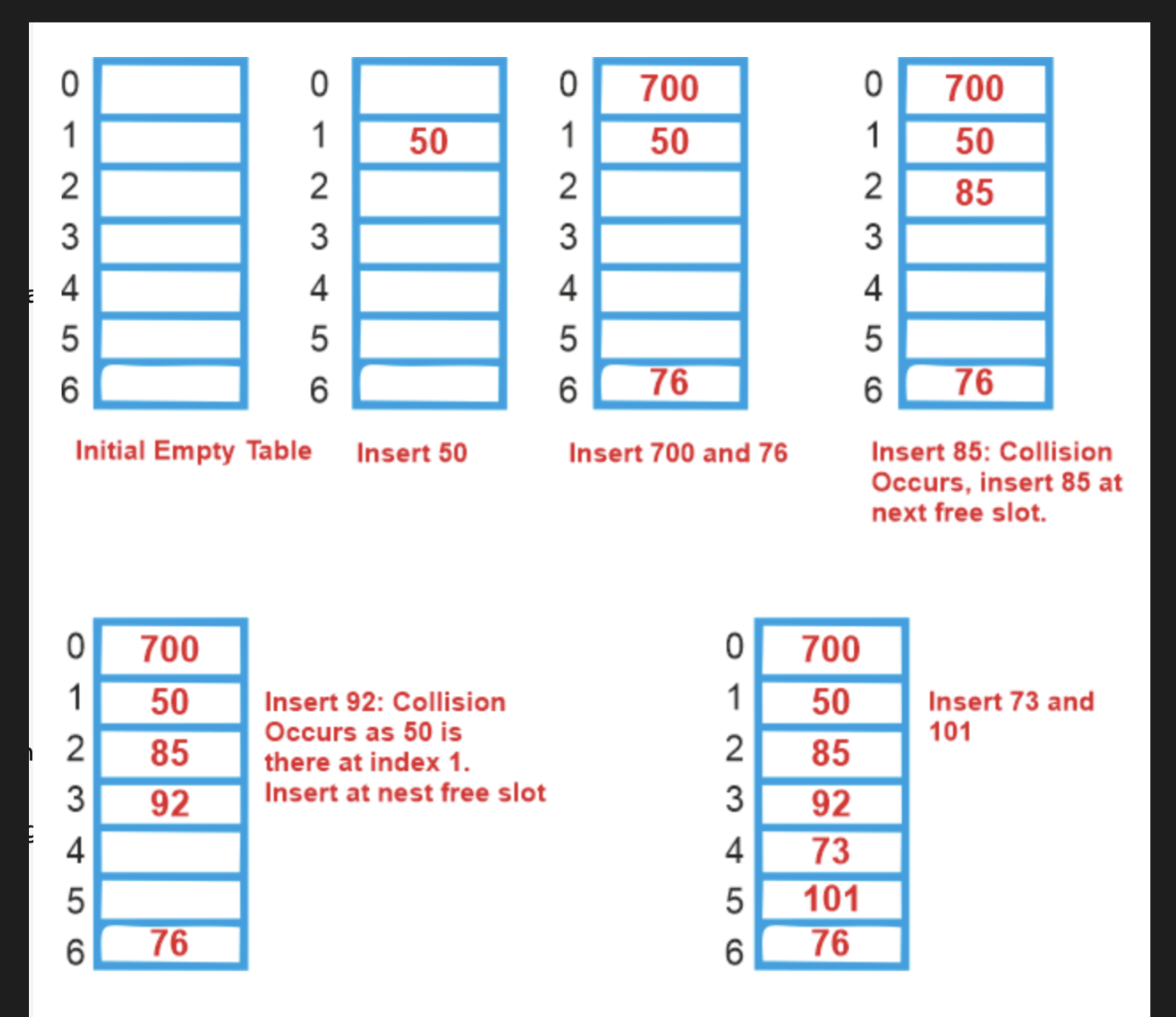
이미지에 나온 대로
1. 1번 인덱스에 이미 값이 있을 때.
2. 1번 인덱스에 새로운 값이 들어오게 된다면 그 다음 인덱스인 2번에 들어오게 된다.
3. 다음에 또 1번 인덱스에 들어오게 된다면 2번 인덱스로 찾아가고 그래도 있으면 3번 인덱스를 찾아간다.
개방 패쇄 방식은 충돌 발생 시 다음 노드에 저장된다.
이때 주로 사용되는 탐색 방식은 몇가지 있는데.
- 선형 탐사(Linear Probing)
- 다음 슬롯으로 일정한 간격으로 이동해 값을 저장 ( 일반적으로 일정한 간격은 1을 의미한다. )
- 파이선의 기본 구현 - 이차원 탐사(Quadratic Probing)
- 일정한 간격으로 제곱으로 이동해 값을 저장
- ex ) 1번 발생시 1, 2번 발생시 4 , 3번 발생시 9만큼 이동해 저장한다. - 이중 해싱(Double Hashing)
- 두개의 해시 함수를 사용해 다음 슬롯을 결정한다.
- 충돌 발생 시 해시 함수를 이용해 다음 슬롯을 정한다.
- 함수를 한번 더 사용하기 때문에 충돌이 덜하지만
구현이 복잡하고 해시 함수에 문제가 있을 경우 성능이 떨어질 수 도 있다.
파이선 공식문서에서 "hash table implemented using open addressing"으로 파이썬의 해시테이블은 open addressing으로 구현되어있다.
외에도 C++ , Rust , Go , Lua등의 언어도 사용중인 알고리즘이다
처음 봤을때 든 생각은 비효율적으로 보였다. Separate Chaining 과 다르게
노드가 사라지고 추가되고 capa가 가득 차게되면 수행하는 rehashing라는 것이 있는데
이러한 것만 봐도 더 복잡해 보이고 생각할 것이 많아 보인다
그렇다면 왜 open addressing를 사용할까.
Chaining에 비해 cache hit rate가 높고, 메모리를 적게 사용한다.
모든 노드가 하나의 테이블에 저장되면 메모리의 연속된 공간을 사용함으로 CPU 캐시의 데이터 캐시 히트율이 높아질 수 있다. Chaining과는 다르게 새로운 메모리를 할당하지 않아 CPU 캐시에 데이터를 유지하게 되는 경우 더 빠른 성능을 보일 경우도 있다 이런 CPU 캐시를 활용하는 빈도를 cache hit rate라고 표현한다.
또한 Open addressing은 해시 충돌 발생 시 다른 슬롯에 값을 저장하여 메모리를 절약할 수 있다는 장점이 있다. 또한 링크드 리스트와 같은 데이터 구조를 사용하지 않아 메모리의 임의 접근(random access)에 대한 성능 저하 문제가 발생하지 않는다는 장점도 있다.
계속 이렇게 노드가 추가되면 결국 테이블을 확장해야 하는 순간이 발생하는데.
map의 capacity의 2/3 이상 데이터가 존재하는 경우
딕셔너리의 (유효 데이터 * 3) 와 같거나 큰 수중 가장 작은 2의 배수를 새로운 capacity로 지정한다.
- 유효 데이터 수 = 10
- 유효 데이터 수 * 3 = 30
- 30보다 크거나 같은 가장 작은 2의 배수 = 32
- 딕셔너리의 capacity는 32
유효 데이터는 10개 실제로 저장된 노드의 개수를 의미한다.
반대로 유효데이터가 적어질 경우 shrink라고 테이블의 크기를 축소해야 하는 경우도 있다.(Chaining에는 없다 )
유효 데이터 수가 capacity의 25%미만 일 경우 현재 딕셔너리 크기의 절반 중 2의 배수로 재 조정된다.
딕셔너리의 크기를 변경하며 원래 크기의 해시 테이블에 있는 모든 데이터를 새로 만들어진 테이블에 다시 해싱한다. 이 때 기준 값은 이미 저장되어 있는 key가 된다.
글만 봐도 느껴지듯이 굉장히 많은 비용이 발생해 최소한으로 발생하도록 주의해야 한다.
파이썬은 왜 Open Addressing을 선택했을까?
- 메모리를 효율적으로 사용할 수 잇다. ( 공간 복잡도가 낮다 . )
- 캐시 효율성이 높다 위에서 설명한것과 같이 히트율이 높다
- 탐색 속도가 빠르다 슬롯에 직접 저장하기 때문에 데이터를 찾는 속도가 빠르다.
파이선의 "Simple is better than complex" 라는 철학을 가지고 있다.
언어적으로 간결하고 직관적인 문법을 가지고 있는데
이는 구현이 하나의 자료 구조 안에서만 해결되어 간결하고 메모리 사용량이 적다는 것과 캐시 히트율을
파이썬의 간결함과 직관성과 일치해 선택하지 않았을까 싶다.
나는 왜 이 둘을 비교했을까.
예전에는 두 알고리즘의 동작을 보고 자바가 더 좋은것 같은대? 라고만 생각을 했는데
얼마전 멘토님과의 대화중 공간복잡도 시간복잡도의 얘기를 하던 도중
문득 생각난 것이 왜 파이선은 공간복잡도를 중요시 했을까 하면서 이 글을 작성하게 되었다.
빅데이터나 머신러닝 같은 분야는 공간 복잡도가 중요하다고 하던데 그래서 파이선을 선택했나?
같이 궁금하게 되었다.
결론적으로 자바와 파이선의 차이를 알게되었다.
자바는 다양한 플랫폼 에서 동작할 수 있는 언어로 탄생했다
그런 이유로 메모리 사용과 성능의 균형을 잘 유지하는 것이 중요했다.
그렇기 때문에 대부분의 사례에서 효율적으로 작동하는 방식은 채용하고파이썬같은 경우 데이터 처리 , 분석의 과학적 혹은 엔지니어릭 그리고
적긴해도 웹 개발등의 다양한 분야의
사용되는 인터프리터 언어로 개발되었다. 배열의 오버헤드를 최소화해 메모리 사용을 최적화해
선형탐사 , 섭동 , 로빈 후드 해싱과 같은 방식으로 구현하게 되었다.
각각의 프로그래밍 언어와 해당 사용 사례의 특성에 따라 최적의 해시 충돌 해결 방법을 채택한 결과인것 같다.
둘의 차이를 알게되어 좋았다.
etc Java에서는 open addressing 어떻게 사용될까?
위에서 말했다 싶이 기본적으로 separate chaining을 채용했지만 필요에 따라서
open addressing을 사용할 수도 있다. ( 직접 구현해서 )
-
연속된 메모리 공간이 필요한 경우:
연결리스트 방식(체이닝)을 사용하는 해시 테이블은
포인터 연산과 메모리 할당에 대한 오버헤드로 인해 더 많은 메모리를 사용한다.
이 경우, 오픈 어드레싱을 사용하면 메모리 오버헤드를 줄일 수 있다. -
해시 테이블 크기가 작은 경우:
작은 크기의 해시 테이블에서는 오픈 어드레싱이 더 나은 성능을 제공할 수 있다.
이는 해시 충돌이 적을 때 더 빠른 성능을 제공하기 때문이다. -
데이터 구조가 읽기 위주인 경우:
연결 리스트 방식(체이닝)은 포인터 연산으로 인해 메모리 접근 지연이 발생할 수 있으므로,
데이터 구조가 읽기 위주인 경우 오픈 어드레싱이 더 나은 성능을 제공할 수 있다. -
해시 테이블에 저장된 데이터의 크기가 작은 경우:
데이터의 크기가 작은 경우(예: 정수, 문자열),
오픈 어드레싱이 더 나은 성능을 제공할 수 있다.
이는 해시 테이블 내의 각 슬롯이 더 많은 데이터를 저장할 수 있기 때문이다.
- Linked List는 노드를 생성 , 연결등의 역할을 하기 위해 더 많은 메모리 공간이 필요하다
이는 오버헤드가 발생한다.> 오버헤드는 실제적인 작업 외 다른 동작들을 의미하는 단어
한줄 요약하자면
메모리 사용을 최소화 해야 하면서 해시 충돌이 적을만한 상황일때 그리고
데이터의 구조가 읽기 위주이거나 데이터의 크기가 작을 경우에서도 좋은 성능을 가질 수도 있다
Java에서는 오픈 어드레싱을 사용하는 해시 맵 라이브러리도 있다.
- Apache Commons 라이브러리의
OpenHashMap클래스도 오픈 어드레싱을 사용한다.
자바의 hashMap과 파이썬의 dictionary를 비교해 보았다.
자바
public static double measureInsertionSpeed(int numItems, int numTests) {
double avgSpeed = 0;
for (int t = 0; t < numTests; t++) {
// 빈 HashMap을 생성합니다.
HashMap<Integer, Integer> dataMap = new HashMap<>();
// numItems 개수만큼 데이터를 HashMap에 삽입합니다.
long startTime = System.nanoTime();
for (int i = 0; i < numItems; i++) {
dataMap.put(i, i);
}
long endTime = System.nanoTime();
double timeTaken = (endTime - startTime) / 1_000_000_000.0;
// HashMap에 데이터를 삽입하는 평균 속도를 계산합니다.
avgSpeed += timeTaken;
}
return avgSpeed / numTests / numItems;
}
public static double measureLookupSpeed(int numItems, int numTests) {
double avgSpeed = 0;
for (int t = 0; t < numTests; t++) {
// 데이터를 포함하는 HashMap을 생성합니다.
HashMap<Integer, Integer> dataMap = new HashMap<>();
for (int i = 0; i < numItems; i++) {
dataMap.put(i, i);
}
// HashMap에서 데이터를 검색하는 평균 속도를 계산합니다.
long startTime = System.nanoTime();
for (int i = 0; i < numItems; i++) {
dataMap.get(i);
}
long endTime = System.nanoTime();
double timeTaken = (endTime - startTime) / 1_000_000_000.0;
// HashMap에서 데이터를 검색하는 평균 속도를 계산합니다.
avgSpeed += timeTaken;
}
return avgSpeed / numTests / numItems;
}파이썬
def measure_insertion_speed(num_items, num_tests):
avg_speed = 0
for _ in range(num_tests):
# 빈 사전을 생성합니다.
data_dict = {}
# num_items 개수만큼 데이터를 사전에 삽입합니다.
start_time = time.perf_counter()
for i in range(num_items):
data_dict[i] = i
end_time = time.perf_counter()
time_taken = end_time - start_time
# 사전에 데이터를 삽입하는 평균 속도를 계산합니다.
avg_speed += time_taken
return avg_speed / num_tests / num_items
def measure_lookup_speed(num_items, num_tests):
avg_speed = 0
for _ in range(num_tests):
# 데이터를 포함하는 사전을 생성합니다.
data_dict = {}
for i in range(num_items):
data_dict[i] = i
# 사전에서 데이터를 검색하는 평균 속도를 계산합니다.
start_time = time.perf_counter()
for i in range(num_items):
data_dict[i]
end_time = time.perf_counter()
time_taken = end_time - start_time
# 사전에서 데이터를 검색하는 평균 속도를 계산합니다.
avg_speed += time_taken
return avg_speed / num_tests / num_items삽입 속도
자바 1000000 개의 항목에 대한 삽입 속도: 0.00000004 초 (999회 테스트)
파이선 1000000 개의 항목에 대한 삽입 속도: 0.00000007 초 (999회 테스트)자바 99 개의 항목에 대한 삽입 속도: 0.00000015 초/항목 (10회 테스트)
파이선 99 개의 항목에 대한 삽입 속도: 0.00000006 초/항목 (10회 테스트)
개수가 작을때는 비교적 노드를 바로바로 삽입하는 파이선이 더 빠르다.
검색 속도
자바 1000000 개의 항목에 대한 검색 속도: 0.00000001 초/항목 (999회 테스트)
파이선 1000000 개의 항목에 대한 검색 속도: 0.00000006 초/항목 (999회 테스트)자바 99 개의 항목에 대한 검색 속도: 0.00000004 초/항목 (10회 테스트)
파이선 99 개의 항목에 대한 검색 속도: 0.00000005 초/항목 (10회 테스트)
검색 속도의 경우 파이선과 자바의 환경차이 때문인지 둘 모두 자바가 우세하게 되었다.
자바 99999999 개의 항목에 대한 삽입 속도: 0.00000005 초
파이선 - 99999999 개의 항목에 대한 삽입 속도: 0.00000032 초
공간복잡도에 파악한게 자바의 경우 heap size를 12G를 할당해줘야 겨우 돌아갔다.
다만 이게 공간복잡도 문제인지 , 개인 하드웨어의 문제인지는 파악중이다...
~~자바가 속도는 빠르지만 메모리 할당량이 높은걸 파악할 수 있었다.~~나중에 파이선 내부에서의 알고리즘을 제대로 파악해 자바에서 제대로 이식해보고 싶다. 구현한 코드가 궁금하다면 아래의 안드레이 시오바누 블로그를 가보는 것을 추천한다.
이미지 출처
