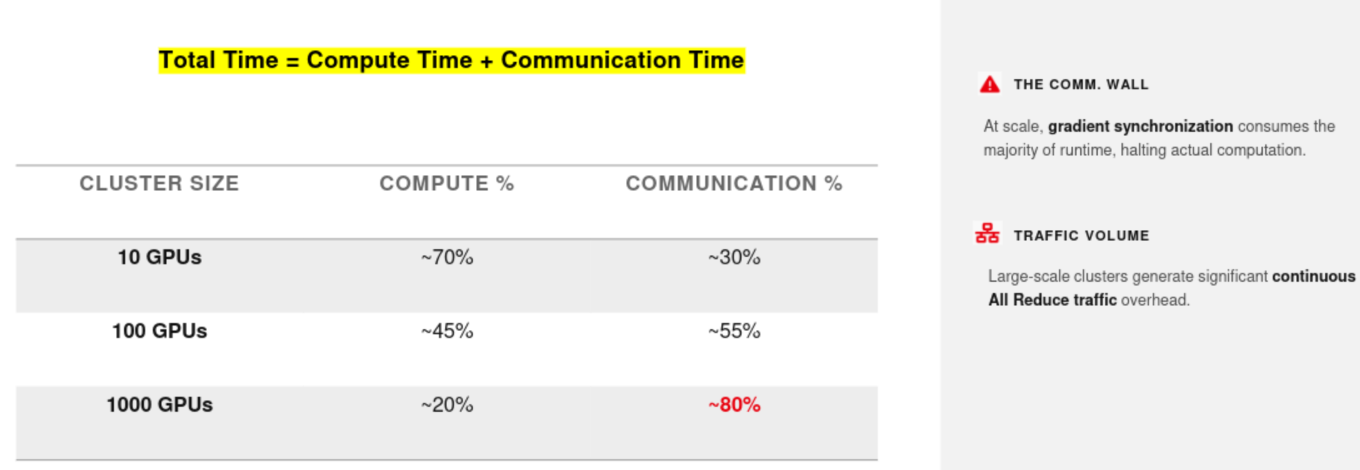
GPU Clustering 의 Communication overhead
메모리 폭발: GPT-3(175B)급 모델을 학습하려면 모델 파라미터, 옵티마이저 상태 등을 모았을 때 최소 800GB 이상의 초거대 메모리가 필요합니다. 단일 GPU나 단일 서버(Host)로는 물리적 탑재가 불가능하므로 GPU 클러스터링(Clustering)이 필수적입니다.
Computation Halting (연산 중단): 데이터 병렬화를 하면 각 GPU가 계산한 가중치 오차(Gradient)를 모아서 평균화(Averaging)해야 합니다. 문제는 이 평균화 패킷이 네트워크를 타고 오가는 동안, GPU는 다음 연산을 하지 못하고 기다리게 된다(Halting). 즉, 통신 속도가 AI 학습 속도를 결정하게 됩니다.

학습에서 중요한것은 위와 같다.
server GPU(메모리 크기)
-> memory size
TFLOPOS(Floating pointg 계산) 필요(메모리 속도)
버스기반 통신으로는 한계 있음(메모리 연결 링크)
-> memory bandwidth
네트워크 포트별 400GB, Low latency(네트워크). TCP/IP는 100us, RDMA 2us 정도의 latency.
-> communication overhead
GPU Centric network analytics

GPU_Clustering을 사용해서 모델 학습을 수행할때, 최적화하기 위한 5가지 로드맵이다.
-
먼저 Communication Bottleneck이 어느정도인지 식별한다.
-
DCN Topolgy 선정(구조 선정), 이 구조에 따라 비용이 달라진다. 어떤 AI서비스를 할거고, 학습 데이터 종류는 어떤것이고..어떤 시점에 publish 할것이냐 등에 따라 적절한 구조를 선정해야한다.
-
4 key challenges 파악.
Incast: congestion에 의한 retranmission,비효율, 전송지연Tail latency: 느린 학습 속도를 가진(Tail) 쪽의 노드를 기다리기 때문에 발생하는 Tail latency
Bandwidth: PCIe 버스나 10G/40G 이더넷 수준으로는 데이터를 다 통과시키는 데만 오래 걸림. 포트당 400Gbps 수준의 초고대역폭 네트워킹과 NVLink 같은 전용 링크가 강제된다.
CPU Overhead: TCP/IP 사용시, 모든 패킷에 대해 TCP stack 처리하기 때문에, CPU의 부하 발생.
-
솔루션 파악.
NVLink 4.0, RDMA/RoCE, and NCCL primitives와 같은 솔루션을 사용하여 챌린지들을 해결한다. -
Federated Learning의 구조 선정, 솔루션 적용
어떻게 해서 체계적, 계층적으로 학습을 구성할 것인가?
flat 구조로 할거냐 계층적으로 할거냐(multilayer)로 할것이냐 등의 고민 필요.
번외: 요즘 뜨는것은 Real-Time AI라 해서 Request - Response 가 100ms 안에 이루어지는 AI.
Distributed ML
data parallelism 과 model parallelism

Data paralleism 실습2에서 했듯이 데이터 쪼개서 학습.
GPU속도에 따라서 different minibatch할 수 있다.
Tail latency 해결 가능.매 라운드마다 gradients sync.
Model parallelism
Data flows through CPU.
각자 다른 모델을 쓰는것.
Distributed ML에서의 Parameter vs All-Reduce Server
전체적인 물리/논리적인 구조.
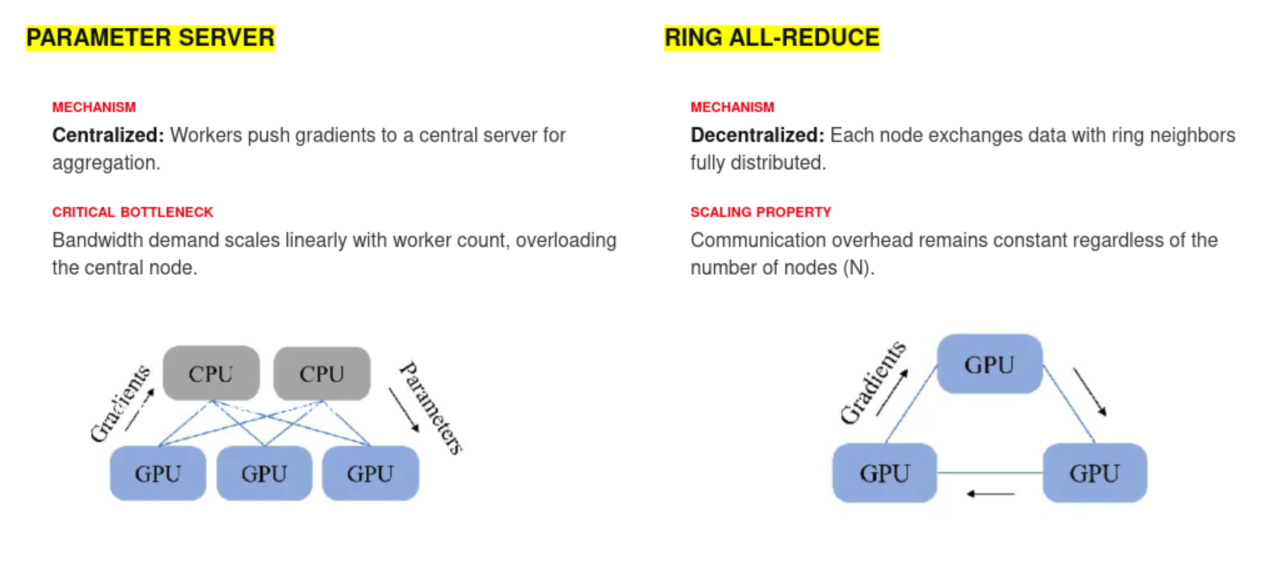
Parameter Server
중앙 서버가지고 aggreagtation.수행. worker들이 많으면 많을 수록 bandwidth 요구가 커진다.
워커가 늘어날수록 중앙 서버의 네트워크 대역폭이 터지는 Incast(인캐스트) 병목과 패킷 드롭이 발생한다.
Ring All-Reduce
각 노드가 서로 데이터를 교환한다. fully distributed.
Ring 형식으로 돌아가면서 서로 데이터 업데이트, 교환.
마스터 서버 없이, GPU들이 링(Ring) 형태로 고리를 만들어 옆 노드에게만 데이터를 전달한다. 전달받은 노드는 내 parameter와 받은 parameter를 aggregate하여, 다음 노드에게 넘겨주는 형식임.
장점: 트래픽이 한 곳으로 몰리지 않고 분산되므로 대규모 클러스터에서 훨씬 효율적입니다.
GPU간 세부 통신 패턴
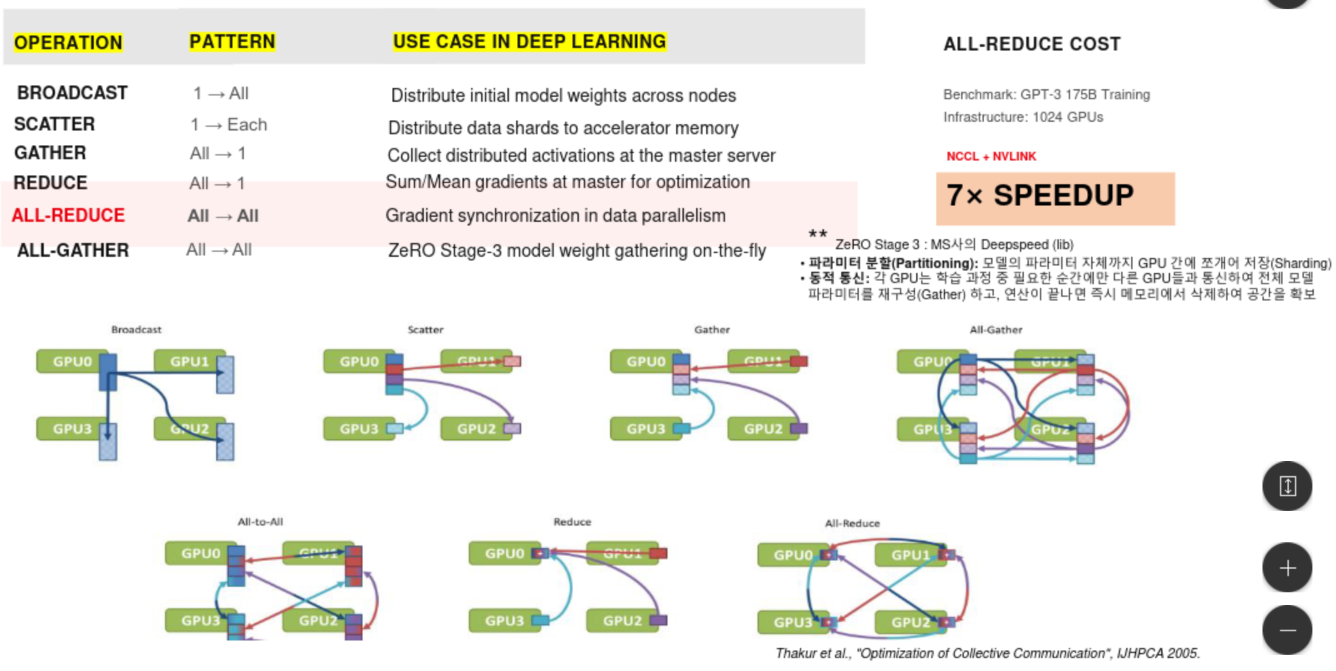
Broadcast - 전체한테 뿌리는것
Scatter - 한번에 쫙 뿌리는게 아니라 하나씩 보내주는것
실습2는 이 Scatter방법으로 수행하였음.
Gather - 거꾸로 서버에게 보내는것
All-Reduce: 서로에게 다 보내주는것. p2p가 되는것. 다 communication.
All-Gather - parameter 부분끼리 쪼개서 관리하는 부분을 나눠주는것.
전체가 왔다갔다하는것이 아니라 일부분씩 나눠서 관리. 트래픽이 동시에 한곳에 몰리지 않는다.
ZeRO Stage-3의 핵심. 메모리를 아끼기 위해 파라미터를 소분해서 들고 있던 GPU들이, 연산 직전에 서로가 가진 조각들을 교환하여 전체 파라미터를 동적으로 재구성할 때 사용한다.
데이터 교환 통신방식: 활용성과 Congestion?
100개 노드가 10분짜리 파일을 매분 10분마다 보내는것과 1시간짜리를 1시간마다 보내는것의 트래픽 차이를 생각해보자.
활용성에서는 10분짜리가 ㄷ좋아보인다? 하지만 congestion 관점에서는...10분짜리를 10분마다 보내는것이 congestion 관점에서 더 안좋다. traffic이 적게 계속 보내다보니까 congestion 발생, Decrease 계속 발생....오히려 안좋다..
파라미터를 조금씩, 통신이 자주 발생하는 All-Reduce/Gather(활용성은 좋지만, congestion 많이 발생)
파라미터를 한번에 많이, 통신 횟수가 적은 All-Reduce/Gather
로 생각할 수 있겠다.
All-Reduce에서의 해결
NCCL 라이브러리는 이를 해결하기 위해 작은 레이어들의 가중치를 하나의 커다란 버킷(Bucket, 예: 25MB)에 꾹꾹 모았다가 한 번에 크게 All-Reduce를 수행한다.
All-Gather에서의 해결
ZeRO의 실제 로직 (On-the-fly Chunking):
앞으로 연산할 레이어들의 파라미터를 미리 청크(Chunk, 덩어리) 단위로 예측하여, 적절한 타이밍에 덩어리째 All-Gather를 수행합니다.
통신 횟수를 최소화하여 네트워크가 최고 속도를 낼 수 있는 '길(Window Size)'을 확보해 주는 것입니다.
GPT3 175B trainining에서는 기존 PCIe 기반 네트워크로는 거대 데이터 학습이 어렵다. NCCL와 NVLINK 사용 -> 7x speedup
NVLINK는 GPU 사이에 새로 깐 '초고속 전용 링크(하드웨어)'이고, NCCL은 그 링크 위에서 동작하는 '프로토콜(소프트웨어)이다.
AI-Optimal speed in physical backbone

6080 GPUs: 메타는 거대 언어 모델(Llama 시리즈 등)을 학습시키기 위해 무려 6,080대의 최고 사양 GPU를 한 공간에 묶었습니다.
즉, GPU Clustering 으로 Distributed ML을 구현한거.
