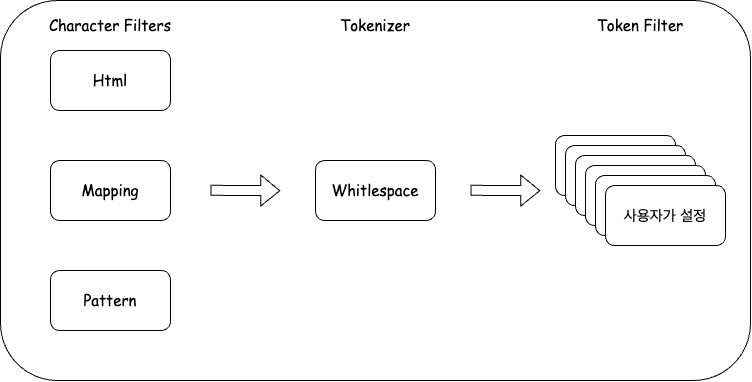
두개의 Tokenizer 사용법
검색의 퀄리티를 높이거나 다양한 요구사항들을 만족시키기 위해서는 한 항목에 tokenizer을 여러개가 필요할 때가 있다.
하지만 tokenizer를 보면 하나의 tokenizer만 적용이 가능하다.
그래서 나는 copyto 방법으로 하나의 mapping을 더 만들어 적용시키는 방법을 활용하였다.
copy_to 방법이란?
문서의 여러 필드 값을 하나의 필드에 결합할 수 있는 기능을 제공하는 중요한 기능입니다. 이 기능은 특정 필드의 내용과 다른 필드의 내용을 합쳐서 검색할 때 사용할 수 있습니다.
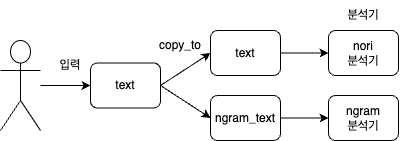
PUT /copy_to_test_index { "settings": { "analysis": { "tokenizer": { "ngram_tokenizer": { "type": "ngram", "min_gram": 2, "max_gram": 2, "token_chars": [ "letter", "digit" ] }, "nori_tokenizer": { "type": "nori_tokenizer" } }, "analyzer": { "ngram_analyzer": { "type": "custom", "tokenizer": "ngram_tokenizer" }, "nori_analyzer": { "type": "custom", "tokenizer": "nori_tokenizer" } } } }, "mappings": { "properties": { "text": { "type": "text", "copy_to": "nagram_text", "analyzer": "nori_analyzer" }, "ngram_text": { "type": "text", "analyzer": "ngram_analyzer" } } } }예시를 보시면 text란 항목과 text를 복사해 ngram_text를 만들고 각각 다른 analyzer를 적용시켰습니다.
이렇게 적용하면 text만 입력하면 알아서 ngram의 내용까지 들어갑니다.
예시는 사용자가 입력하면 copy_to를 통해 두가지를 만들고 각각의 분석기로 적용시키는 방식입니다.
copy_to는 이렇게만 사용하는 걸까?
아니다 보통은 여러개의 항목을 하나로 합쳐서 사용할 때 이용한다.
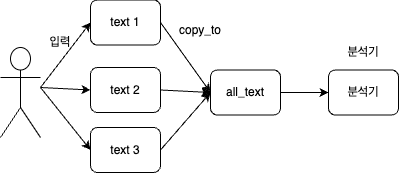
PUT basic_copy_to_test_index { "mappings": { "properties": { "text1": { "type": "keyword", "copy_to": "all_text" }, "text2": { "type": "keyword", "copy_to": "all_text" }, "text3": { "type": "keyword", "copy_to": "all_text" }, "all_text":{ "type": "keyword" } } } }이렇게 text1, text2, text3을 하나의 all_text로 묶어 사용
예시처럼 사용자가 입력한 내용을 all_text로 묶어서 하나의 분석기로 처리
이렇게 사용하면 나중에 검색할 때도 all_text내용만을 통해 분석 가능
정리
copy_to를 이용해서 내가 입력 받은 내용을 나눌 수도 있고 합칠 수도 있다.
한개를 여러개의 분석기로 사용하거나
여러개를 하나의 분석기로 사용할 수 있다.

백엔드 개발자