KDD99 intruction Dataset 기반 Anomaly Detection
preprocess_data
Data가공
preprocess 전처리 - Missing data를 어떻게 처리할것인가 중간값을 집어넣을수도있고, 다른 열과의 상관관계에 가장 밀접한 애를 집어넣고 빠져있는 놈을 예측해볼 수 있음,노이즈를 어떻게 처리할것이냐 등을 처리하는 단계.
하지만, KDD99 intruction dataset의 경우 이미 정제가 되어있는 상태임. 따라서 missing data와 같은 부분을 처리할 필요는 없다.
이 부분에서 KDD dataset의 일부분을 뽑아내서 1%의 오차율만을 갖는 normal한 데이터를 만들어낸다.
이때, 1%의 오차율이 필요한 이유는 학습을 할때 오리지널 데이터만 넣어서 하면 안됨. 약간 틀린값들을 수용하게 하려면..데이터의 다양성을 인정할 수 있게 해줘야 견고하다.
약간 굴곡이 있는 데이터를 만들어서 넣어서, 모델의 정확성을 올리는것.
Robust한 dataset을 만드는것.
약간만 다른 데이터만 들어와도 abort하는것이 아니라 조금 수용 범위를 늘려준다.
# preprocess_data.py의 77~88라인 부근
def reduce_anomalies(df, pct_anomalies=0.01):
num_normal = len(df[df["label"] == "normal."])
num_anomalies = int(pct_anomalies * num_normal)
all_anomalies = labels[labels != "normal."]
# 무작위 추출을 통해 노이즈(이상치)의 양을 강제로 조절
anomalies_to_keep = np.random.choice(
all_anomalies.index, size=num_anomalies, replace=False
)
...이렇게 normal dataset으로 학습될 x_train가 만들어진다.
그러면 validation data로 쓸 x_test는

이렇게 기존 Intrusion data에서 25%정도만 뽑아서 사용한다.
그 이후 MinMaxScaler로 0~1 사이의 값으로 스케일링 수행
main.py에서 수행하는것임.

1-hot encoding
네트워크 패킷 데이터에는 숫자가 아닌 'TCP', 'HTTP' 문자가 많습니다. 이를 어떻게 숫자로 바꿀 것인가가 전처리의 관건. 다음과 같이 수행.
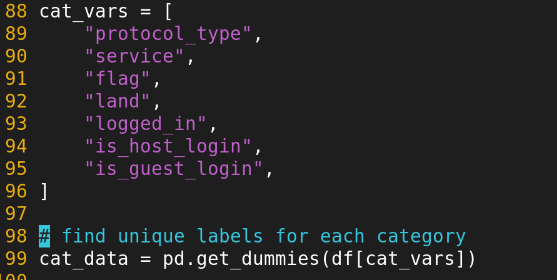

Autoencoder
입력 데이터(Original Input)와 그 데이터를 압축했다가 다시 풀어낸 복원 데이터(Reconstructed Output)를 1:1로 비교
encoder와 decoder를 나눠서 .. 서로 값이 다르면 잘못된것이라고 판별함.
input -> 압축 -> 원하는 데이터 크기로 동작.
input에는 normal데이터, 에러가 threshold값 이상이면 에러라고 판단하는것.
즉,
정상 데이터가 들어오면: 모델은 정상 패턴을 완벽히 꿰고 있어서, 압축했다가 풀어도 원래와 거의 똑같은 값을 만들어냅니다. 즉, Input - Decode ≈ 0 이 된다.
비정상 데이터가 들어오면: 모델은 이런 패턴을 본 적이 없습니다. 그래서 억지로 복원해봐도 원래 데이터와는 엉뚱한 결과가 나옵니다. 즉, Input - Decode = 큰 값 이 됩니다.

64~72가 encoding하는 부분
86~93이 decoding 부분
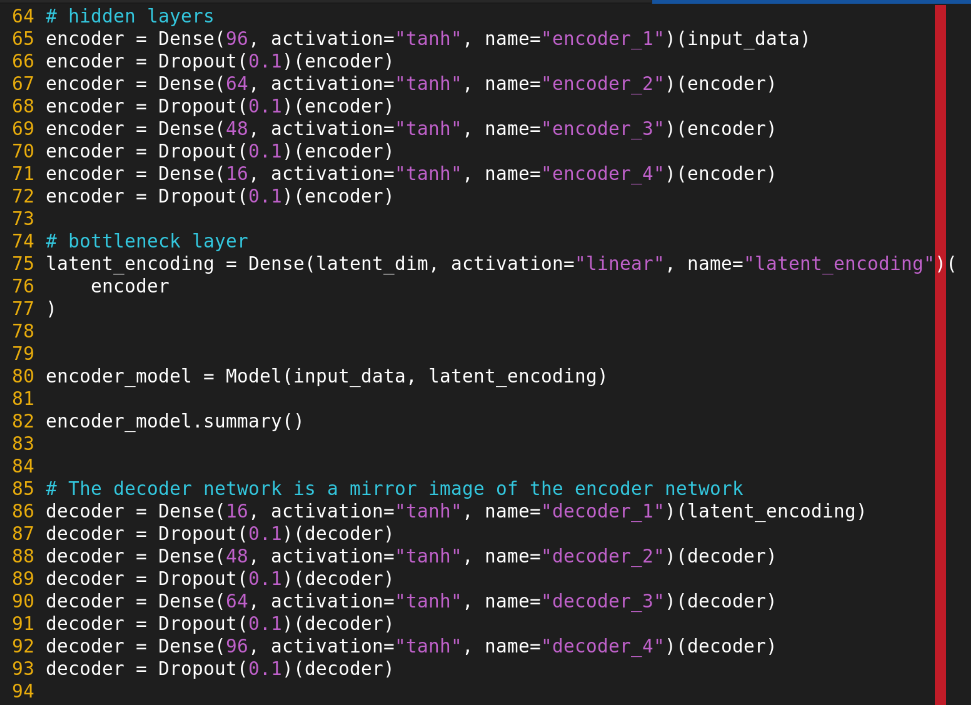
Validation

위와 같이 decode된 reconstruction 값이 원본 데이터와 다른 정도가 정해진 임계값을 넘으면, intrusion으로 판별한다.
connection 별로 encode/decode하여 reconstruction data와 비교함.
그 이후, Anomaly connection을 추출해내는데, 다음과 같이 결과값을 얻을 수 있음.
총 25만개중에 2100개정도가 Anomaly로 판별됨.
응용 방법, 추가적인 방법
데이터 크기만 가지고, 정상/비정상을 판별할 수 있을까?
1단계는 데이터의 크기만을 가지고 DDOS와 같은 단순 공격들을 필터링 해내고,
2단계에서는 1단계를 넘긴 연결에 대해서 오토인코더를 사용해서 디테일한 필터링을 수행하는 방식을 생각해볼 수 있겟다.
또는..
ping 공격이나, tcp syn공격과 같은 것들을 판별하기 위해서는 학습 데이터를 따로 가공하여 학습시켜야함.
ICMP: protocol_type이 ICMP이면서 duration이 짧고 패킷 수가 비정상적으로 많은 특징을 데이터셋에서 강조해야 한다.
TCP SYN Flood: TCP 연결 설정 과정인 3-way handshake를 완료하지 않은 상태(flag가 S0 등)가 짧은 시간에 폭증하는 패턴을 모델이 학습하도록 데이터를 구성해야 한다.
패킷을 커널단에서 후킹하여 응용단에 보내도 되는지 결정하게 함.
TODO: 2-step Anomaly detection.
1단계에서는 단순히 데이터크기만을 가지고 빠르게 DDOS와 같은 공격을 필터링하고, 2단계에서는 1단계를 패스한 데이터에 한해서만 encoding을 통해 필터링한다.
글을 따로 빼는것도 좋을것같음.
기존 방법 성능 테스트
2step 방법과의 비교.
Federated Learning
데이터 병렬화 방법 중 Federated learning. 연합 학습
왜 이것이 나왔는가
Privacy. 많은 데이터가 필요한데, 사진이라든지 이런 개인정보가 학습에 필요하다면....프라이버시 문제있음.
특정 모델 학습을 위한 데이터가 부족함. 다른 곳에서는 개인의 허락없이는 그 데이터를 가져올 수 없다. 모델의 정확도를 올리기 위해서 연합학습.
Efficiency. 데이터 전송하는데 너무 많은 저장, 통신 오버헤드가 발생한다. 파라미터만 보낸다. 파라미터가 엄청나게 크면 거기서 또 문제 생김.
Congestion이 발생하지 않게끔 하는 연구 존재.
Scalability. 중앙 집중형은 매우 느리다.
Collab. 기관간에 협력을 요구하는 경우. Agent들간의 협력.
서로 협력. 굉장히 중요하다. Physical AI. 로봇들간의 협력..어떻게 협력하면 좋을까..보상을 어떻게 분배할것인지와 같은 문제가 있음.
Collab할때 통신없이 하자. 다른놈의 액션을 예측하면서 수행하는 방법도 있음.
강화학습에서는 보상을 어떻게 분배하고 어느정도로 보상할것인지 결정하는것은 굉장히 어려운 기술인데...Collab환경에서는 그것이 더 힘들다.
쨌든 프라이버시 문제가 제일 크다. 법적으로 데이터 이동이 금지되어있다. 데이터를 옮기지 않고 학습하자는것.
Decentralized approach. 각각 edge에서 학습.
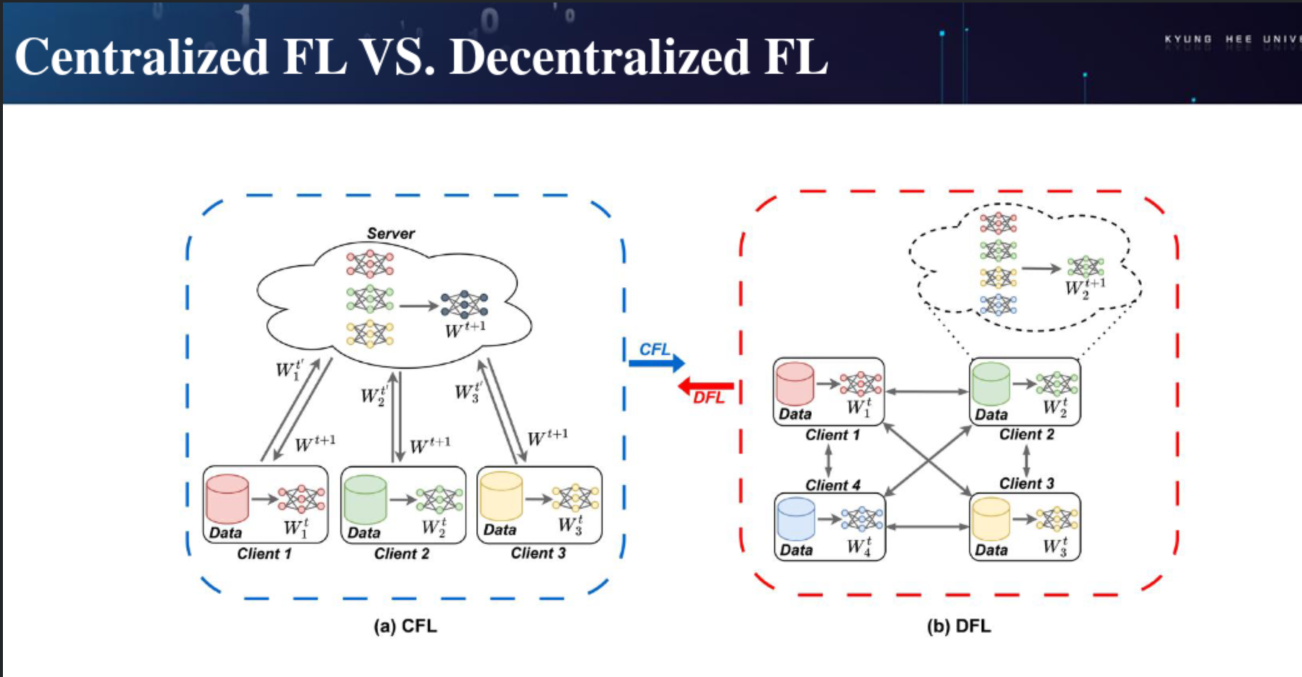
CFL vs DFL
CFL: 중앙 서버에 두고, 모델 파라미터들을 취합해서 aggregation 수행. 모델 업데이트 수행.
DFL: 중앙 서버 없이 각각 노드에서,,,,p2p 개념으로 수행하는것. 이때 각각 노드의 속도가 다르다면..오히려 DFL이 좋을 수 있다. CFL의 경우 모든 노드가 끝날때까지 기다려야하는 문제가 있음. 어떻게하면 조금 더 빨리할 수 있는가?
정확도 이슈. 들쭉날쭉한 데이터와 일정한 데이터 합쳤을때 어떤게 정확한것인가? 어떤것이 영향력을 더 가질 것인가와 같은 이슈 존재.
DFL 형태
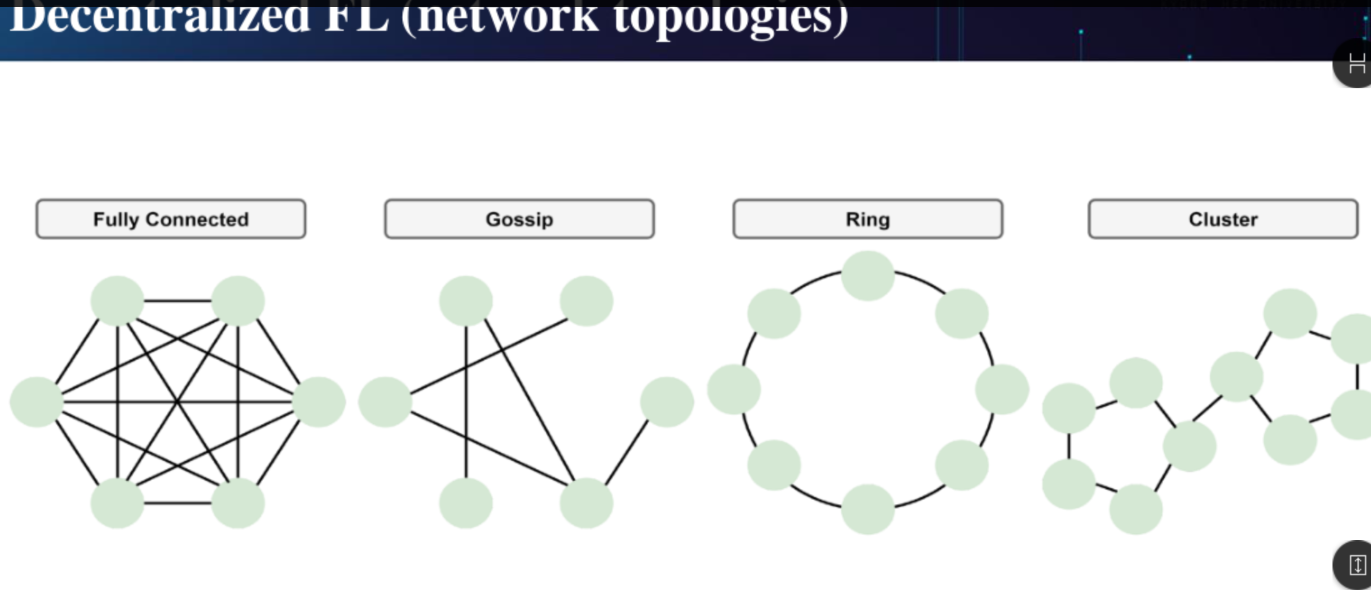
Fully Connected Gossip Ring Cluster 형태 존재
Cluster - 가까운 애들끼리 하고 경계에 있는 애들끼리 합치자. 이런것들이 다 네트워크와 관련된 이슈들이다.
Ring 으로 하면 한놈이 정체되면 굉장히 느려진다. 속도의 문제가 있다.
Fully는 너무 많은 통신을 필요로 함.
Gossip, Cluster는 괜찮음.
코드가 어떻게 구성되나?
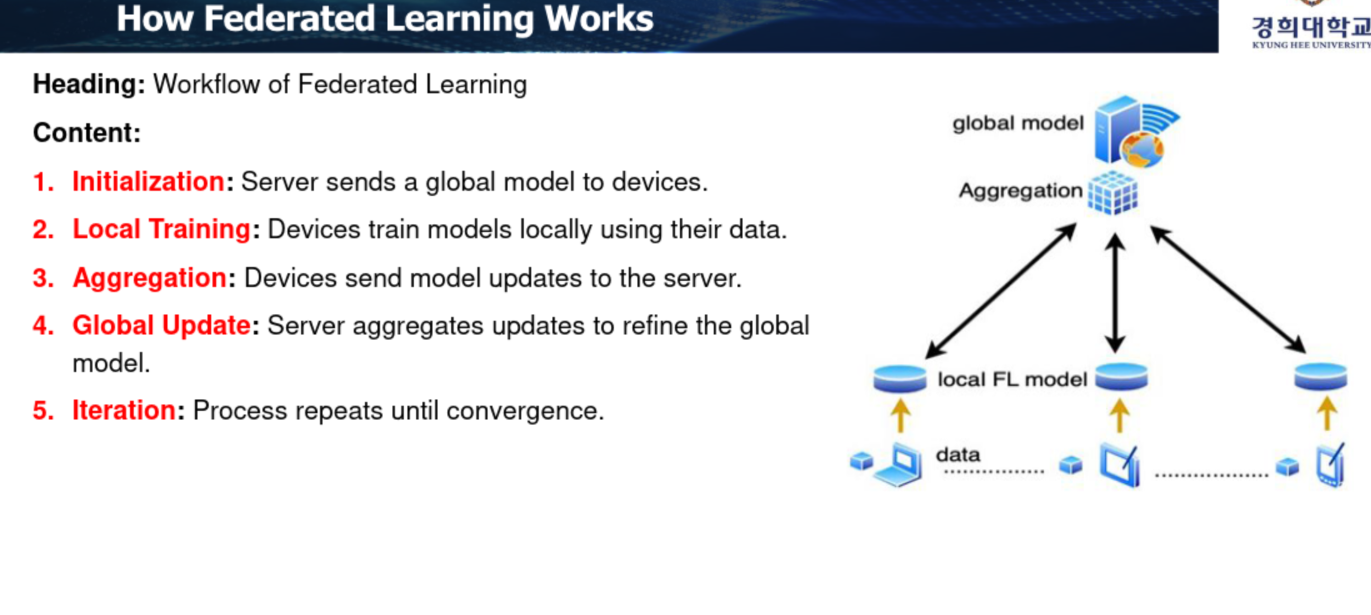
어떻게 코드가 만들어지느냐?
1. 모델 아키텍처 정의
2. 로컬 학습
3. 한 라운드 마다, 한 epoch마다 parameter 교환 필요. 이렇게 계속 aggregation.
4. Iteration 반복
Federated Learning 수행시 각각 가지고 있는 데이트세트 크기, 분포 모두 상이할것이다. 이를 non-identical distribution이라고 한다. 그걸 단순하게 averaging 해버리자는것이 Federated Averaging 기법. 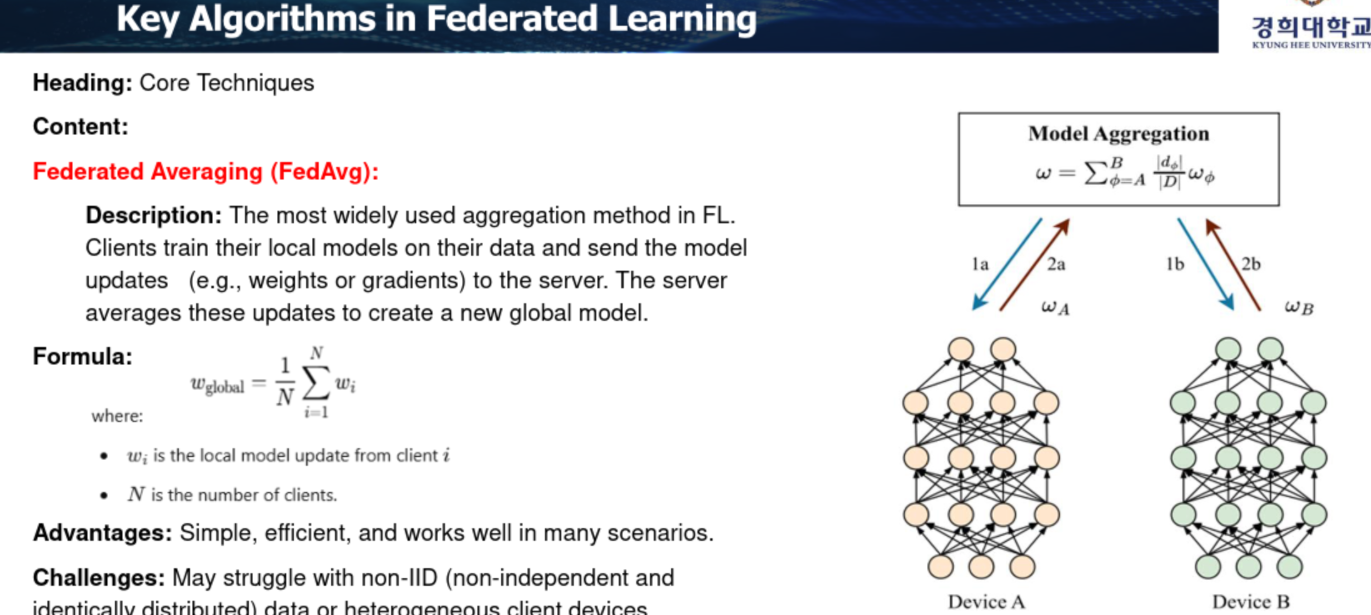
Federated Averaging(FedAvg) 기법
ex) y = ax + bx .....일때 처음 각 a,b,c 파라미터 랜덤으로 정의
y1 = ax...에서의 a,b,c와 같을리가 없다.
그 파라미터의 평균값을 쓰자. 노드가 많으면 많을 수록 N개로 평균화시켜서 학습하겠다는것.
Weighted Federated Averaging
누가 더 많은 데이터와 요소의 종류를 가지고 가중치...그걸 기반으로 평균 내자느것.

Secure Aggregation
aggregation 데이터까지 암호화시키자는 아이디어.
Weighted Federated Averaging
누가 더 많은 데이터와 요소의 종류를 가지고 가중치...그걸 기반으로 평균 내자느것.

Secure Aggregation
aggregation 데이터까지 암호화시키자는 아이디어.
FSVRG
그레디언트. 파라미터들의 분산을 보고 어느정도선에서 커버를 치자는것이 그 방법이다. 파라미터간의 분포를 보고 결정

Clustered Federated Learnning
비슷한 파라미터를 가지고 있는 애들끼리 합치는것. 끼리끼리 similarity(데이터 분포와 디바이스 타입)을 기반으로 그룹화하여

Differential Privacy-Based Aggregation
노이즈를 넣어서 모델을 업데이트하자. 차등적인 프라이버시를 확보하기 위해서 로컬 모델에 노이즈를 넣자. 로컬 모델 파라미터에 약간의 노이즈를 주자.
오리지널을 주는것이 아니라 노이즈가 추가되어서...가우시안 분포의 노이즈 추가.

Sparse Aggregation
중요한 특징을 지닌 파라미터들을 중심으로 aggregation.
변화가 적은 것은 냅두고 변화가 많은 파라미터들을 가지고.
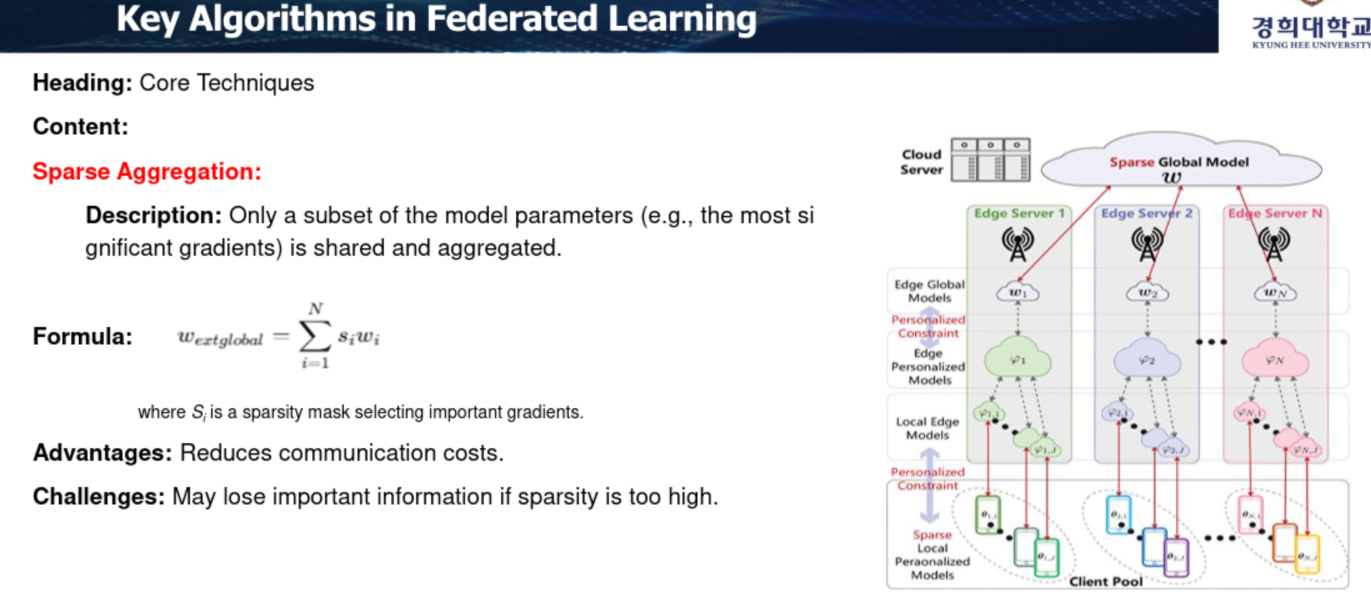
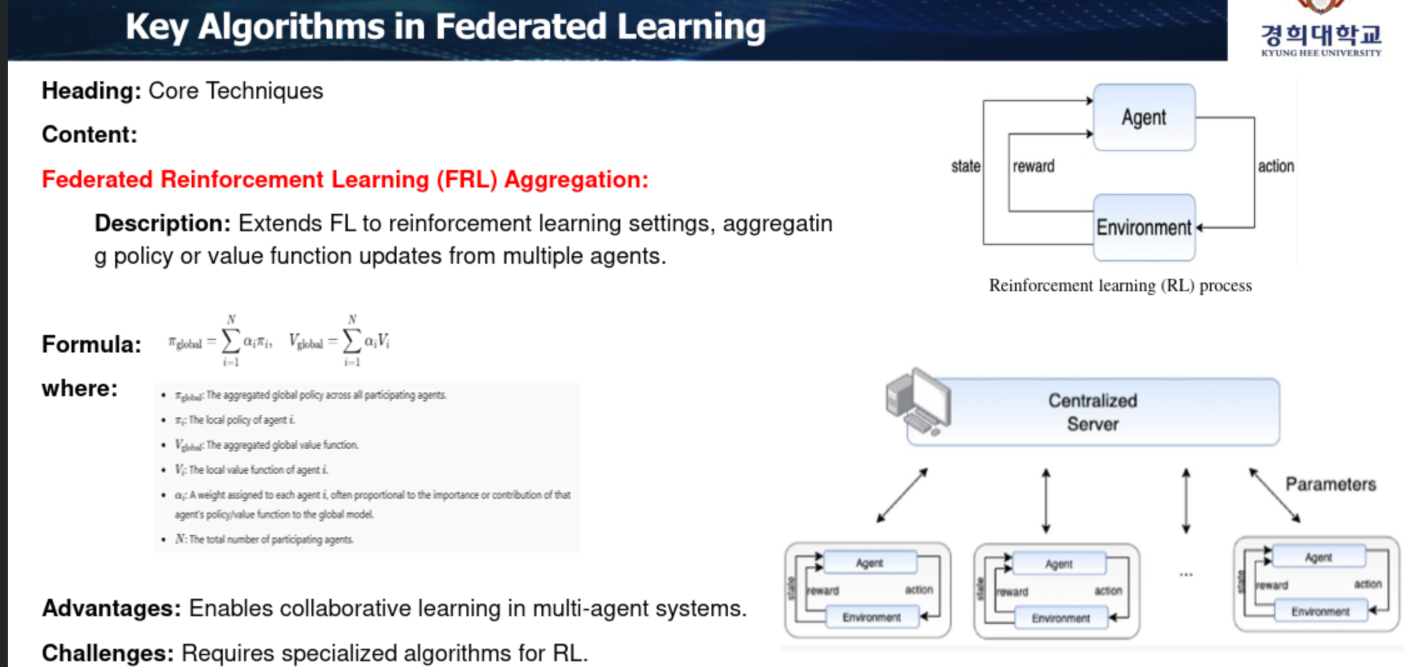
FRL Aggregation(Agent Computing)
FRL Aggregation
네트워크에서 꼭 알아야하는 부분. 액션을 줬을때 그 다음 상태가 어떻게 변화할지 보고, 그다음 액션에 보상을 주는것.
보상과 패널티에 대한 결과를 보고 피드백하여 반복적으로 액션을 변경시켜가는것.
강화학습.
Agent computing. 액션이 있어야함.
ex) 돌덩이가 있으므로 방향을 틀면 보상을 받는 형태. 그 액션들을 모아서 보상 체계를 넣는것이 강화학습.
Agent는 행동이 있다. 그 행동을 예측으로 하자. 지속적으로 읽으면서 권한을 다르게 부여하는것: agent. 액션과 피드백이 있는 소프트웨어를 agent라고 함.
환경을 지속적으로 읽으면서(Monitoring), 목표를 달성하기 위해 스스로 다음 행동을 결정함 (능동적).
어떤 액션을 취했을때 어떤 값이 나올것이냐. 보상 피드백을 통해 액션을 조정. 그 값을 가지고 다음 액션을 예측.
v3 백신의 예시. 계속해서 검사해서 액션을 취하고, 그 ㄱ값을 중앙서버에게 알림
Federated Agent Learning
Federated Agent Learning. agent끼리 연합학습. 한놈이 하는게 아니라 여러놈이 다 같이..
자기가 가지고 있는 지식을 공유하는 개념.
Challenges

1. Data heterogenity, Non-IID 인 경우 학습을 어떻게 할것이냐. 여전히 문제임.
2.3 을가지고 대충 ...어떻게 개선해봤다라는 프로젝트를 해야함.
