[논문리뷰] Accurate Image Super-Resolution Using Very Deep Convolutional Networks (VDSR)
Paper Review

👉Paper
안녕하세요, 오늘 소개 해 드릴 논문은 Super-Resolution문제를 Deep한 Network를 쌓아 해결 한 VDSR이라는 논문입니다. VDSR은 SRCNN 다음 나온 논문으로 매우 Deep한 Network와 Residual Learning을 한 논문이죠!
Abstract
VDSR은 VGG-net에서 아이디어를 얻어 SR에 깊은 네트워크를 적용한 Algorithm이다. 이 논문에서는 깊은 network가 accuracy를 향상시킨다는 것을 보여준다. 또한 이 논문에서는 deep한 network가 효율적으로 수렴하기 위해 residual 학습과 adjustable gradient clipping을 적용하였다.
Introduction
SRCNN의 문제점은 small image regions의 context에 의지한다는 것과, 학습의 수렴 속도가 너무 느리다는 것, 그리고 network가 하나의 scale에 대해서만 작동한다는 것이다.
그래서 VDSR은 실용적으로 이 문제들을 해결하기 위한 방법을 제안한다.
- Context : VDSR은 매우 큰 image regions에 있는 contextual information을 사용하였다. 왜냐하면 large scale factor에 대해서 small patch에 있는 information은 detail을 복원하기에 충분하지 않기 때문이다.
- Convergence : VDSR은 training의 속도를 빠르게 하는 방법을 제안한다. 그 방법은 residual-learning과 gradient clipping이다.
- Scale Factor : VDSR은 scale factor를 임의로 지정할 수 있는 단일 SR 모델을 제안한다.
Proposed Method
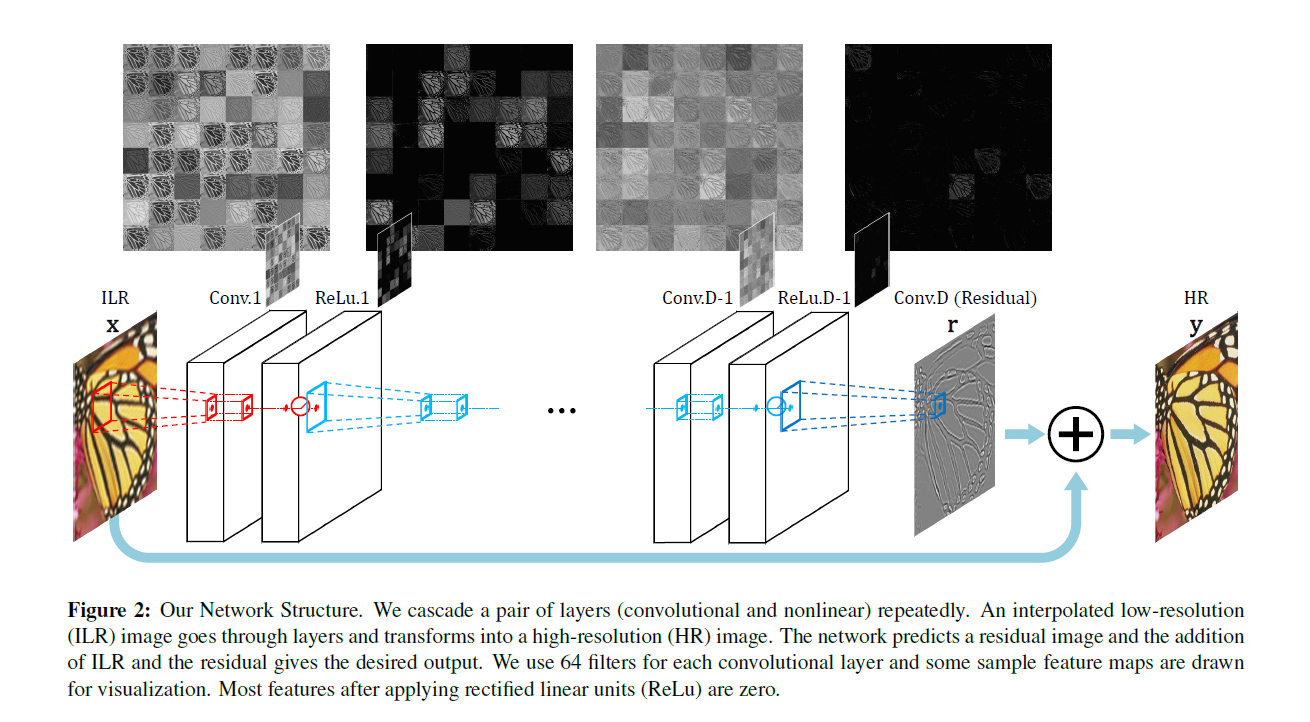
VDSR의 network는 위의그림과 같이 매우 깊은 layers로 구성되어있다. input image인 x는 interpolated된 이미지이며, 인풋 이미지는 사이에 있는 deep network를 통과하고 나온 feature에 마지막으로 더해져서 HR 이미지로 복원된다.
Training
VDSR은 Loss로 MSE loss를 선택하였으며, deep한 layer를 가진 model의 vanishing/exploding gradients 문제를 해결하기 위해 residual-learning을 적용하였다.
우선, residual-image "r"은 다음과 같이 정의 된다.
$$r = y - x$$x : interpolated image, y : high-resolution image
그리고 residual-learning은 이 residual이 0에 가깝거나 작아지도록 하는 것이다. Residual-Learning은 r과 f(x) [network prediction value]를 가지고 MSE Loss를 구한다.
학습에서 learning-rate는 0.0001로 설정하였다고 한다.
Adjustable Gradient Clipping
Gradient Clipping은 recurrent neural network를 학습시키는데 보통 사용된다고 한다.
Gradient Clipping 내용 참조 블로그 : https://dhhwang89.tistory.com/90
recurrent neural network과 같은 강한 비선형 목적함수를 갖고 있는 경우, 미분값이 매우 크거나 작아지는 문제가 생기고, 이런 지점에서는 backpropagation에서의 gradient update step에서 파라미터들이 크게 움직이게 되고, 이렇게 되면 학습하던 epoch들이 의미가 없게 될 수 있는 문제가 발생한다. (Training과정에서 Gradient는 이 알고리즘이 가야 할 방향을 알려주는 역할을 한다. )
이러한 문제를 해결하기 위한 방법 중 하나는 learning rate를 매우 작게 하는것이다. 하지만 이런 해결 방법은 학습 속도를 매우 느리게 만들고, local minima에 빠질 수 있다.
그래서 위 방법보다 더 좋은 해결 방법이 "Gradient Clipping"이다. Gradient clipping은 gradient의 최대 갯수를 제한하고, gradient가 최대치를 넘게 되면 gradient의 크기를 재조정하는 것이다. 이 방법은 gradient descent 알고리즘이 가야하는 방향은 그대로 유지하면서, 업데이트 되어야 하는 step의 learning rate를 자동으로 조정해준다.
그래서 VDSR은 이 Adjustable Gradient Clipping을 이용하여 빠르게 converge가 되도록 하였다.
Multi-Scale
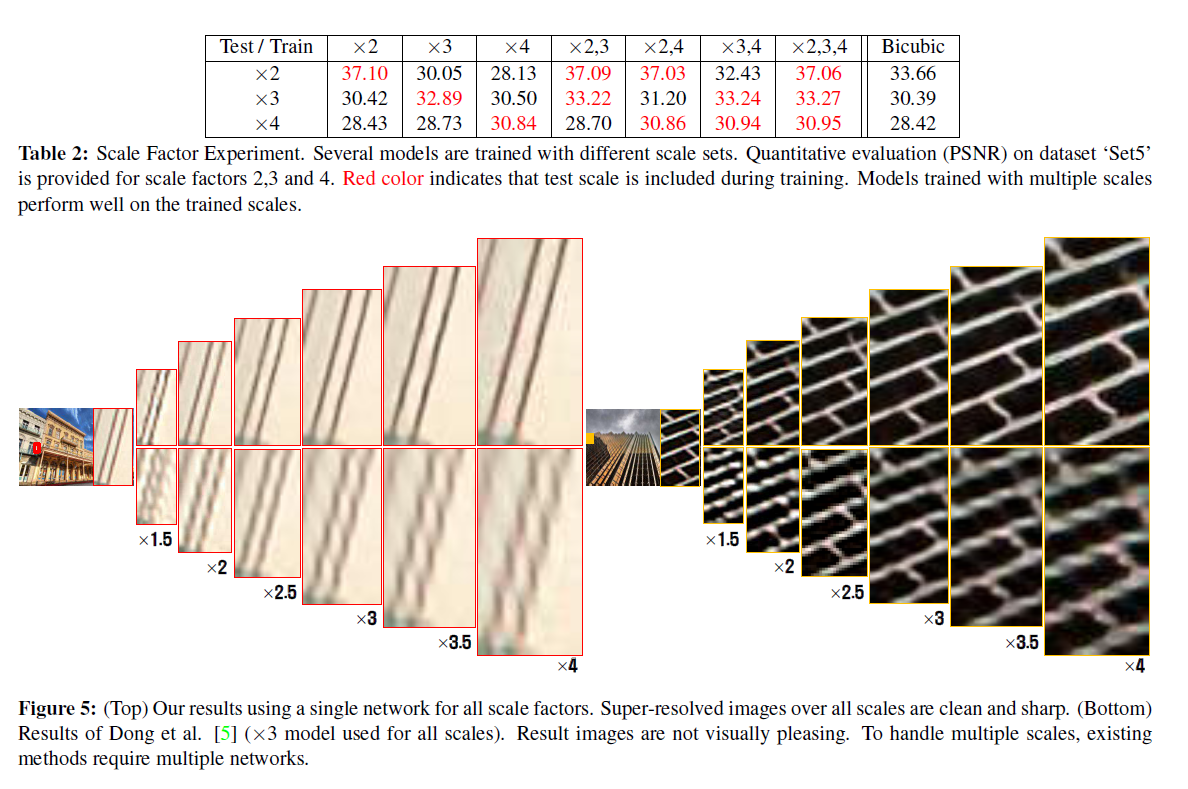
전형적으로 하나의 network는 하나의 scale-factor만 만들어 낼 수 있지만, VDSR은 muti-scale model을 학습시켰다. 그래서 아래와 같이 다양한 스케일에서 적용이 가능하다.
Experimental Results
- Datasets for Training and Testing
VDSR은 training을 위해 data augmentation (rotation or flip)을 사용하였으며, Test로는 benchmark인 Set5와 Set14, Urban100, B100을 사용하였다고 한다.

비쥬얼적인 결과 비교는 위와 같으며, 기존 알고리즘들에 비해 훨씬 더 선명한 결과를 보이고 있다.
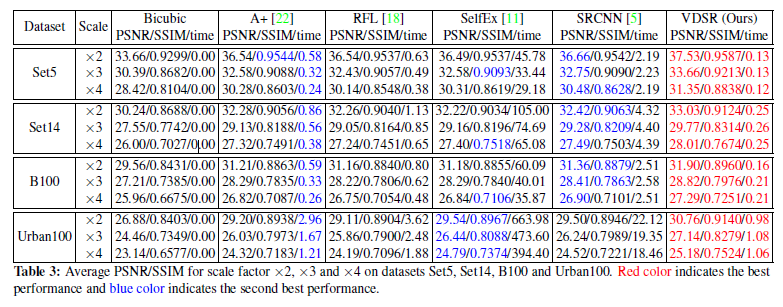
수치적인 결과 또한 기존의 알고리즘들에 비해 모두 높은 성능을 보였다.
Review
Multi-scale을 single model에 적용시킨 것이 좋았고, 깊은 network로 인해 일어나는 문제들을 잘 해결하여 좋은 성능을 낸 algorithm인 것 같다.
