
안녕하세요👼 오늘은 처음으로 올리는 논문은 Super-Resolution 논문인 SRCNN 입니다. 기본적으로 SR문제는 저해상도의 이미지를 고해상도로 복원시키는 문제이며, 다양한 Computer Vision task에서 pre-processing step으로 사용될 수 있습니다 :-)
👉 SRCNN
Abstract
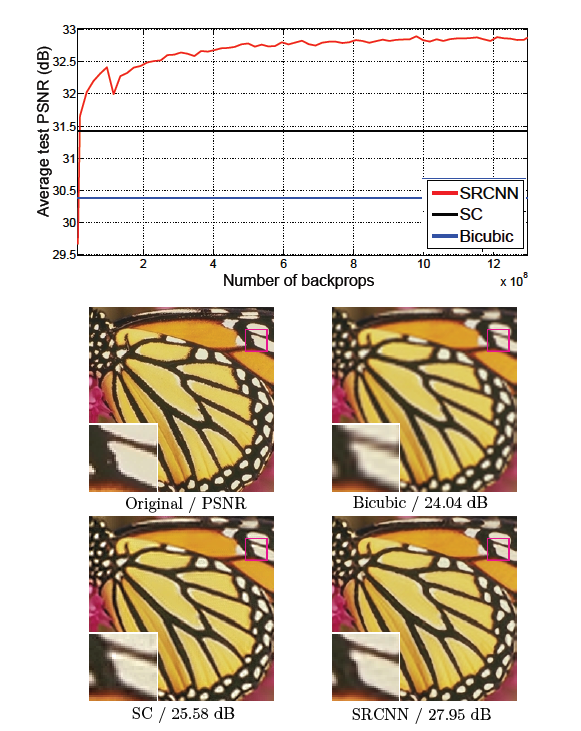
이 논문에서는 Deep Learning을 이용한 Single Image Super-Resolution 방법을 제안하고 있다. 이 논문에서는 direct로 low/high-resolution image 사이의 mapping 방법을 end-to-end로 학습시킨다. Mapping은 CNN을 이용해 low-resolution의 input을 high-resolution의 output로 만들어 내는 것이다. 아래 그림과 같이 제안하는 방법은 3개의 layer를 사용한 가벼운 structure임에도 당시 state-of-the-art의 quality를 보여주었다.
Introduction
SRCNN은 Deep learning method를 이용해 Single image super-resolution을 해결하는 방법을 제안한 논문이다. Single image super-resolution은 “저해상도 (low-resolution) 영상을 고해상도 (high-resolution) 영상으로 복원하는 것” 을 말하며, 하나의 input으로부터 여러 result가 나올 수 있기 때문에 “ill-posed problem” 이기도 하다.
SRCNN은 Low-resolution images로부터 High-resolution images로 직접 end-to-end mapping하는 방법을 학습하는 convolutional neural network를 제안한다.
SRCNN의 Contribution은 3가지가 있다.
1) Present fully convolutional neural network for image super-resolution.
2) Establish a relationship between SRCNN and traditional sparse-coding-based SR methods.
3) Demonstrate that deep learning is useful in the classical computer vision.
Proposed Method
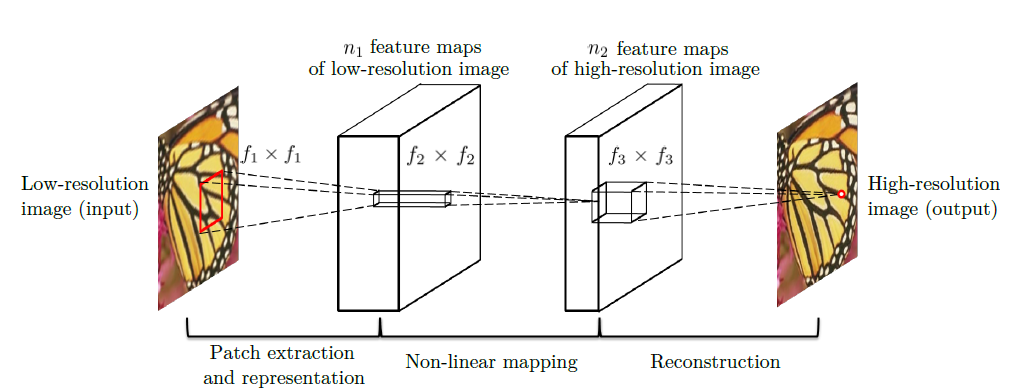
SRCNN은 위의 그림과 같이 크게 3가지로 구성 되어있다.
1) Patch extraction and representation
이 연산은 low-resolution image Y로부터 patches를 extracts하고 고차원의 vector로 representation한다.
이 vectors는 feature maps의 set으로 구성되어있다.
2) Non-linear mapping
이 연산은 고차원의 vector를 다른 고차원의 vector로 nonlinear mapping한다. 각 mapping된 vector는 개념적으로 고해상도의 patches를 표현한다.
3) Reconstruction
이 연산은 patches로부터 최종적으로 고해상도의 image를 만들어낸다.
간단하게 이야기하면, 각 파트들은 Convolution Layer로 이루어져 있으며, 첫 번째 layer에서는 저해상도 이미지로부터 feature를 추출하고, 두 번째 layer에서는 고차원의 vector들을 feature mapping을 하며, 마지막 layer에서 feature로부터 나온 결과를 image로 복원한다.
Training
end-to-end mapping function F 를 학습시키기 위해서는 network parameters를 estimation하는 것이 필요하다. 이 estimation은 network로부터 나온 output과 ground-truth 사이의 loss를 최소화 하는 것이다. 이 논문에서는 이 차이를 최소화 하기 위해 loss function으로는 MSE를 사용하였으며, optimization으로는 SGD (stochastic-gradient-decent)를 사용하였다.
앞의 두 Layer는 learning-rate를 0.0001으로 하였고, 마지막 layer는 learning-rate를 0.00001로 학습을 진행하였다. 이 논문에서는 마지막 layer의 lr을 작게 해야 network의 수렴에 도움이 된다고 하고있다.
Training을 위해서 input으로는 ground-truth images를 random crop해서 사용하였다. 그리고 "Gaussian kernel"을 이용해 sub-image를 blur처리하였고, bicubic interpolation을 이용해 scale을 미리 업스케일링 시킨다.
그리고 모든 layer에는 padding을 사용하지 않았다.
Experiments
SR의 결과를 비교하기 위한 PSNR/SSIM 수치는 Y channel에서 측정되었다.
Training data
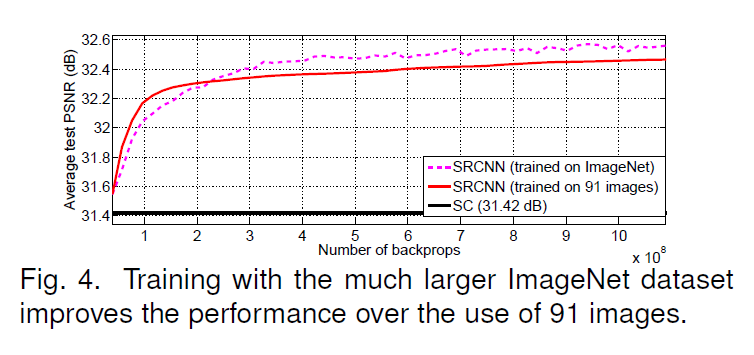
SRCNN은 training의 data에 따라 결과가 달라지기 때문에, 91장으로 이루어진 small training set과 395,909장으로 이루어진 large training set을 이용했다고 한다. 위의 이미지와 같이 large dataset을 사용할 수록 성능이 향상되었다고 한다.
Training sub image는 33X33 크기를 사용하였다고 한다.
첫 Layer의 filter size는 9, 두 번째 Layer의 filter size는 1, 마지막 Layer의 filter size는 5이다.
첫 Layer의 channel 수는 64, 두 번째 Layer의 channel 수는 32이다.
그리고, SRCNN은 validation을 위해 Set5와 Set14를 사용하였다.
Experiments on Color Channels
Color channels를 위해서 먼저 images를 YCbCr Channel로 바꾼 후, Cb,Cr Channels은 bicubic interpolation으로 upscaling을 진행하였고, Y채널만 SR algorithm을 적용하였다.


Review
가장 처음 Super-Resolution을 딥러닝으로 가장 간단하게 표현해낸 방법이다. Visual적인 결과나 수치적인 결과도 기존 Non deep-learning methods보다 좋았다.

참 좋은 글입니다.