profiling based auto load balancing 이후, vm여러개 놔두고 vanila FL와 Hierarchical FL에서의 communication overhead차이, devmem TCP 적용해서(devmem TCP 사용 불가, AF_XDP 사용해봤는데 성능 차이 모르겠음...) splice로 kernel - user memory pipeline으로 성능 개선 해 볼 것.
어느정도로 개선되었는지 확인할 것임.
devmem TCP 확인(udmabuf)
grep -E "CONFIG_NET_DEVMEM|CONFIG_UDMABUF" /boot/config-$(uname -r)

-
ethtool 설정
devmem TCP는 Mellanox 같은 수백만 원짜리 실제 하드웨어 랜카드가 패킷을 칼로 자르듯 쪼개주는 기능(Header-Split)을 탑재하고 있어야 작동한다. 지금 돈을 쓰지 않고 가상 머신(QEMU) 안에서 실험하고 있음.소프트웨어 에뮬레이션: 리눅스 커널에게 "야, 우리 랜카드가 가짜(VirtIO)라서 하드웨어 컷팅을 못 하니까, 대신 너가 소프트웨어로 패킷들을 포인터 리스트로 묶어서(rx-gro-list) 메모리 복사 없이 하이패스로 넘겨줘" 하고 속이는 작업이다. 이 설정을 안 하면 가상 환경에서 devmem TCP가 아예 동작하지 않고 전통적인 Copy 방식으로 튕겨버립니다. -
sysctl 버퍼 펌핑을 하는 이유
리눅스 가상 머신의 기본 네트워크 종이 장부(버퍼 크기)는 아주 작게(수십 KB 단위) 세팅되어 있습니다. 웹서핑이나 일반 텍스트 데이터를 주고받을 때는 문제가 없는데요.
패킷 유실(Drop) 방지: 텐서플로우 가중치 같은 거대 데이터가 들어오면, 작은 버퍼는 순식간에 꽉 차서 넘쳐흐릅니다. 버퍼가 넘치면 커널은 패킷을 버려버리고(Drop), 재전송 요철을 하느라 속도가 기어 다니게 됩니다.
해결책: 수신 버퍼 창고 자체를 64MB~128MB로 대폭 늘려놓아서, 대용량 AI 데이터가 한 번에 밀려 들어와도 대기실에서 안정적으로 udmabuf로 이동할 수 있도록 시간을 벌어주는 것입니다.virtio에서의 devmem TCP는 header-split을 host kernel이 수행하고, vring에 적힌대로 헤더와 udmabuf 메모리 공간에 따로 게스트에게 전달한다.
일단 ncdevmem이라는 테스트 서버 작동하도록 수정해야함.
그 이후 ftrace로 확인해볼것
qemu내 인터페이스는 rx큐별 패킷 처리 설정인 ntuple을 지원하지 않으므로 단일 queue를 갖는 인터페이스 2개를 만들어야함.
일단 외부 통신용 인터페이스랑 dma용 인터페이스.
그 이후 dma용 인터페이스 queue에 udmabuf 를 binding해야함.!!
ncdevmem.c에서 enp7s0 의 0번 큐에 udmabuf binding하는법 ???
devmem TCP 사용 불가.
아니 virtio 는 애초에 header-split이 불가능해서 devmem TCP 자체를 지원을 안하네..? mellanox 같은걸 에뮬레이션 할 수 있나 ?
불가능....하 devmem TCP는접자..
udmabuf 와 AF_XDP를 사용해서 성능향상??
udmabuf는 GPU의 VRAM에 direct 접근하기 위한 것. 근데 CPU연산에서는 그냥 일반 RAM에서 수행하므로 딱히 의미가 없어보임.
AF_XDP와 iouring 같이 사용하는 쪽으로?
DDIO 와 cache locality로 CPU연산에서도 성능 향상 가능?
<cpu mode='host-passthrough' check='none'/>??
추가적으로 AF_XDP는 코어수와 queue 수를 매칭시켜주면 성능이 잘 나온다.
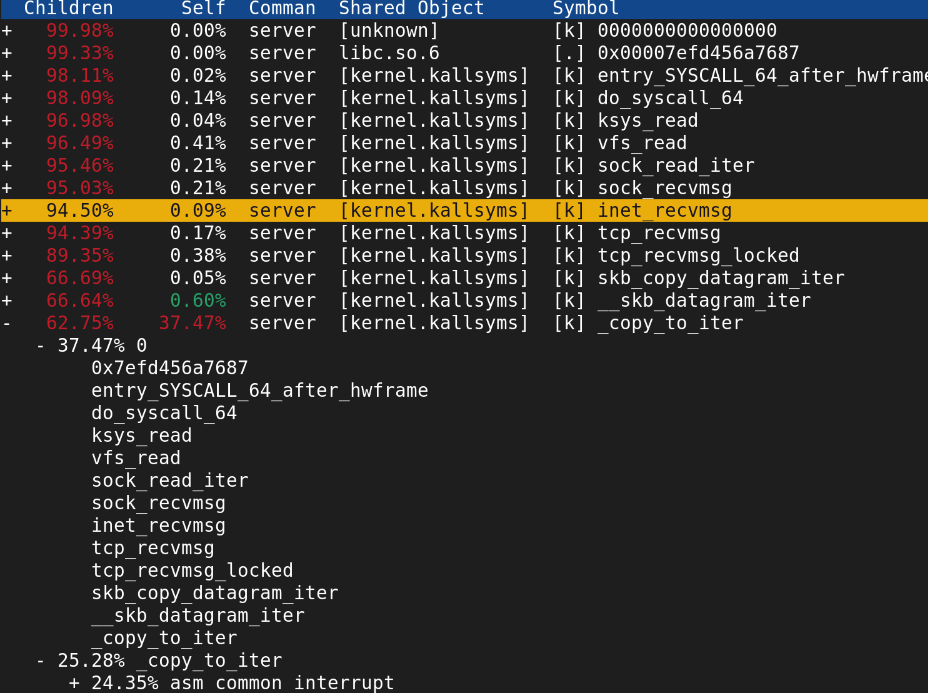
일단 바닐라 환경에서 200GB 전송했을때 어느 정도인지 알기 위해서 C소켓 코드 작성, perf로 누가 범인인지 알아보려고함.
copy가 무려 62.75%잡아먹는걸 볼 수 있음.
apt install -y libxdp-dev libbpf-dev iproute2 clang llvm xdp-tools -y
지금 우리의 방식 (Generic / SKB 레벨)
가상 머신(VM) 환경이라 하드웨어가 XDP를 모를 때 쓰는 방식입니다.
메모리 복사: 1회 (하드웨어 -> 커널 SKB 버퍼)
흐름: 1. 가상 랜카드(enp7s0)가 패킷을 받으면, 리눅스 커널이 일반 패킷용 표준 메모리 구조체인 sk_buff (SKB)를 생성하고 거기에 패킷을 1번 복사해 넣습니다.
2. 그 직후 우리 XDP 코드가 실행되어 패킷을 AF_XDP 소켓으로 토스합니다.
3. 커널은 이 SKB에 담긴 패킷 데이터를 유저 공간의 UMEM으로 넘겨줍니다.
[일반 TCP/IP 구조] 패킷 유입 ──> [커널 SKB 복사 (1회)] ──> [무거운 TCP/IP 드라이버 링, 넷필터, 라우팅 스택 통과]
│
▼ (유저가 read() 시스콜 호출)
[유저 공간 메모리로 또 복사 (2회: _copy_to_iter)] 💥 병목!
[XDP Generic 구조]
패킷 유입 ──> [커널 SKB 복사 (1회)] ──> [XDP 프로그램이 문턱에서 하이재킹] ──> [유저 UMEM으로 다이렉트 매핑]
(무거운 커널 TCP 스택 전체 패싱 ❌)
(유저 공간으로의 _copy_to_iter 복사 ❌)
XDP_PASS이후 XSK 코드로 하이재킹 구조?


공유 user memory을 사용한 Zero-Copy 구현
프로그램이 켜지자마자 유저 RAM에 공유 메모리(UMEM)를 할당해 커널과 반반씩 공유합니다. (매번 malloc 하는 비용 제거)
번호표 장부 교환 (Fill / Rx Ring):
유저와 커널은 무겁고 느린 시스템 콜(read()) 대신, "나 몇 번 방 비워놨다(Fill)", "거기 패킷 채워놨다(Rx)"라는 가벼운 번호표 장부만 주고받으며 소통합니다.
길목 문턱 낚채기 (하이재킹):
가상 머신(VM) 제약상 완벽한 하드웨어 제로카피(XDP_REDIRECT)는 못 쓰지만, XDP_PASS로 올라오는 패킷을 커널 네트워크 스택(TCP/IP)에 들어가기 직전 문턱에서 낚채어 가장 무거웠던 유저 공간 복사 오버헤드를 통째로 파괴합니다.
하드웨어에서 skb로 패킷 복사하는건 필수적인것이고, 그 다음에 skb에서 user memory로 데이터를 옮길때 memcpy가 발생하는것 아니냐 ??
XDP Native, Generic, Offload모드
우리는 XDPGeneric모드.
skb의 pointer swapping을 통해 이루어진다??
xdp쓰니까 어째 더 느린거 같냐
XDP 적용하면 RSO 비활성화되기 때문? 그건 아닌거같음...
xdp가 RSO 단계전에 하이재킹하기 때문에 RSO가 없어지는데 이건 아닌거같고..
UDP는 segmentation offload지원 없기 때문? 활성화했는데 똑같다.
udp 쓸때 client에서 보내자마자 바로 서버측에서 수신이 안되는 이유가 뭘까?
XDP zerocopy 사용 불가
아니...XDP도 하드웨어 제약이 있다..? XDP generic 모드만 지원하는 virtio-net은 performance benefit을 얻을 수 없다.
XDP native 사용 가능하긴 하나, XDP Zero copy는 사용안되는듯
패킷 알맹이를 게스트 VM 유저의 UMEM 공간에 찔러 넣어줄 때는 호스트-게스트 메모리 경계를 넘나드는 데이터 복사(XDP_COPY)가 커널 내부에서 필연적으로 발생하게 됩니다.
bind_flag에 XDP_ZEROCOPY 사용시,
아 뭐 도저히 뭐 어떻게 성능차이를 내야할지 답이 안나온다. 50GB 전송하는데 둘다 시간이 똑같이 걸리는데 하..
splice?
유저 - 커널 메모리 복사 오버헤드를 줄이기 위한 마지막 방법
splice하니까 27초로 줄어들긴한다.
FL에 적용 어떻게?
일단 학습은 dummy로 하고, parameter 교환에만 집중하기 위해서 코드를 수정하자.
전부 종합해서, parameter exchange communication overhead를 측정하는 코드를 포함한, 학습은 dummy로 하고, parameter 크기는 수십GB인 최종 코드
또 다음과 같이 user-kernel copy를 담당하는 copy_to_iter과 skb_copy_datagram_tier이 20% 정도..
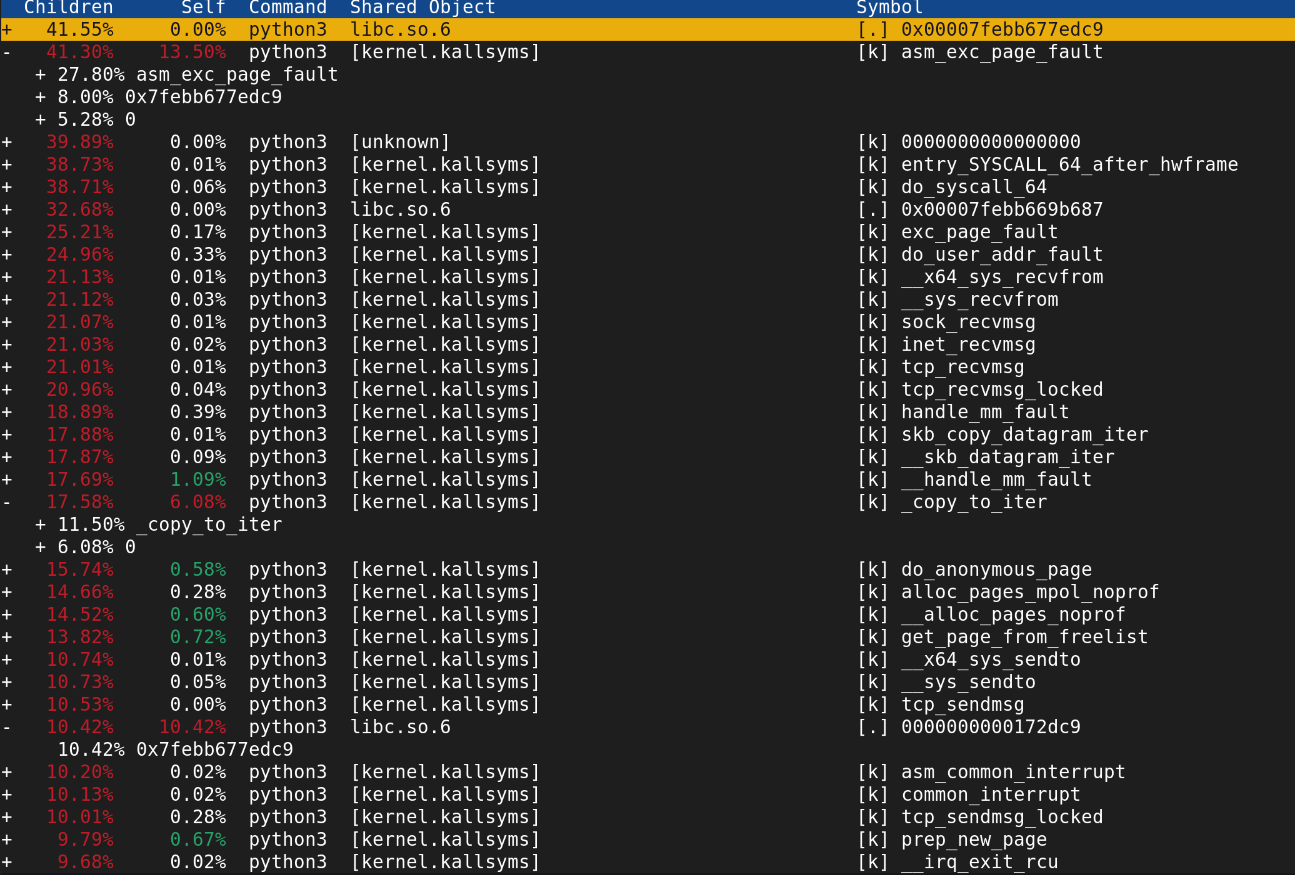
server측 12Gbps, client측 8Gbps정도 나옴.

user-kernel memory pipeline 구축하여 copy를 줄여보고자 함.
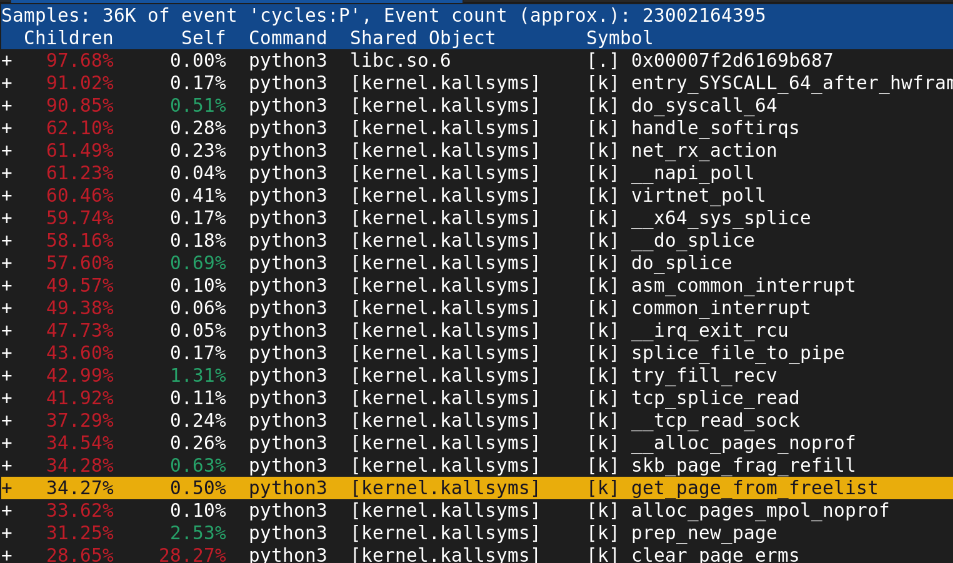
fast-C-splice read적용ㅇ하니까 45Gbps까지 상승...

#define _GNU_SOURCE
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <errno.h>
#include <poll.h>
/**
* Non-blocking 소켓 환경에서도 대용량 트래픽을 싱크 유실 없이
* 안정적으로 대기하며 제로카피 수신하는 고도화된 C-Splice 루프
*/
long long c_recv_splice(int sock_fd, long long total_bytes) {
int pipe_fds[2];
if (pipe(pipe_fds) < 0) {
return -errno;
}
int null_fd = open("/dev/null", O_WRONLY);
if (null_fd < 0) {
close(pipe_fds[0]);
close(pipe_fds[1]);
return -errno;
}
long long received = 0;
size_t chunk_size = 65536;
unsigned int flags = SPLICE_F_MOVE | SPLICE_F_MORE;
struct pollfd pfd_sock;
pfd_sock.fd = sock_fd;
pfd_sock.events = POLLIN;
while (received < total_bytes) {
long long to_recv = total_bytes - received;
if (to_recv > chunk_size) {
to_recv = chunk_size;
}
// 💡 [안전 장치] 소켓에 진짜로 패킷이 도달할 때까지 커널 레벨 블로킹 대기
int poll_ret = poll(&pfd_sock, 1, -1); // -1: 무한 대기 (Infinite)
if (poll_ret < 0) {
long long err = -errno;
goto cleanup;
}
// 포트를 통해 데이터 인입이 확인되었으므로 안심하고 splice 수행
long bytes_to_pipe = splice(sock_fd, NULL, pipe_fds[1], NULL, to_recv, flags);
if (bytes_to_pipe < 0) {
if (errno == EAGAIN || errno == EWOULDBLOCK) {
// 혹시 모를 일시적 빈 버퍼 신호는 무시하고 다시 poll 대기로 이동
continue;
}
long long err = -errno;
goto cleanup;
}
else if (bytes_to_pipe == 0) {
// 데이터가 도달했다고 해서 poll이 깨졌는데 0바이트가 읽힌 것은 '정상적인 세션 종료(EOF)'를 의미
break;
}
// Step B: Kernel Pipe -> /dev/null
long bytes_to_null = splice(pipe_fds[0], NULL, null_fd, NULL, bytes_to_pipe, flags);
if (bytes_to_null < 0) {
if (errno == EAGAIN || errno == EWOULDBLOCK) {
continue;
}
long long err = -errno;
goto cleanup;
}
received += bytes_to_null;
}
long long err = received;
cleanup:
close(pipe_fds[0]);
close(pipe_fds[1]);
close(null_fd);
return err;
}
이걸 FL 에 어떤식으로 적용할 수 있을지 고민해봐야함.
결국 splice -> user buffer 1copy는 필수적?
vmsplice() 로 NIC -> User buffer 바로 가능하도록? 할 수 있나?
XDP, devmem TCP는하드웨어 제약이 있고, vmsplice, splice는 뭐 깔끔하게 안되거나 기존이랑 다를게 없는거같고...
splice + disk pipeline??
header split을 하지 않으면 의미가 없다...skb를 통째로 쓰게 되는거니까 ? numpy의 offset 지정 ?
하 zero-copy는 너무 하드웨어적인 제약이 많다.
Incast-Problem으로 바꾸자.
2번으로 하자....실제 parameter 50GB를 넣는건 불가능하니까 python에서 dummy 50GB를 주는데, 바꾼 알고리즘으로 python socket, communication 라이브러리에 적용가능한지
TCP BBR, DCTCP
아니다 devmem TCP Emulation으로 갈까?
파이썬에서 /dev/shm/dummy_device라는 가상 장치 맵을 개설합니다.
소켓으로 50GB 스트림이 들어올 때, 커널 공간에서 [소켓 ➔ 커널 파이프 ➔ /dev/shm 장치] 경로로 splice를 쳐버립니다.
데이터가 일반 유저 RAM을 거치지 않고 가상 장치 메모리 공간으로 다이렉트 주입됩니다. (devmem TCP의 DMA 수신 단계 모사 완료)
가용 RAM(2GB)이 모자란 문제는 리눅스 가상 메모리 관리자가 이 /dev/shm 구획을 백그라운드에서 스왑 아웃(Swap-out)시키며 알아서 제어하므로 OOM이 나지 않습니다.
devmem TCP emulation
그 shm 가상 장치맵에 들어온 애를 간단히 average정도만 내게 해서 GPU VRAM이 있는것처럼 모사할 수 있나?
소켓 2개를 열어서 헤더 split?
① 제어 소켓 (Control Channel): 클라이언트가 이 소켓으로는 모델의 구조(shape, dtype) 같은 피클 메타데이터 헤더만 먼저 쏩니다. 서버는 이를 일반 노트북 RAM으로 아주 가볍게 읽어서 파싱합니다.
② 데이터 소켓 (Data Channel): 메타데이터 전송이 끝나면, 클라이언트는 이 전용 소켓에 피클 껍데기나 프로토콜 헤더를 단 1바이트도 섞지 않고, 오직 50GB짜리 순수 float32 바이너리 알맹이만 냅다 스트리밍으로 꽂아버립니다.
결과: 서버는 데이터 소켓에 대고 C-Splice를 당기기 때문에, /dev/shm/fake_gpu_devmem 장치 맵에는 처음부터 끝까지 100% 순수한 가중치 알맹이만 예쁘게 정렬되어 차곡차곡 쌓이게 됩니다.
읽기만 가능하면 average가 가능하다...
야 근데 생각해보니 FL aggregator에서 GPU VRAM이 그렇게 중요한가? RDMA나 devmem TCP가 필요한건 GPU Clustering 아냐?
Ring All-Reduce를....devmem TCP 모사법으로 성능 향상
그러면 학습은 빼고, 매우 큰 크기의 parameter 를 가져와서 내것과 average하는 식을 Ring All-Reduce 모사?
일단 splice같은 zero copy없이 VRAM역할을 하는 shm 을 공유하게 하는 코드를 줘봐. 50GB정도 parameter를 공유할거고, 실제 disk 50GB를 차지해서는 안되고, parameter 역할을 하는 random한 숫자를 포함한 50GB를 전송하는식이어야하고, Ring All-Reduce형태로, vm1 으로부터 전송 받은 parameter를 vm2의 parameter와 average내고, 그 결과를 vm3에게 전송하고 vm3가 그걸 다시 자신의 것과 average내서 최종 FedAvg를 완성할거야. 그리고 이렇게 splice가 없었을때의 communication overhead(~Gbps, 소모 시간, CPU overhead)를 측정하는 코드도 포함되어있어야함
일단 /dev/shm을 15기가로
dd if=/dev/zero of=/swapfile15g bs=1M count=16384
chmod 600 /swapfile15g
mkswap /swapfile15g
swapon /swapfile15g
mount -o remount,size=15G /dev/shm
질문: 교수님, 이번 연합학습 Aggregation 통신 병목 과제 관련해서 현실적인 인프라 제약 때문에 구현 방향을 조금 영리하게 틀어보려고 합니다.
요즘 구글에서 쓰는 devmem TCP나 AF_XDP 같은 기술들이 핫하긴 한데, 이게 특정 최신 랜카드(NIC) 드라이버 하드웨어가 무조건 지원되어야만 해서 저희 일반 장비나 VM 환경에서는 아예 구동조차 불가능하더라고요.
그래서 하드웨어 제약 없이 devmem TCP 메커니즘을 검증하기 위해, 리눅스 표준 시스템 콜인 splice()와 공유메모리(/dev/shm)를 조합해서 '소프트웨어 정의형 제로카피 엔진'을 직접 구현해 보려고 합니다.
텐서플로우 학습 노이즈를 배제하기 위해, Ring All-Reduce 구조(VM1➔VM2➔VM3)로 15GB 대용량 파라미터를 서로 평균 내고 토스하는 더미 패킷 환경을 구축할 예정입니다.
이렇게 하면 비싼 하드웨어 장비 없이도 일반 복사 방식 대비 제로카피가 CPU 부하를 얼마나 낮추고 대역폭을 유지하는지 명확하게 정량 비교할 수 있을 것 같은데, 이 방향으로 실험 진행해도 괜찮을까요?"
그니까 xdp를 쓰면 기존 socket 방식을 사용하지 못한다?
user - kernel memory copy를 없애기 위해서 splice를 쓰는거지 tcp stack 을 우회하기 위해서 쓰는것이 아니다?
FL 를 사용?
FL을 위한 Python AI Framework.
실제 parameter 송/수신은 splice + /dev/shm 로 system programming(data plane)
control plane은 Flower에게 맡기는 식으로
일단 gRPC를 이용하는 방법에서 1GB를 사용할때,
====================================================================
[gRPC 프로토콜 데이터 평면 전체 실측 결과] - Round 1
====================================================================
[총 소요 시간 (Latency)] : 42718.62 ms (42.7186 초)
--------------------------------------------------------------------
[실측 유효 대역폭 (Goodput)] : 603,245,273 bps (603.25 Mbps)
====================================================================
가 나옴.
여기다가 splice 적용...
splice동작방식이 어떻게 devmem TCP를 모사해서 성능을 올렸는지?
발표 내용: 기존의 문제점 kernel - user memory copy 발생
-> TCP 스택을 완전 우회하게 하는 eBPF를 사용하는 XDP Redirect가 아닌 TCP 를 사용하면서 memory로 데이터를 zero-copy를 하게 만드는 기술
리눅스 커널에서의 devmem TCP .... NIC 하드웨어적으로 Header-Split 기술이 있어야한다. Header에 대해서만 TCP 스택 처리, Split된 payload는 GPU Memory 에 DMA. (dmabuf와 udmabuf 설명...)
Google Cloud Platform에서 accelerated Network 기능을 사용하면 gvnic 에서 tcp-header-split 이 사용 가능하다고 나와있지만, 비용이 굉장히 많이 듦. 무료 토큰 사용 가능한 Azure에서 zero-copy를 구현하도록 하는 방식으로 변경.
근데 내가 하고 있는 환경에서는 header-split이 없음. 따라서 우리가 하려고 하는것은 기존 Flower의 gRPC 통신 방식을 splice() 와 /dev/shm (tmpfs 설명) 을 통해서 devmem TCP을 모사하는 zero-copy communication으로 CPU overhead를 줄여보고자 함.
실제는 ~~이랬고 ~~정도 향상되었다. 하지만 하드웨어적 한계로 인해 실제 parameter를 송/수신하는 환경에서는 테스트해보지 못했다.
- io_uring 의 추가 가능성, splice() 의 한계. 등등
Hugging Face로 gemma2 parameter 사용?
5GB짜리 가져와서 서로 송/수신하는 communication overhead를 측정해보자.
이때, Layer별로 나누어서 전송해서 out of memory를 방지하고, swapfile 설정함.
잘되긴한다.
목표:
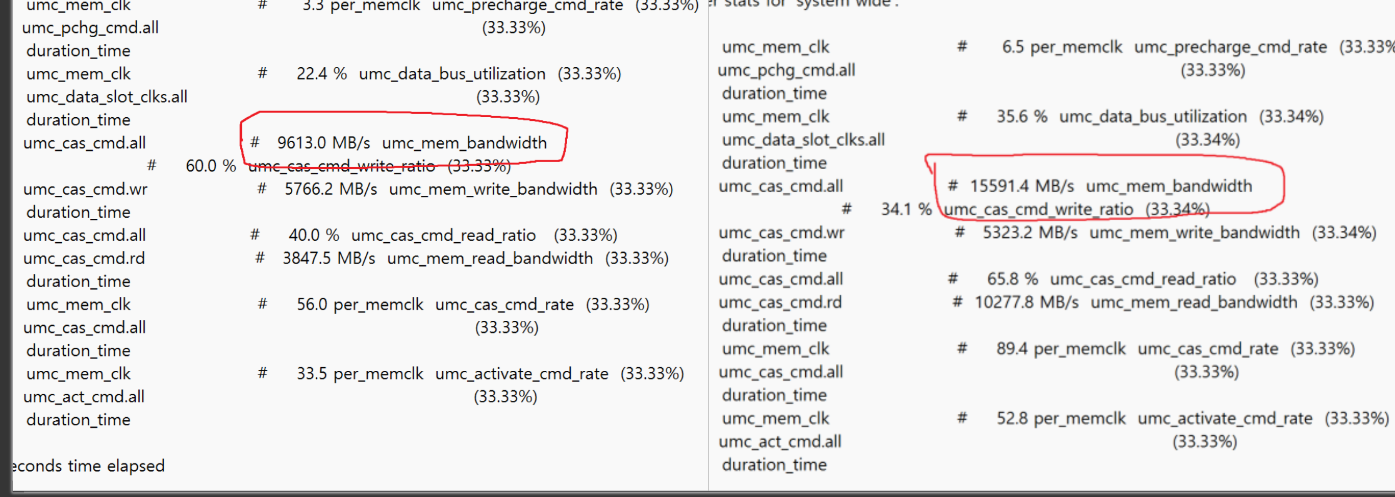
이런느낌으로 network/memory bandwidth 측정하고,
fast-slice recv C library shared object 적용해서 어떤 차이가 있는지 확인할것
zero-copy를 확인하려면 어떤걸 측정해야하지??
perf와 코드 변경으로
splice() 통신 테스트
잘된다.
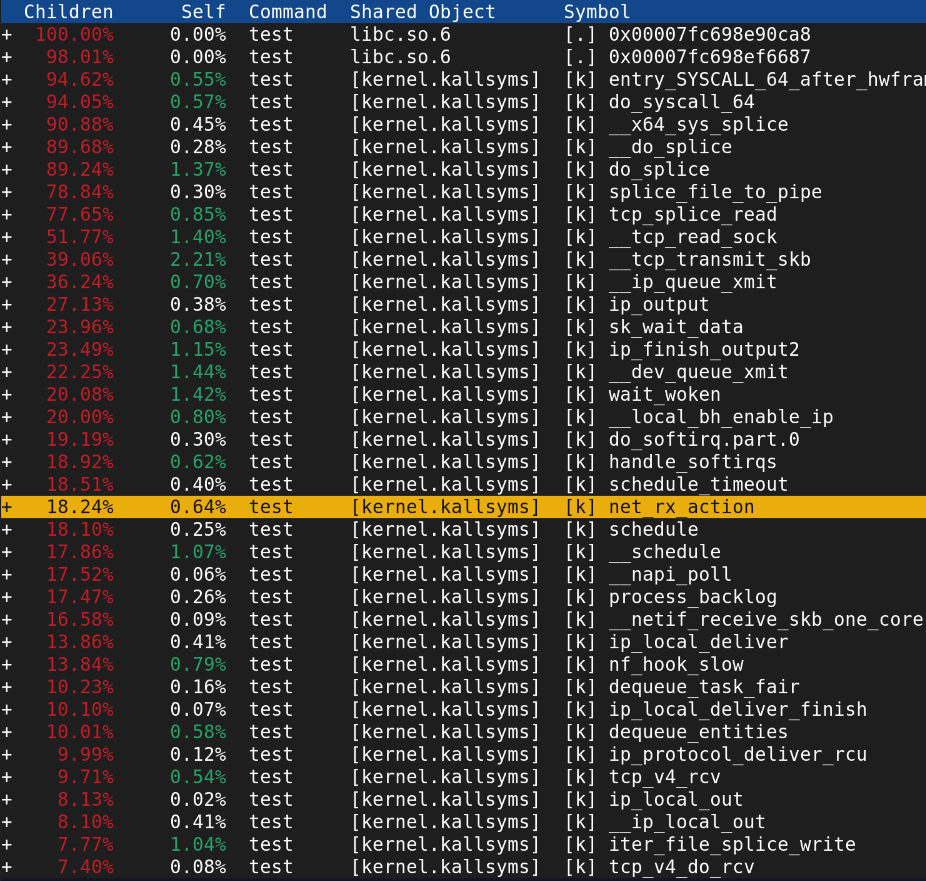

socket방식

splice()를 사용할때 생각해야하는것들.
보안,
기존 sock.recvall()은 kernel payload를 유저로 복사해와서 Layer payload를 가지고 있을 수 있었는데
-> 데이터가 유저 스페이스로 빠져나갔기 때문에, 커널은 자신이 관리하는 소켓 수신 큐(커널 메모리)를 즉시 비우고 다음 패킷을 계속 받을 수 있다.
splice()는 kernel에서 할당한 놈의 pointer를 넘겨주는거잖아. 그러면 kernel memory에 그 Layer 가 다 차지 않게 해야하지 않나?
지금 recvallI()을 사용할때는 일정 크기마다 kernel -> user 복사하면서 kernel memory 를 해제하고, incoming_size 가 다 채워지면 종료하는 거 아니냐? 근데 splice는 Layer를 전부받을때까지 mmap에 의해 kernel memory를 해제할 수 없잖아.
splice() zero copy 동작방식
splice는 간단하게, file 의 struct address space(offset:PFN 매핑 cache)의 offset에 패킷이 위치한 Physical Frame Number를 할당해서 zero-copy를 구현하는것.
따라서, copy없이도 memfd 의 offset에 접근시, 데이터의 offset에 접근할 수 있다.
splice() 한번당 pipeline 크기만큼 소켓큐, kernel memory 해제.
ex) 64KB 의 pipeline을 가진다면, splice() 한번당 64KB 크기의 페이지 주소가 복사되므로, 그만큼 소켓큐와 kernel memory를 해제한다. -> 이는 1차 splice() 실행시 tcp_splice_read에서 tcp_eat_skb()로 이루어진다.
리눅스의 file에는 address space structure가 있다.
page cache로,
offset : Physical Frame Numer 형태로 있는데,
splice()시 offset에 맞는 곳에 physical page address를 복사한다고 보면 된다.
splice() 에 전달되는 FD의 종류(소켓 or block device)에 따라서 다르게 하위 호출을 호출한다. 아래는 Socket -> pipeline시 발생하는, PFN 전달 함수.
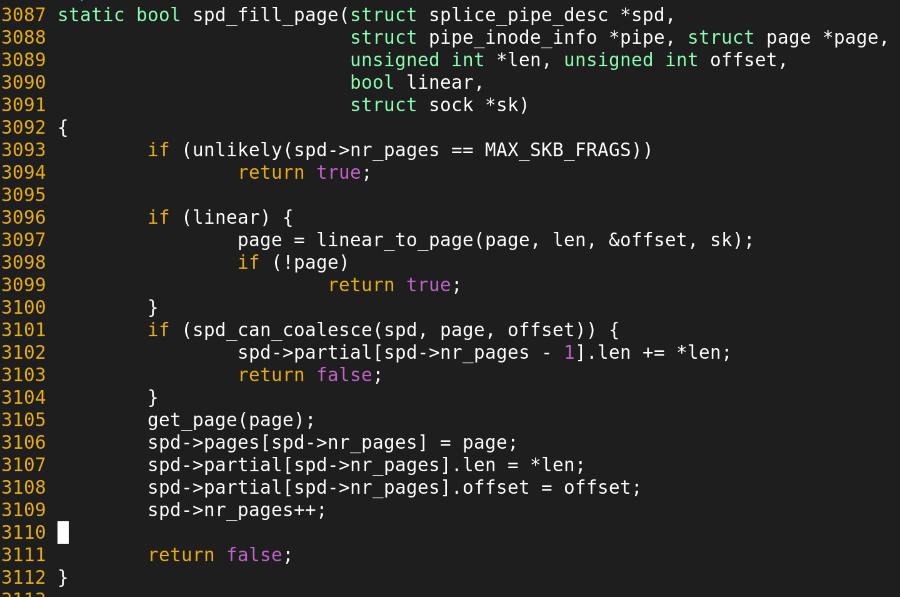
socket의 file operation. splice_read시 sock_splice_read를 실행
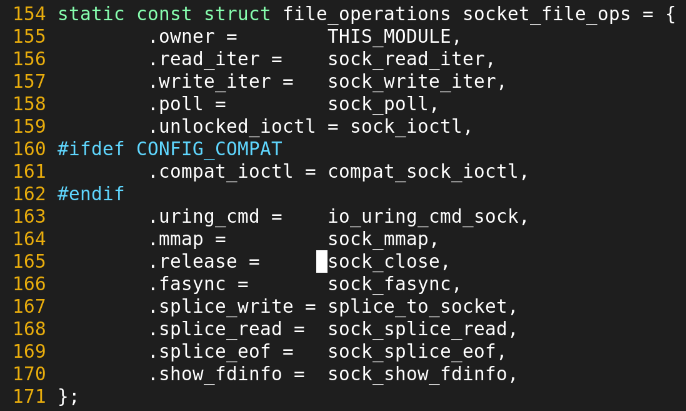
두번째 splice시 page cache에 어떻게 PFN이 할당되는가?
write시,

generic_perform_write()함수 실행됨
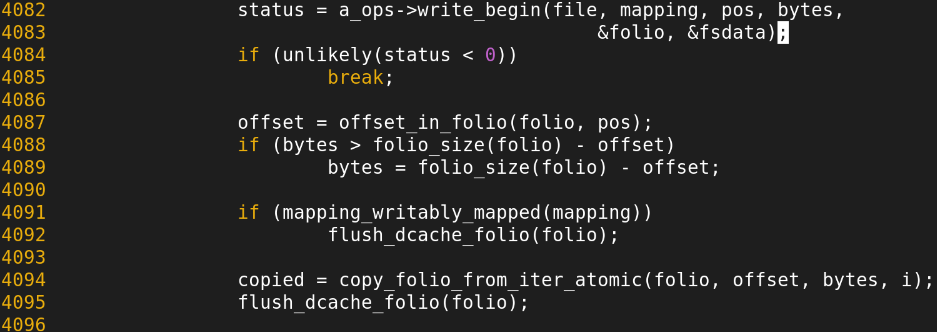
해당하는 offset에 대한 자리 확보
offset에 PFN copy 수행
copy_folio는 다음을 실행시킴.
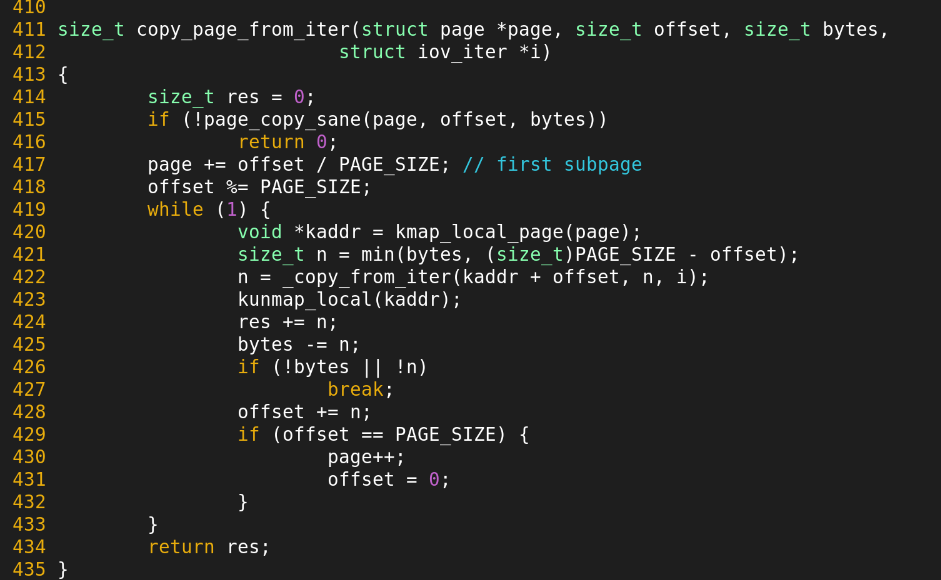
-> copy_iter에서....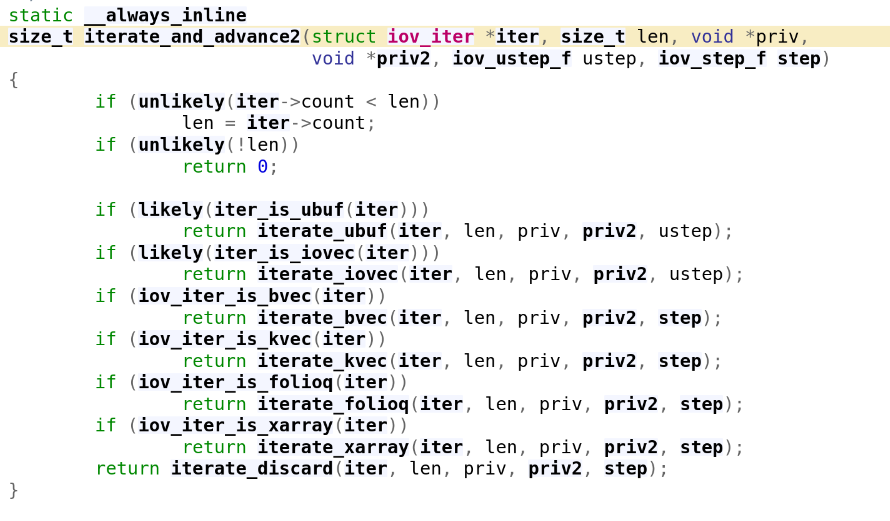
bvec이므로 iterate_bvec실행
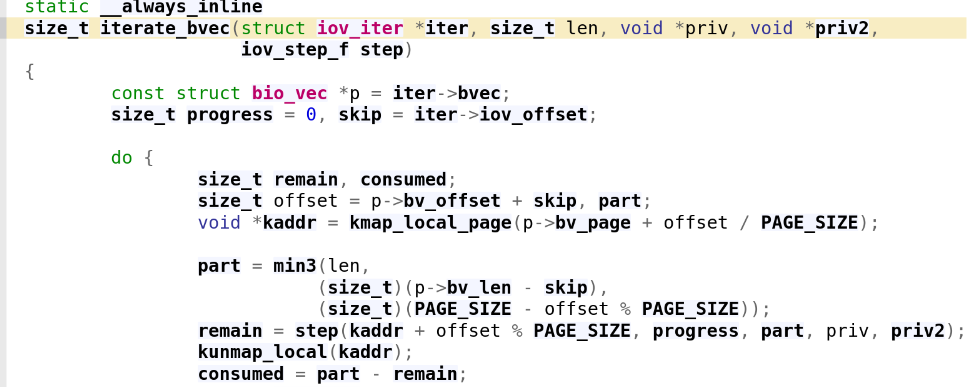
step() 함수는 memcpy함수임...그러면 결국 copy가 발생하는거라고??
과거에는 진짜 PFN 변경만 했지만, 보안 이슈때문에 바뀌었다?
Dirty Pipe라는 굉장히 유명한 보안 이슈 발생..!
이상적인 zero-copy는 불가능하다.
recvall과 동일하게 1 copy는 존재한다.
io_uring을 사용하면 끌어올릴 수 있다.?
IORING_OP_RECV_ZC??
iouring + changing memory allocation option + changing congestion control to BBR 시도!!
IOURING도 결국 header-split필요...
그냥 kernel source code 수정해서 PFN 스왑하는쪽으로 만들까??
에바인거같은데 이거는
일단 splice() 넣어보자!
일단 recv_into_pool만 C로 splice()없이 구현했을때,

Cur는 400~800정도뜸.
이걸 splice()로 바꿔서 한번 테스트해보자.

pipeline maximum 16MB로 증가