
개요
데이터 베이스를 공부했다면 한번쯤은 MySQL를 누구나 사용해봤을 것이다.
그렇기에 좀 더 원초적인 특성들을 살펴보고자 이렇게 글을 쓰게 됐다.
MySQL 세 가지 특성
1. 단일 코어에서 Nested Loop Join 처리
MySQL에서는 모든 SQL 처리를 단일 코어에서 Nested Loop Join 방식으로 데이터를 처리한다. 해당 말은 병렬 처리라는 것이 없다. 물론 예외적인 케이스가 있다. 3rd 스토리지 엔진을 플러그인으로 설치하면 병렬 처리가 가능하다고는 하지만 기본적인 스토리 엔진에는 단일 코어만을 수행한다.
🤔3rd 스토리지 엔진🤔
외부에서 가져오는 스토리 엔진
그렇기 때문에 MySQL 입장에서는 CPU 코어 개수를 늘리는 Scale-Out보다는 단위 처리량이 좋은 CPU로 Scale-up을 하는 것이 훨씬 유리합니다.
그렇다면 왜 Nested Loop Join이 무엇이기에 CPU Scale-up을 하는 것이 훨씬 유리하다고 하는 것일까🤔
-> 간단하다 영어를 풀어서 해석한다면 중첩 루프 조인 알고리즘이다. 즉 해당 말은 이중 for문이 들어간다는 말이 된다.
t1세 테이블 사이의 조인이 t2다음 t3조인 유형을 사용하여 실행된다고 가정합니다.
Table Join Type
t1 range
t2 ref
t3 ALL위와 같은 방식을 NLJ알고리즘이 사용되는 경우 조인은 다음과 같은 처리가 이루어집니다.
for each row in t1 matching range {
for each row in t2 matching reference key {
for each row in t3 {
if row satisfies join conditions, send to client
}
}
}NLJ알고리즘은 외부 루프에서 내부 루프로 행을 한 번에 하나씩 전달하기 때문에 일반적으로 내부 루프에서 처리된 테이블을 여러 번 읽습니다.
그렇기에 단일 코어의 처리를 높이기 위한 Scale-up을 하는 게 훨씬 유리하다는 말이 성립되기 때문입니다.!!
👉 이러한 Join 뿐만아니라 Sub Query , Inner Join은 모두 NLJ만으로 처리가 됩니다.
❗️그렇다고 MySQL은 NLJ만 사용하는 것은 아니다❗️ MySQL 내부에는 옵티마이저가 있는데 옵티마이저가 선택하는 하나의 조인 알고리즘 중 하나이다!!
즉 여러 알고리즘으로 수행될거라는 사실!! 꼭 NLJ만 있는 것이 아니라 옵티마이저가 쿼리의 특성과 테이블의 크기, 인덱스 상황 등을 고려하여 최적의 조인 알고리즘을 선택해줍니다.
2. 다양한 스토리 엔진을 지원한다.
스토리 엔진이란? -> 만약 디테일한 사항은 여기를 참고
실제 Data를 디스크 스토리지에 저장하거나 읽어오는 부분을 담당하는 역할!!
MySQL 내부에서도 다양한 스토리 엔진을 지원하지만, 부가적으로 간단하게 플러그인 형식으로 설치를 할 수 있다.
간단하게 MySQL 내부 스토리엔진을 봐보자!!
- MyISAM Storage Engine
인덱스만 메모리에 올려서 데이터를 처리하거나 수정할 때 해당 테이블 전체를 잠금 처리하는 스토리지 엔진으로 단순 백그라운드에서 로그 수집에 적합합니다. 다만 변경 작업을 수행하는 로직에는 절대 적합하지 않습니다.
🤔테이블 잠금이란🤔
동시에 여러 개의 쿼리 또는 연결이 동일한 테이블을 수정하려고 할 때 발생할려고 하는 현상
- Archieve Storage Engine
원시 로그 수집에 원초적인 스토리지 엔진이다. 다만 여기서는 트랜잭션, 인덱스 모두 지원하지 않지만, 테이블에서 데이터 처리를 행 단위 잠금으로 수행하기 때문에 동시다발적으로 데이터 입력 상황에도 상당히 좋은 퍼포먼스를 제공한다.
- InnoDB Storage Engin
해당 스토리지는 어떻게 보면 Mysql기본적인 설정으로 우리가 암묵적으로 사용되는 스토리 엔진으로서 많이 쓰이는 만큼 테이블 저장 및 관리를 담당하는 기술이 담겨져 있습니다.
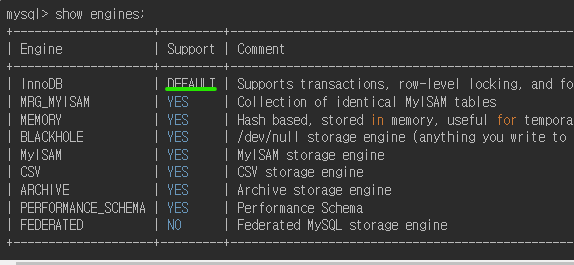
실제로 우리는 기본적으로 show engines; 명령어를 통해서 기본적으로 InnoDB에 해당한다는 사실을 알 수 있다.
InnoDB는 행 단위 잠금, 메모리, 인덱스, 트랜젝션 모두 지원하기 때문에 데이터 접근 속도가 빠릅니다. 메모리가 많이 허용되면 엄청난 퍼포먼스를 발휘하는 엔진 그리고 별도로 트랜잭션을 제공하고, 동시 데이터 처리 시에도 행 단위 잠금 처리하기 때문에 대용량 처리에 가장 적합한 스토리 엔진이라고 볼 수 있다.
위와 같은 다양한 엔진을 능숙하게 사용할 수만 있다면 서버 효율성을 상단 수준으로 끌어낼 수 있다고 한다.
3. 데이터 복제(Replication) 기능
MySQL은 물리적으로 독립적인 디스크 영역에 데이터를 복제(Replication)하여 데이터를 이중화할 수 있습니다.
그렇다면 MySQL을 이중화한다는 말은 서버를 여러 개 두겠다는 말이 되는데 굳이 서버를 이중화해야 하는 이유가 무엇이냐?
부하 분산
읽기 , 쓰기를 하나의 DB에서 처리하게 된다면 트래픽이 늘어남에 따라 자연스럽게 병목 현상이 생길 수밖에 없다.
그렇기에 쓰기를 원본 서버에서 수행하고 읽어올 때는 복제 서버에서 읽어오게 한다면 병목현상 없이 모두 향상시킬 수 있게 된다.
대표적인 구조는 MySQL Replication Master-Slave 구조이며 해당 구조를 통해서 마스터에서 데이터 변경 작업이 일어나면, 해당 내역은 자동으로 슬레이브로 비동기적으로 전송되어 실제 마스터의 데이터 복사본을 유지하는 것을 의미하게 된다.
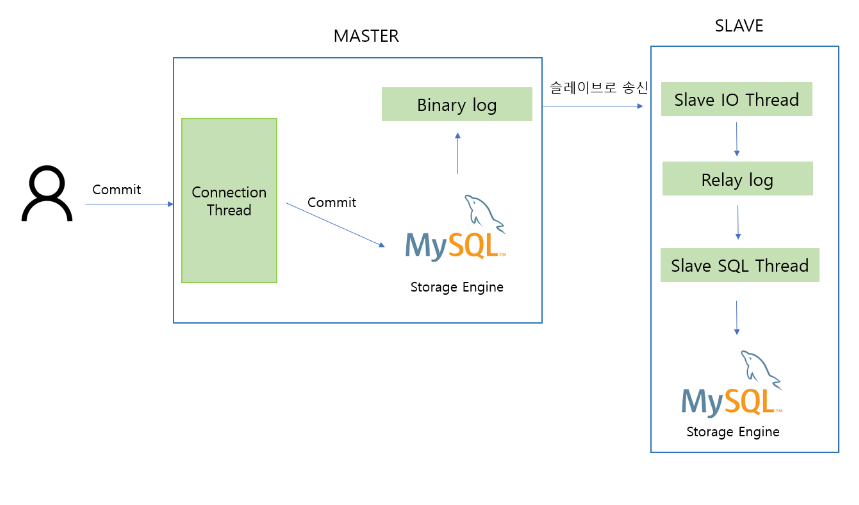
위와 같은 구조를 가지게 된다면 우리는 부하 분산뿐만 아니라
데이터의 보안
Replication을 구성하게 되면 항상 복제를 진행하는 게 아닌, 일시 중지가 가능하다 그렇기에 원천 데이터를 손상하지 않고 복제본에서 백업 서비스를 작동시키는 게 가능하다.
장애 극복
만약 Master DB가 모종의 이유로 장애가 발생해 사용이 중지된다면 바로 Slave를 Master로 승격해 데이터를 빠르게 복구를 진행할 수 있다. 다만 MySQL Replication은 비동기 방식으로 진행되기 때문에 복사 시간을 온전히 기다리지 않을뿐더러 그로 인해 데이터가 완벽하게 복사가 되지 않을 수 있다.
마치면서
아직도 지금까지 해당글을 작성하면서 많이 부족하다는 사실을 알고 있다. 그렇지만 그래도 전반적은 큰 틀은 이해했다고 생각한다.
하지만 위에서 말했듯이 부족하다. 좀 더 디테일한 글 정리를 통해 하나씩 공부할려고한다. --> 요약 이거 시리즈 만든다는 뜻!!ㅋㅋㅋㅋ
https://gywn.net/2011/12/mysql-three-features/
https://dev.mysql.com/doc/refman/8.0/en/nested-loop-joins.html
https://jane096.github.io/project/mysql-master-slave-replication/

잘 봤습니다. 좋은 글 감사합니다.