토폴로지 구조
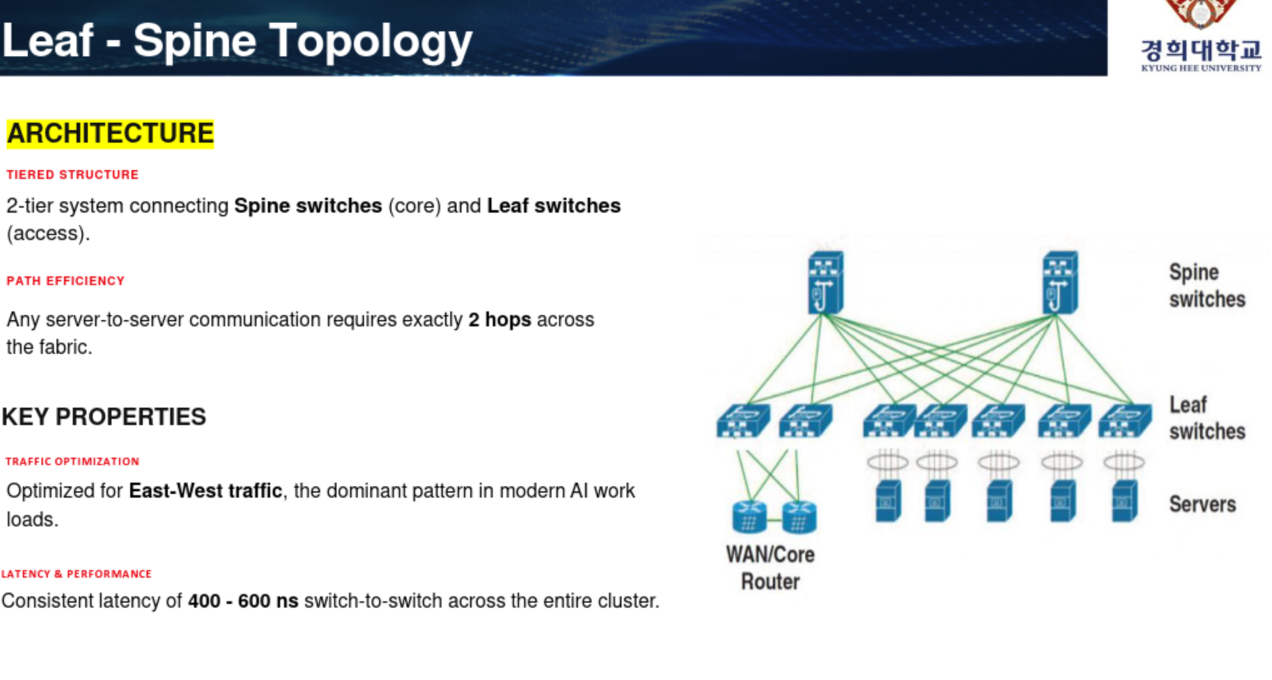
기본적으로 이러한 Spine-Leaf, 2-tier system 구조를 사용한다.
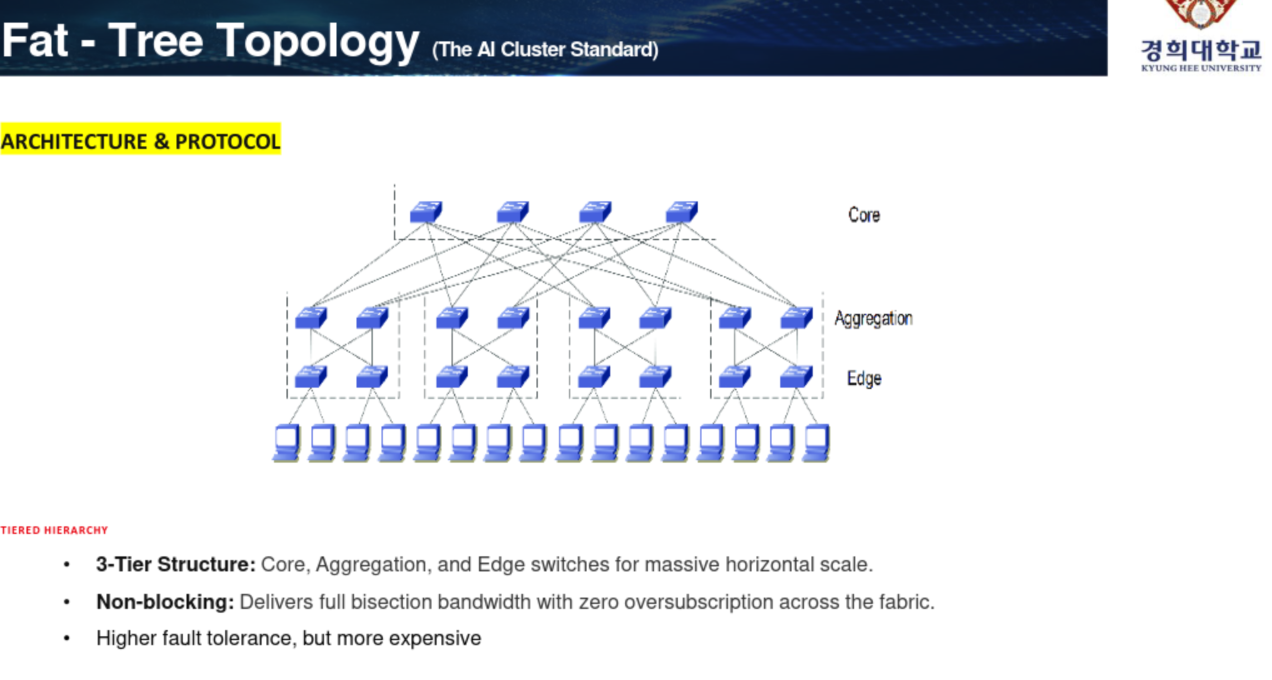
Fat-Tree 구조는 3-tier structure를 이용한다.
Core-Aggreagtion-Edge 구조를 갖는다.
일반적으로 발생하는 병목을 해결하기 위해서 aggregation단을 추가한 것. 하지만 추가되어야하는 장비와 케이블수가 상대적으로 많다.
Intra/Inter-Node

Server 내부의 GPU Clustering을 위한 Intra-node 기술들
NVLink를 지원하는 GPU와 그 GPU들을 연결하는 NVSwitch Fabric.
Server 간의 GPU Clustering을 위한 Inter-node 기술들.
Infiniband 와 ethernet을 통한 RDMA를 위한 RoCEv2
RDMA: Zero-Copy로 GPU Memory에 직접 접근하는 기술.
Network Bottlenecks
1. Incast Problem.
All-Reduceaggreagtion시 수많은 서버가 하나의 서버로 동시에 데이터를 송신할때, 발생하는 성능 저하를 Incast problem이라고 한다.
Collective communication: 전체적으로 collective하게 데이터를 수집한다는 말이다.

모든 노드가 어떤 노드로 데이터를 전송 후 모으고(Reduce & Aggregate) 그 최종 결과물을 다시 모든 노드에게 똑같이 복사해서 배포(Broadcast)하는, All-Reduce 통신 패턴에서는 이 Incast 문제가 많이 발생한다.
ex) 100개의 노드가 400Gbps 속도로 parameter를 전송한다면, 5TB/s peak가 되고, 12 us만에 Switch buffer가 다 차게 된다. 그 후 packet loss 발생.
-> packet loss -> Retranmission -> Bandwidth 효율성 저하 악순환 발생한다.
실제로 시간당 40분이 Time Loss인 경우도 있었음.
해결:
PFC: Priority Flow Control, 스위치 버퍼가 터지기 직전에 데이터 송신을 멈출 수 있게 하는것.
DCQCN: 무손실 혼잡 제어 기술
RDMA: Remote DMA, retransmission overhead 최적화
이 3가지를 함께 사용하면서 Incast Problem을 해결한다.
2,3. Straggler Effect, Bandwidth Bottleneck

성능이 안좋은 GPU003이 전체 시스템 stall을 위발한다.
Transformer 가 스텝별로 요구하는 데이터는 500GB/s인데, PCIe5를 사용하면 최대 128GB/s까지 밖에 이용할 수 없다.
따라서 NVLink를 이용해서 서버내에 위치한 GPU간 연결될 수 있도록 한다.
ex) 80GB짜리 H100 GPU 8대를 NVLink로 묶으면, 소프트웨어(PyTorch 등) 입장에서는 마치 640GB짜리 거대한 초고성능 단일 GPU 메모리가 하나 있는 것처럼 인식하여 초거대 LLM(GPT 시리즈 등) 모델을 통째로 올려 학습시킬 수 있다.
4. CPU Overhead

시스템 레벨에서 네트워크 패킷을 처리하는데 CPU 오버헤드가 많이 발생한다. NIC Interrupt -> Kernel Copy -> Network stack -> Application...패킷 처리를 위한 부하도 굉장히 많다.
CPU를 많이 쓰면 NIC도 많이 쓰게 되는.. 비례적인 관계인가?
그렇지 않다.
웹같이 단순 I/O가 많은 트래픽은 CPU를 비교적으로 적게 쓰지만, AI 학습을 위한 트래픽은 Payload가 굉장히 많고, 크기 때문에 Copy하고, 그 패킷을 가공 처리하는데에만 굉장히 많은 CPU 연산을 차지한다. 이렇게 응용에 따라서 CPU 부하가 달라지게 된다.
NIC RAM -> skb -> User memory 영역 복사 발생 2~3번의 Copy 발생.
Solutions

devmem TCP: NIC RAM에서 skb로 복사할 때, 커널 공간이 아니라 드라이버 단에서 곧바로 GPU VRAM(dmabuf 라는 GPU-커널 직통 경로)으로 목적지를 지정해 버립니다. 이로 인해 사용자 공간으로의 거대한 메모리 복사 비용이 0(Zero-copy)이 됩니다.
RDMA: 아예 skb 과정과 프로토콜 인터럽트 과정 전체를 스킵합니다. 랜카드 칩셋이 하드웨어적으로 패킷 헤더를 처리하는등, 가공 후 CPU 도움 없이 GPU VRAM에 최종 결과물만 던져준다.
이 RDMA 드라이버의 핵심은 Zero-copy, GPU Memory까지 데이터가 전달되는데에 CPU 개입이 전혀 없다는것이다.
Zero-Copy -> memory 사용 감소 -> Power 사용 감소 -> 발열 감소 -> 비용 감소

NCCL: Collective Communications 을 위한 Software Library.
NVLink의 프로토콜을 담당하는 Library.
개발자가 학습을 위한 코드를 작성할때, GPU0의 데이터는 NVLink 2번을 통해서 ~~로 가라 는 것을 직접 명시하는것은 비효율적이다.
따라서, NCCL은 GPU간의 연결(PCIe, NVLink, RoCE)와 상태와 같은 하드웨어적인 토폴로지를 자동으로 감지하여 최적화된 알고리즘을 제공한다. Hardware-Topology awared algorithm.
즉, 전체 Link path를 관리하는 orchestator이다.

SmartNIC? NIC안에서 DPU(Data Processing Unit)을 사용하여 가상 path 수립, 데이터 여기서 저기로 보낼 수 있게 하고, flow 별로, logic에 따라 설정할 수 있다. traffic을 가상화하여 처리할 수 있게 끔 한다. DPDK같은걸 쓴다.
DPU는 호스트 컴퓨터(서버) 내부의 눈에 보이지 않는 수많은 가상 머신(VM)이나 컨테이너(Docker)들에게 각각 독립된 가상 랜카드(SR-IOV / VF, Virtual Function)를 쪼개서 가상 통로를 만들어 준다.
로직에 따른 통신 통제 (Flow-based Routing): * DPU 내부의 eSwitch는 OVS(Open vSwitch) 같은 가상화 소프트웨어와 연동된다.
이를 통해 "A 가상 머신에서 나가는 80번 포트 트래픽(Flow)은 암호화 가속기 로직을 거쳐서 외부로 보내고, B 컨테이너의 트래픽은 패킷을 다 거르고 방화벽 로직을 태운 뒤 저기로 보내라" 같은 지능적인 제어 프로그래밍(소프트웨어 정의 네트워크, SDN)을 랜카드 안에서 완벽하게 독립적으로 수행합니다.
DPDK를 통해 네트워크 스택을 완전히 뛰어넘을 수 있게 한다.
즉, CPU가 해야하는 경로 설정이나, 헤더 처리같은것을 NIC의 DPU에 offload하는것이다.
In-computing Aggreagtion: switch가 aggreagtion하는것. DPU같은것이 할 수도 있음.
InfiniBand: 무손실을 지향하는, 하드웨어적으로 최대한 많은것을 처리하도록 하는 네트워크. 지연 시간(Latency)을 0에 가깝게 줄이고 대역폭을 극한으로 끌어올리겠다는 목적하에 만들어진것. 개비쌈
계층적 Federated Learning에서도 성능이 잘 나오도록 해야한다.
계층적 FL와 바닐라 FL의 Communication Overhead는 어떻게 다른가? 혹은 어떤 식으로, 어떤 노드에서, 어떤 솔루션을 잘 활용하면 게층적 FL에서 가장 좋은 효율을 뽑아낼 수 있을 것인가? 가 관건이다.
단순 학습뿐만 아니라 100ms이내에 응답을 내야하는 Real-Time AI같은것들도 중요하다.
