상황 설명
간단한 검색기능이 필요하면 Like 쿼리를 이용하여 검색 기능을 만들고자 했습니다. 이 과정에서 쿼리 플랜이 저의 기대와 다르게 Index Scan이 아닌 Bitmap Scan으로 동작하는 경우가 있었습니다. 왜 저의 예상과 다른 플랜이 나왔는지 알아가는 과정을 공유하고자 합니다.
테이블 및 쿼리 정보
- 아래의 SQL문은 테스트에 사용한 DDL과 Seed 데이터 생성합니다.
CREATE TABLE qp( id SERIAL PRIMARY KEY NOT NULL, title TEXT NOT NULL ); CREATE UNIQUE INDEX index_sample_title ON qp USING btree (title); -- 랜덤 데이터 생성(100만건) INSERT INTO qp (title) SELECT md5(random()::text) FROM generate_series(1, 1000000) AS n; - 실제 수행했던 쿼리는 아래와 같습니다. like query를 통해 unique index가 설정된 title 컬럼을 prefix가 일치하는 데이터를 조회하고 있습니다.
-- EXPLAIN ANALYSE SELECT * FROM qp WHERE title like '?%' -- ?는 다이나믹한 파라미터 ORDER BY title LIMIT 20;
이러한 환경에서 제가 기대했던 쿼리 플랜은 Index Scan을 통해 데이터를 가져온 뒤 IO작업을 통해서 필요한 다른 컬럼 데이터를 가져오는 플랜이었습니다. 하지만 저의 기대와는 다르게 Index Scan 보다는 다른 방식이 사용될 수 있었습니다.
EXPLAIN을 활용하여 QUERY PLAN 조회해보기
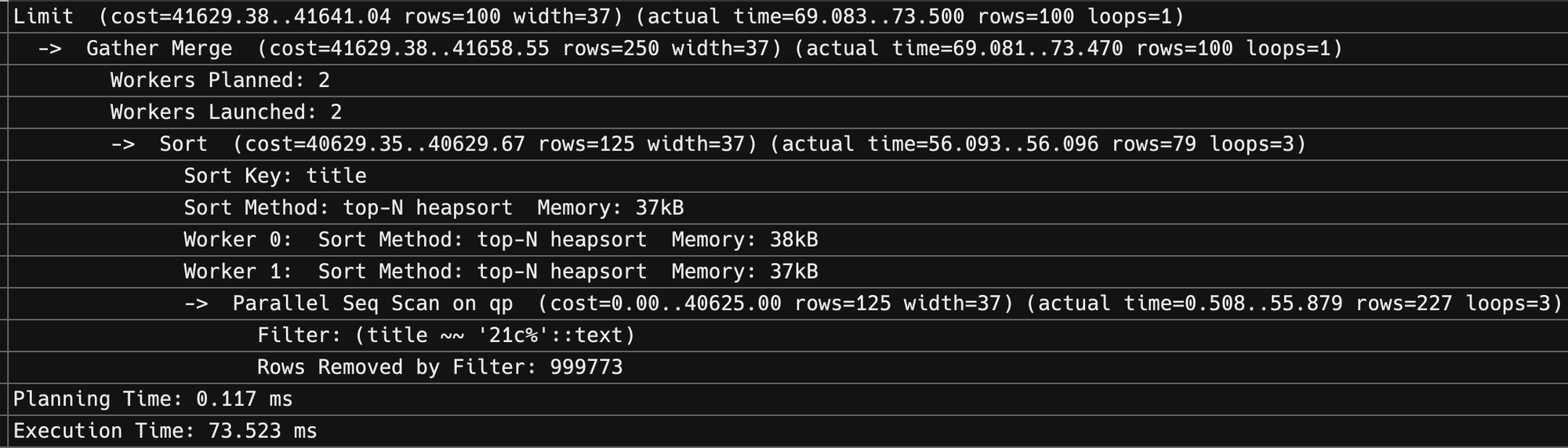
실제로 Limit의 수가 달라질 때마다 Query Plan의 동작이 달라졌습니다. 아래에서 볼 수 있듯이 Limit되는 row의 수에 따라 query plan이 3개로 나눠지는 것을 알 수 있습니다. 원래 기대했던 Index Scan은 제한이 가장 적을 때만 발생했고 중간정도의 제한에서는 Parallel Index Scan을 제한이 높아지면 Parallel Sequence Scan 이후 Sort를 진행하게 됩니다. 아래에 표기되지 않았지만 경우에 따라 Bitmap Scan이 플래닝 될 수도 있었습니다.
- Limit 10

- Limit 20

- Limit 100
기대와 다른 이유
그렇다면 왜 이렇게 Index를 사용해서 쉽게 검색될 것 같은 쿼리가 다양한 플랜이 나오고 조회하는 데이터가 조금만 커져도 Index Scan을 하지 않게 되는 걸까요? 그 원인은 correlation 값에서 힌트를 얻을 수 있습니다.
Correlation
Correlation는 상관분석, 상관관계라는 뜻으로 실제 데이터의 순서와 컬럼의 데이터의 순서의 상관관계를 의미합니다. 1은 같은 순서로 동일하게 정렬된 것을, -1은 반대 방향으로 정렬을 의미합니다. 0에 가까울수록 무작위성이 강하여 해당 컬럼의 정렬 순서와 데이터의 정렬 순서가 무관함을 의미합니다.
그렇다면 이 값이 쿼리 수행에 어떤 영향을 줄까요? 실제 힙영역의 페이지 조회 수에 영향을 줄 수 있습니다. 조금 더 쉽게 설명하면 실제 데이터를 조회하기 위한 접근 횟수와 영향이 있다는 의미입니다. 실제로 쿼리플랜의 가중치에 보면 seq_page_cost(default 1.0)와 random_page_cost(default 4.0) 확인할 수 있습니다. 순차적 페이지 탐색보다 랜덤 페이지 탐색 4배 비싸다고 판단하고 있습니다. 따라서 Correlation이 낮은 컬럼은 컬럼의 순서대로 접근 시 랜덤 페이지 탐색이 많이 발생하고 순서대로 탐색하는 것이 비싸게 측정됩니다.
실제로 저희가 탐색하려고 했던 qp 테이블의 correlation을 조회하면 아래와 같습니다.
SELECT tablename, attname, correlation
FROM pg_stats
WHERE tablename = 'qp';
id 필드는 1이라는 아주 강한 상관관계를 가진 반면 title은 거의 0에 가까운 값을 가진 것을 알 수 있습니다. 따라서 위 조회 쿼리에서 데이터가 많을수록 순차적으로 읽을 수 있는 가능성이 높아지지만 높은 확률로 랜덤 페이지 탐색을 수행하게 됩니다. psql는 이를 보정하기 위해서 순차적으로 읽으면서 랜덤 탐색을 줄이려고 한 것이었습니다.
실제로 id 컬럼으로 유사한 검색을 하면 데이터 수와 상관없이 일관되게 index를 활용하는 것을 알 수 있습니다.
EXPLAIN ANALYSE
SELECT *
FROM qp
WHERE id > 21
ORDER BY title
LIMIT 500;
이 글에서 언급되지 않았지만 order by가 쿼리에 포함되어 있어서 index 탐색은 더욱 높게 평가 되어있습니다. index 순서로 탐색할 경우 별도의 정렬 비용이 없기 때문입니다. 그럼에도 불구하고 랜덤 엑세스에 대한 비용이 더 크다고 판단하는 psql이었습니다.
