이번에 AUSG에 지원해서 합격했는데, 서류 작성 시 아래의 문항에 대한 답변을 작성해야 했다.
AUSG에서 어떤 활동을 하고 싶은지 알려주세요!
이 문항에 대하여 스터디와 대규모 트래픽이 존재하는 IT 서비스 인프라 설계해보기 이렇게 두 개의 활동을 해보고 싶다고 답변했었다. 스터디는 K8S 스터디와 검색 엔진과 관련된 스터디를 해보고 싶다고 작성했었는데, 스터디를 참여하기 전에 검색 엔진에 대해서 한 번 공부해보면 좋을 것 같아 이 주제를 LIVID에서 수박 겉핥기 수준으로 정리해서 공유하기로 결정했다.
Elastic Search, Open Search
Elastic Search와 Open Search의 역사
과거 Elastic Search와 Open Search가 사실상 같은 제품이라고 들었던 기억이 있었는데, 현재는 다른 제품으로 구분하기에 관련된 내용을 정리하면서 시작하고자 한다.
Elastic의 Elastic Search가 오픈 소스로 공개된 이후, AWS는 Elastic의 Elastic Search를 기반으로 한 AWS 내에서 제품을 출시하여 사용자들에게 제공해왔었다.
그러던 중, Elastic Search가 SSPL 라이선스로 제품이 전환되었고, AWS는 이에 대응하여 SSPL 라이선스 정식 적용 직전 해당 오픈소스를 fork하여 Document DB와 Open Search를 출시하면서 유사하지만 다른 제품으로 분리되었다.
분리된 이후 Elastic Search와 Open Search는 다른 방향의 업데이트를 지속해왔다.
Elastic Search는 Managed Service를 강화하며 사용성과 편의성에 중점을 두었으며, Open Search는 보안이나 인증 등에 대해 집중하고 있다.
(출처: Elastic과 Opensearch: 오픈 소스를 둘러싼 대립, 2024-07-15)
Elastic Search
Elastic에서는 Elastic Search에 대해 시간이 갈수록 증가하는 문제를 처리하는 분산형 RESTful 검색 및 분석 엔진이라고 설명하고 있다.
특징
- 분산 시스템이기에 수평적 확정이 가능
- RESTful하기에, Data의 CRUD 작업이 HTTP Restful API를 활용해 수행 가능
- 새로운 문서를 indexing할 때부터 검색 가능한 대기 시간이 1초 정도 걸림.
- Document형 DB
- 스키마가 아닌, Json형식의 문서로 Query DSL을 이용해 문서 탐색
여기서의 Query DSL은 JPA에서 활용되는 Query DSL이 아닌 Json 형식의 검색 질의 방식
Open Search
AWS OpenSearch 기본 설명서에서는 Open Search를 Apache 2.0 라이선스 하에 제공되는 분산형 커뮤니티 기반 100% 오픈 소스 검색 및 분석 제품군으로, 실시간 애플리케이션 모니터링, 로그 분석 및 웹 사이트 검색과 같이 다양한 사용 사례에 사용할 수 있는 제품이라고 설명하고 있다.
특징
- Elastic Search와 유사한 기능 제공
- 보안 플러그인, 알림 기능 등 추가 기능 포함
- Elastic Search API와 호환성 유지
Elastic Search API와는 완벽한 호환성을 제공하지 않기에, 유의해야 한다.
동작 원리
Elastic Search의 동작 원리에 대해 잘 정리되어 있는 블로그 글을 첨부한다.
쉽게 정리하면 아래와 같이 동작한다.
1. 문서 저장
2. 역색인 자료구조 저장
3. Analyzer를 활용한 텍스트 분석
어떤 제품을 선택해야 할까?
라이센스/레퍼런스 등의 측면에서 구분해놓은 블로그 글이 있어 첨부한다.
이를 참고해서 선택하면 좋을 것 같다.
VectorDB
사실 VectorDB는 위의 두 검색 엔진과는 다르게 데이터베이스의 한 종류이다. VectorDB를 짧게 정의해보면, 고차원의 벡터 데이터들에 대한 저장 및 조회를 높은 성능으로 할 수 있는 데이터베이스이다.
검색
VectorDB를 이용해서도 검색을 구현할 수 있는데, 관련된 내용을 Google Summit 세션으로 들었기에, 세션에서 사용된 이미지를 가지고 정리해본다.
다만 아래의 예시는 이미지/비디오/텍스트를 모두 아우르기에 검색과는 다른 부분이 명확히 존재한다는 점을 유의해야 한다.

먼저, 입력이 들어온다면 위와 같이 텍스트 임베딩 모델을 활용하여 임베딩을 진행한다.

임베딩 과정에서, AI는 벡터값을 부여한다.
위의 이미지를 보면 food/plant/animal이라는 3축이 존재하며, 축별로 값을 가지는 것을 알 수 있다.
이를 통해, 유사한 의미를 가지는 데이터일 경우, 벡터값의 차이가 적다는 것을 알 수 있다.

최종적으로 검색할 경우, 임베딩된 공간에서 가장 높은 유사도를 가지고 있는 데이터를 찾아 반환하게 되는 것이다.

위의 과정을 하나의 장표로 정리한 내용이다.
임베딩을 통해 벡터값으로 변환시킨 뒤 인덱스를 부여하고, 이렇게 벡터공간에 위치한 데이터를 검색할 수 있다는 것이다.
이 부분은 지식적으로 많이 부족해서, 틀린 점이 존재할 가능성이 있기에 "이런게 있구나."와 같이만 이해하면 좋을 것 같다.
RDB를 검색엔진에 어떻게 적용할까?
이 주제를 정하게 된, 가장 큰 이유는 RDB에 저장되어 있는 데이터를 어떻게 Document형으로 변환하여 적재하고 검색 엔진에서 검색이 가능하도록 할것인가?에 대한 궁금증 해결이다.
이 궁금증을 해결하기 위해 관련된 내용을 찾아보고 학습하다 후기 서비스 AWS Opensearch 도입기라는 마켓 컬리 기술 블로그 글을 읽게 되었다. 해당 글이 관련해서 가장 많은 도움을 받아서 해당 내용을 포함하여 정리해보고자 한다.
내가 생각한 방법
데이터 모델 설계
먼저, RDB에 있는 데이터를 검색엔진에 넣기 전에 데이터 모델을 설계해야 한다고 판단했다.
검색엔진은 Document가 Json 형식으로 저장되기에, RDB의 데이터를 그대로 저장할 수 없으므로 변환이 필요하고, 이를 인덱스 및 필드로 매핑시켜야 할 것이다.
인덱스 설계
검색 엔진은 가상 면접 사례로 배우는 대규모 시스템 설계 기초 책에서 나온 것과 동일하게 역인덱스를 활용하기에, 검색 성능을 최대한으로 내기 위해서는 인덱스 설계가 중요하다고 생각했다.
인덱스를 생성할 때에는 형태소 분석기 등을 활용하여 토큰화하는 방식을 사용한다.
형태소 분석기가 무엇인지에 따라 달라질 수 있기에 주의해서 결정해야 한다.
실제로, 마켓 컬리도 은전한닢 형태소 분석기를 사용했을 당시 오프셋 역전 현상이 발생했었으며,이후 추가된 Nori 형태소 분석기로 변경하여 해당 문제를 해결했다고 한다.
토큰화와 관련된 내용은 요기요 기술 블로그가 잘 정리되어 있는 것 같아 참고하면 좋을 것 같다.
Full-text search를 사이드 프로젝트에서 적용한 과정을 정리했었기에, 혹시 Full-text search 도입기가 궁금하면 한 번 읽어보면 된다.
데이터 변환 및 적재
나였다면, 카프카를 활용해 실시간으로 데이터를 검색 서버에 반영할 수 있도록 인프라를 구축할 것 같다.
API 서버 <-> 카프카 <-> 검색 서버 <-> 검색 엔진
카프카는 실시간으로 높은 성능으로 데이터를 처리할 수 있으므로, 다량의 데이터가 추가되더라도 데이터 유실 없이 검색 서버에 반영할 수 있을 것이라고 생각했다.
실시간으로 반영되지 않아도 되는 데이터들은 트래픽이 가장 낮은 시간대에 배치를 활용해 적재할 것 같다.
위의 과정에서, 데이터 변환은 카프카를 소비하는 검색 서버에서 진행한다.
검색 쿼리 개발
모든 데이터를 적재하는 과정이 끝났으므로, 검색엔진에서 사용할 검색 쿼리를 개발해야 한다. Json형식의 데이터를 찾기 위한 Query DSL을 제공하므로 이를 활용하면 된다고 생각했다.
Query DSL 예시 문서를 통해 찾아본 결과, Golang 기준 아래와 같이 활용할 수 있다.
res, err := es.Search(
es.Search.WithBody(strings.NewReader(`{
"query": {
"bool": {
"must": [
{
"match": {
"title": "Search"
}
},
{
"match": {
"content": "Elasticsearch"
}
}
],
"filter": [
{
"term": {
"status": "published"
}
},
{
"range": {
"publish_date": {
"gte": "2015-01-01"
}
}
}
]
}
}
}`)),
es.Search.WithPretty(),
)
fmt.Println(res, err)마켓 컬리의 방법
RDB의 데이터베이스에서 Json형식으로 변환하는 것은 당연한 내용이라 후기 원천 데이터를 모두 역정규화하여 운영 AWS Opensearch 인덱싱이라는 문장으로 정리되어 있다.
그렇기에, 데이터 동기화 과정을 중점적으로 정리한다.
데이터 동기화
마켓 컬리에서는 Event Driven Architecture를 선택했다.
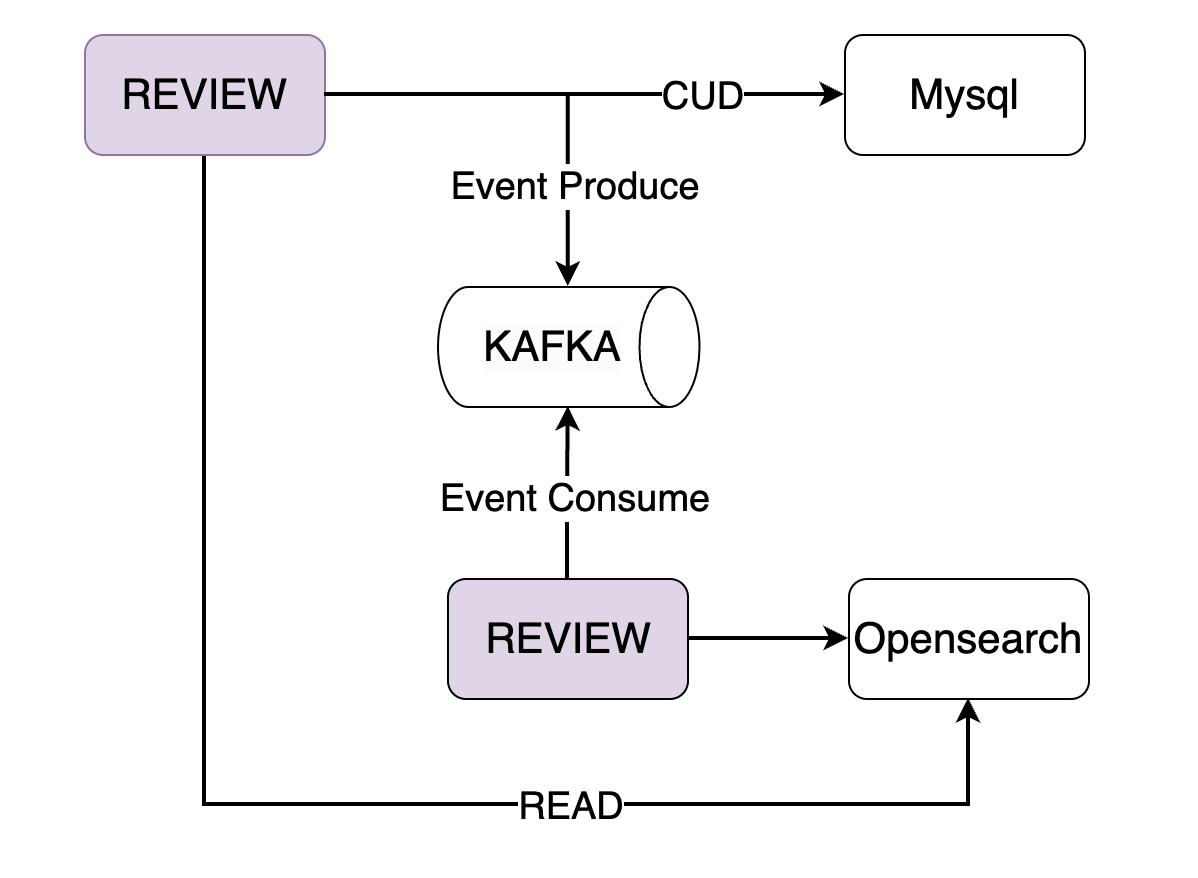
(그림: 컬리, © 2023. Kurly. All rights reserved.)
Event Driven Architecture를 선택한 이유 중 마켓 컬리의 서비스와 상관없이 가장 대표적인 이유는 아래와 같다.
- 후기 원천 데이터는 저장 성공 이후, Opensearch에서 실패하는 경우 사용자에게 실패 응답을 반환할 수 있어야 함.
- 동기화한다면, 후기 서버가 아닌 OpenSearch에서 문제가 발생했을 경우에도 응답이 지연될 수 있다는 점
- SRP(단일 책임 원칙)의 위반 발생
왜 SRP 위반인가?
일단 원본 데이터를 저장하는 것과 역정규화된 데이터를 저장하는 것이 두 가지 책임으로 분리된다. 만약 이걸 카프카 없이 하나의 플로우에서 관리한다면, 두 가지 책임이 하나의 플로우에서 관리되므로 SRP 위반으로 간주할 수 있다는 것이다.
인상깊었던 점
정리되어 있는 모든 내용이 재밌었고, 많은 것을 배울 수 있었지만 느낀 점이 가장 인상 깊었다.
데이터 직군이 아닌 개발자라도 운영하고 있는 서비스에 대한 데이터에 대한 관심을 가져야 하며, 데이터를 가지고 더 좋은 방향성을 만들어 낼 수 있도록 해야 합니다.
데이터 기반으로 짧은 주기의 업데이트를 지향하는 내 관점과 일치해서 그런 것 같기는 한데, 앞으로도 데이터 기반으로 최고의 사용자 경험을 만들어 나가야겠다.
스터디에서 공유하고자 정리한 내용을 올린 글입니다.
레퍼런스
읽어보면 좋을 관련 글
