BERT
-
사전 훈련된 워드 임베딩
- 태스크에 사용하기 위한 데이터가 적다면 사전 훈련된 임베딩을 사용했을 시 성능향샹 기대
- 임베딩 층을 랜덤 초기화 하여 처음부터 학습하는 방법 총 2가지 방법 존재
-
워드 임베딩의 문제
- 다의어나 동음이의어를 구분하지 못한다.
- 이를 해결하기 위해 사전 훈련되 언어 모델을 사용
- ELMo , BERT 를 사용 가능
-
Transformer
- Transformer가 도입되면서 성능이 향상 됬으며 , LSTM을 사용하지 않게 되었다.
- 그러나 LSTM을 이용하지 않게 되었을 때 생기는 문제(이전 단어와의 유사성, 단어 위치)는 이전 단어들의 정보를 받아 오지 못하는 문제가 발생
- 다음의 수식으로 Transformer는 이전 데이터의 정보를 가져올 수 있음
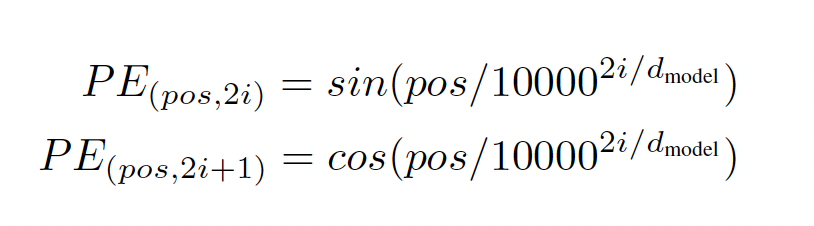
-
GPT
- Transformer Decoder 12개의 층을 쌓은 후에 방대한 텍스트 데이터를 학습시켰음
-
Masked Lasnguage Model
- 입력 텍스트의 단어 집합의 15%의 단어를 랜덤으로 가림 = 마스킹
- 예시 = “나는 [MASK]에 가서 그곳에서 빵과 [MASK]를 샀다”
-
BERT
- 2018년 구글이 공개한 사전 훈련된 모델
- 레이블이 없는 방대한 데이터로 사전 훈련된 모델을 가지고, 레이블이 있는 다른 작업(Task)에서 추가 훈련과 함께 하이퍼파라미터를 재조정하여 이 모델을 사용하면 성능이 높게 나오는 기존의 사례들을 참고
-
BERT의 크기
- Base , Large
- Base의 layer는 12개 Large 는 Base에 2배이다.
-
BERT의 문맥을 반영한 임베딩
- 출력 임베딩이 문맥을 모두 참고한 문맥을 반영한 임베딩 벡터가 된다.
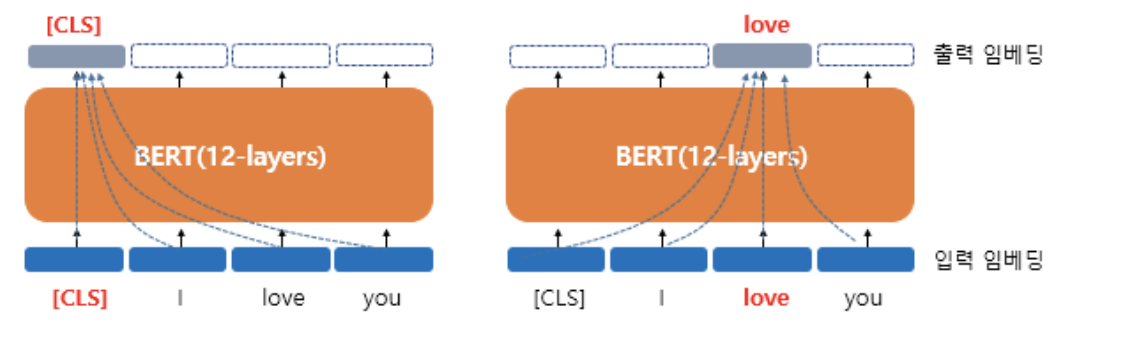
-
BERT의 서브워드 토크나이저 : WordPiece
- BERT가 사용한 토크나이저는 WordPiece 토크나이저로 서브워드 토크나이저 챕터에서 공부한 바이트 페어 인코딩(Byte Pair Encoding, BPE)의 유사 알고리즘
- 만약, 예를 들어 embeddings이라는 단어가 입력으로 들어왔을 때 BERT의 단어 집합에
em, ##bed, ##ding, #s라는 서브 워드들이 존재한다면, embeddings는 em, ##bed, ##ding, #s 로 분리
-
BERT 의 포지션 임베딩
- 위치 정보를 확인하는 임베딩 층을 사용한다.
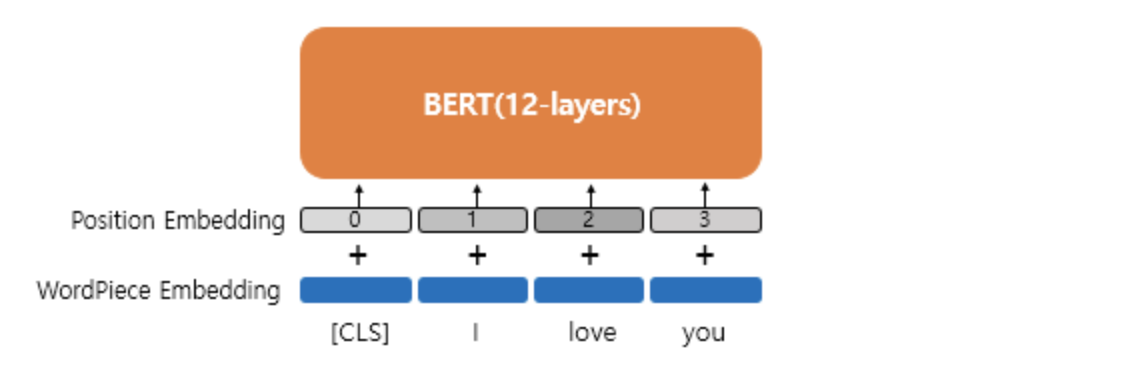

- 위치 정보를 확인하는 임베딩 층을 사용한다.
-
BERT의 사전훈련 모델
-
마스크드 언어 모델
-
입력 텍스트의 단어 집합의 15%의 단어를 랜덤으로 가림 = 마스킹
-
예시 = “나는 [MASK]에 가서 그곳에서 빵과 [MASK]를 샀다”
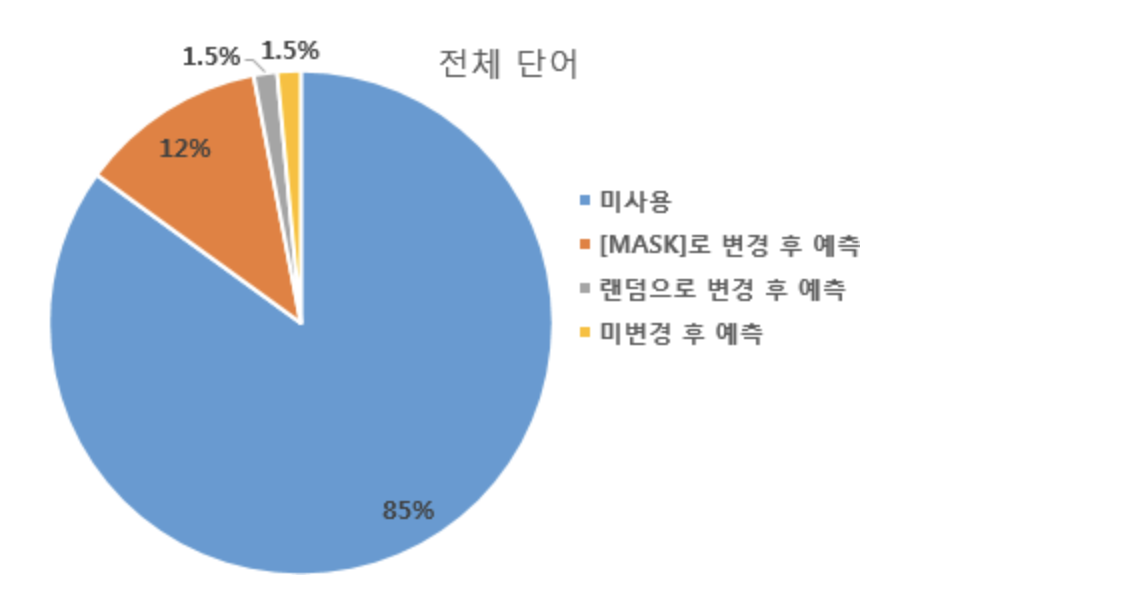
-
mask 표시 단어 맞추기에서는 해당 마스크 된 부분의 출력층 벡터만을 이용한다.
-
만약 마스크가 된 부분을 제외한 다른 부분이 원레의 데이터 입력과 다르것도 찾는 작업을 동시에 해야 한다면 어떻게 될까
- BERT 입장에서는 이것이 변경된 단어인지 아닌지 모르므로 마찬가지로 원래 단어를 예측해야 한다.
-
-
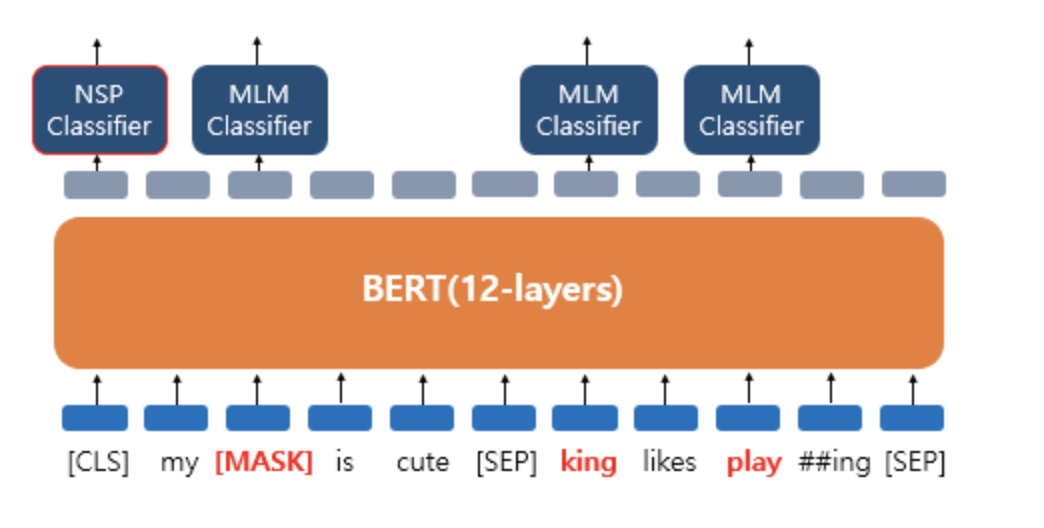
다음 문장 예측
-
두 개의 문장을 준 후에 이 문장이 이어지는 문장인지 아닌지 맞추는 방식으로 훈련
-
SEP = 문장 구분 토큰
-
CLS = 실제 이어지는 문장인지 아닌지를 푸는 이진 분류 문제
-
MASKED model과 두 문장 합치기는 따로 학습이 아닌 loss를 합하여 학습이 동시에 이뤄짐
-
정리 마스크가 된 곳과 두문장이 주어지는 경우 loss를 합쳐서 같이 학습한다.
-
-
-
세그먼트 임베딩 (Segment Embedding)
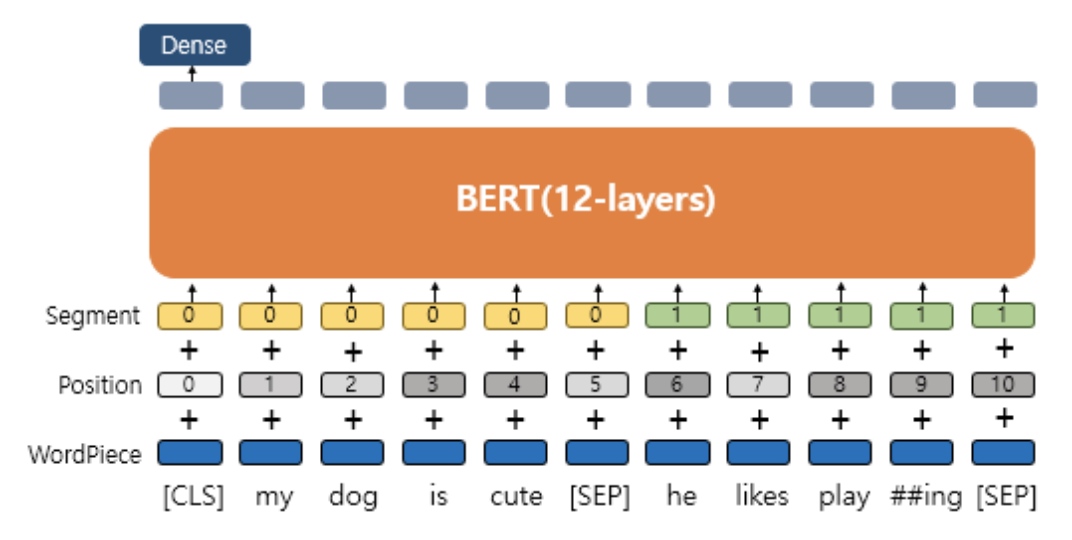
- Segment = 또 하나의 임베딩 층 첫번째 문장에는 0 두번째 문장에 1
- 결론적으로 BERT는 총 3개의 임베딩 층이 사용
- WordPiece Embedding - 실질적인 입력
- Position Embedding - 위치 정보를 학습하기 위함
- Segment Embedding - 두 개의 문장 구분
- 주의
- SEP , 세그먼트 임베딩으로 구분되는 BERT의 입력에서의 두 개의 문장은 실제로는 두 종류의 텍스트 두개의 문서일 수 있다. 우리가 아는 문장이 아닐 수 있다. 보다 더 큰 의미
- 결론적으로 BERT는 총 3개의 임베딩 층이 사용

DataScience_Study