Scikit-Learn
python을 대표하는 머신러닝 라이브러리.
다양한 전처리 도구와 알고리즘 제공, 직관적인 API
주요기능 : 분류, 회귀, 군집화, 차원 축소, 전처리
Scikit-Learn Preprocessing
Scikit-Learn의 전처리 기능은 크게 4가지다.
스케일링 : 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 것
이진화 : 연속적인 값을 0또는 1로 나누는 것, 연속형 변수 -> 이진형 변수
인코딩 : 범주형 값을 적절한 숫자형으로 변환하는 작업, 범주형 변수 -> 수치형 변수
변환 : 데이터 분포를 변환하여 정규성 확보
스케일링 (Scaling)
독립변수(feature)별로 값의 변위가 상이하다면, 종속변수(target)에 대한 영향이 독립변수의 변위에 따라 크게 달라진다. -> 머신러닝시 학습효과가 떨어진다.
스케일링을 통해서 최적화 과정에서의 안정성 및 수렴 속도를 향상시킨다.
*특히 k-means 등 거리기반 모델에선 스케일링이 매우 중요하다.
표준화
표준분포화 : 평균을 0, 분산을 1로 스케일링
- StandardScaler(): 기본 스케일러, 평균과 표준편차 사용
- RobustScaler(): 중앙값과 IQR(Q3-Q1)을 사용. 이상치의 영향을 최소화
정규화
규격화 : 특정 범위(주로 [0,1])로 스케일링.
- MinMaxScaler(): 범위가 [0,1]이 되도록 스케일링
- MaxAbsScaler(): 양수는 [0,1], 음수는 [-1,0], 양음수는 [-1,1]이 되도록 스케일링
변환
특정한 분포나 모양을 따르도록 스케일링
- PowerTransformer(): 정규분포화(Box-Cox 변환, Yeo-Johnson 변환)
- QuantileTransformer(): 균일(Uniform)분포 또는 정규(Gaussian)분포로 변환
- Normalizer(): 한 행의 모든 피처들 사이의 유클리드 거리가 1이 되도록 변환
스케일링 절차
Scaler 객체를 이용
- fit() : 주어진 데이터에 맞추어 학습
- transform() Scaler 적용, fit()된 정보를 이용해 데이터 변환
- fit_transform() : fit()과 transform()을 한 번에 실행
표준화 (Standardization)
-> 표준화를 하면, 서로 다른 통계 데이터들을 비교하기 용이하다
seaborn에서 제공하는 penguins 데이터를 활용
import pandas as pd
import seaborn as sns
# Pandas 소수점 4째자리 이하에서 반올림
pd.set_option('display.float_format', lambda x: f'{x:.4f}')
# penguins 데이터 로드
penguins = sns.load_dataset('penguins')
print(penguins)
# penguins의 수치형 변수만 선택
penguins = penguins.select_dtypes(exclude='object')
# penguins의 기술통계량을 확인
penguins.describe()
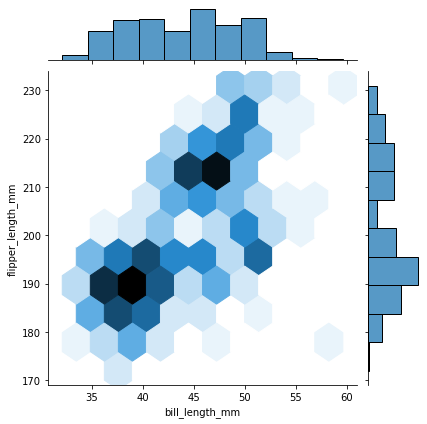
# bill_length_mm와 flipper_length_mm의 jointplot을 그림
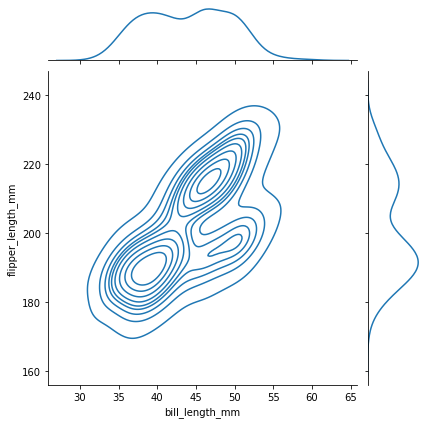
sns.jointplot(data=penguins, x='bill_length_mm', y='flipper_length_mm', kind='hex')#kind = kde, scatter 등... 다양한 그래프헥스빈 그래프
kde 그래프
from sklearn.preprocessing import StandardScaler, RobustScaler
# Scaler 객체 생성
standard_scaler = StandardScaler()
robust_scaler = RobustScaler()
# 데이터 변환
penguins_standard = pd.DataFrame(standard_scaler.fit_transform(penguins), columns=penguins.columns)
penguins_robust = pd.DataFrame(robust_scaler.fit_transform(penguins), columns=penguins.columns)
# 결과 출력
print('Standard Scaled: \n', penguins_standard.describe()) # mean = 0, std = 1
print()
print('Robust Scaled: \n', penguins_robust.describe()) # median = 0, IQR = 1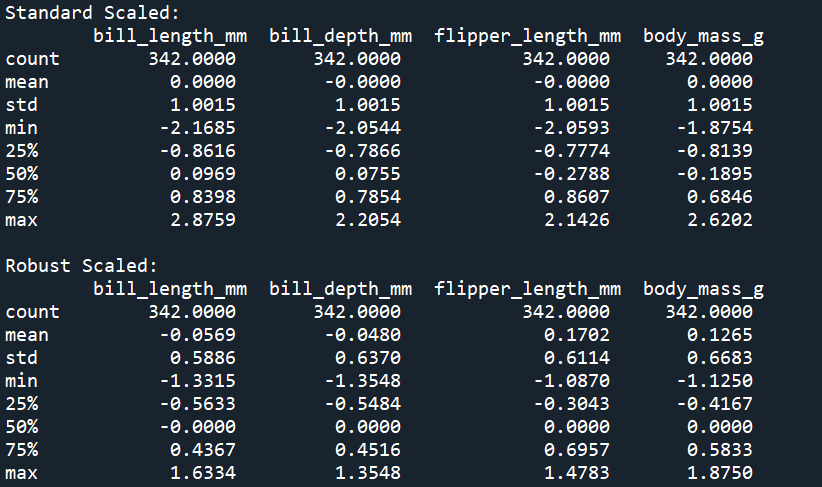
# penguins_standard
g1 = sns.jointplot(data=penguins_standard, x='bill_length_mm', y='flipper_length_mm', kind='hex')
g1 = pw.load_seaborngrid(g1)
g1.set_suptitle("Standard Scaled")
# penguins_robust
g2 = sns.jointplot(data=penguins_robust, x='bill_length_mm', y='flipper_length_mm', kind='hex')
g2 = pw.load_seaborngrid(g2)
g2.set_suptitle("Robust Scaled")
# 그래프 합치기
g12 = (g1|g2)
g12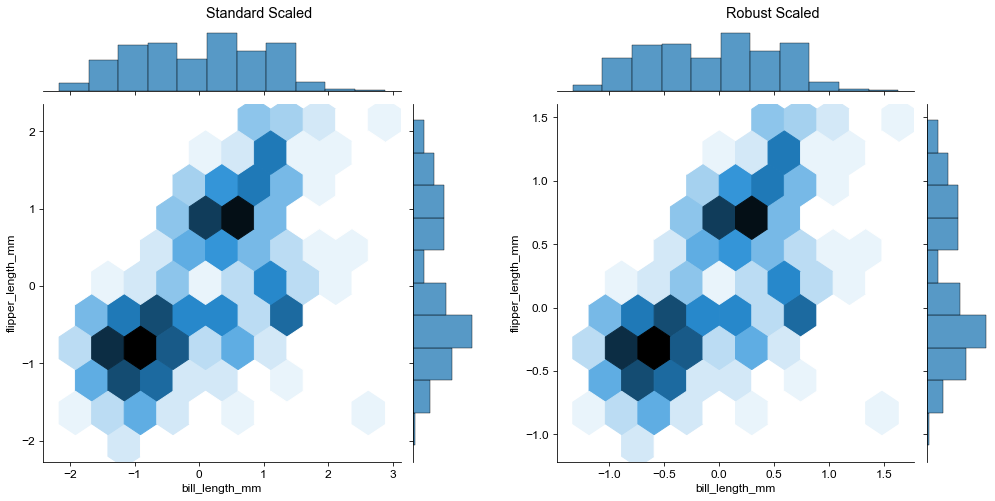
정규화
-MinMaxScaler(): 범위가 [0,1]이 되도록 스케일링
-MaxAbsScaler()
모든 값이 양수이면, 범위가 [0,1]이 되도록 스케일링, MinMaxScaler()와 유사
모든 값이 음수이면, 범위가 [-1,0]이 되도록 스케일링
양수와 음수가 혼재하면, 범위가 [-1,1]이 되도록 스케일링
from sklearn.preprocessing import MinMaxScaler, MaxAbsScaler
# Scaler 객체 생성
minmax_scaler = MinMaxScaler()
maxabs_scaler = MaxAbsScaler()
# 데이터 변환
penguins_minmax = pd.DataFrame(minmax_scaler.fit_transform(penguins), columns=penguins.columns)
penguins_maxabs = pd.DataFrame(maxabs_scaler.fit_transform(penguins), columns=penguins.columns)
# 결과 출력
print('MinMax Scaled: \n', penguins_minmax.describe()) # min = 0, max = 1
print()
print('MaxAbs Scaled: \n', penguins_maxabs.describe()) # min ~ 0, max = 1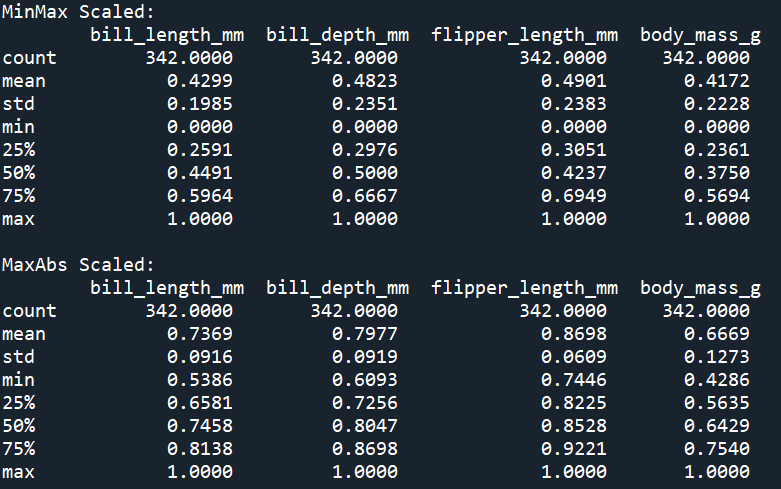
# 세번째 그래프
g3 = sns.jointplot(data=penguins_minmax, x='bill_length_mm', y='flipper_length_mm', kind='hex')
g3 = pw.load_seaborngrid(g3)
g3.set_suptitle("MinMax Scaled")
# 네번째 그래프
g4 = sns.jointplot(data=penguins_maxabs, x='bill_length_mm', y='flipper_length_mm', kind='hex')
g4 = pw.load_seaborngrid(g4)
g4.set_suptitle("MaxAbs Scaled")
# 그래프 합치기
g34 = (g3|g4)
g34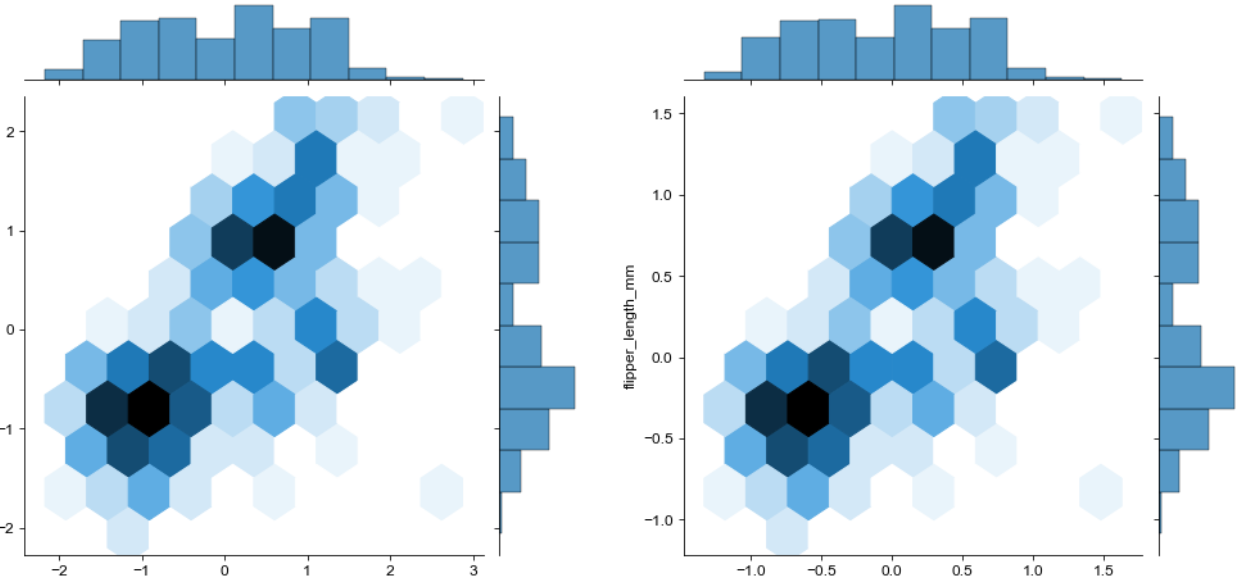
변환
PowerTransformer(): 정규성 변환(Box-Cox 변환, Yeo-Johnson 변환)
QuantileTransformer(): 균일(Uniform)분포 또는 정규(Gaussian)분포로 변환
Normalizer(): 한 행의 모든 피처들 사이의 유클리드 거리가 1이 되도록 변환
import numpy as np
from sklearn.preprocessing import PowerTransformer, Normalizer
# Scaler 객체 생성
power_scaler = PowerTransformer()
normal_scaler = Normalizer()
#결측치 오류 해결위해 0으로 대체
penguins = penguins.fillna(0)
# 데이터 변환
penguins_power = pd.DataFrame(power_scaler.fit_transform(penguins), columns=penguins.columns)
penguins_normal = pd.DataFrame(normal_scaler.fit_transform(penguins), columns=penguins.columns)
# 결과 출력
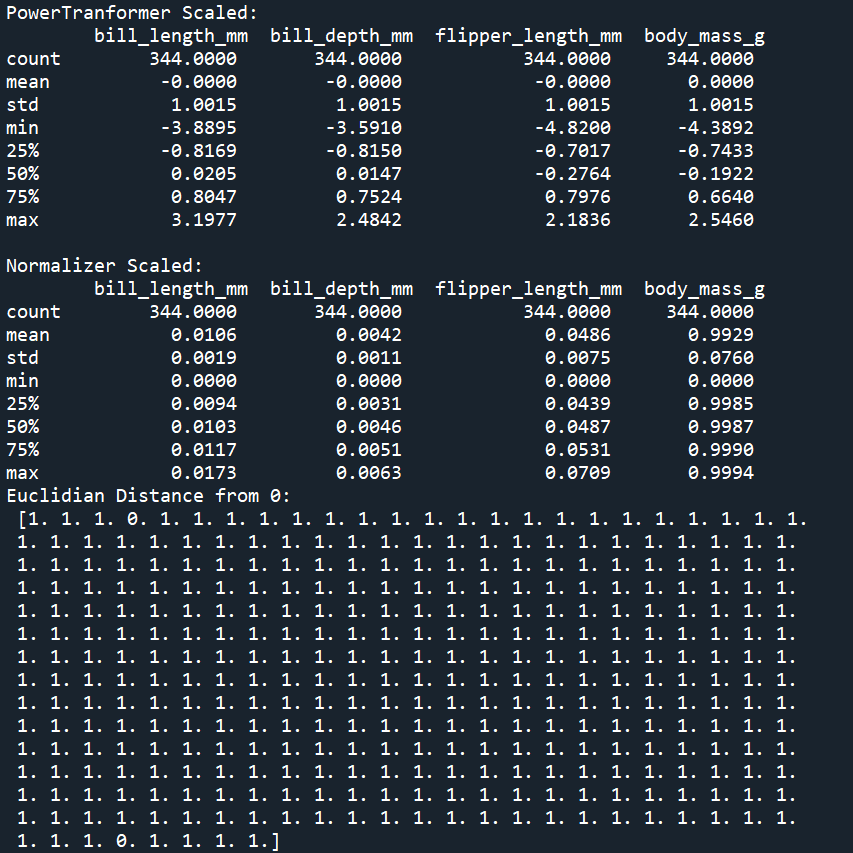
print('PowerTranformer Scaled: \n', penguins_power.describe()) # mean = 0, std = 1
print()
print('Normalizer Scaled: \n', penguins_normal.describe())
print('Euclidian Distance from 0: \n', np.linalg.norm(penguins_normal, axis=1)) # 각 행의 벡터 크기가 1이 되는지 확인
print('Euclidian Distance from 0: \n', np.linalg.norm(penguins_normal, axis=1)) # 각 행의 벡터 크기가 1이 되는지 확인
from sklearn.preprocessing import QuantileTransformer
# Scaler 객체 생성
gaussian_scaler = QuantileTransformer(output_distribution='normal')
uniform_scaler = QuantileTransformer(output_distribution='uniform')
# 데이터 변환
penguins_gaussian = pd.DataFrame(gaussian_scaler.fit_transform(penguins), columns=penguins.columns)
penguins_uniform = pd.DataFrame(uniform_scaler.fit_transform(penguins), columns=penguins.columns)
# 결과 출력
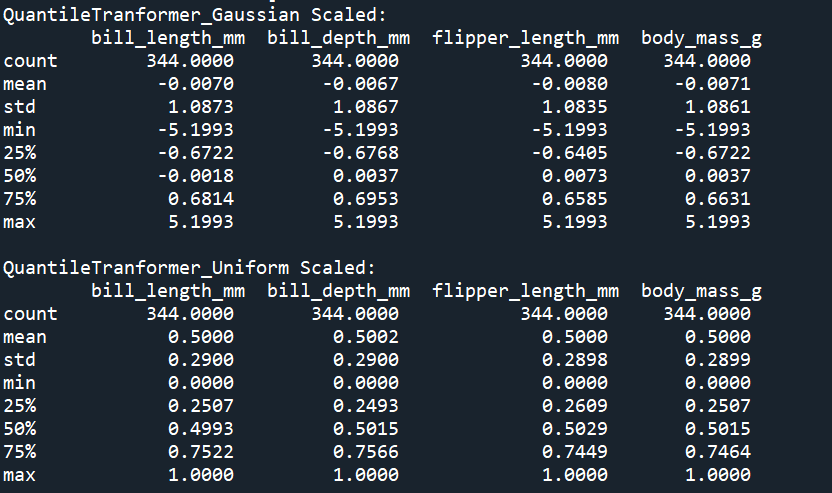
print('QuantileTranformer_Gaussian Scaled: \n', penguins_gaussian.describe())
print()
print('QuantileTranformer_Uniform Scaled: \n', penguins_uniform.describe())
# 일곱번째 그래프
g7 = sns.jointplot(data=penguins_gaussian, x='bill_length_mm', y='flipper_length_mm', kind='hex')
g7 = pw.load_seaborngrid(g7)
g7.set_suptitle("QuantileTranformer_Gaussian Scaled")
# 여덟번째 그래프
g8 = sns.jointplot(data=penguins_uniform,x='bill_length_mm', y='flipper_length_mm', kind='hex')
g8 = pw.load_seaborngrid(g8)
g8.set_suptitle("QuantileTranformer_Uniform Scaled")
# 그래프 합치기
g78 = (g7|g8)
g78
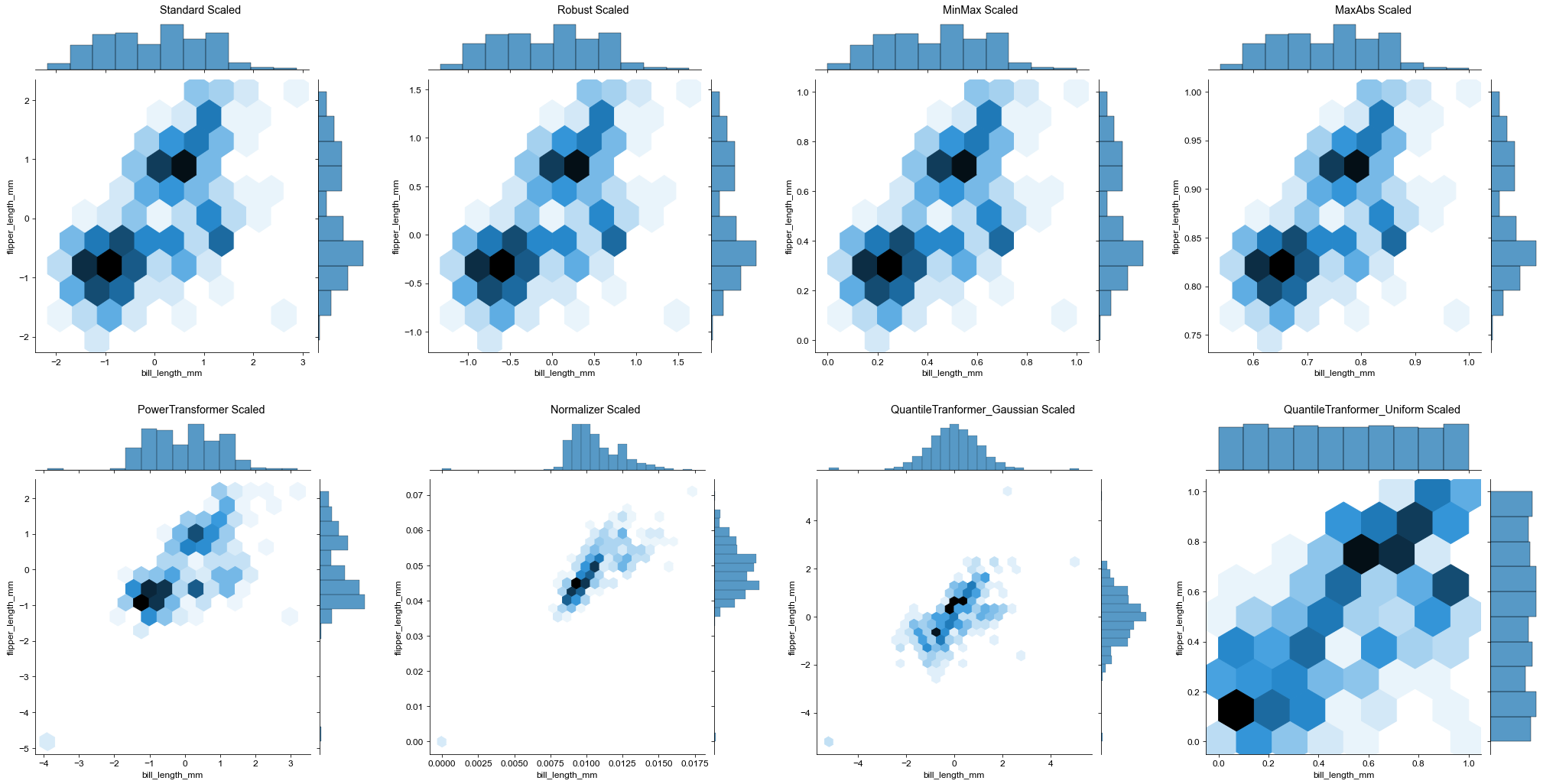
(g1|g2|g3|g4)/(g5|g6|g7|g8)