💡 set_index() 함수를 사용해 데이터프레임의 인덱스를 설정할 수 있다.
Syntax
set_index() 함수 사용 방법은 다음과 같다.
df.set_index(keys=[col1,col2,...], inplace=True/False, drop=True/False)
✔ keys: 인덱스로 지정할 list, series, 데이터프레임의 칼럼 이름을 입력한다.
✔ inplace: True면 원본 데이터프레임의 인덱스도 변경된다. default는 False이다.
✔ drop: True면 인덱스로 지정한 칼럼을 제거한다. default는 True 이다.
리스트를 인덱스로 지정하기
✔ list, series 등을 인덱스로 지정할 때는 데이터프레임의 행의 갯수와 동일해야 한다.
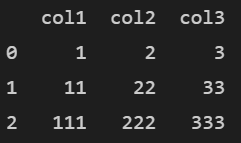
# 데이터프레임 생성 import pandas as pd df1 = pd.DataFrame({'col1':[1,11,111],'col2':[2,22,222],'col3':[3,33,333]}) print(df1)
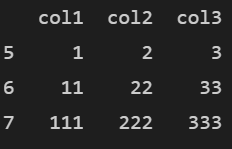
# 행의 갯수와 동일한 list, series를 인덱스로 지정 df2 = df1.set_index([[5,6,7]]) print(df2)
컬럼을 인덱스로 지정하기
✔ 1개 이상의 컬럼을 인덱스로 지정할 수 있다.
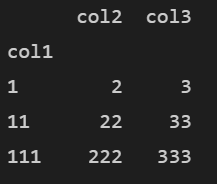
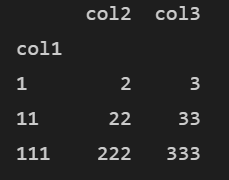
# 데이터프레임의 컬럼인 col1을 인덱스로 지정 df3 = df1.set_index(['col1']) print(df3)
# col1, col2를 인덱스로 지정 df4 = df1.set_index(['col1','col2']) print(df4)
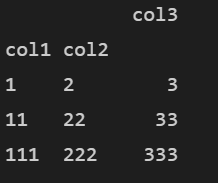
inplace
✔ inplace=True는 원본 인덱스를 변경한다.
# 원본 변경 df1.set_index(['col1'], inplace = True) print(df1)
drop
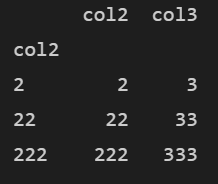
✔ drop=False는 인덱스로 지정한 컬럼을 유지한다.
# 인덱스로 지정한 칼럼 유지 df5 = df1.set_index(['col2'], drop = False) print(df5)