drop_duplicates 사용하기
💡 데이터프레임의 중복된 행을 제거할 수 있다.
import pandas as pd # 중복제거 df.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
# 데이터프레임 생성
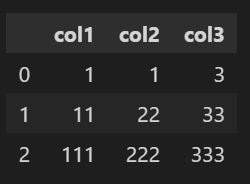
dct1 = {'col1':[1,1,1,11,11,111], 'col2':[1,2,3,22,22,222],'col3':[3,3,3,33,33,333]}
df1 = pd.DataFrame(dct1, columns=['col1','col2','col3'])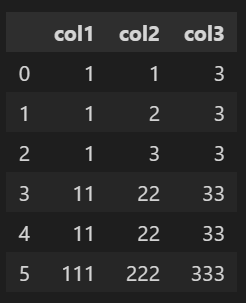
subset으로 기준열 지정하기
◾ 데이터프레임에서 중복을 제거할 기준열을 입력한다.
df1.drop_duplicates(['col1'])👉 col1 열을 기준으로 중복되는 행이 제거되었다
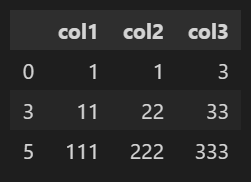
df1.drop_duplicates(['col1','col2'])👉 col1과 col2 열을 기준으로 중복되는 행이 제거되었다
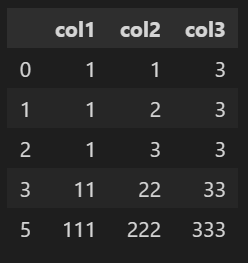
◾ 입력하지 않으면 모든 열을 기준열로 지정한다.
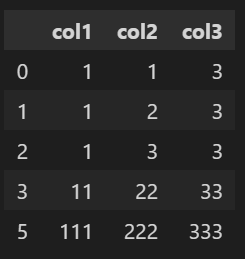
# subset=None 기준열 지정 안하기 df1.drop_duplicates()👉 index 4 행이 제거 되었다
keep으로 표시할 행 지정하기
✔ 중복된 데이터 중 제거할 행과 표시할 행을 지정할 수 있다.
✔ default는 'first' 이다.
◾ keep='first' 인덱스가 첫번째인 행 표시하기
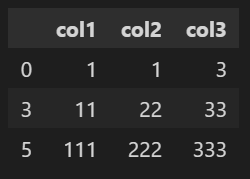
df1.drop_duplicates(['col1'],keep = 'first')👉 index 0, 1, 2 중 0만 표시되었다
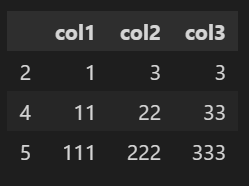
◾ keep='last' 인덱스가 마지막인 행 표시하기
df1.drop_duplicates(['col1'],keep = 'last')👉 index 0, 1, 2 중 2만 표시되었다
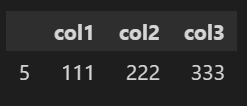
◾ keep='False' 표시하지 않고 중복되는 행 모두 제거
df1.drop_duplicates(['col1'],keep = False)👉 중복되는 행 모두 제거되었다
inplace로 원본 데이터 변경하기
✔ inplace=True는 원본 데이터에 반영하여 변경된다.
✔ inplace의 default는 False이다.
# 원본 데이터에 반영 df1.drop_duplicates(['col1'],keep = 'first', inplace=True) df1
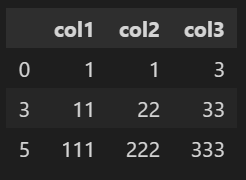
ignore_index로 인덱스 초기화 하기
✔ ignore_index=True는 인덱스를 초기화한다.
✔ ignore_index default는 False이다.
# 원본 데이터에 반영 df1.drop_duplicates(['col1'],keep = 'first', ignore_index=True) df1