
02-모델 기반 학습 예제
🟤 요약 : 간단한 머신러닝 모델
- 데이터 준비 (특성, 타깃 : 지도학습)
- 모델 선택 (선형 회귀)
- 모델 훈련 (fit 메서드 호출 : 사이킷-런)
- 새로운 데이터에 대한 예측 or 추론 (inference)
🟣 삶의 만족도 데이터의 예측 모델의 코딩은 다음과 같음
- 데이터
: OECD의 삶의 만족도(life satisfaction) 데이터
: IMF의 1인당 GDP(GDP per capita) 데이터
🔹 깃허브_code
# 데이터 합치기
def prepare_country_stats(oecd_bli, gdp_per_capita):
oecd_bli = oecd_bli[oecd_bli["INEQUALITY"]=="TOT"]
oecd_bli = oecd_bli.pivot(index="Country", columns="Indicator", values="Value")
gdp_per_capita.rename(columns={"2015": "GDP per capita"}, inplace=True)
gdp_per_capita.set_index("Country", inplace=True)
full_country_stats = pd.merge(left=oecd_bli, right=gdp_per_capita,
left_index=True, right_index=True)
full_country_stats.sort_values(by="GDP per capita", inplace=True)
remove_indices = [0, 1, 6, 8, 33, 34, 35]
keep_indices = list(set(range(36)) - set(remove_indices))
return full_country_stats[["GDP per capita", 'Life satisfaction']].iloc[keep_indices]
# 라이브러리 생성
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import sklearn.linear_model
# 데이터 적재
oecd_bli = pd.read_csv(datapath + "oecd_bli_2015.csv", thousands=',')
gdp_per_capita = pd.read_csv(datapath + "gdp_per_capita.csv",thousands=',',delimiter='\t',
encoding='latin1', na_values="n/a")
# 데이터 준비
country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)
X = np.c_[country_stats["GDP per capita"]]
y = np.c_[country_stats["Life satisfaction"]]
# 데이터 시각화
country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')
plt.show()
# 선형 모델 선택
model = sklearn.linear_model.LinearRegression()
# 모델 훈련
model.fit(X, y)
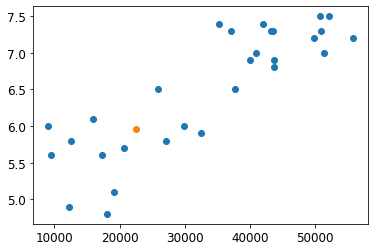
# 키프로스에 대한 예측
X_new = [[22587]] # 키프로스 1인당 GDP
print(model.predict(X_new)) # 출력 [[ 5.96242338]]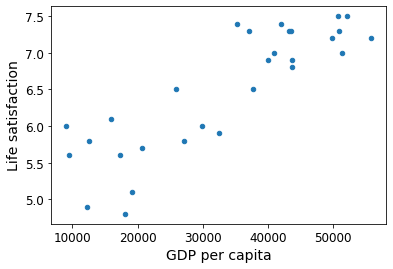
# 선형회귀 결과
plt.scatter(X, y)
plt.scatter(22587, 5.96)
plt.show()

best of best