1.벡터화
대량의 데이터를 학습시키는데 있어 for 문을 생략할 수 있게 해주는
벡터화
import numpy as np
a = np.array([1, 2, 3, 4])
print(a)
#결과
#[1 2 3 4]
import time
a = np.random.rand(1000000)
b = np.random.rand(1000000)
tic = time.time()
c = np.dot(a,b)
toc = time.time()
print('vectorized version:' + str(1000*(toc-tic) + 'ms')=
import time
a = np.random.rand(1000000)
b = np.random.rand(1000000)
tic = time.time()
c = np.dot(a,b)
toc = time.time()
print('vectorized version:' + str(1000*(toc-tic) + 'ms')
#non vectorized 와의 시간 비교
c = 0
tic = time.time()
for i in range(1000000):
c += a[i]*b[i]
toc = time.time()
print('for loop :' + str(10000*(toc-tic) + 'ms')결과를 확인하면 벡터화를 통해 얼마나 시간을 아낄 수 있는지 확인 가능
SIMD(Single Instruction Multiple Data)는 병렬 프로세서의 한 종류로, 하나의 명령어로 여러 개의 값을 동시에 계산하는 방식입니다. 이는 벡터화 연산을 가능하게 합니다. 따라서 for문으로 하나의 값을 연산하는 것 보다 벡터로 만들어서 한번에 연산하는 것이 더 효율적입니다.
가능한 for 문을 쓰지 않는 것이 좋다.
u = np.zeros((n,1))
for i in range(n):
u[i] = math.exp(v[i])
보다는
import numpy as np
u = np.exp(v)np를 통해 for 문을 제거해 훈련 데이터의 코드를 간소화
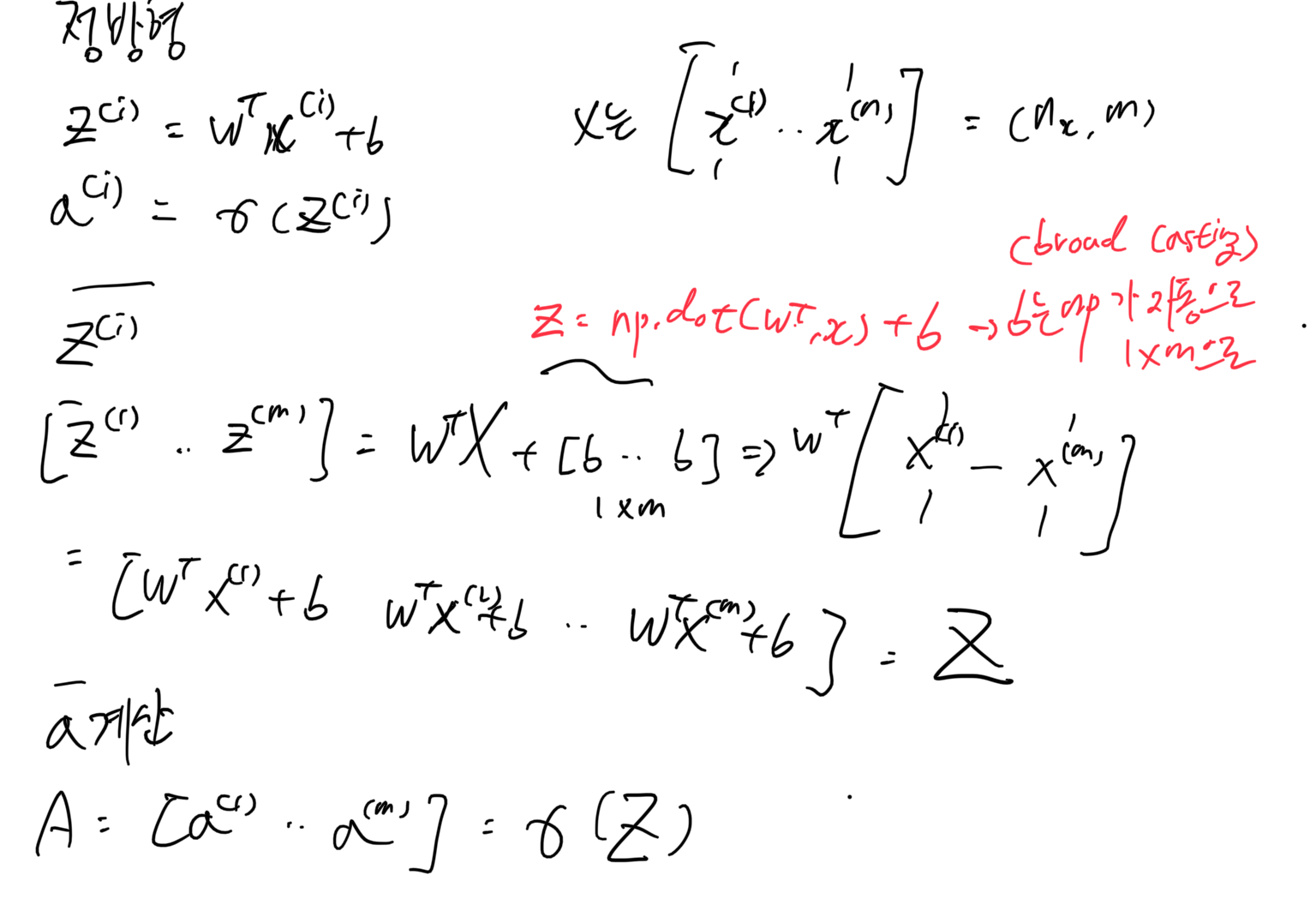
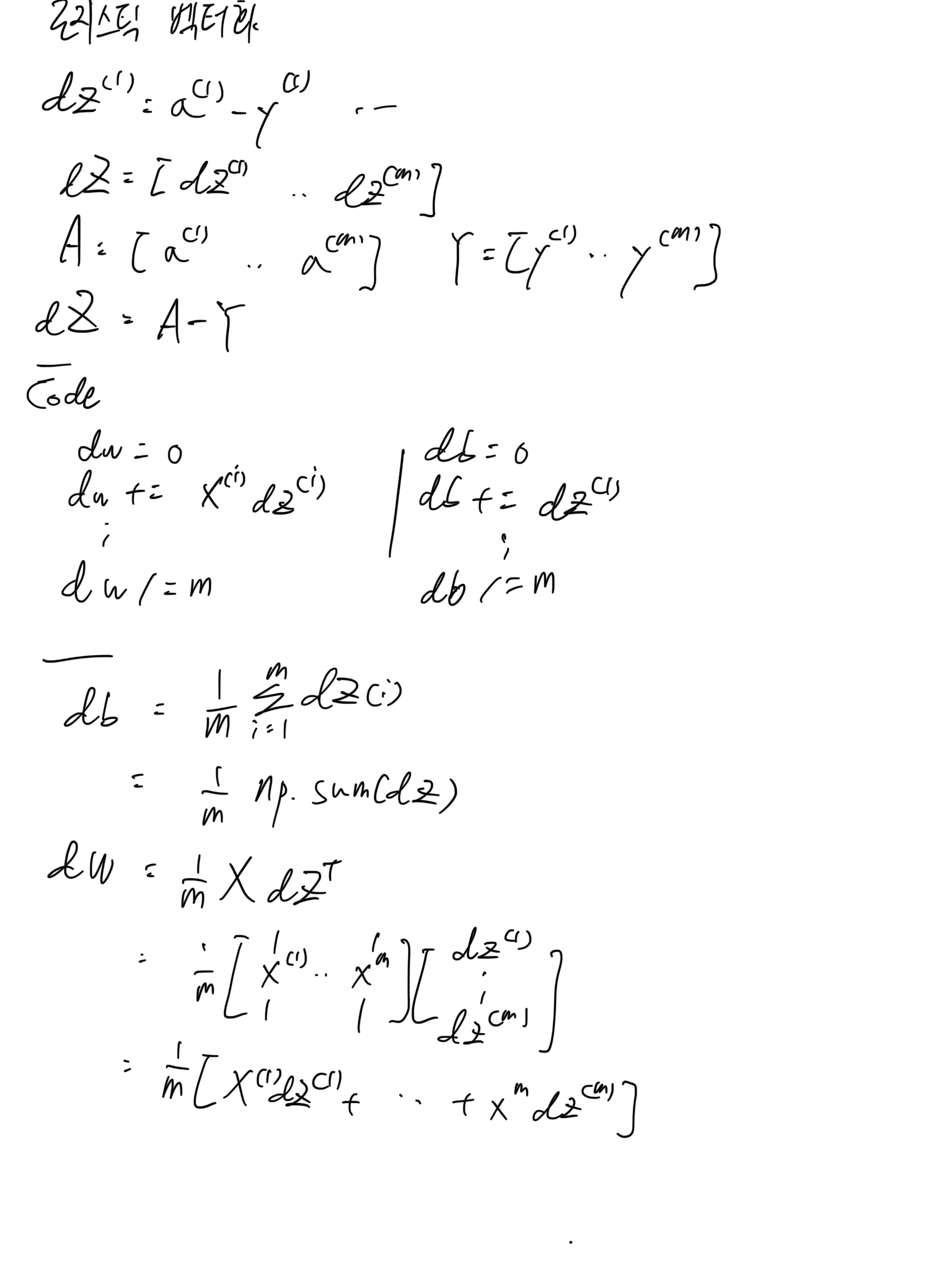
이런 효율성은 BroadCasting에서 나타남.
import numpy as np
A = np.array([56, 0, 4.4, 68],
[1.2, 104, 52, 8],
[1.8, 135, 99, 0.9])
#일 때 각 사과, 소고기,계란, 감자의 탄수,단백,지방의 칼로리이고
#각 음식의 칼로리 비중 계산
#axis=0는 (4,3) 행렬에서 4를 합치고 3을 남김 즉 열 단위
cal = A.sum(axis=0)
print(cal)
percentage = 100*A/cal.reshape(1,4)
print(percentage)
(m,n) 과 (1,n)or(m,1)을 연산하면 파이썬은 자동으로 뒤 행렬을 복사해 (m,n)행렬로 만들어 연산처리 해준다.
- numpy
코드 실습
import numpy as np
a = np.random.randn(5)
print(a)
print(a.shape)
#(5,) = 행벡터도 열벡터도 아니다. 랭크 1 배열
print(a.T)
#따라서 전치를 해도 같은 값이 낭옴
print(np.dot(a,a.t))
#는 외적인 행렬이 아니라 하나의 값이 나온다.
#따라서 (n,)식의 값은 사용하지 않는게 좋다.
a = np.random.randn(5,1)
#이때는 행렬로 나타남
print(np.dot(a,a.t))
#외적
#벡터를 확실히 하기 위해 assert 사용도 가능
assert(a.shape == (5,1))
- 로지스틱 회귀의 비용함수


데이터 사이언스를 공부하는 커피쟁이