들어가기 전,
주니어 FE 개발자로 "어떻게 브라우저는 동작을 할까?" 고민을 하다가 공부하면서 Posting을 하게 되었습니다.
네이버 D2에서 잘 설명이 되어있지만 번역이 이상한 부분과 오류를 고치고 필요한 요소는 추가로 더했습니다.
PS) chrome의 경우에는 이전에 Webkit(ver. 28전)을 사용했으나 지금은 blink를 사용하고 있는데 제 생각엔 webkit부터 이해하는 것이 좋을 것 같습니다 :)
1. 브라우저의 주요 구성 요소
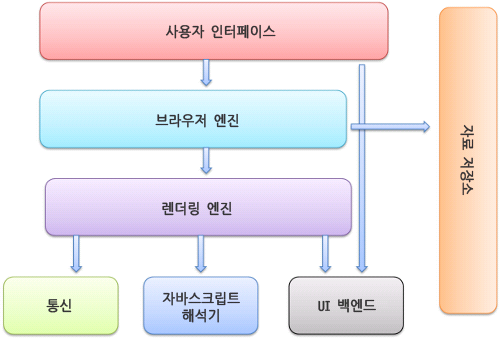
1. 사용자 인터페이스 - 주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등 요청한 페이지를 보여주는 창을 제외한 나머지 모든 부분
2. 브라우저 엔진 - 사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어
3. 렌더링 엔진 - 요청한 콘텐츠를 표시. ex) HTML을 요청하면 HTML과 CSS를 파싱하여 화면에 표시
4. 통신 - HTTP 요청과 같은 네트워크 호출에 사용. 이것은 플랫폼 독립적인 인터페이스고 각 플랫폼 하부에서 실행됨.
5. UI 백엔드 - 콤보 박스와 창 같은 기본적인 장치를 그림. 플랫폼에서 명시하지 않는 일반적인 인터페이스로서, OS 사용자 인터페이스 체계를 사용
6. 자바스크립트 해석기 - 자바스크립트 코드를 해석하고 실행.
7. 자료 저장소 - 자료를 저장하는 계층. 쿠키를 저장하는 것과 같이 모든 종류의 자원을 하드 디스크에 저장할 필요가 있다. HTML5 명세에서는 브라우저가 지원하는 'WEB DATABASE'가 정의되어 있다.
크롬은 대부분의 브라우저와 달리 각 탭마다 별도의 렌더링 엔진 인스턴스를 유지하는 것이 주목할만하다. 각 탭은 독립된 프로세스로 처리된다.
일하다가 한쪽 탭에서 작업하다가 죽은 적이 있는데 다른 탭에 렌더링 엔진이 함께 죽어서 보이지 않던 문제를 최근에 발견해서 다음포스팅에 알아보겠습니다.
2. 렌더링 엔진
렌더링 엔진은 요청 받은 내용을 브라우저 화면에 표시하는 일이다.
HTML 및 XML 문서와 이미지를 표시할 수 있다. 물론 플러그인이나 브라우저 확장 기능을 이용해 PDF와 같은 다른 유형도 표시할 수 있다.
- 동작 과정
렌더링 엔진은 통신으로부터 요청한 문서의 내용을 얻는 것으로 시작하는데 문서의 내용은 보통 8KB 단위로 전송됨.

렌더링 엔진은 HTML 문서를 파싱하고 "콘텐츠 트리" 내부에서 DOM 노드로 변환한다. 그 다음 외부 CSS 파일과 함께 포함된 스타일 요소도 파싱한다. 스타일 정보와 HTML 표시 규칙은 "렌더 트리" 라고 부르는 또 다른 트리를 생성한다.
렌더 트리는 색상 또는 면적과 같은 시각적 속성이 있는 사각형을 포함하고 있는데 정해진 순서대로 화면에 표시된다.
렌더 트리 생성이 끝나면 배치가 시작되는데 이것은 각 노드가 화면의 정확한 위치에 표시되는 것을 의미한다. 다음은 UI 백엔드에서 렌더 트리의 각 노드를 가로지르며 형상을 만들어 내는 그리기 과정이다.
일련의 과정들이 점진적으로 진행된다는 것을 아는 것이 중요하다. 렌더링 엔진은 좀 더 나은 사용자 경험을 위해 가능하면 빠르게 내용을 표시하는데 모든 HTML을 파싱할 때까지 기다리지 않고 배치와 그리기 과정을 시작한다. 네트워크로부터 나머지 내용이 전송되기를 기다리는 동시에 받은 내용의 일부를 먼저 화면에 표시하는 것이다.
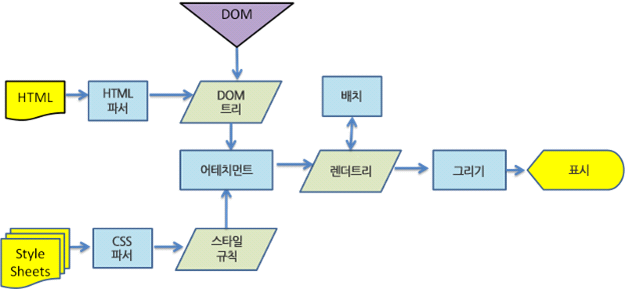
- 웹킷 동작과정
- 게코 동작과정
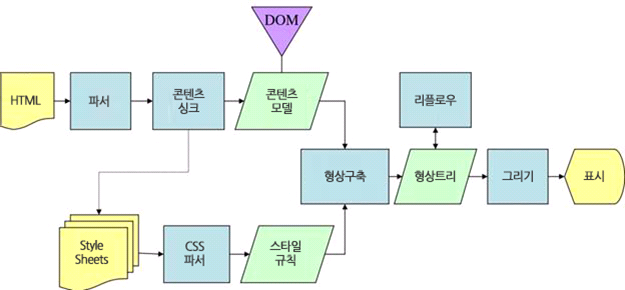
웹킷과 게코가 용어를 약간 다르게 사용하고 있지만 동작 과정은 기본적으로 동일하다는 것을 알 수 있다.
게코는 시각적으로 처리되는 렌더 트리를 "형상 트리" 라고 부르고 각 요소를 형상(frame)으로 부르는데 웹킷은 "렌더 객체(Render Object)"로 구성되어 있는 "렌더 트리(Render Tree)"라는 용어를 사용한다. 웹킷은 요소를 배치하는데 "배치(layout)" 라는 용어를 사용하지만 게코는 "리플로우(reflow)"라고 부른다. "어태치먼트(attachment)"는 웹킷이 렌더 트리를 생성하기 위해 DOM 노드와 시각 정보를 연결하는 과정이다. 게코는 HTML과 DOM 트리 사이에 "콘텐츠 싱크(content sink)"라고 부르는 과정을 두는데 이는 DOM 요소를 생성하는 공정으로 웹킷과 비교하여 의미있는 차이점은 없는 것으로 보인다.
저 같은 경우에 개발을 하다 "재배치"의 의미로 reflow로 자주 들었습니다. 사람들마다 용어를 다르게 부를 수는 있지만 어떤 의미인지만 알면 소통은 할 수 있을 것 같네요.
3. 파싱과 DOM 트리 구축
3-1. 파싱 일반
파싱은 렌더링 엔진에서 매우 중요한 과정이기 때문에 더 자세히 다룰 필요가 있다. 파싱에 대해서 간단한 소개로 시작한다.
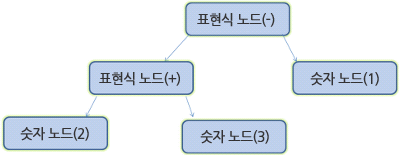
문서 파싱은 브라우저가 코드를 이해하고 사용할 수 있는 구조로 변환하는 것을 의미한다. 파싱 결과는 보통 문서 구조를 나타내는 노드 트리인데 파싱 트리(parse tree) 또는 문법 트리(syntax tree)라고 부른다.
예를 들면 2+3-1 과 같은 표현식은 다음과 같은 트리가 된다.
3-2. 문법
파싱은 문서에 작성된 언어 또는 형식의 규칙을 따르는데 파싱할 수 있는 모든 형식은 정해진 용어와 구문 규칙에 따라야 한다. 이것을 문맥 자유 문법이라 한다. 인간의 언어는 이런 모습과는 다르기 때문에 기계적으로 파싱이 불가능 하다.
Programming Language마다 문법이 다른 것 처럼 Natural Language 역시 여러가지의 모습을 가지고 있고 이해하는 데 방법이 달라 기계적으로 파싱이 불가능 하다고 이해하시는게 좋겠습니다.
3-3. 파서-어휘 분석기 조합
파싱은 어휘 분석과 구문 분석 두가지로 구분할 수 있다.
어휘분석은 자료를 토큰(Token)으로 분해하는 과정이다. 토큰은 유효하게 구성된 단위의 집합체로 용어집이라고도 할 수 있는데 인간의 언어로 말하자면 사전에 등장하는 모든 단어에 해당된다.
구문 분석은 언어의 구문 규칙을 적용하는 과정이다.
파서는 보통 두 가지 일을 하는데 자료를 유효한 토큰으로 분해하는 어휘 분석기(토큰 변환기 라고도 부름)가 있고 언어 구문 규칙에 따라 문서 구조를 분석함으로써 파싱 트리를 생성하는 파서가 있다. 어휘 분석기는 공백과 줄 바꿈 같은 의미없는 문자를 제거한다.
아래에서 중요하게 다루니 이 부분을 항상 생각하고 내려갑시다.
- 파싱트리를 문서 소스로부터 만드는 과정
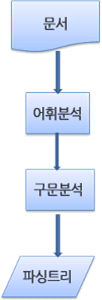
파싱 과정은 반복된다. 파서는 보통 어휘 분석기로부터 새 토큰을 받아서 구문 규칙과 일치하는지 확인한다. 규칙에 맞으면 토큰에 해당하는 노드가 파싱 트리에 추가되고 파서는 또 다른 토큰을 요청한다.
규칙에 맞지 않으면 파서는 토큰을 내부적으로 저장하고 토큰과 일치하는 규칙이 발견될 때까지 요청한다. 맞는 규칙이 없는 경우 예외로 처리하는데 이것은 문서가 유효하지 않고 구문 오류를 포함하고 있다는 의미다.
3-4. 변환
파서 트리는 최종 결과물이 아니다. 파싱은 보통 문서를 다른 양식으로 변환하는데 컴파일이 하나의 예가 된다. 소스 코드를 기계 코드로 만드는 컴파일러는 파싱 트리 생성 후 이를 기계 코드 문서로 변환한다.

3-5. 파서의 종류
파서는 기본적으로 하향식 파서와 상향식 파서가 있다.
하향식 : 구문의 상위 구조로부터 일치하는 부분을 찾기 시작한다.
상향식 : 낮은 수준에서 점차 높은 수준으로 찾는다.
3-6. 파서 자동 생성
파서를 생성해 줄 수 있는 도구를 파서 생성기라고 한다. 언어에 어휘나 구문 규칙 같은 문법을 부여하면 동작하는 파서를 만들어 준다. 파서를 생성하는 것은 파싱에 대한 깊은 이해를 필요로 하고 수동으로 파서를 최적화하여 생성하는 것은 쉬운 일이 아니기 때문에 파서 생성기는 매우 유용하다.
웹킷은 잘 알려진 두 개의 파서 생성기를 사용한다. 어휘 생성을 위한 플렉스(Flex)와 파서 생성을 위한 바이슨(Bison)이다. 플렉스는 토큰의 정규 표현식 정의를 포함하는 파일을 입력 받고 바이슨은 BNF 형식의 언어 구문 규칙을 입력 받는다.
4. HTML 파서
HTML 파서는 HTML 마크업을 파싱 트리로 변환한다.
4-1. HTML 문법 정의
HTML의 어휘와 문법은 W3C에 의해 명세로 정의되어 있다. 현재 버전은 HTML4와 초안 상태로 진행 중인 HTML5 다.
이 글이 나올 때가 2012년이다. 따라서 HTML5 에 대해 규정을 하던 시기이며 지금은 5에 맞춰 개발을 하는 시기다. 참고해서 이해하면 좋겠다.
4-2. 문맥 자유 문법이 아님
파싱 일반 소개를 통해 알게 된 것처럼 문법은 BNF와 같은 형식을 이용하여 공식적으로 정의할 수 있다.
안타깝게도 모든 전통적인 파서는 HTML에 적용할 수 없다. 그럼에도 불구하고 지금까지 파싱을 설명한 것은 단순 재미 때문에는 아니다.
파싱은 CSS와 자바스크립트를 파싱하는 데 사용된다. HTML은 파서가 요구하는 문맥 자유 문법에 의해 쉽게 정의할 수 없다.
HTML 정의를 위한 공식적인 형식으로 DTD(Document Type Definition)가 있지만 이것은 문맥 자유 문법이 아니다.
문서 타입 정의(DTD)는 XML 문서의 구조 및 해당 문서에서 사용할 수 있는 적법한 요소와 속성을 정의합니다.
HTML5 부터는 SGML(Standard Generalized Markup Language)을 기반으로 하지 않아 DTD를 참조할 필요가 사라지고 브라우저 엔진에게만 알려주는 역할을 한다. TCP SCHOOL- doctype
ex) <!DOCTYPE html>
이것은 언뜻 이상하게 보일 수도 있는데 HTML이 XML과 유사하기 때문이다. 사용할 수 있는 XML 파서는 많다. HTML을 XML 형태로 재구성한 XHTML도 있는데 무엇이 큰 차이점일까?
HTML은 더 '너그럽다'
HTML은 암묵적으로 태그에 대한 생략이 가능하다. 가끔 시작 또는 종료 태그 등을 생략한다. 전반적으로 뻣뻣하고 부담스러운 XML에 반하여 HTML은 "유연한" 문법이다.
이런 작은 차이가 큰 차이를 만들어 낸다. 웹 제작자의 실수를 너그럽게 용서하고 편하게 만들어주는 이것이야 말로 HTML이 인기가 있었던 이유다. 다른 한편으로는 공식적인 문법으로 작성하기 어렵게 만드는 문제가 있다. 정리하자면 HTML은 파싱하기 어렵고 전통적인 구문 분석이 불가능하기 때문에 문맥 자유 문법이 아니라는 것이다. XML 파서로도 파싱하기 쉽지 않다.
4-3. HTML DTD
HTML의 정의는 DTD 형식 안에 있는 SGML 계열 언어의 정의를 이용한 것이다. 이 형식은 허용되는 모든 요소와 그들의 속성 그리고 중첩 구조에 대한 정의를 포함한다. 앞서 말 한대로 HTML DTD는 문맥 자유 문법이 아니다.
DTD는 여러 변종이 있다. 엄격한 형식은 명세만을 따르지만 다른 형식은 낡은 부라우저에서 사용된 마크업을 지원한다. 낡은 마크업을 지원하는 이유는 오래된 콘텐츠에 대한 하위 호환성 때문이다. 현재의 엄격한 형식의 DTD는 www.w3,org/TR/html4/strict.dtd에서 확인할 수 있다.
4-4. DOM
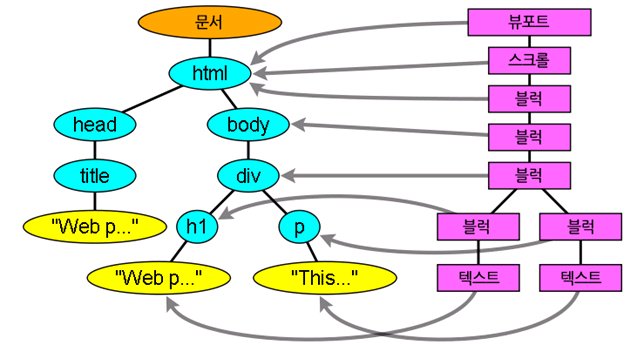
"파싱 트리"는 DOM요소와 속성 노드의 트리로서 출력 트리가 된다. DOM은 문서 객체 모델의 준말이다. 이것은 HTML 문서의 객체 표현이고 외부를 향하는 자바스크립트와 같은 HTML 요소의 연결 지점이다. 트리의 최상위 객체는 document이다.
DOM은 마크업과 1:1의 관계를 맺는다. 예를 들면 이런 마크업이 있다.
<html>
<body>
<p>Hello World</p>
<div><img src="example.png" /></div>
</body>
</html> 이것은 아래와 같은 DOM 트리로 변환할 수 있다.
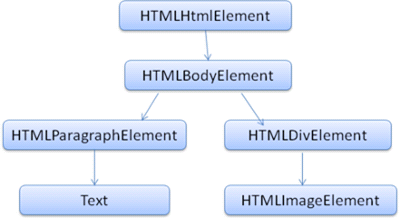
HTML과 마찬가지로 DOM은 W3C에 의해 명세(www.w3.org/DOM/DOMTR)가 정해져 있다. 이것은 문서를 다루기 위한 일반적인 명세인데 부분적으로 HTML요소를 설명하기도 한다. HTML 정의는 (https://www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html)에서 찾을 수 있다.
트리가 DOM 노드를 포함한다고 말하는 것은 DOM 접점의 하나를 실행하는 요소를 구성한다는 의미다. 브라우저는 내부의 다른 속성들을 이용하여 이를 구체적으로 실행한다.
4-5. 파싱 알고리즘
앞서 말한대로 HTML은 일반적인 하향식 또는 상향식 파서로 파싱이 안되는데 그 이유는 다음과 같다.
- 언어의 너그러운 속성
- 잘 알려져 있는 HTML 오류에 대한 브라우저의 관용.
- 변경에 의한 재파싱. 일반적으로 소스는 파싱하는 동안 변하지 않지만 HTML에서 document.write을 포함하고 있는 스크립트 태그는 토큰을 추가할 수 있기 때문에 실제로는 입력 과정에서 파싱이 수정된다.
일반적인 파싱 기술을 사용할 수 없기 때문에 브라우저는 HTML 파싱을 위해 별도의 파서를 생성한다.
파싱 알고리즘은 HTML 자세히 설명되어 있다. 알고리즘은 토큰화와 트리 구축 이렇게 두 단계로 되어 있다.
토큰화는 어휘 분석으로서 입력 값을 토큰으로 파싱한다. HTML에서 토큰은 시작 태그, 종료 태그, 속성 이름과 속성 값이다.
토큰화는 토큰을 인지해서 트리 생성자로 넘기고 다음 토큰을 확인하기 위해 다음 문자를 확인한다. 그리고 입력의 마지막까지 이 과정을 반복한다.
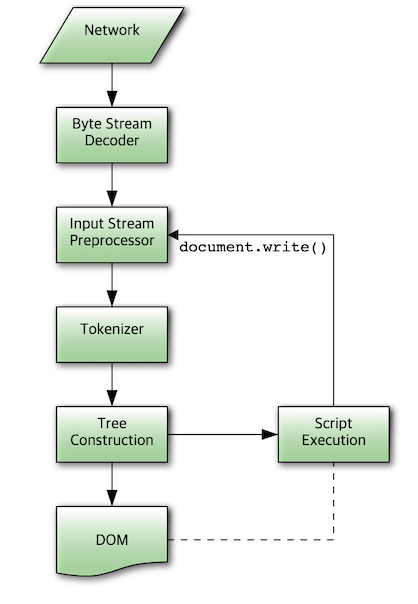
D2 그림이 더 이해하기 어려울 것 같아 whatwg에서 이미지를 가져왔습니다.
설명하면 Network로 부터 HTML 문서를 받아 Byte단위로 Input Stream 처리기에 넣어 Token화를 진행합니다. Tree를 생성해나갑니다.이 동작을 반복하고 DOM을 마지막에 리턴합니다.
4-6. 토큰화 알고리즘
알고리즘의 결과물은 HTML 토큰이다. 알고리즘은 상태 기계(state Machine)라고 볼 수 있다. 각 상태는 하나 이상의 연속된 문자를 입력받아 이 문자에 따라 다음 상태를 갱신한다. 그러나 결과는 현재의 토큰화 상태와 트리 구축 상태의 영향을 받는데 같은 문자를 읽어 들여도 현재 상태에 따라 다음 상태의 결과가 다르게 나온다는 걸 의미한다. 알고리즘 전체를 설명하기에 너무 복잡하니 원리 이해를 도울만한 간단한 예제를 보자.
다음은 HTML 토큰화를 설명하기 위한 기본적인 예제다.
<html>
<body>
Hello world
</body>
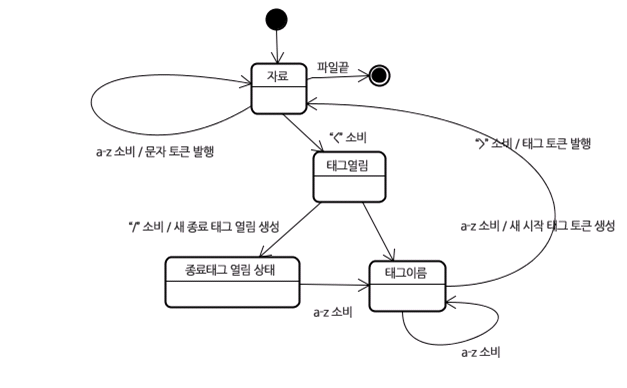
</html> 초기 상태는 "자료 상태"다. "<" 문자를 만나면 상태는 "태그 열림 상태"로 변한다. a 부터 z 까지의 문자를 만나면 "시작 태그 토큰"을 생성하고 상태는 "태그 이름 상태"로 변하는데 이 상태는 ">" 문자를 만날 때까지 유지한다. 각 문자에는 새로운 토큰 이름이 붙는데 이 경우 생성된 토큰은 html 토큰이다.
">" 문자에 도달하면 현재 토큰이 발행되고 상태는 다시 "자료 상태"로 바뀐다. 태그는 동일한 절차에 따라 처리된다. 지금까지 html 태그와 body 태그를 발행했고 다시 "자료 상태"로 돌아왔다. Hello world의 'H'를 만나면 문자 토큰이 생성되고 발행될 것이다. 이것은 종료 태그의 "<"를 만날 때까지 진행된다. Hello World의 각 문자를 위한 문자 토큰을 발행할 것이다.
다시 "태그 열림 상태"가 되었다. "/"문자는 종료 태그 토큰을 생성하고 "태그 이름 상태"로 변경 될 것이다. 이 상태는 ">" 문자를 만날 때까지 유지된다. 그리고 새로운 태그 토큰이 발행되고 다시 "자료 상태"가 된다. 또한 동일하게 처리될 것이다.
5. 트리 구축 알고리즘
파서가 생성되면 문서 객체가 생성된다. 트리 구축이 진행되는 동안 문서 최상단에서는 DOM 트리가 수정되고 요소가 추가된다. 토큰화에 의해 발행된 각 노드는 트리 생성자에 의해 처리된다. 각 토큰을 위한 DOM 요소의 명세는 정의되어 있다. DOM 트리에 요소를 추가하는 것이 아니라면 열린 요소는 스택에 추가된다. 이 스택은 부정확한 중첩과 종료되지 않은 태그를 교정한다. 알고리즘은 상태 기계라고 설명할 수 있고 상태는 "삽입 모드"라고 부른다.
아래 입력 예제의 트리 생성 과정을 보자.
<html>
<body>
Hello world
</body>
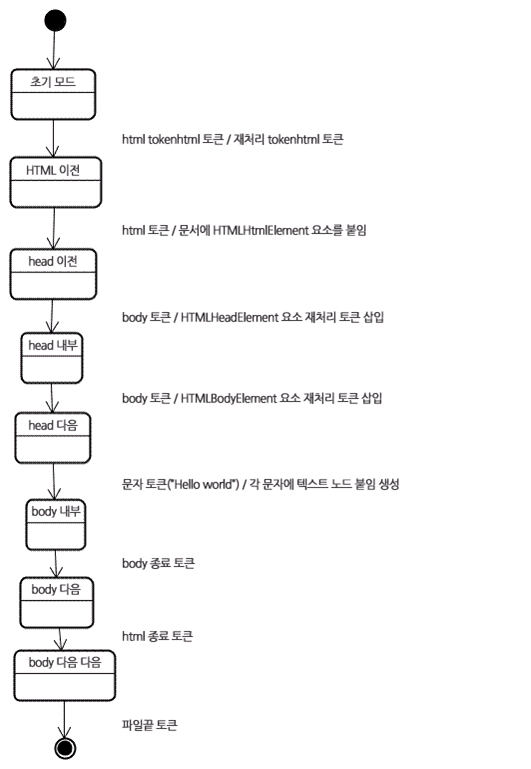
</html> 트리 구축 단계의 입력 값은 토큰화 단계에서 만들어지는 일련의 토큰이다. 받은 html 토큰은 "html 이전" 모드가 되고 토큰은 이 모드에서 처리된다. 이것은 HTMLHtmlElement 요소를 생성하고 문서 객체의 최상단에 추가된다.
상태는 "head 이전" 모드로 바뀌었고 "body" 토큰을 받았다. "head" 토큰이 없더라도 HTMLHeadElement는 묵시적으로 생성되어 트리에 추가될 것이다.
곧이어 "head 안쪽" 모드로 이동했고 다음은 "head 다음"모드로 간다. body 토큰이 처리되었고 HTMLBodyElemenet가 생성되어 추가됐으며 "body안쪽" 모드가 되었다.
"Hello world" 문자열의 문자 토큰을 받았다. 첫 번째 토큰이 생성되고 "본문" 노드가 추가되면서 다른 문자들이 그 노드에 추가될 것이다.
body 종료 토큰을 받으면 "body 다음" 모드가 된다. html 종료 태그를 만나면 "body 다음 다음" 모드로 바뀐다. 마지막 파일 토큰을 받으면 파싱을 종료한다.
6. 파싱이 끝난 이후의 동작
이번 단계에서 브라우저는 문서와 상호작용할 수 있게 되고 문서 파싱 이후에 실행되어야 하는 "지연" 모드 스크립트를 파싱하기 시작한다. 문서 상태는 "완료"가 되고 "로드" 이벤트가 발생한다. 보다 자세한 내용은 HTML5 토큰화 알고리즘과 트리 구축에서 볼 수 있다.
7. 브라우저의 오류 처리
HTML 페이지에서 "유효하지 않은 구문" 이라는 오류를 본 적이 드물 것이다.
이는 브라우저가 모든 오류 구문을 교정하기 때문이다. 아래 오류가 포함된 HTML 예제를 보자
<html>
<mytag></mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html> 나는 일부러 여러 가지 규칙을 위반 했다. "mytag"는 표준 태그가 아니고 "p" 태그와 "div" 태그는 중첩 오류가 있다. 그러나 브라우저는 투덜거리지 않고 올바르게 표시하는데 이는 파서가 HTML 제작자의 실수를 수정했기 때문이다.
이런 오류 처리 행태는 브라우저에서 꽤나 일반적임에도 불구하고 HTML의 현재 명세가 아니라는 점이 놀라울 뿐이다. 북마크와 이전/다음 버튼처럼 수 년간 브라우저 안에서 구현된 것이다. 잘 알려진 HTML 오류를 많은 사이트에서 발견할 수 있지만 브라우저는 다른 브라우저들이 했던 것처럼 관습적으로 오류를 고치고 있다.
HTML5 명세는 이런 요구 사항 일부를 정의했다. 웹킷은 이것을 HTML 파서 클래스의 시작 부분에 주석으로 잘 요약해 두었다.
파서는 토큰화된 입력 값을 파싱하여 문서를 만들고 문서 트리를 생성한다. 규칙에 맞게 잘 작성된 문서라면 파싱이 수월하겠지만 불행하게도 형식에 맞지 않게 작성된 많은 HTML 문서를 다뤄야 하기 때문에 파서는 오류에 대한 아량이 있어야 한다.
파서는 적어도 다음과 같은 오류를 처리해야 한다.
- 어떤 태그의 안쪽에 추가하려는 태그가 금지된 것일 때 일단 허용된 태그를 먼저 닫고 금지된 태그는 외부에 추가한다.
- 파서가 직접 요소를 추가해서는 안된다. 문서 제작자에 의해 뒤늦게 요소가 추가될 수 있고 생략 가능한 경우도 있다. HTML, HEAD, BODY, TBODY, TR, TD, LI 태그가 이런 경우에 해당한다.
- 인라인 요소 안쪽에 블록 요소가 있는 경우 부모 블록 요소를 만날 때까지 모든 인라인 태그를 닫는다.
- 이런 방법이 도움이 되지 않으면 태그를 추가하거나 무시할 수 있는 상태가 될 때까지 요소를 닫는다.
웹킷이 오류를 처리하는 예는 다음과 같다.
<br> 대신 </br>
어떤 사이트는 <br> 대신 </br>을 사용한다. 인터넷 익스플로러, 파이어폭스와 호환성을 갖기 위해 웹킷은 이것을 <br> 으로 간주한다. 코드는 다음과 같다.
if(t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}오류는 내부적으로 처리하고 사용자에게는 표시하지 않는다.
더 자세하게는 웹킷 오류 처리 코드 예제를 확인해 보는게 좋겠다.
8. CSS 파싱
소개 글에서 설명했던 파싱의 개념을 기억하는가? HTML과 다르게 CSS는 문맥 자유 문법이고 소개 글에서 설명했던 파서 유형을 이용하여 파싱이 가능하다.
몇 가지 예제를 보자. 어휘 문법은 각 토큰을 위한 정규 표현식으로 정의되어 있다.
omment \/*[^]*+([^/][^]*+)\/
num [0-9]+|[0-9]"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}
"ident"는 클래스 이름처럼 식별자(identifier)를 줄인 것이다. "name"은 요소의 id("#"으로 참조) 이다.
구문 문법은 BNF로 설명된다.
Ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
Selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
Class
: '.' IDENT
;
element_name
: IDENT | '*'
;
Attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
Pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
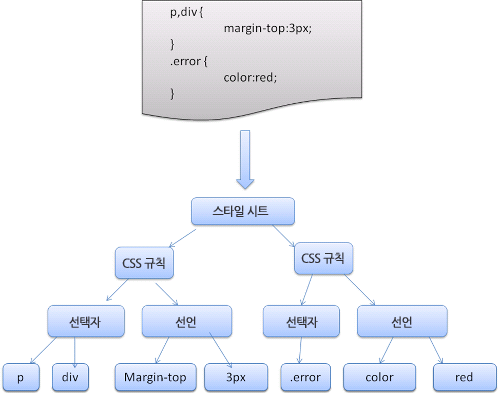
;룰셋(ruleset)은 다음과 같은 구조를 나타낸다.
div.error, a.error {
color: red;
font-weight: bold;
}div.error와 a.error 는 선택자(selector)이다. 중괄호 안쪽에는 이 룰셋에 적용된 규칙이 포함되어 있다. 이 구조는 공식적으로 다음과 같이 정의되어 있다.
Ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;룰셋은 쉼표와 공백(S가 공백을 의미함)으로 구분된 하나 또는 여러 개의 선택자라는 것을 의미한다. 룰셋은 중괄호 내부에 하나 또는 세미 콜론으로 구분된 여러 개의 선언을 포함한다. "선언"과 "선택자"는 이어지는 BNF에 정의되어 있다.
8. 웹킷 CSS 파서
웹킷은 CSS 문법 파일로부터 자동으로 파서를 생성하기 위해 플렉스와 바이슨 파서 생성기를 사용한다. 파서 소개에서 언급했던 것처럼 바이슨은 상향식 이동 감소 파서를 생성한다. 파이어폭스는 직접 작성한 하향식 파서를 사용한다. 두 경우 모두 각 CSS 파일은 스타일 시트 객체로 파싱되고 각 객체는 CSS 규칙을 포함한다. CSS 규칙 객체는 선택자와 선언 객체 그리고 CSS 문법과 일치하는 다른 객체를 포함한다.
9. 스크립트와 스타일 시트의 진행 순서
-
스크립트
웹은 파싱과 실행이 동시에 수행되는 동기화(synchronous) 모델이다. 제작자는 파서가 < script > 태그를 만나면 즉시 파싱하고 실행하기를 기대한다. 스크립트가 실행되는 동안 문서의 파싱은 중단된다. 스크립트가 외부에 있는 경우 우선 네트워크로부터 자원을 가져와야 하는데 이 또한 실시간으로 처리되고 자원을 받을 때까지 파싱은 중단된다. 이 모델은 수 년간 지속됐고 HTML4와 HTML5의 명세에도 정의되어 있다. 제작자는 스크립트를 "지연(defer)"으로 표시할 수 있는데 지연으로 표시하게 되면 문서 파싱은 중단되지 않고 문서 파싱이 완료된 이후에 스크립트가 실행된다. HTML5는 스크립트를 비동기(asynchronous)로 처리하는 속성을 추가했기 때문에 별도의 맥락에 의해 파싱되고 실행된다. -
예측 파싱
웹킷과 파이어폭스는 예측 파싱과 같은 최적화를 지원한다. 스크립트를 실행하는 동안 다른 스레드는 네트워크로부터 다른 자원을 찾아 내려받고 문서의 나머지 부분을 파싱한다. 이런 방법은 자원을 병렬로 연결하여 받을 수 있고 전체적인 속도를 개선한다. 참고로 예측 파서는 DOM 트리를 수정하지 않고 메인 파서의 일로 넘긴다. 예측 파서는 외부 스크립트, 외부 스타일 시트와 외부 이미지와 같이 참조된 외부 자원을 파싱할 뿐이다. -
스타일 시트
한편 스타일 시트는 다른 모델을 사용한다. 이론적으로 스타일 시트는 DOM 트리를 변경하지 않기 때문에 문서 파싱을 기다리거나 중단할 이유가 없다. 그러나 스크립트가 문서를 파싱하는 동안 스타일 정보를 요청하는 경우라면 문제가 된다. 스타일이 파싱되지 않은 상태라면 스크립트는 잘못된 결과를 내놓기 때문에 많은 문제를 야기한다. 이런 문제는 흔치 않은 것처럼 보이지만 매우 빈번하게 발생한다. 파이어폭스는 아직 로드 중이거나 파싱 중인 스타일 시트가 있는 경우 모든 스크립트의 실행을 중단한다. 한편 웹킷은 로드되지 않은 스타일 시트 가운데 문제가 될만한 속성이 있을 때에만 스크립트를 중단한다.
10. 렌더 트리 구축
DOM 트리가 구축되는 동안 브라우저는 렌더 트리를 구축한다. 표시해야 할 순서와 문서의 시각적인 구성 요소로써 올바른 순서로 내용을 그려낼 수 있도록 하기 위한 목적이 있다.
파이어폭스는 이 구성 요소를 "형상(frames)" 이라고 부르고 웹킷은 "렌더러(renderer)" 또는 "렌더 객체(render object)"라는 용어를 사용한다.
렌더러는 자신과 자식 요소를 어떻게 배치하고 그려내야 하는지 알고 있다.
웹킷 렌더러의 기본 클래스인 RenderObject 클래스는 다음과 같이 정의되어 있다.
class RenderObject { virtual
void layout(); virtual
void paint(PaintInfo); virtual
void rect repaintRect();
Node * node; //the DOM node
RenderStyle * style; // the computed style
RenderLayer * containgLayer; //the containing z-index layer
}각 렌더러는 CSS2 명세에 따라 노드의 CSS 박스에 부합하는 사각형을 표시한다. 렌더러는 너비, 높이 그리고 위치와 같은 기하학적 정보를 포함한다.
박스 유형은 노드와 관련된 "display" 스타일 속성의 영향을 받는다(스타일 계산 참고). 여기 보이는 웹킷 코드는 display 속성에 따라 DOM 노드에 어떤 유형의 렌더러를 만들어야 하는지 결정하는 코드이다.
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
…
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}요소 유형 또한 고려해야 하는데 예를 들면 폼 콘트롤과 표는 특별한 구조이다.
요소가 특별한 렌더러를 만들어야 한다면 웹킷은 creatRenderer 메서드를 무시하고 비기하학 정보를 포함하는 스타일 객체를 표시한다.
11. DOM 트리와 렌더 트리의 관계
Renderer는 DOM 요소에 부합하지만 1:1로 대응하는 관계는 아니다. 예를 들어 "head" 요소와 같은 비시각적 DOM 요소는 렌더 트리에 추가되지 않는다. 또한 display 속성에 "none" 값이 할당된 요소는 트리에 나타나지 않는다. (visibility 속성에 "hidden"값이 할당된 요소는 트리에 나타난다)
여러 개의 시각 객체와 대응하는 DOM 요소도 있는데 이것들은 보통 하나의 사각형으로는 묘사할 수 없는 복잡한 구조다. 예를 들면 "select" 요소는 '표시 영역, 드롭다운 목록, 버튼' 표시를 위한 3개의 렌더러가 있다. 또한 한 줄에 충분히 표시할 수 없는 문자가 여러줄로 바뀔 때, 새 줄은 별도의 렌더러로 추가된다. 여러 렌더러와 대응하는 또 다른 예는 깨진 HTML이다. CSS 명세에 의하면 인라인 박스는 블록 박스만 포함하거나 인라인 박스만을 포함해야 하는데 인라인과 블록 박스가 섞인인 경우 인라인 박스를 감싸기 위한 익명의 블록 렌더러가 생성된다.
select를 만들어보면 dropdown, button, show가 있는데 이 같이 여러개의 시각 객체와 대응하는 DOM요소를 말한다.
어떤 렌더 객체는 DOM 노드에 대응하지만 트리의 동일한 위치에 있지 않다.
float 처리된 요소 또는 position 속성 값이 absolute로 처리된 요소는 흐름에서 벗어나 트리의 다른 곳에 배치된 상태로 형상이 그려진다. 대신 자리 표시자가 원래 있어야 할 곳에 배치된다.
"뷰포트"는 최초의 블록이다. 웹킷에서는 "RenderView"객체가 이 역할을 한다.
12. 트리를 구축하는 과정
파이어폭스에서 프레젠테이션은 DOM 업데이트를 위한 리스너로 등록된다. 프레젠테이션은 형상 만들기를 FrameConstructor에 위임하고 FrameConstructor는 스타일(스타일 계산 참고)을 결정하고 형상을 만든다.
웹킷에서는 스타일을 결정하고 렌더러를 만드는 과정을 "어태치먼트(attachment)" 라고 부른다. 모든 DOM 노드에는 "attach" 메서드가 있다. 어태치먼트는 동기적인데 DOM 트리에 노드를 추가하면 새 노드의 "attach" 메서드를 호출한다.
html 태그와 body 태그를 처리함으로써 렌더 트리 루트를 구성한다. 루트 렌더 객체는 CSS 명세에서 포함 블록(다른 모든 블록을 포함하는 최상위 블록)이라고 부르는 그것과 일치한다. 파이어폭스는 이것을 ViewPortFrame이라 부르고 웹킷은 RenderView라고 부른다. 이것이 문서가 가리키는 렌더 객체다. 트리의 나머지 부분은 DOM 노드를 추가함으로써 구축된다.
13. 스타일 계산
렌더 트리를 구축하려면 각 렌더 객체의 시각적 속성에 대한 계산이 필요한데 이것은 각 요소의 스타일 속성을 계산함으로써 처리된다.
스타일은 인라인 스타일 요소와 HTML의 시각적 속성(예를 들면 bgcolor 같은 HTML 속성)과 같은 다양한 형태의 스타일 시트를 포함하는데 HTML의 시각적 속성들은 대응하는 CSS 스타일 속성으로 변환된다.
최초의 스타일 시트는 브라우저가 제공하는 기본 스타일 시트인데 페이지 제작자 또는 사용자도 이를 제공할 수 있다. 브라우저는 사용자가 선호하는 스타일을 정의할 수 있도록 지원하는데 파이어폭스의 경우 "파이어폭스 프로필" 폴더에 있는 스타일 시트를 변경함으로써 사용자 선호 스타일을 정의할 수 있다.
스타일을 계산하는 일에는 다음과 같은 몇 가지 어려움이 따른다.
-
스타일 데이터는 구성이 매우 광범위한데 수 많은 스타일 속성들을 수용하면서 메모리 문제를 야기할 수 있다.
-
최적화되어 있지 않다면 각 요소에 할당된 규칙을 찾는 것은 성능 문제를 야기할 수 있다. 각 요소에 할당된 규칙 목록을 전체 규칙으로부터 찾아내는 것은 과중한 일이다. 맞는 규칙을 찾는 과정은 얼핏 보기에는 약속된 방식으로 순탄하게 시작하는 것 같지만 실상 쓸모가 없거나 다른 길을 찾아야만 하는 복잡한 구조가 될 수 있다.
예를 들어 이런 복합 선택자가 있다.div div div div { … }
이 선택자는 3번째 자손<div>에 규칙을 적용한다는 뜻이다. 규칙을 적용할 <div> 요소를 확인하려면 트리로부터 임의의 줄기를 선택하고 탐색하는 과정에서 규칙에 맞지 않는 줄기를 선택했다면 또 다른 줄기를 선택해야 한다.
-
규칙을 적용하는 것은 계층 구조를 파악해야 하는 꽤나 복잡한 다단계 규칙을 수반한다.
브라우저가 이 문제를 어떻게 처리하는지 살펴보자.
13-1. 스타일 정보 공유
웹킷 노드는 스타일 객체(RenderStyle)를 참조하는데 이 객체는 일정 조건 아래 공유할 수 있다. 노드가 형제이거나 또는 사촌일 때 공유하며 다음과 같은 조건일 때 공유할 수 있다.
- 동일한 마우스 반응 상태를 가진 요소여야 한다. 예를 들어 한 요소가 :hover 상태가 될 수 없는데 다른 요소는 :hover가 될 수 있다면 동일한 마우스 상태가 아니다.
- 아이디가 없는 요소.
- 태그 이름이 일치해야 한다.
- 클래스 속성이 일치해야 한다.
- 지정된 속성이 일치해야 한다.
- 링크(link) 상태가 일치해야 한다.
- 초점(focus) 상태가 일치해야 한다.
- 문서 전체에서 속성 선택자의 영향을 받는 요소가 없어야 한다. 여기서 영향이라 함은 속성 선택자를 사용한 경우를 말한다(속성 선택자 예 input[type=text]{...})
- 요소에 인라인 스타일 속성이 없어야 한다(인라인 스타일 예 <p style="...">...</p>).
- 문서 전체에서 형제 선택자를 사용하지 않아야 한다. 웹 코어는 형제 선택자를 만나면 전역 스위치를 열고 전체 문서의 스타일 공유를 중단한다. 형제 선택자는 + 선택자와 :first-child 그리고 :last-child를 포함한다.
13-2. 스타일 시트 다단계 순서
스타일 속성 선언은 여러 스타일 시트에서 나타날 수 있고 하나의 스타일 시트 안에서도 여러 번 나타날 수 있는데 이것은 규칙을 적용하는 순서가 매우 중요하다는 것을 의미한다. 이것을 "다단계(cascade)" 순서라고 한다. CSS2 명세에 따르면 다단계 순서는 다음과 같다(우선 순위가 낮은 것에서 높은 순서임).
- 브라우저 선언 (browser declarations)
- 사용자 일반 선언 (user normal declarations)
- 저작자 일반 선언 (author normal declarations)
- 저작자 중요 선언 (author important declarations)
- 사용자 중요 선언 (user important declarations)
브라우저 선언의 중요도가 가장 낮으며 사용자가 저작자의 선언을 덮어 쓸 수 있는 것은 선언이 중요하다고 표시한 경우뿐이다. 같은 순서 안에서 동일한 속성 선언은 특정성(specificity)에 의해 정렬이 되고 이 순서는 곧 특정성이 된다. HTML 시각 속성은 CSS 속성 선언으로 변환되고 변환된 속성들은 저작자 일반 선언 규칙으로 간주된다.
14. 배치
렌더러가 생성되어 트리에 추가될 때 크기와 위치 정보는 없는데 이런 값을 계산하는 것을 배치 또는 리플로라고 부른다.
HTML은 흐름 기반의 배치 모델을 사용하는데 이것은 보통 단일 경로를 통해 크기와 위치 정보를 계산할 수 있다는 것을 의미한다. 일반적으로 "흐름 속"에서 나중에 등장하는 요소는 앞서 등장한 요소의 위치와 크기에 영향을 미치지 않기 때문에 배치는 왼쪽에서 오른쪽으로 또는 위에서 아래로 흐른다. 단, 표는 크기와 위치를 계산하기 위해 하나 이상의 경로를 필요로 하기 때문에 예외가 된다 (3.5).
좌표계는 기준점으로부터 상대적으로 위치를 결정하는데 좌단(X축)과 상단(Y축) 좌표를 사용한다.
배치는 반복되며 HTML 문서의 <html> 요소에 해당하는 최상위 렌더러에서 시작한다. 배치는 프레임 계층의 일부 또는 전부를 통해 반복되고 각 렌더러에 필요한 크기와 위치 정보를 계산한다.
최상위 렌더러의 위치는 0,0 이고 브라우저 창의 보이는 영역에 해당하는 뷰포트 만큼의 면적을 갖는다.
모든 렌더러는 "배치" 또는 "리플로" 메서드를 갖는데 각 렌더러는 배치해야 할 자식의 배치 메소드를 불러온다.
14-1. 더티 비트 체제
소소한 변경 때문에 전체를 다시 배치하지 않기 위해 브라우저는 "더티 비트" 체제를 사용한다. 렌더러는 다시 배치할 필요가 있는 변경 요소 또는 추가된 것과 그 자식을 "더티"라고 표시한다.
"더티"와 "자식이 더티" 이렇게 두 가지 플래그가 있다. 자식이 더터하다는 것은 본인은 괜찮지만 자식 가운데 적어도 하나를 다시 배치할 필요가 있다는 의미다.
14-2. 전역 배치와 점증 배치
배치는 렌더러 트리 전체에서 일어날 수 있는데 이것을 "전역" 배치라 하고 다음과 같은 경우에 발생한다.
- 글꼴 크기 변경과 같이 모든 렌더러에 영향을 주는 전역 스타일 변경.
- 화면 크기 변경에 의한 결과.
배치는 더티 렌더러가 배치되는 경우에만 점증되는데 추가적인 배치가 필요하기 때문에 약간의 손실이 발생할 수 있다.
점증 배치는 렌더러가 더티일 때 비동기적으로 일어난다. 예를 들면 네트워크로부터 추가 내용을 받아서 DOM 트리에 더해진 다음 새로운 렌더러가 렌더 트리에 붙을 때이다.
14-3. 비동기 배치와 동기 배치
점증 배치는 비동기로 실행된다. 파이어폭스는 점증 배치를 위해 "리플로 명령"을 쌓아 놓고 스케줄러는 이 명령을 한꺼번에 실행한다. 웹킷도 점증 배치를 실행하는 타이머가 있는데 트리를 탐색하여 "더티" 렌더러를 배치한다.
"offsetHeight" 같은 스타일 정보를 요청하는 스크립트는 동기적으로 점증 배치를 실행한다.
전역 배치는 보통 동기적으로 실행된다.
때때로 배치는 스크롤 위치 변화와 같은 일부 속성들 때문에 초기 배치 이후 콜백으로 실행된다.
14-4. 최적화
배치가 "크기 변경" 또는 렌더러 위치 변화 때문에 실행되는 경우 렌더러의 크기는 다시 계산하지 않고 캐시로부터 가져온다.
어떤 경우는 하위 트리만 수정이 되고 최상위로부터 배치가 시작되지 않는 경우도 있다. 이런 경우는 입력 필드에 텍스트를 입력하는 경우와 같이 변화 범위가 한정적이어서 주변에 영향을 미치지 않을 때 발생한다. 만약 입력 필드 바깥쪽에 텍스트가 입력되는 경우라면 배치는 최상단으로부터 시작될 것이다.
14-5. 배치 과정
배치는 보통 다음과 같은 형태로 진행된다.
-
부모 렌더러가 자신의 너비를 결정.
-
부모가 자식을 검토.
-
자식 렌더러를 배치(자식의 x와 y를 설정)
-
(부모와 자식이 더티하거나 전역 배치 상태이거나 또는 다른 이유로) 필요하다면 자식 배치를 호출하여 자식의 높이를 계산한다.
-
-
부모는 자식의 누적된 높이와 여백, 패딩을 사용하여 자신의 높이를 설정한다. 이 값은 부모 렌더러의 부모가 사용하게 된다.
-
더티 비트 플래그를 제거한다.
파이어폭스는 "상태" 객체(nsHTMLReflowState)를 배치("리플로"를 의미)를 위한 매개 변수로 사용하는데 상태는 부모의 너비를 포함한다.
파이어폭스 배치의 결과는 "매트릭스" 객체(nsHTMLReflowMatrics)인데 높이가 계산된 렌더러를 포함한다.
14-6. 너비 계산
렌더러의 너비는 포함하는 블록의 너비, 그리고 렌더러의 너비와 여백, 테두리를 이용하여 계산된다.
예를 들어 다음은 div 요소의 너비를 보자.
<div style="width:30%"></div> 웹킷은 다음(RenderBox 클래스의 calcWidth 메서드)과 같이 계산할 것이다.
-
컨테이너의 너비는 컨테이너 availableWidth와 0 사이의 최대값이다. 이 경우 availableWidth는 다음과 같이 계산된 contentWidth이다.
clientWidth() - paddingLeft() - paddingRight()
clientWidth와 clientHeight는 객체의 테두리와 스크롤바를 제외한 내부 영역을 의미한다.
-
요소의 너비는 "width" 스타일 속성의 값이다. 이 컨테이너 너비의 백분률 값은 절대 값으로 변환될 것이다.
-
좌우측 테두리와 패딩 값이 추가된다.
여기까지 "미리 획득한 너비"의 계산이었다. 이제는 최소 너비와 최대 너비를 계산해야 한다.
미리 획득한 너비가 최대 너비보다 크면 최대 너비가 사용된다. 미리 획득한 너비가 최소 너비(깨지지 않는 가장 작은 단위)보다 작으면 최소 너비가 사용된다.
배치할 필요가 있지만 너비가 고정된 경우 값은 캐시에 저장된다.
14-7. 줄 바꿈
렌더러가 배치되는 동안 줄을 바꿀 필요가 있을 때 배치는 중단되고 줄 바꿀 필요가 있음을 부모에게 전달한다. 부모는 추가 렌더러를 생성하고 배치를 호출한다.
15. 그리기
그리기 단계에서는 화면에 내용을 표시하기 위한 렌더 트리가 탐색되고 렌더러의 "paint" 메서드가 호출된다. 그리기는 UI 기반의 구성 요소를 사용한다.
15-1. 전역과 점증
그리기는 배치와 마찬가지로 전역 또는 점증 방식으로 수행된다. 점증 그리기에서 일부 렌더러는 전체 트리에 영향을 주지 않는 방식으로 변경된다. 변경된 렌더러는 화면 위의 사각형을 무효화 하는데 OS는 이것을 "더티 영역"으로 보고 "paint" 이벤트를 발생시킨다. OS는 몇 개의 영역을 하나로 합치는 방법으로 효과적으로 처리한다. 크롬은 렌더러가 별도의 처리 과정이기 때문에 조금 더 복잡하다. 크롬은 OS의 동작을 어느 정도 모방한다. 프레젠테이션은 이런 이벤트에 귀 기울기고 렌더 최상위로 메시지를 전달한다. 그러면 트리는 적절한 렌더러에 이를 때까지 탐색되고 스스로(보통 자식과 함께) 다시 그려진다.
15-2. 그리기 순서
CSS 2는 그리기 과정의 순서를 정의했다. 이것은 실제로 요소가 stacking contexts에 쌓이는 순서다. 스택은 뒤에서 앞으로 그려지기 때문에 이 순서는 그리기에 영향을 미친다. 블록 렌더러가 쌓이는 순서는 다음과 같다.
- 배경 색
- 배경 이미지
- 테두리
- 자식
- 아웃라인
15-3. 파이어폭스 표시 목록
파이어폭스는 렌더 트리를 검토하고 그려진 사각형을 위한 표시 목록을 구성한다.
목록은 올바른 그리기 순서(배경, 테두리, 기타……)에 따라 사각형을 위한 적절한 렌더러를 포함한다. 이런 방법으로 트리는 여러 번 리페인팅을 실행하는 대신 한 번만 탐색하면서 배경 색, 배경 이미지, 테두리 그리고 나머지 순으로 그려낸다.
파이어폭스는 다른 불투명 요소 뒤에 완전히 가려진 요소는 추가하지 않는 방법으로 최적화를 진행한다.
15-4. 웹킷 사각형 저장소
리페인팅 전에 웹킷은 기존의 사각형을 비트맵으로 저장하여 새로운 사각형과 비교하고 차이가 있는 부분만 다시 그린다.
15-5. 동적 변경
브라우저는 변경에 대해 가능한 한 최소한의 동작으로 반응하려고 노력한다.
그렇기 때문에 요소의 색깔이 바뀌면 해당 요소의 리페인팅만 발생한다. 요소의 위치가 바뀌면 요소와 자식 그리고 형제의 리페인팅과 재배치가 발생한다. DOM 노드를 추가하면 노드의 리페인팅과 재 배치가 발생한다. "html" 요소의 글꼴 크기를 변경하는 것과 같은 큰 변경은 캐시를 무효화하고 트리 전체의 배치와 리페인팅이 발생한다.
15-6. 렌더링 엔진의 스레드
렌더링 엔진은 통신을 제외한 거의 모든 경우에 단일 스레드로 동작한다. 파이어폭스와 사파리의 경우 렌더링 엔진의 스레드는 브라우저의 주요한 스레드에 해당한다. 크롬에서는 이것이 탭 프로세스의 주요 스레드이다.
통신은 몇 개의 병렬 스레드에 의해 진행될 수 있는데 병렬 연결의 수는 보통 2개에서 6개로 제한된다(예를 들면 파이어폭스 3은 6개를 사용).
이벤트 순환
브라우저의 주요 스레드는 이벤트 순환으로 처리 과정을 유지하기 위해 무한 순환된다. 배치와 그리기 같은 이벤트를 위해 대기하고 이벤트를 처리한다. 아래는 주요 이벤트 순환을 위한 파이어폭스 코드이다.
while (!mExiting)
NS_ProcessNextEvent(thread); 16. CSS2 시각 모델
16-1. 캔버스
CSS2 명세는 캔버스를 "서식 구조가 표현되는 공간" 이라고 설명한다. 브라우저가 내용을 그리는 공간인 것이다. 캔버스 공간 각각의 면적은 무한하지만 브라우저는 뷰포트의 크기를 기초로 초기 너비를 결정한다.
CSS2 명세에 따르면 캔버스는 기본적으로 투명하기 때문에 다른 캔버스와 겹치는 경우 비쳐 보이고, 투명하지 않을 경우에는 브라우저에서 정의한 색이 지정된다.
16-2. 박스 모델
CSS 박스 모델은 문서 트리에 있는 요소를 위해 생성되고 시각적 서식 모델에 따라 배치된 사각형 박스를 설명한다.
각 박스는 콘텐츠 영역(문자, 이미지 등)과 선택적인 패딩과 테두리, 여백이 있다.
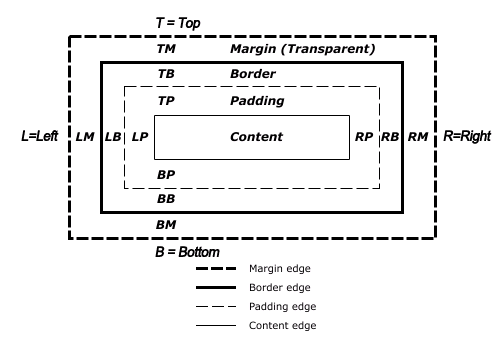
각 노드는 이런 상자를 0에서 n개 생성한다.
모든 요소는 만들어질 박스의 유형을 결정하는 "display" 속성을 갖는데 이 속성의 유형은 다음과 같다.
- block - 블록 상자를 만든다.
- inline - 하나 또는 그 이상의 인라인 상자를 만든다.
- none - 박스를 만들지 않는다.
기본 값은 인라인이지만 브라우저의 스타일 시트는 다른 기본 값을 설정한다.
예를 들면 "div" 요소의 display 속성에 대한 기본 값은 block 이다.
16-3. 위치 결정 방법
위치를 결정하는 방법은 다음과 같은 세 가지다.
- Normal - 객체는 문서 안의 자리에 따라 위치가 결정된다. 이것은 렌더 트리에서 객체의 자리가 DOM 트리의 자리와 같고 박스 유형과 면적에 따라 배치됨을 의미한다.
- Float - 객체는 우선 일반적인 흐름에 따라 배치된 다음 왼쪽이나 오른쪽으로 흘러 이동한다.
- Absolute - 객체는 DOM 트리 자리와는 다른 렌더 트리에 놓인다.
위치는 "position" 속성과 "float" 속성에 의해 결정된다.
- static과 relative로 설정하면 일반적인 흐름에 따라 위치가 결정된다.
- absolute와 fixed로 설정하면 절대적인 위치가 된다.
position 속성을 정의하지 않으면 static이 기본 값이 되며 일반적인 흐름에 따라 위치가 결정된다. static 아닌 다른 속성 값(relative, absolute, fixed)을 사용하면 top, bottom, left, right 속성으로 위치를 결정할 수 있다.
박스가 배치되는 방법은 다음과 같은 방법으로 결정된다.
- 박스 유형(display, inline ...)
- 박스 크기(width, height ...)
- 위치 결정 방법(position, float)
- 추가적인 정보 - 이미지 크기와 화면 크기 등
16-4. 박스 유형
블록 박스: 브라우저 창에서 사각형 블록을 형성한다.

인라인 박스: 블록이 되지 않고 블록 내부에 포함된다.
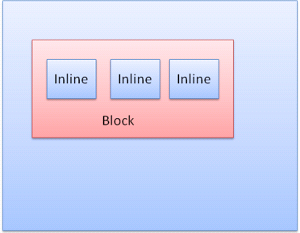
블록은 다른 블록 아래 수직으로 배치되고 인라인은 수평으로 배치된다.
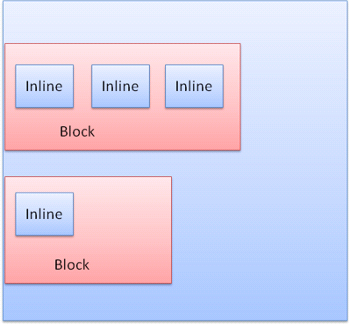
인라인 박스는 라인 또는 "라인 박스" 안쪽에 놓인다. 라인은 적어도 가장 큰 박스만큼 크지만 "baseline" 정렬일 때 더 커질 수 있다. 이것은 요소의 하단이 다른 상자의 하단이 아닌 곳에 배치된 경우를 의미한다. 포함하는 너비가 충분하지 않으면 인라인은 몇 줄의 라인으로 배치되는데 이것은 보통 문단 안에서 발생한다.
16-5. 위치 잡기
상대적인 위치
상대적인 위치 잡기는 일반적인 흐름에 따라 위치를 결정한 다음 필요한 만큼 이동한다.
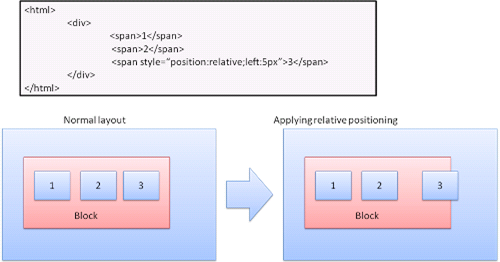
플로트
플로트 박스는 라인의 왼쪽 또는 오른쪽으로 이동한다. 흥미로운 점은 다른 박스가 이 주변을 흐른다는 것이다.
HTML을 다음과 같이 작성하면.
<p>
<img src="http://helloworld.naver.com/image.gif" alt="image.gif" width="100" height="100" style="float:right">
Lorem ipsum dolor sit amet, consectetuer...
</p> 아래와 같이 보일 것이다.

절대적인(absolute) 위치와 고정된(fixed) 위치
절대와 고정 배치는 일반적인 흐름과 무관하게 결정되고, 일반적인 흐름에 관여하지 않으며, 면적은 부모에 따라 상대적이다. 고정인 경우 뷰포트로부터 위치를 결정한다.
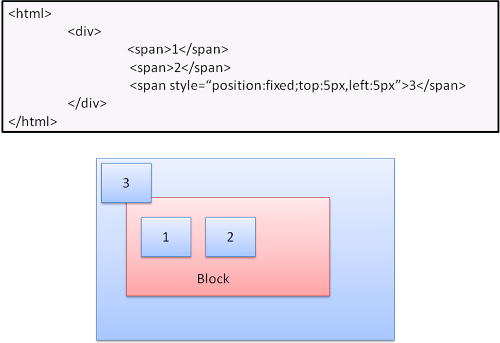
참고 - 고정된 박스는 문서가 스크롤되어도 따라 움직이지 않는다.
16-6. 층 표현
이것은 CSS의 z-index 속성에 의해 명시된다. 층은 박스의 3차원 표현이고 "z 축"을 따라 위치를 정한다.
박스는 (stacking contexts라고 부르는) 스택으로 구분된다. 각 스택에서 뒤쪽 요소가 먼저 그려지고 앞쪽 요소는 사용자에게 가까운 쪽으로 나중에 그려진다. 가장 앞쪽에 위치한 요소는 겹치는 이전 요소를 가린다.
스택은 z-index 속성에 따라 순서를 결정한다. z-index 속성이 있는 박스는 지역 스택(local stack)을 형성한다. 뷰포트는 바깥쪽의 스택(outer stack)이다.
다음 예제를 보자.
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div style="z-index:3;background-color:red;width:1in;height:1in"></div>
<div style="z-index:1;background-color:green;width:2in;height:2in"></div>
</p> 
붉은색 박스가 초록색 박스보다 마크업에서 먼저 나오기 때문에 일반적인 흐름이라면 먼저 그려져야 하지만 z-index 속성이 높기 때문에 더 앞쪽에 표시된다.
사진은 네이버 D2에서 가지고 왔지만 원 출처는 How Browsers Work: Behind the scenes of modern web browsers 입니다.
참고
D2 - 브라우저는 어떻게 동작하는가?
How Browsers Work: Behind the scenes of modern web browsers
