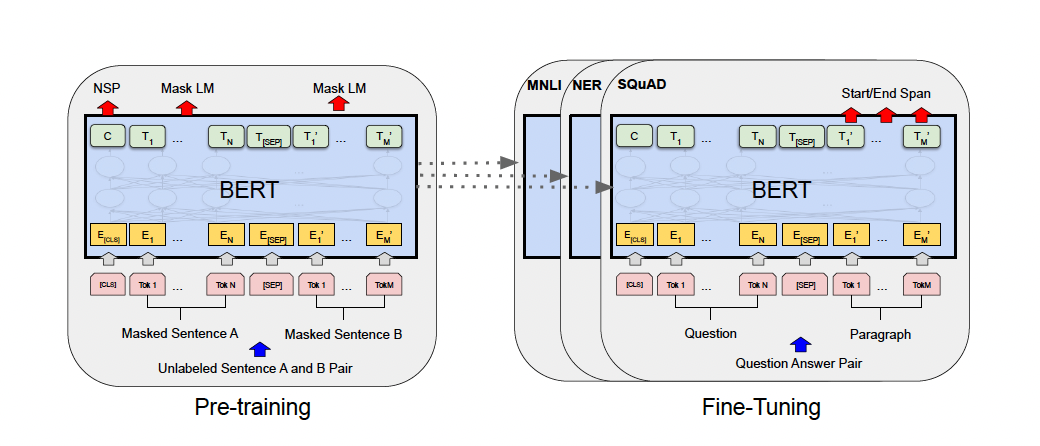
- 관련 사이트
- https://lena-voita.github.io/nlp_course/seq2seq_and_attention.html - seq2seq , attention
개인적으로 찾아보기 위한 이론 정리를 시작하려 합니다. 내일은 올림픽 프로젝트 마지막으로 찾아뵐게요 ㅎㅎ
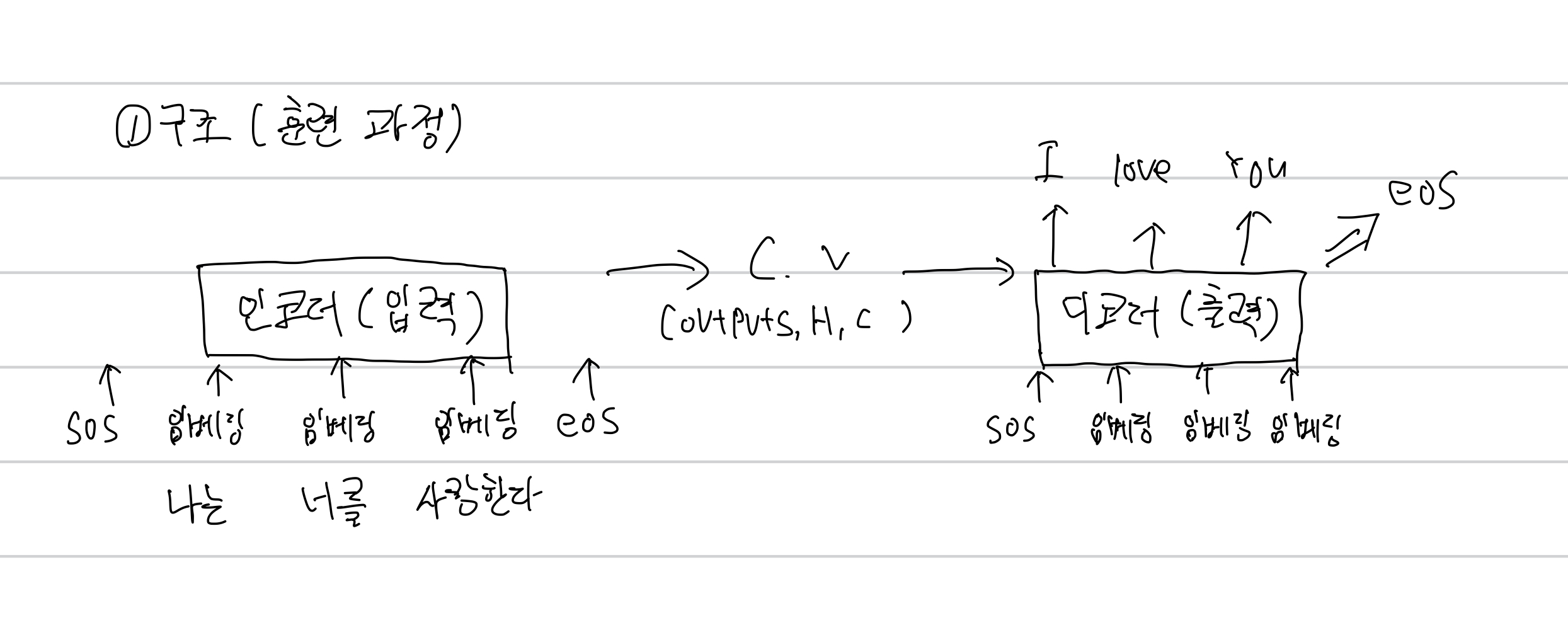
가장 기본적인 sequence to sequence
-
인코더에서 연산이 이루어짐 입력이라고 보면 된다.
- 앞에서 연산이 된 결과가 다음 연산에 전달이 되면서 반복된다.
- 마지막에는 context vector 가 연산을 하며 디코더에 전달한다.
-
디코더는 출력이라고 생각하면 된다.
- 처음 출력값을 연산해서 앞선 인코더 처럼 반복된다.
- 마지막에 eos가 나올 때까지 되풀이를 하는 것
-
현재는 자주 쓰이는 구조는 아니다.
-
LSTM을 사용했을 때 보다 성능이 더 괜찮아짐을 보인다.
-
문제점
- 컨텍스트 벡터 크기 고정 (매우 긴 문장 —> 정보손실 큼)
- LSTM을 기반으로 하고 있어 기울기 손실 문제가 존재한다. 층이 높아질 수록
- 시그모이드 보다는 덜 하긴 하지만 기울기 손실 문제를 피할 수는 없다.
- 문단 단위로 들어가거나 하면 품질이 매우 떨어진다. (다른 알고리즘도 피할 수 없는 문제 )
- 이걸 최소화 하기 위한 attention 알고리즘이 고안됬다.
토큰화
- 토큰화 = 문자,단어,문장,서브단어
- 토큰화를 무조건 시행해야 한다. 딥러닝의 학습과 예측을 위해
- 그 중 서브단어
- 바이트 단위로 나뉘는 쌍을 이루는 단위로 인코딩(GPT,BERT) 사용 알고리즘
- 단어 조각 인코딩 (WordPiece)
인코딩 방식
바이트 쌍 인코딩 GPT에서 사용
- 정보를 압축하기 위한 용도로 사용하던 알고리즘
- **가장 많이 등장한 문자열을 묶어서 압축**
- 연속적으로 나오는 두 문자를 하나의 문자로 통일한다. - 사용 이유
- out of vocabulrary
단어가 사전에 없는 경우를 피하기 위해서
- out of vocabulrary
- 작동 과정
- 새롭게 받은 데이터가 사용자의 단어사전에 존재하지 않을 수 있다.
- 이 때 기존 단어사전에 존재하는 단어들을 가장 많이 등장한 문자열 순서로 묶어서 압축한다.
- 아래 결과 예시를 보면 의미를 알 수 있을 것이다. - 결과(예시)
- l, o, w, e, r, n, s, t, i, d, es, est, lo, low, ne, new, newest, wi, wid, widest
- 이게 하나의 사전이 된다. 하나씩 묶어논 단어들을 추가시켜 주는 과정
- 나아가 새롭게 입력된 데이터를 글자 단위로 나눠 주고 나뉘어진 글자들에서도 가장 긴 단어부터 참조한다.
워드피스
- 바이트 쌍 인코딩과 비슷, 코퍼스에서 자주 등장한 문자열을 토큰화
- 차이점
- 문자열을 합치는 기준이 다름
- 바이트 쌍 인코딩에서는 빈도를 기준으로 합치기
- 워드피스는 코퍼스에 우도(likelihood)가 높은 쌍을 합치기
- 우도 likelihood
- 베이즈이론에서 나오는 이론
- 만약에 내가 가지고 있는 코퍼스에서 a,b 문자에 대해 계산
- 계산 수식
- #ab(ab라는 문자가 들어가는 횟수 / n(전체문자 빈도수) ) / (#a/n) * (#b/n)
- 해당 결과값이 큰 값에 해당되는 쌍부터 합치기
- 이 값이 커지려면
- a 와 b가 독립이라는 가정 하에 수식을 해석할 때
- a b 가 자주 동시에 등장해야 한다.
- 센턴스 피스
- 문장에서 단어를 분리하는 패키지
- 언어에 구애받지 않고 잘 동작 된다는 장점
- 허깅페이스
- 자주 등장하는 서브 워드들을 하나의 토큰으로 토큰화

DataScience_Study