Elastic Search
1.Elastic Search alias 설정
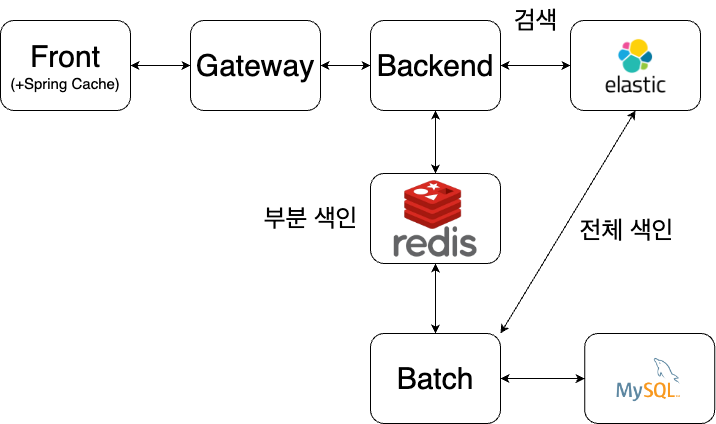
색인의 별명 index의 또 다른 이름 이라고 생각하면 된다.그래서 index의 이름 대신 alias 설정을 통해 index를 직접 사용하는 것이 아닌 alias를 사용할 수 있다.Post /\_aliases 로 aliases를 설정할 수 있다,예시는 alias에 my
2.Elastic Search 기본 개념
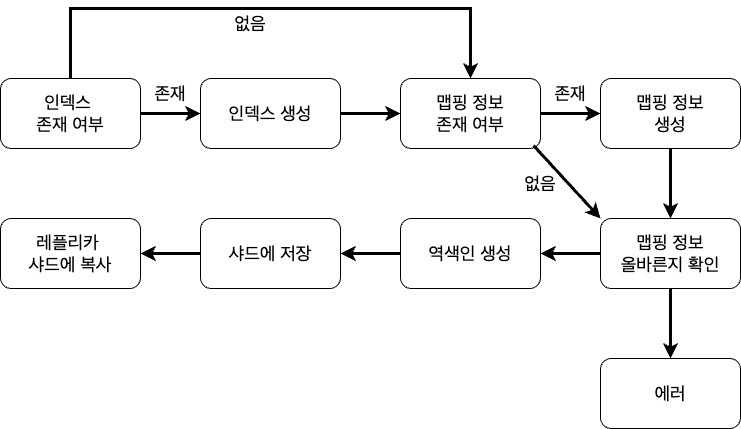
Apache Lucene 기반의 java 오픈소스 분산 검색 엔진데이터를 신속하게 저장, 검색, 분석을 수행하는 역할역색인 구조로 대용량 데이터를 빠르게 처리 가능기존 관계 데이터베이스 시스템에서는 다루기 어려운 전문검색(Full Text Search) 기능과 점수 기
3.Elastic Search의 분석기 - Char Filters
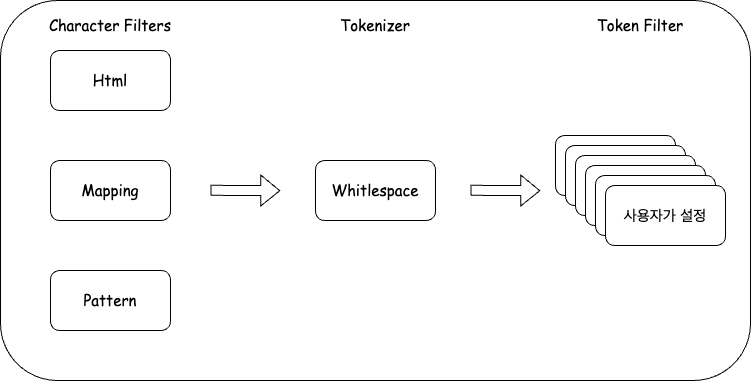
분석기(Analyzer)란 > Elastic Search는 문자열 필드가 저장될 때 데이터에서 검색어 토큰을 저장하기 위해 여러 단계의 처리 과정을 거칩니다. 이 전체 과정을 텍스트 분석(Text Analysis) 이라고 하고 이 과정을 처리하는 기능을 분석기(Ana
4.Elastic Search 분석기 - Tokenizer

Tokenizer 란? > 텍스트를 분절시키는 방법 입니다. 어떻게 텍스트를 token으로 나눌 것인가? 참고로 tokenizer는 하나만 사용가능하다. 기본 Tokenizer > ### standard tokenizer는 띄어쓰기를 기준으로 나눈다. 결과 띄어쓰
5.Elastic Search copy_to 활용법
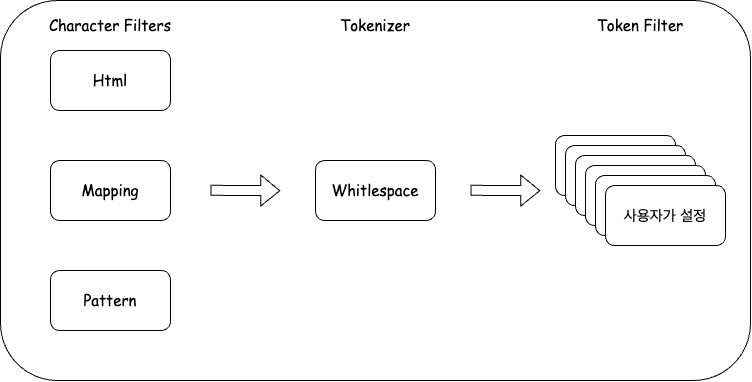
검색의 퀄리티를 높이거나 다양한 요구사항들을 만족시키기 위해서는 한 항목에 tokenizer을 여러개가 필요할 때가 있다. 하지만 tokenizer를 보면 하나의 tokenizer만 적용이 가능하다.그래서 나는 copyto 방법으로 하나의 mapping을 더 만들어 적
6.Elastic Search 분석기 - Token Filter
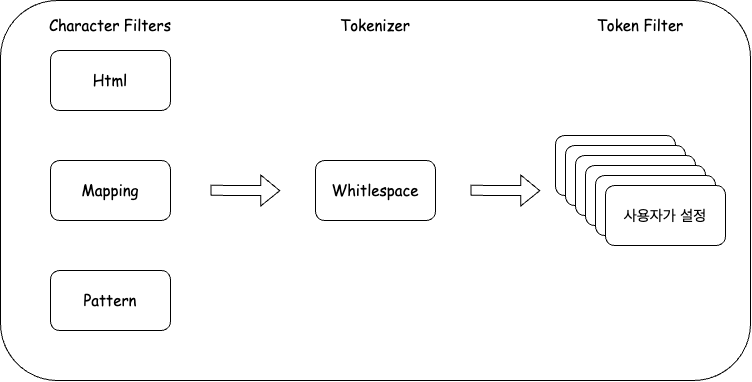
Elasticsearch에서 token_filter는 텍스트 분석 파이프라인의 중요한 부분으로, 텍스트를 토큰화한 후 필터링을 통해 분석된 토큰을 변형하거나 처리asciifolding: 유니코드 문자를 ASCII 문자로 변환합니다. 예를 들어, "é"를 "e"로 변환합