B877031 장성환 데이터 전처리
노이즈처리
데이터별 노이즈
- 측정된 변수에 무작위의 오류 또는 분산이 존재하는 것.
정형 데이터에서의 노이즈
분산(Variance)로 나타남.
통계 모형에서는 오차항으로 나타남
이미지/영상 데이터에서의 노이즈
blur, white noise, pink noise, Gausian noise 등 다양한 형태로 나타남
시계열/음성/신호데이터의 노이즈
백색잡음 또는 가우시안 잡음으로 나타남
텍스트 데이터의 노이즈
철자오류, 약어, 비표준 단어, 반복 등
자동 음성 인식, 광학 문자 인식, 기계번역, Web Scraping 등으로 수집한 데이터에서 주로 발견
Defact vs. Fault vs. Artifact vs. Noise
Defact
전체 데이터에 존재하는 일부 오류(error)데이터
이상치가 아닌 잘못된 데이터
주로 생산이나 제조분야에서 사용하는 용어
Defact가 제품/설비의 기능에 손상을 야기하면 제품/설비가 Fault(불량/기능이상)이 됨
Artifact
Defact와 동일한 의미
주로 과학기술 분야에서 사용
Noise
일반적으로 그 원인을 알 수 없는 무작위 변동을 의미
주로 신호처리 (signal processing) 분야에서 사용하는 용어임
디노이징
데이터에서 노이즈를 저감하여 모형이 더 좋은 성능을 내도록 하는 전처리 과정
정형 데이터의 디노이징
구간화
정렬된 데이터 값들을 몇 개의 bin(혹은 bucket)으로 분할하여 대표값으로 대체
군집화
유사한 값들을 하나의 군집으로 처리하여 중심점을 대표값으로 대체
1. 동일 간격 구간화 -> pandas의 cut()사용
2. 동일 빈도 -> 동일한 개수의 데이터를 가지는 구간으로 설정
구간별 대표값 설정방법
- 평균값 평활화 : bin에 있는 값들을 평균값으로 대체
- 중앙값 평활화 : 중앙값으로 대체
- 경계값 평활화 : 경계값 중 가까운 값으로 대체
numpy 랜덤 사용법
균등분포로 부터 무작위 표본 추출
np.random.uniform(최솟값, 최댓값, 데이터 개수)
정규분포로 부터 무작위 표본 추출
np.random.normal(평균, 표준편차, 데이터 개수)
이항분포
np.random.binomial(경우의 수, 확률, 데이터 개수)
감마분포
np.random.binomial(shape, scale=1.0, 데이터 개수)
import pandas as pd
import numpy as np
df = pd.DataFrame({'uniform': np.sort(np.random.uniform(0,10,10)), #균등분포
'normal': np.sort(np.random.normal(3,2.5,10)), #감마분포
'gamma': np.sort(np.random.gamma(2, size=10)),
'binomial': np.sort(np.random.binomial(1,0.5,10))})#이항분포
df.plot(kind='hist', bins=15, alpha=0.5)
df.describe()
Pandas로 구간화
cut() : 같은 길이로 구간 나누기
qcut() : 같은 갯수로 구간 나누기
# cut(), qcut() 사용법
col = 'uniform'
num_bins = 5
df_binned = pd.DataFrame()
df_binned[col] = df[col].sort_values() # 원 데이터
df_binned['eq_dist_auto'] = pd.cut(df_binned[col], num_bins) # cut 동일간격
df_binned['eq_dist_fixed'] = pd.cut(df_binned[col], bins=[0,2,4,6,8,10]) # cut 지정 구간
df_binned['eq_freq_auto'] = pd.qcut(df_binned[col], num_bins) # 동일 빈도
df_binned| uniform | cut 동일간격 | cut 지정 구간 | 동일 빈도 |
|---|---|---|---|
| 0 | 1.458509 | (1.45, 3.09] | (0, 2] |
| 1 | 1.876997 | (1.45, 3.09] | (0, 2] |
| 2 | 2.086896 | (1.45, 3.09] | (2, 4] |
| 3 | 2.653401 | (1.45, 3.09] | (2, 4] |
| 4 | 3.706276 | (3.09, 4.722] | (2, 4] |
| 5 | 3.752690 | (3.09, 4.722] | (2, 4] |
| 6 | 5.675149 | (4.722, 6.354] | (4, 6] |
| 7 | 6.724354 | (6.354, 7.986] | (6, 8] |
| 8 | 6.886010 | (6.354, 7.986] | (6, 8] |
| 9 | 9.617634 | (7.986, 9.618] | (8, 10] |
cols = ['uniform', 'normal', 'gamma']
# cut 동일간격 구간화
df_ew = df.copy()
for col in cols:
df_ew[col+'_eq_dist'] = pd.cut(df_ew[col], 3)
means = df_ew.groupby(col+'_eq_dist')[col].mean()
df_ew.replace({col+'_eq_dist': means}, inplace=True)
display(df_ew)
# 동일 빈도 구간화
df_ef = df.copy()
for col in cols:
df_ef[col+'_eq_freq'] = pd.qcut(df_ef[col], 3)
means = df_ef.groupby(col+'_eq_freq')[col].mean()
df_ef.replace({col+'_eq_freq': means}, inplace=True)
display(df_ef)
# 시각화
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(10,5))
df_ew.astype(float).plot(ax=axes[0])
df_ef.astype(float).plot(ax=axes[1])
plt.show()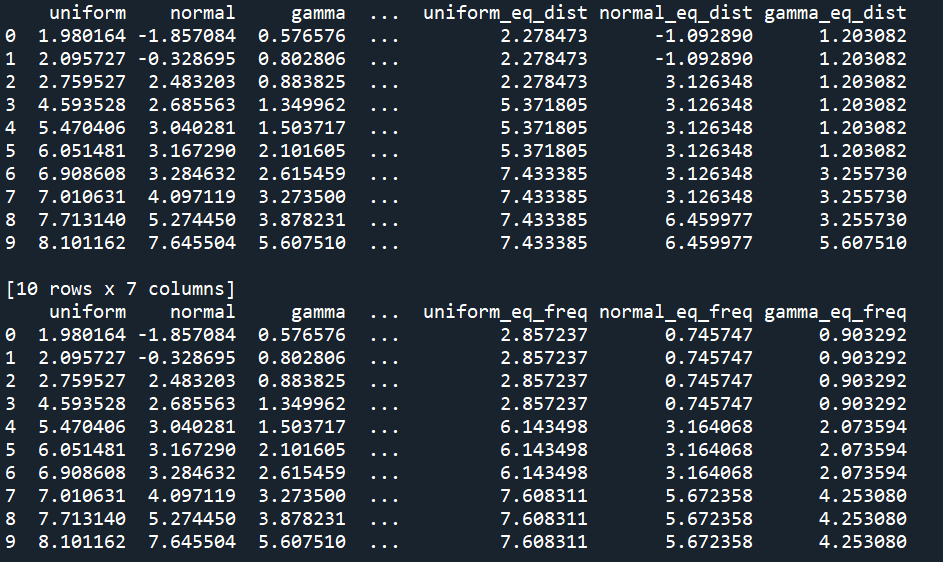
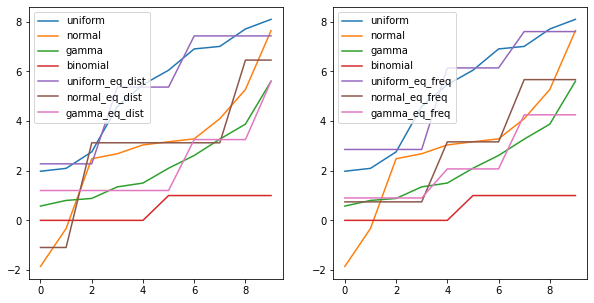
군집화(clustering)
Scikit-Learn으로 구간화
- KBinsDiscretizer() 사용
python
import warnings
warnings.filterwarnings("ignore")
from sklearn.preprocessing import KBinsDiscretizer
# 동일 간격 strategy='uniform'
ed_binner = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform', subsample=None)
df_ed = ed_binner.fit_transform(df)
# 동일 빈도 strategy='quantile'
ef_binner = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='quantile', subsample=None)
df_ef = ef_binner.fit_transform(df)
# KMeans 클러스터링 strategy='kmeans'
km_binner = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='kmeans', subsample=None)
df_km = km_binner.fit_transform(df)
df_ed = pd.DataFrame(df_ed, columns=df.columns+'_eq_dist')
df_ef = pd.DataFrame(df_ef, columns=df.columns+'_eq_freq')
df_km = pd.DataFrame(df_km, columns=df.columns+'_km')
df_bin = pd.concat([df, df_ed, df_ef, df_km], axis=1)
print(df_bin)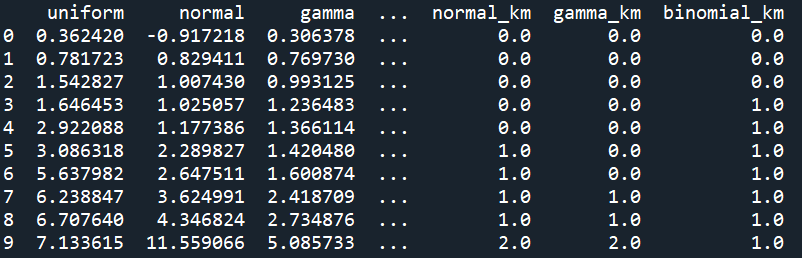 ```
```
코드를 입력하세요
for bin_col in df_bin.columns:
col = bin_col.split('_')[0]
means = df_bin.groupby(by=bin_col)[col].mean() # 구간별 평균값 계산
df_bin.replace({bin_col: means}, inplace=True) # 평균값 대체
df_bin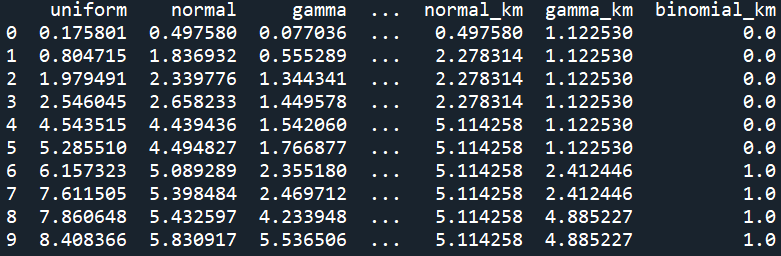
python
#그래프
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 3, figsize=(15,5))
pd.concat([df_bin.iloc[:,:3], df_bin.iloc[:,3:6]], axis=1).astype(float).plot(ax=axes[0])
pd.concat([df_bin.iloc[:,:3], df_bin.iloc[:,6:9]], axis=1).astype(float).plot(ax=axes[1])
pd.concat([df_bin.iloc[:,:3], df_bin.iloc[:,9:]], axis=1).astype(float).plot(ax=axes[2])
plt.show()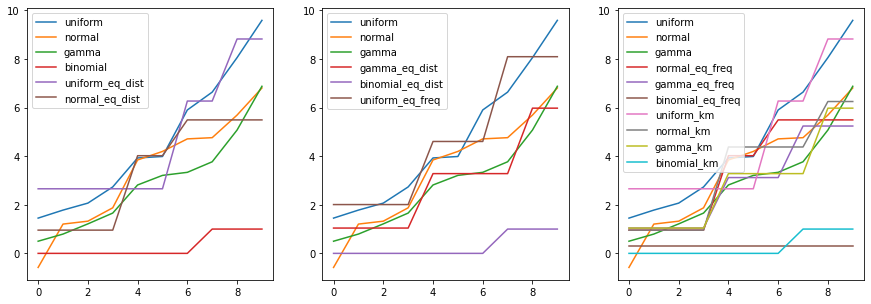
응용 (개인 공부)
df = pd.DataFrame({'uniform': np.sort(np.random.uniform(0,10,10))})
df_binned = pd.DataFrame()
df_binned['uniform'] = df['uniform'].sort_values() # 원 데이터
df_binned['동일간격'] = pd.cut(df_binned['uniform'], 10)
df_binned['지정된 구간'] = pd.cut(df_binned['uniform'], bins=[0,1,2,3,4,5,6,7,8,9,10])
df_binned['동일 빈도'] = pd.qcut(df_binned['uniform'], 10)
print(df_binned)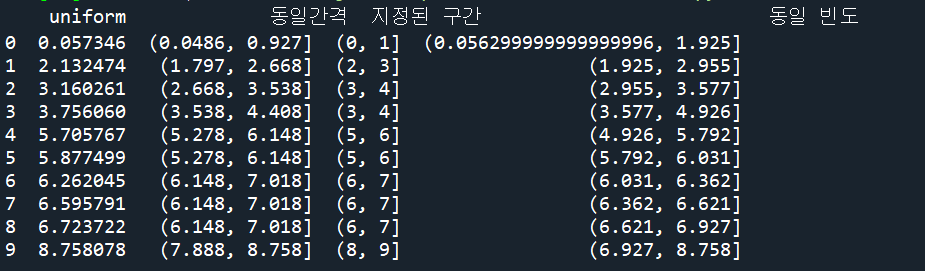
구간화 연습
#동일간격 구간화
df_ew = df.copy()
df_ew[u+'동일간격 구간화'] = pd.cut(df_ew[u], 5)
means = df_ew.groupby(u+'동일간격 구간화')[u].mean()
df_ew.replace({u+'동일간격 구간화': means}, inplace=True)
display(df_ew)
import matplotlib.pyplot as plt
plt.rc('font', family='Malgun Gothic')
fig, axes = plt.subplots(1, 2, figsize=(10,5))
df_ew.astype(float).plot(ax=axes[0])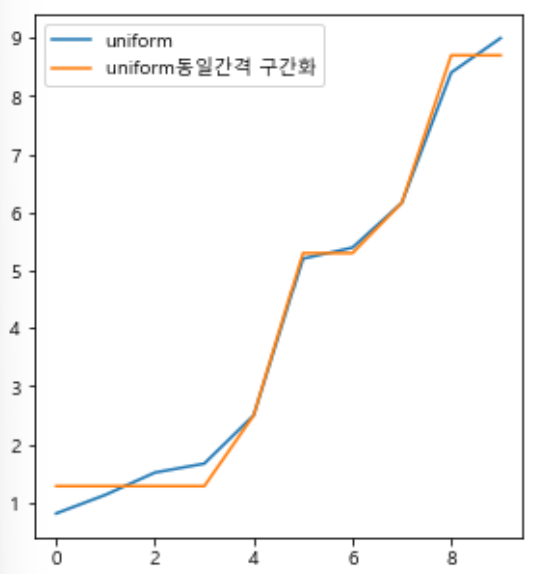
군집화 연습
from sklearn.preprocessing import KBinsDiscretizer
ed_binner = KBinsDiscretizer(n_bins=10, encode='ordinal', strategy='uniform', subsample=None)
df_ed = ed_binner.fit_transform(df)
df_ed = pd.DataFrame(df_ed, columns=df.columns+'동일간격 군집화')
fig, axes = plt.subplots(1, 3, figsize=(15,5))
pd.concat([df_ed.iloc[:,:3], df_ed.iloc[:,3:6]], axis=1).astype(float).plot(ax=axes[0])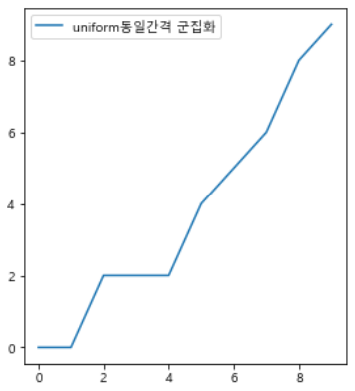
스케일링
Scikit-Learn
python을 대표하는 머신러닝 라이브러리.
다양한 전처리 도구와 알고리즘 제공, 직관적인 API
주요기능 : 분류, 회귀, 군집화, 차원 축소, 전처리
Scikit-Learn Preprocessing
Scikit-Learn의 전처리 기능은 크게 4가지다.
스케일링 : 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 것
이진화 : 연속적인 값을 0또는 1로 나누는 것, 연속형 변수 -> 이진형 변수
인코딩 : 범주형 값을 적절한 숫자형으로 변환하는 작업, 범주형 변수 -> 수치형 변수
변환 : 데이터 분포를 변환하여 정규성 확보
스케일링 (Scaling)
독립변수(feature)별로 값의 변위가 상이하다면, 종속변수(target)에 대한 영향이 독립변수의 변위에 따라 크게 달라진다. -> 머신러닝시 학습효과가 떨어진다.
스케일링을 통해서 최적화 과정에서의 안정성 및 수렴 속도를 향상시킨다.
*특히 k-means 등 거리기반 모델에선 스케일링이 매우 중요하다.
표준화
표준분포화 : 평균을 0, 분산을 1로 스케일링
- StandardScaler(): 기본 스케일러, 평균과 표준편차 사용
- RobustScaler(): 중앙값과 IQR(Q3-Q1)을 사용. 이상치의 영향을 최소화
정규화
규격화 : 특정 범위(주로 [0,1])로 스케일링.
- MinMaxScaler(): 범위가 [0,1]이 되도록 스케일링
- MaxAbsScaler(): 양수는 [0,1], 음수는 [-1,0], 양음수는 [-1,1]이 되도록 스케일링
변환
특정한 분포나 모양을 따르도록 스케일링
- PowerTransformer(): 정규분포화(Box-Cox 변환, Yeo-Johnson 변환)
- QuantileTransformer(): 균일(Uniform)분포 또는 정규(Gaussian)분포로 변환
- Normalizer(): 한 행의 모든 피처들 사이의 유클리드 거리가 1이 되도록 변환
스케일링 절차
Scaler 객체를 이용
- fit() : 주어진 데이터에 맞추어 학습
- transform() Scaler 적용, fit()된 정보를 이용해 데이터 변환
- fit_transform() : fit()과 transform()을 한 번에 실행
표준화 (Standardization)
-> 표준화를 하면, 서로 다른 통계 데이터들을 비교하기 용이하다
seaborn에서 제공하는 penguins 데이터를 활용
import pandas as pd
import seaborn as sns
# Pandas 소수점 4째자리 이하에서 반올림
pd.set_option('display.float_format', lambda x: f'{x:.4f}')
# penguins 데이터 로드
penguins = sns.load_dataset('penguins')
print(penguins)
# penguins의 수치형 변수만 선택
penguins = penguins.select_dtypes(exclude='object')
# penguins의 기술통계량을 확인
penguins.describe()
# bill_length_mm와 flipper_length_mm의 jointplot을 그림
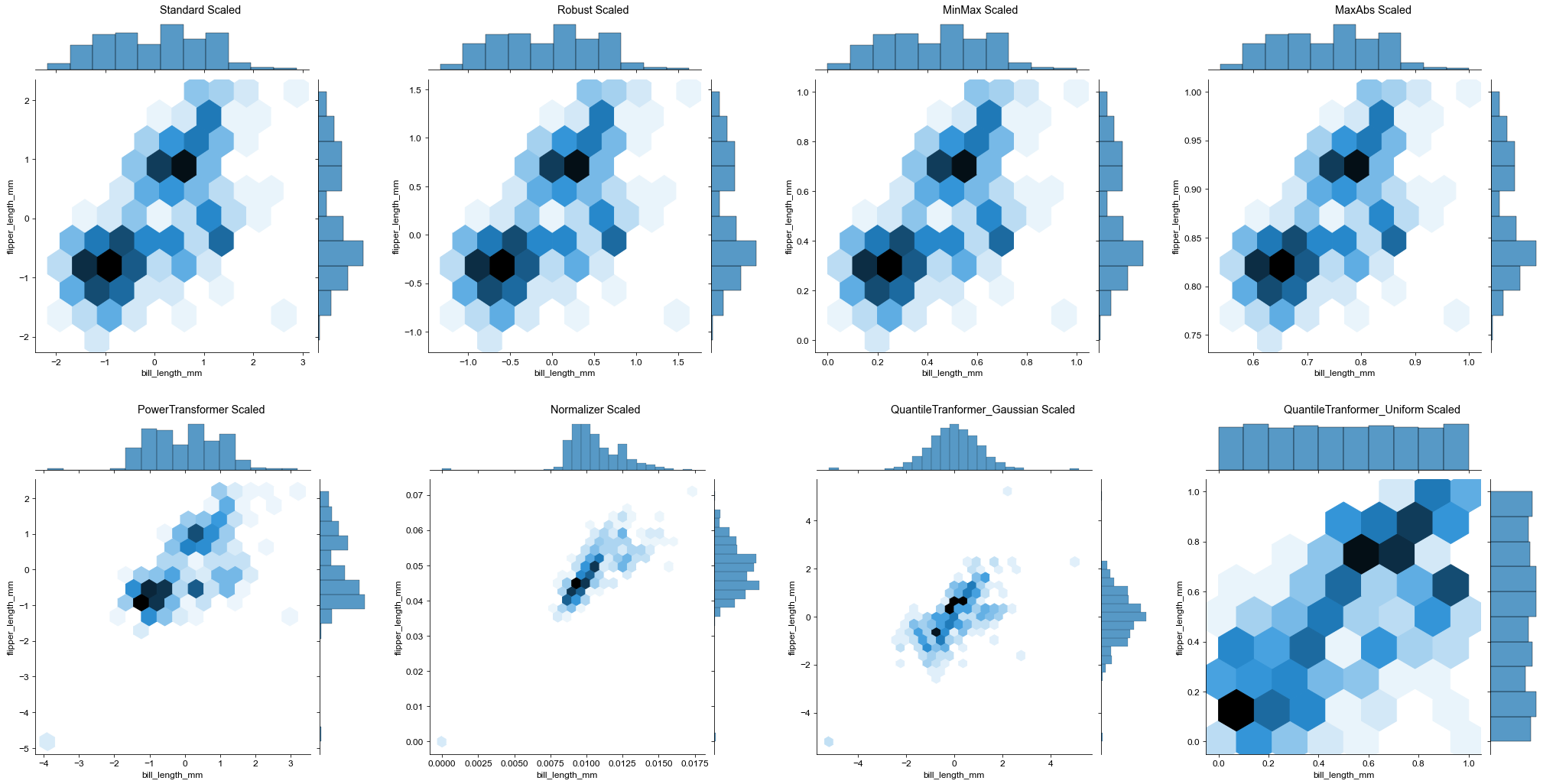
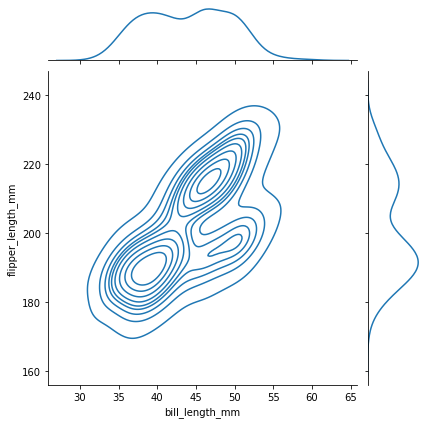
sns.jointplot(data=penguins, x='bill_length_mm', y='flipper_length_mm', kind='hex')#kind = kde, scatter 등... 다양한 그래프헥스빈 그래프
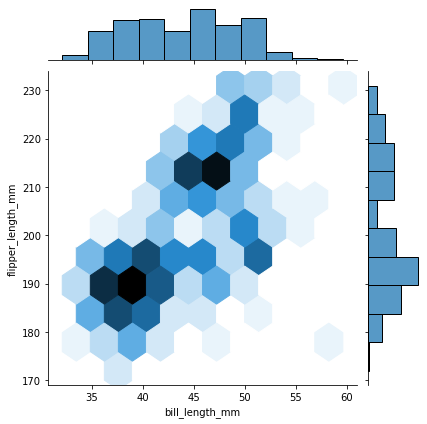
kde 그래프
from sklearn.preprocessing import StandardScaler, RobustScaler
# Scaler 객체 생성
standard_scaler = StandardScaler()
robust_scaler = RobustScaler()
# 데이터 변환
penguins_standard = pd.DataFrame(standard_scaler.fit_transform(penguins), columns=penguins.columns)
penguins_robust = pd.DataFrame(robust_scaler.fit_transform(penguins), columns=penguins.columns)
# 결과 출력
print('Standard Scaled: \n', penguins_standard.describe()) # mean = 0, std = 1
print()
print('Robust Scaled: \n', penguins_robust.describe()) # median = 0, IQR = 1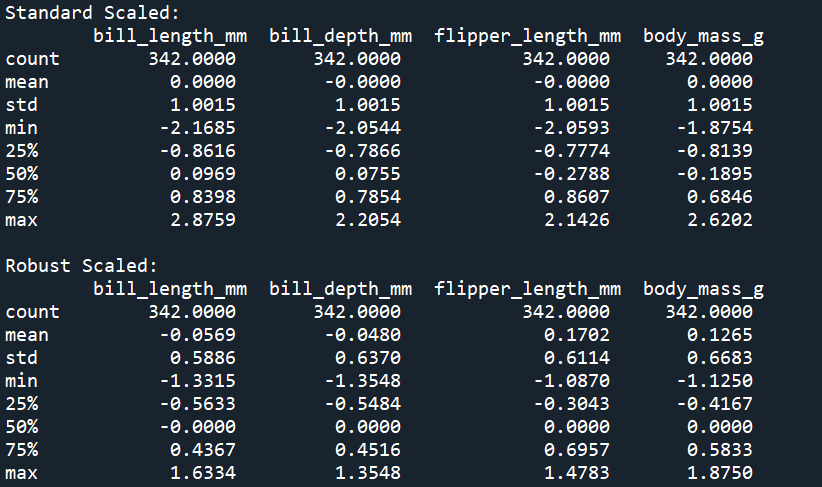
# penguins_standard
g1 = sns.jointplot(data=penguins_standard, x='bill_length_mm', y='flipper_length_mm', kind='hex')
g1 = pw.load_seaborngrid(g1)
g1.set_suptitle("Standard Scaled")
# penguins_robust
g2 = sns.jointplot(data=penguins_robust, x='bill_length_mm', y='flipper_length_mm', kind='hex')
g2 = pw.load_seaborngrid(g2)
g2.set_suptitle("Robust Scaled")
# 그래프 합치기
g12 = (g1|g2)
g12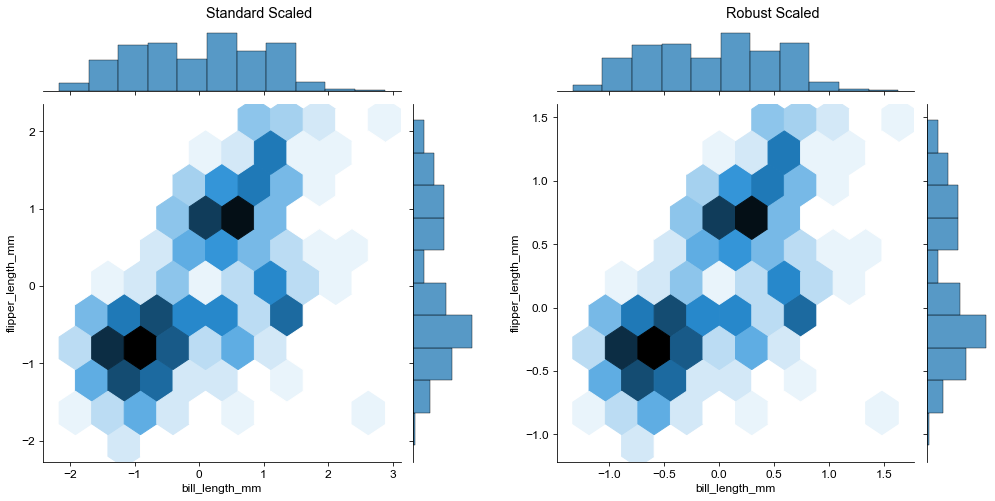
정규화
-MinMaxScaler(): 범위가 [0,1]이 되도록 스케일링
-MaxAbsScaler()
모든 값이 양수이면, 범위가 [0,1]이 되도록 스케일링, MinMaxScaler()와 유사
모든 값이 음수이면, 범위가 [-1,0]이 되도록 스케일링
양수와 음수가 혼재하면, 범위가 [-1,1]이 되도록 스케일링
from sklearn.preprocessing import MinMaxScaler, MaxAbsScaler
# Scaler 객체 생성
minmax_scaler = MinMaxScaler()
maxabs_scaler = MaxAbsScaler()
# 데이터 변환
penguins_minmax = pd.DataFrame(minmax_scaler.fit_transform(penguins), columns=penguins.columns)
penguins_maxabs = pd.DataFrame(maxabs_scaler.fit_transform(penguins), columns=penguins.columns)
# 결과 출력
print('MinMax Scaled: \n', penguins_minmax.describe()) # min = 0, max = 1
print()
print('MaxAbs Scaled: \n', penguins_maxabs.describe()) # min ~ 0, max = 1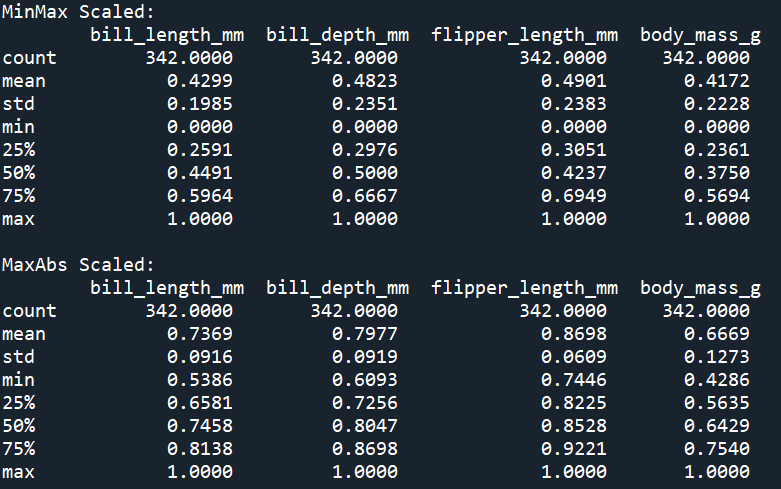
# 세번째 그래프
g3 = sns.jointplot(data=penguins_minmax, x='bill_length_mm', y='flipper_length_mm', kind='hex')
g3 = pw.load_seaborngrid(g3)
g3.set_suptitle("MinMax Scaled")
# 네번째 그래프
g4 = sns.jointplot(data=penguins_maxabs, x='bill_length_mm', y='flipper_length_mm', kind='hex')
g4 = pw.load_seaborngrid(g4)
g4.set_suptitle("MaxAbs Scaled")
# 그래프 합치기
g34 = (g3|g4)
g34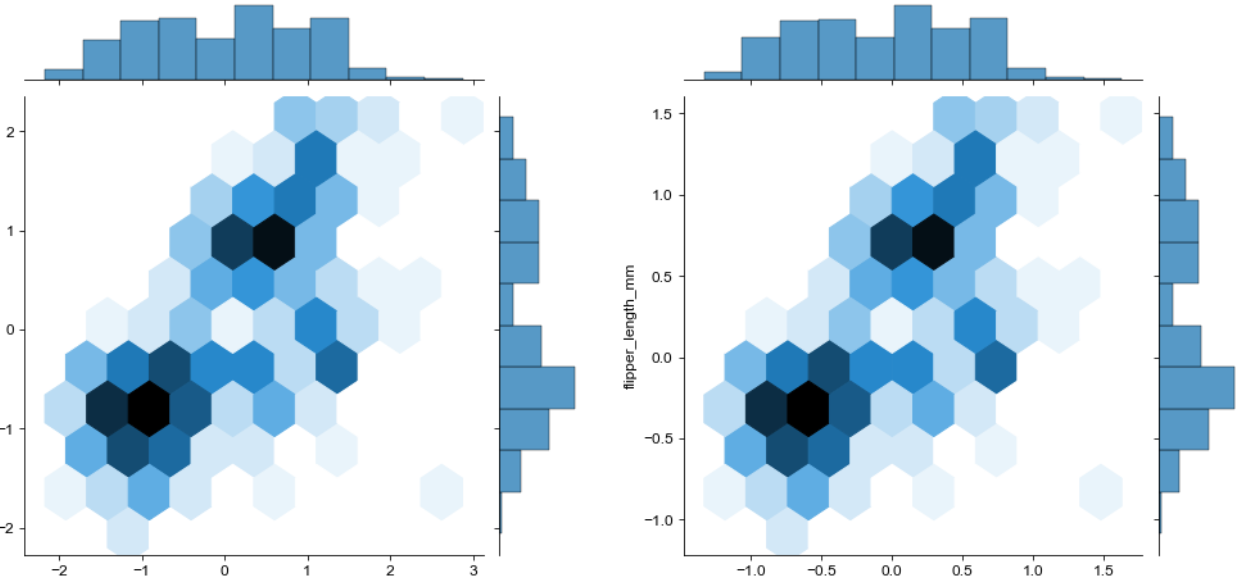
변환
PowerTransformer(): 정규성 변환(Box-Cox 변환, Yeo-Johnson 변환)
QuantileTransformer(): 균일(Uniform)분포 또는 정규(Gaussian)분포로 변환
Normalizer(): 한 행의 모든 피처들 사이의 유클리드 거리가 1이 되도록 변환
import numpy as np
from sklearn.preprocessing import PowerTransformer, Normalizer
# Scaler 객체 생성
power_scaler = PowerTransformer()
normal_scaler = Normalizer()
#결측치 오류 해결위해 0으로 대체
penguins = penguins.fillna(0)
# 데이터 변환
penguins_power = pd.DataFrame(power_scaler.fit_transform(penguins), columns=penguins.columns)
penguins_normal = pd.DataFrame(normal_scaler.fit_transform(penguins), columns=penguins.columns)
# 결과 출력
print('PowerTranformer Scaled: \n', penguins_power.describe()) # mean = 0, std = 1
print()
print('Normalizer Scaled: \n', penguins_normal.describe())
print('Euclidian Distance from 0: \n', np.linalg.norm(penguins_normal, axis=1)) # 각 행의 벡터 크기가 1이 되는지 확인
print('Euclidian Distance from 0: \n', np.linalg.norm(penguins_normal, axis=1)) # 각 행의 벡터 크기가 1이 되는지 확인
펭귄 데이터 세트에 결측치가 존재하는 오류가 발생하므로, 결측치를 0으로 대체.
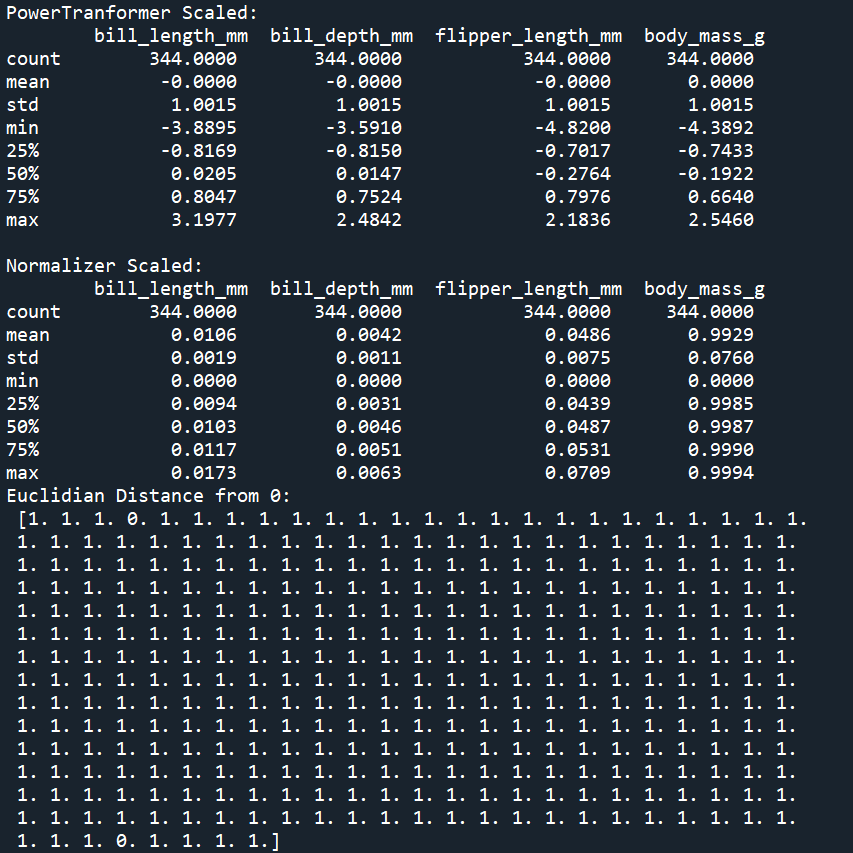
from sklearn.preprocessing import QuantileTransformer
# Scaler 객체 생성
gaussian_scaler = QuantileTransformer(output_distribution='normal')
uniform_scaler = QuantileTransformer(output_distribution='uniform')
# 데이터 변환
penguins_gaussian = pd.DataFrame(gaussian_scaler.fit_transform(penguins), columns=penguins.columns)
penguins_uniform = pd.DataFrame(uniform_scaler.fit_transform(penguins), columns=penguins.columns)
# 결과 출력
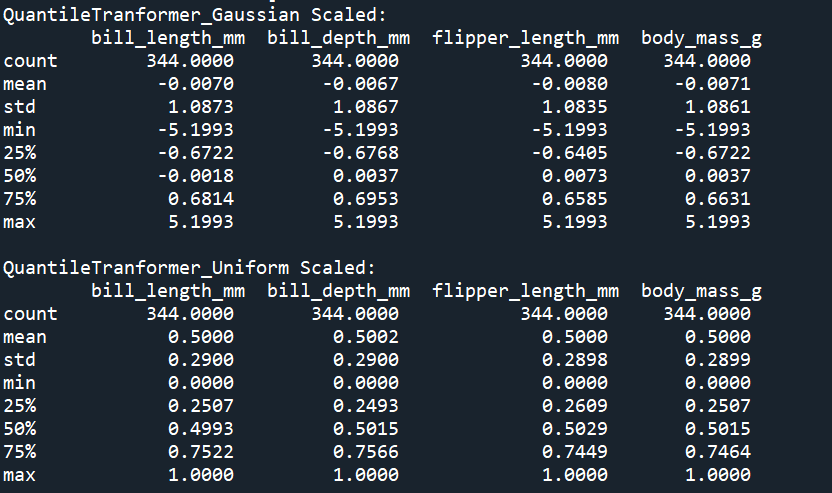
print('QuantileTranformer_Gaussian Scaled: \n', penguins_gaussian.describe())
print()
print('QuantileTranformer_Uniform Scaled: \n', penguins_uniform.describe())
# 일곱번째 그래프
g7 = sns.jointplot(data=penguins_gaussian, x='bill_length_mm', y='flipper_length_mm', kind='hex')
g7 = pw.load_seaborngrid(g7)
g7.set_suptitle("QuantileTranformer_Gaussian Scaled")
# 여덟번째 그래프
g8 = sns.jointplot(data=penguins_uniform,x='bill_length_mm', y='flipper_length_mm', kind='hex')
g8 = pw.load_seaborngrid(g8)
g8.set_suptitle("QuantileTranformer_Uniform Scaled")
# 그래프 합치기
g78 = (g7|g8)
g78
(g1|g2|g3|g4)/(g5|g6|g7|g8)