
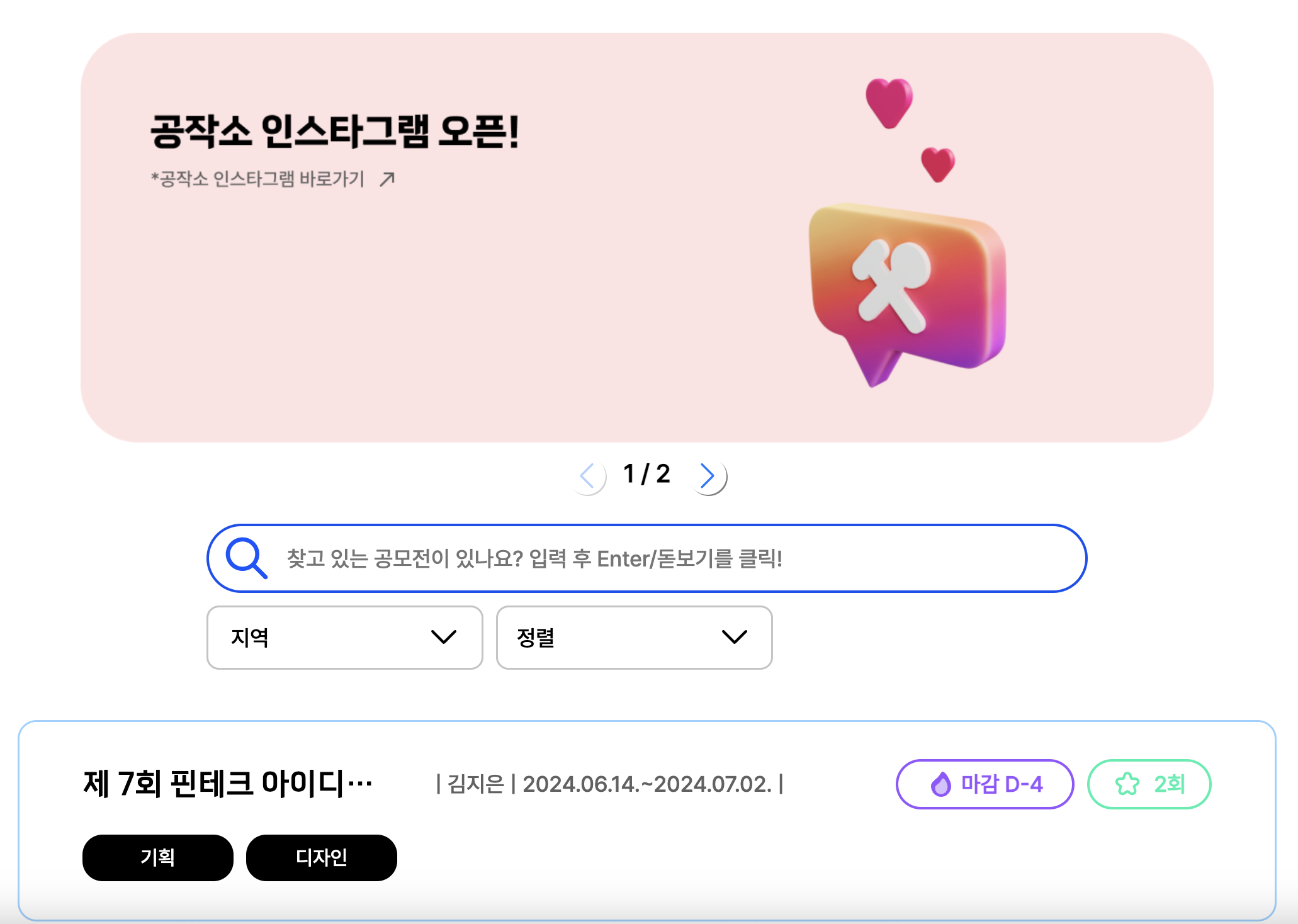
공작소는 페이지에 아래와 같이 검색 기능을 제공하고 있다.
현재, 해당 검색 기능은 아래와 같이 개발되어 있는 상황이다.
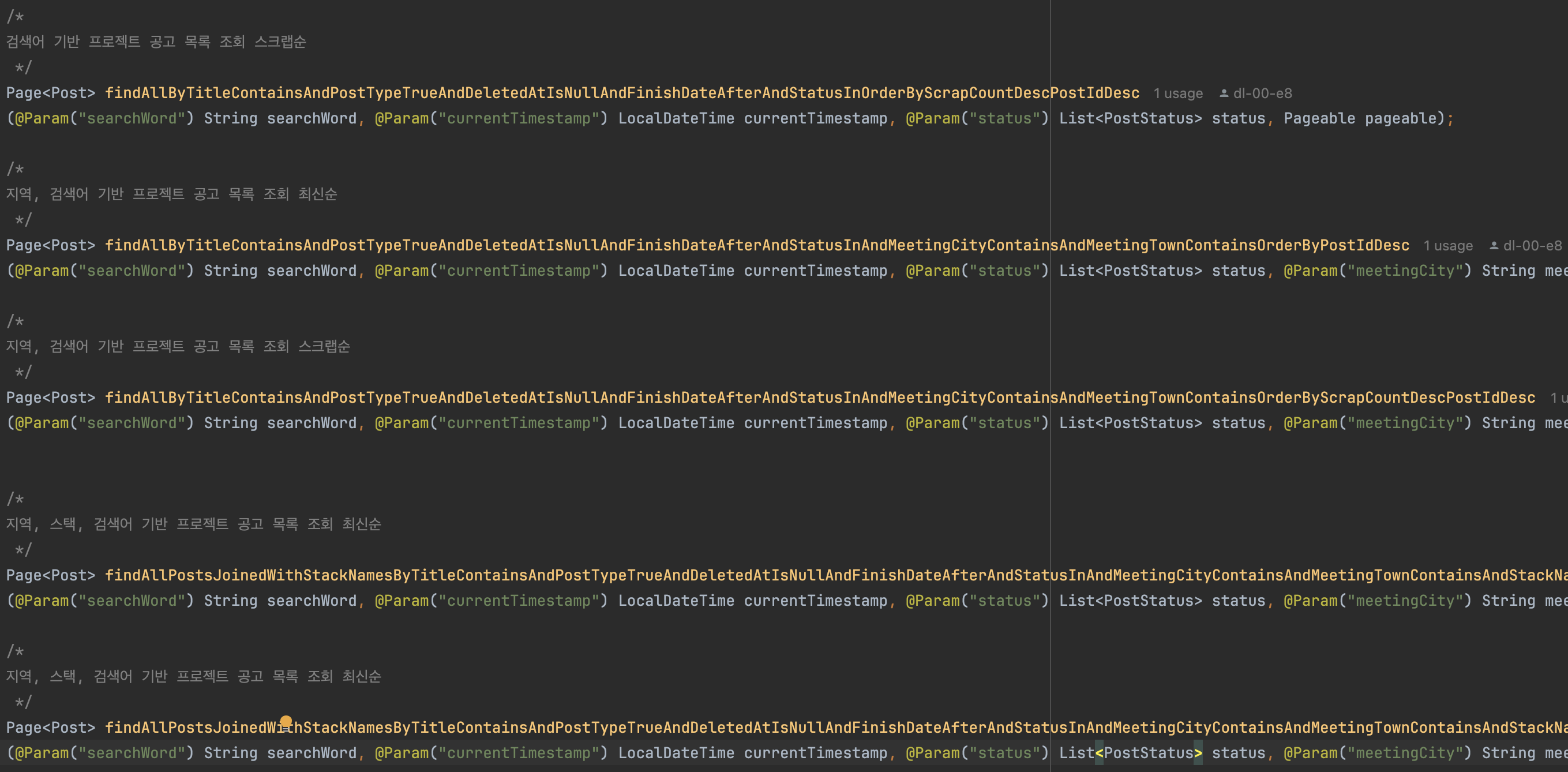
현재 검색은 팀 모집 공고의 제목을 기반으로만 검색이 가능하며, 공고가 많아질 경우 Full Scan으로 동작하는 Like문의 특성상 성능의 문제가 발생할 것으로 보여 Full-text search로 변환을 결정했다.
Full-text search와 Like
MySQL의 검색타입
Full-text search와 Like를 알아보기 전, MySQL의 검색 타입에 대해 정리하면 아래와 같다.
-
all, index: 이 두 타입은 테이블 전체를 스캔하는 것으로, 인덱스를 사용하지 않고 모든 행을 검색한다. 특히 all은 LIKE 절을 사용한 검색에서 많이 발생할 수 있다. 데이터가 많은 경우 성능 저하를 유발할 수 있다.
-
range: 이 타입은 인덱스를 사용하여 범위 검색을 수행한다. 예를 들어, WHERE 절에서 BETWEEN을 사용한 경우에 해당된다. 인덱스를 효율적으로 사용하여 데이터를 검색하므로 일반적으로 빠른 검색 속도를 제공한다.
-
fulltext: MATCH...AGAINST 구문을 사용하여 Full Text Search를 실행할 때 사용된다. Full Text Search는 전용 인덱스를 사용하여 텍스트 검색을 빠르게 수행한다.
-
ref, eq_ref, const: 이들은 주로 조인 작업에서 발생하는 타입이다. ref는 일반적인 인덱스 검색을 나타내며, eq_ref는 유일한 인덱스 또는 기본 키를 통해 한 개의 행만을 검색한다. const는 상수 값을 기반으로 한 인덱스 검색을 의미하며, 가장 빠른 검색 타입 중 하나이다.
-
system: 데이터가 없거나 한 개만 있는 경우에 해당되며 잘 사용되지 않는다.
Like
Like문을 활용한 예시 쿼리를 살펴보면 아래와 같다.
SELECT * from table where column like '%input%'즉, column에 해당하는 값 중 input을 포함하고 있는 값을 찾는 쿼리인데, 패턴이 문자열의 양쪽에 존재하기 때문에 인덱스를 활용할 수 없다.
검색 문자열인 %input%은 크게 3가지로 나누어 볼 수 있다.
-
input% -
%input -
%input%
1번은 첫 문자가 패턴이 아닌 문자열이므로 인덱스를 활용할 수 있지만 2번과 3번은 패턴이므로 인덱스를 활용할 수 없다. 즉, Full Scan으로 일치하는 데이터를 찾을 수 밖에 없기에 데이터 양이 늘어날수록 성능 저하의 폭이 커진다.
Full-text search
Full-text search는 전체 텍스트 내에서 검색을 효과적으로 수행하기 위한 방식이다. Full-text index를 활용해 텍스트 데이터를 효율적으로 인덱싱하여 검색 성능을 향상시킬 수 있다.
MySQL 기준, Full-text search를 활용하려면 MATCH () AGAINST () 문법을 사용해야 한다. 예시는 아래와 같다.
# MATCH() in SELECT list...
SELECT MATCH (a) AGAINST ('abc') FROM t GROUP BY a WITH ROLLUP;
SELECT 1 FROM t GROUP BY a, MATCH (a) AGAINST ('abc') WITH ROLLUP;
# ...in HAVING clause...
SELECT 1 FROM t GROUP BY a WITH ROLLUP HAVING MATCH (a) AGAINST ('abc');
# ...and in ORDER BY clause
SELECT 1 FROM t GROUP BY a WITH ROLLUP ORDER BY MATCH (a) AGAINST ('abc');Full-text Search는 Natural lanague mode, Boolean mode, Query extension 모드 등으로 구분할 수 있다. 여기서는 Natural language mode와 Boolean mode의 개념 및 차이만 정리한다.
Natural language mode
MySQL Docs에서의 Natural language mode 정의는 검색 문자열과 목록에 명명된 열의 해당 행에 있는 텍스트 간의 유사성을 측정하는 방식이다.
즉, 검색하고자 하는 문자열을 단어 단위로 분리한 이후, 해당 단어 중 하나라도 포함되는 데이터를 찾는 방식으로, 얼마나 많은 키워드가 포함되어 있는지(= 매치율)를 기반으로 높은 관련성 순서대로 결과값을 반환한다.
SELECT COUNT(*)
FROM articles
WHERE MATCH (title,body) AGAINST ('database' IN NATURAL LANGUAGE MODE);아래 쿼리와 같이 직접 매치율이 얼마나 되는지를 확인할 수 있다.
SELECT match() AGAINST() AS match_rate
FROM film;Boolean mode
MySQL Docs에서 Boolean mode 정의는 수정자를 사용하여 전체 텍스트 검색을 수행하는 방식이다. 여기서의 수정자는 +나- 등을 의미한다.
즉, 문자열을 단어 단위로 분리한 이후, 아래의 예시 쿼리와 같이 추가적인 검색 규칙을 적용하여 이를 만족시키는 데이터를 찾는 방식이다.
SELECT *
FROM articles
WHERE MATCH (title,body) AGAINST ('+MySQL -YourSQL' IN BOOLEAN MODE);두 방식 간 성능 비교
먼저 Full-text search와 Like문 간의 성능을 비교하고자 한다.
Full-text search의 Natural language mode를 기준으로 한다.
성능 측정 환경 설정
쿼리 수행 시 성능 지표 등을 확인하기 위해서는 쿼리 프로파일링(Query Profiling)을 활용해야 한다.
쿼리 프로파일링(Query Profiling)
MySQL 5.1 버전부터 지원하는 각 단계별 작업에 시간이 얼마나 걸렸는지 확인할 수 있는 기능
MySQL 기준, 프로파일링 옵션이 켜져있는지 확인하려면 아래의 명령어를 사용하면 된다.
show variables like 'profiling%';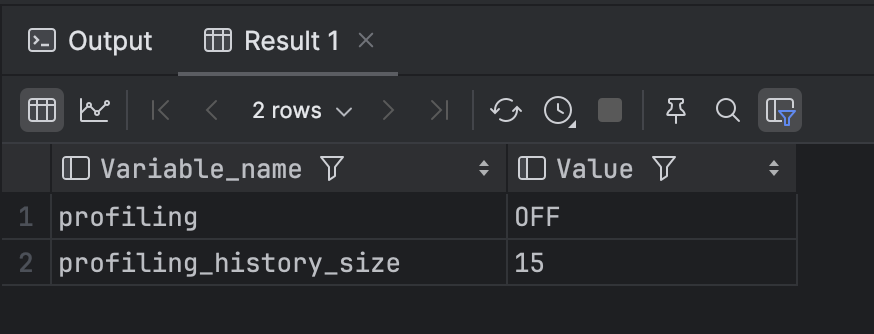
만약 프로파일링 옵션이 off로 설정되어 있다면 아래 명령어를 활용해서 프로파일링 옵션을 활성화할 수 있다.
set profiling = 'ON'확인하고 싶은 프로파일링 기록의 수를 늘리려면 아래의 명령어를 활용하면 된다.
set profiling_history_size = {기록의 수};쿼리 프로파일링 목록은 아래 명령어로 확인할 수 있다.
show profiles;특정 쿼리에 대해 자세히 보고자 한다면, 해당 쿼리 ID를 지정해서 확인할 수 있다.
show profile for query {Query_ID};예시
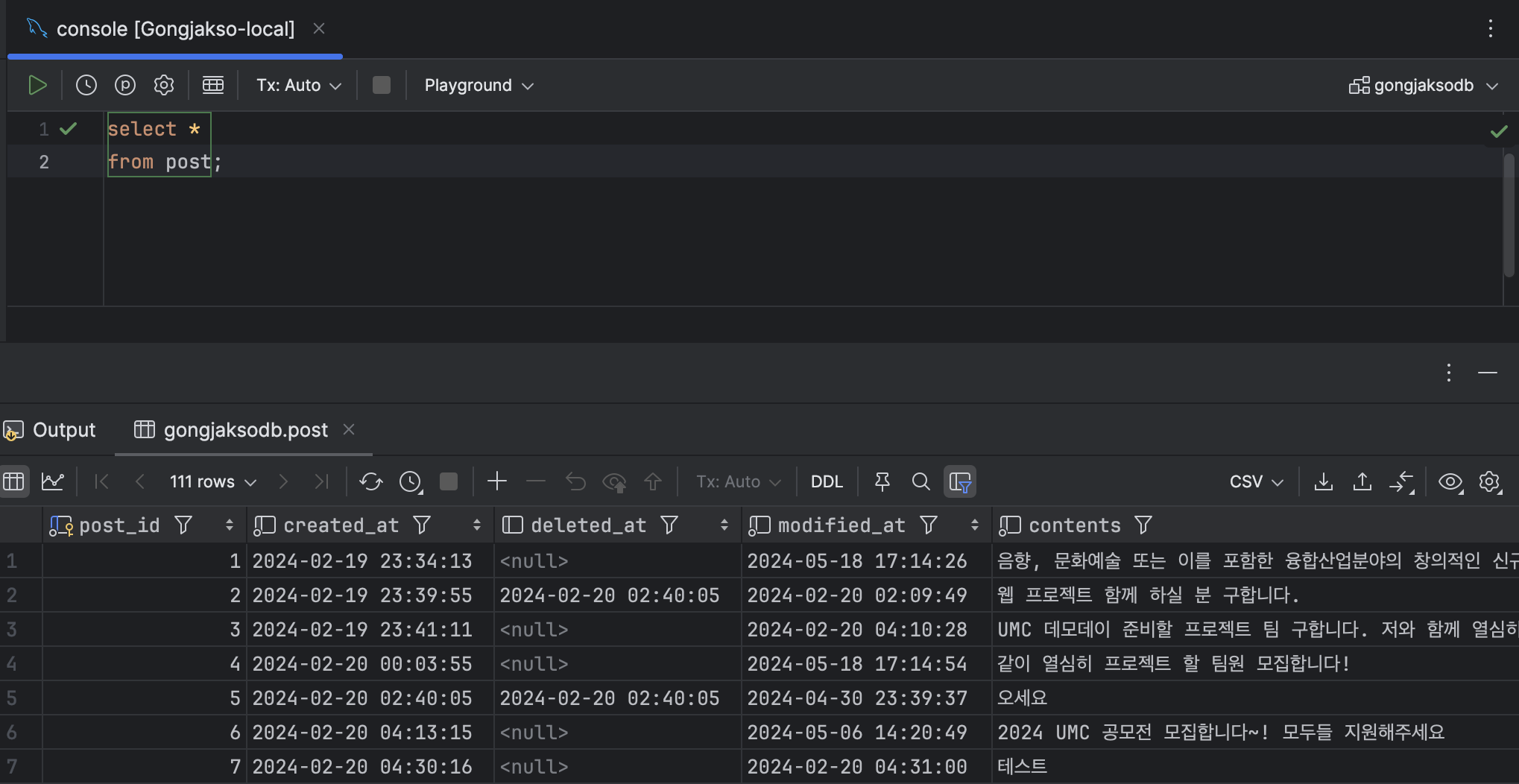
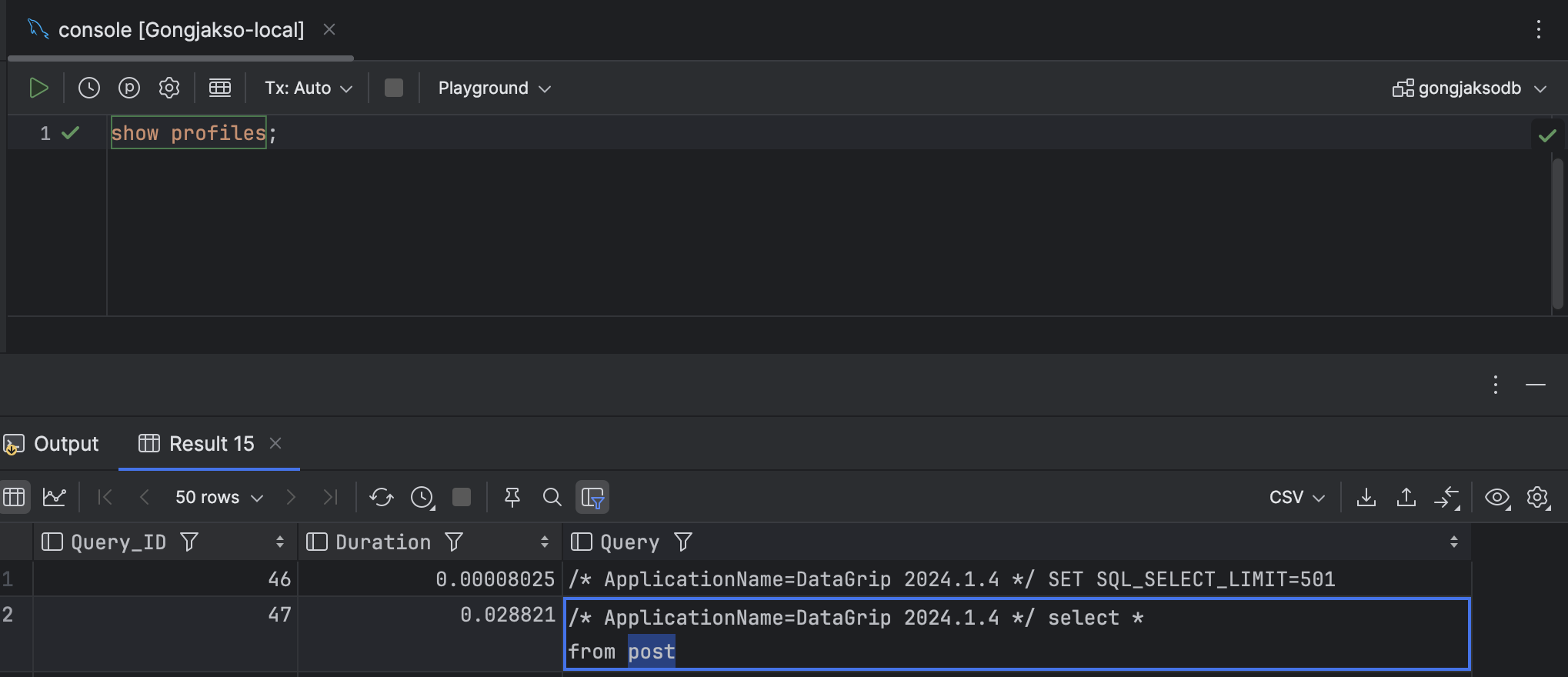 위 이미지에서, duration이 해당 쿼리가 실행되는데 소요된 시간이다.
위 이미지에서, duration이 해당 쿼리가 실행되는데 소요된 시간이다. 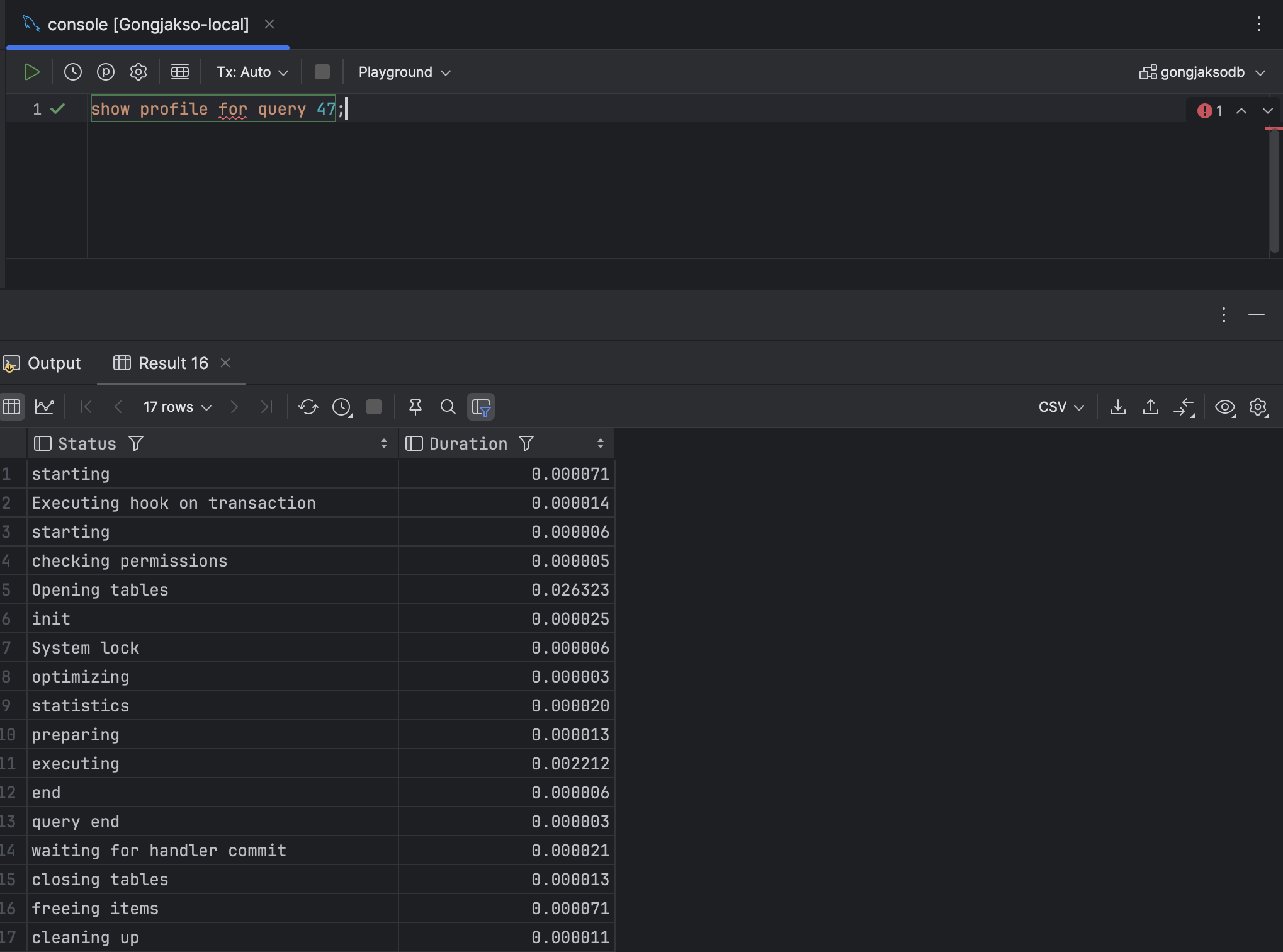
Ngram parser
Ngram Parser는 MySQL의 Full-text parser에 사용되는 내장 parser이다. 단어의 시작과 끝을 지정해 파싱하는 구분점이 되도록 토큰화하는 것으로, 중국어/일본어/한글을 지원한다.
즉, abcd라는 문자열이 있다면 이를 ab, bc, cd등의 토큰화시킨다.
특이점은 공백을 무시한 후 토큰화하기에, ab cd의 결과값도 위와 동일하다.
토큰으로 만드는 사이즈는 아래 명렁어로 확인한다. (기본값은 2이다.)
SHOW GLOBAL VARIABLES LIKE "ngram_token_size";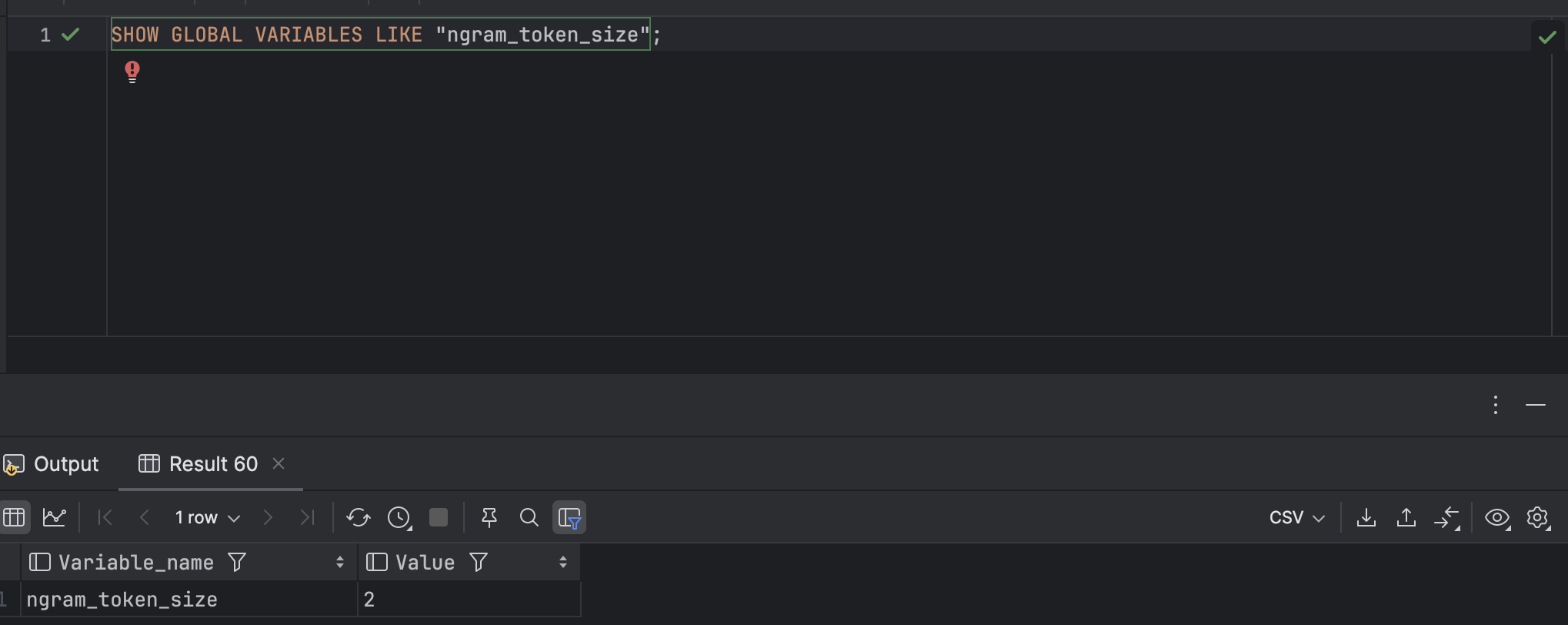
만약 사이즈를 변경하고 싶다면, 서버 시작 시 아래와 같이 옵션을 지정해야 한다.
mysqld --ngram_token_size=2토큰 사이즈가 작을수록 전체 텍스트 검색 색인이 작아져 검색 속도가 빨라진다는 것을 인지하고 있어야 한다.
여기서는 기본 사이즈인 2를 기준으로 진행한다.
Full-text index
MySQL의 검색타입에 정리했듯이, Full-text search를 활용하기 위해서는 전용 인덱스를 사용해야 한다. 전용 인덱스가 바로 Full-text index다.
Full-text index는 테이블 생성 시 지정이 가능하며, 이미 생성했다면 ALTER를 활용하여 추가할 수 있다.
// CREATE
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body) WITH PARSER ngram
) ENGINE=InnoDB CHARACTER SET utf8mb4;
// ALTER
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT
) ENGINE=InnoDB CHARACTER SET utf8mb4;
ALTER TABLE articles ADD FULLTEXT INDEX ft_index (title,body) WITH PARSER ngram;예시 데이터 삽입
articles라는 테이블에 제목과 본문이라는 두 개의 칼럼이 존재한다고 가정하고 데이터를 삽입한다. 예시 데이터 삽입 과정은 Claude의 도움을 받아 진행했다.
// 테이블 생성
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body) WITH PARSER ngram
) ENGINE=InnoDB CHARACTER SET utf8mb4;
// 찾고자하는 예시 데이터 삽입
INSERT INTO articles (title, body) VALUES
('MySQL 성능 최적화', 'MySQL 데이터베이스의 성능을 최적화하는 방법에 대해 알아봅시다.'),
('Full-text Search 사용법', 'MySQL에서 Full-text Search를 효과적으로 사용하는 방법을 설명합니다.'),
('Like 연산자의 장단점', 'Like 연산자는 간단하지만 대규모 데이터에서는 성능 이슈가 있을 수 있습니다.'),
('인덱스 설계의 중요성', '효율적인 인덱스 설계는 데이터베이스 쿼리 성능 향상에 큰 영향을 미칩니다.'),
('데이터베이스 백업 전략', '안전한 데이터 관리를 위한 효과적인 백업 전략을 수립해야 합니다.');
// 랜덤 텍스트를 활용해 데이터 수 늘리기
INSERT INTO articles (title, body)
SELECT
CONCAT('제목 ', FLOOR(RAND() * 1000000)),
CONCAT('내용 ', REPEAT('Lorem ipsum ', FLOOR(RAND() * 100)))
FROM
information_schema.columns
LIMIT {늘리고자 하는 칼럼 수};성능 측정 결과
Like
SELECT * FROM articles WHERE title LIKE '%성능%' OR body LIKE '%성능%';Full-text search
SELECT * FROM articles WHERE MATCH(title, body) AGAINST('성능' IN NATURAL LANGUAGE MODE);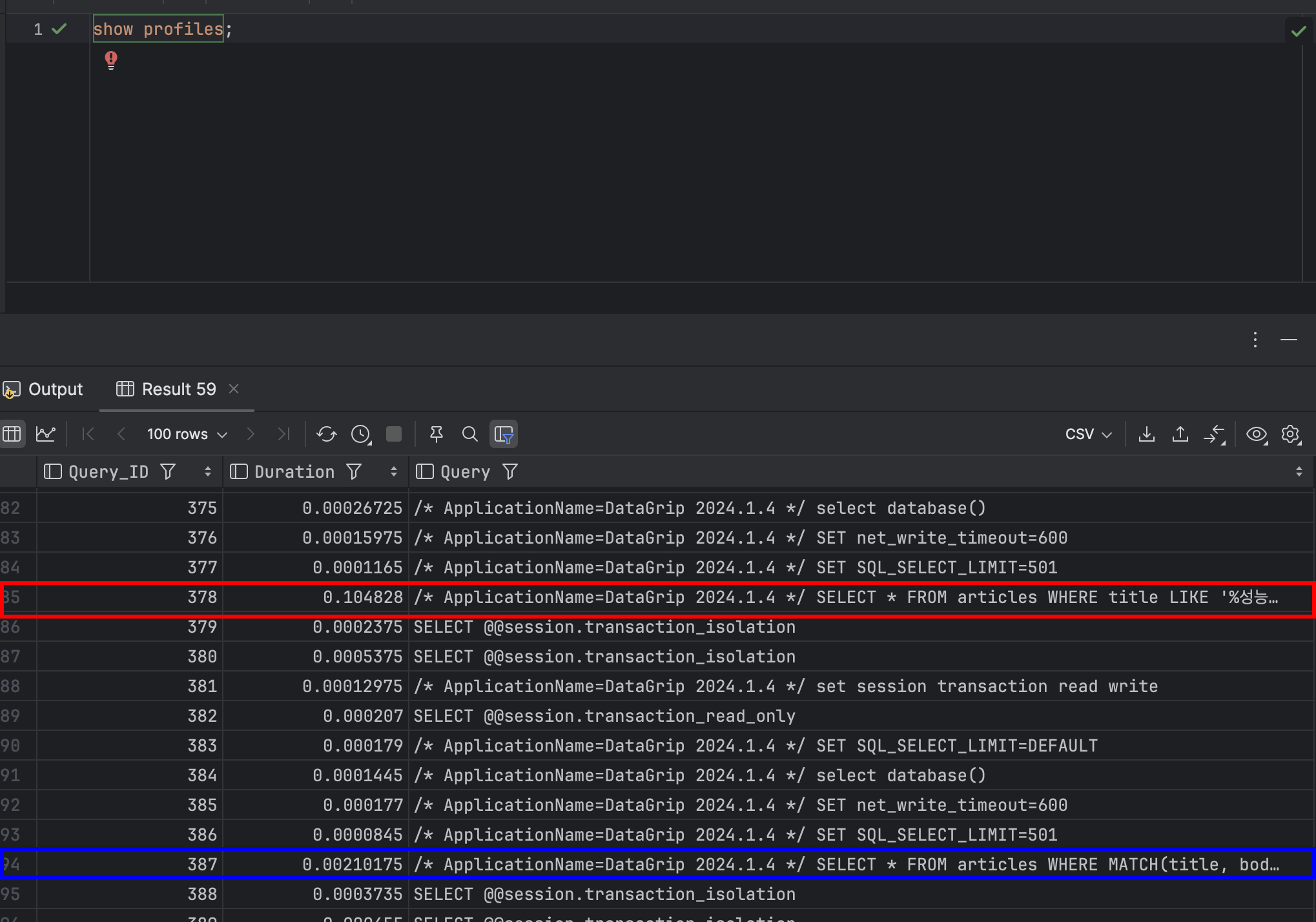
약 30,000건의 데이터 기준 성능은 위와 같다. 빨간색이 Like 쿼리이며, 파란색이 Full-text search이다.
데이터의 수가 적고 칼럼의 수도 적기에 엄청난 차이를 보이지는 않지만 유의미한 차이를 만들 수 있다는 것을 알 수 있다.
Spring Boot + MySQL 도입
개발 환경
- Java17
- Spring Boot 3.x
- MySQL 8.x
Full-text search용 칼럼 등록하기
공작소에서 검색이 적용되는 테이블은 Post 테이블이다.
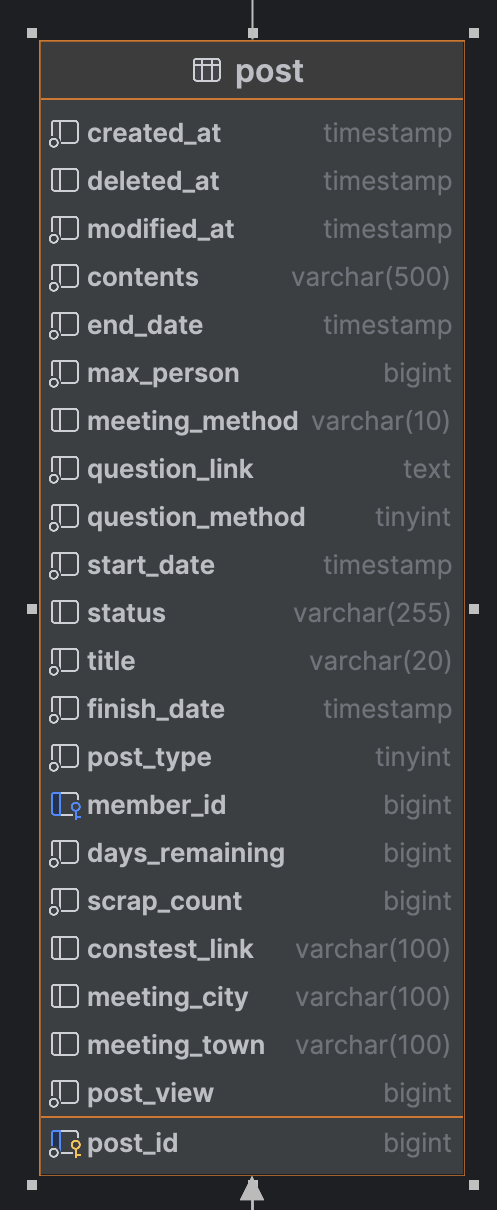
현재 검색에서 활용될 칼럼은 title과 contents칼럼이다.
그렇기에, ft_index라는 이름을 가진 FULLTEXT INDEXT 타입의 인덱스를 추가했다.
ALTER TABLE post ADD FULLTEXT INDEX ft_index (title, contents) WITH PARSER ngram;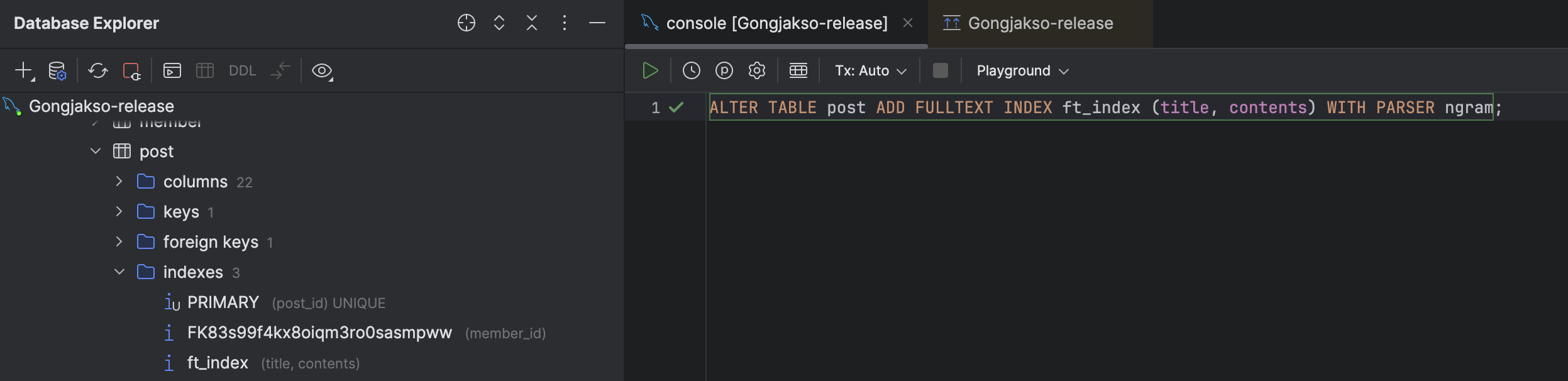
Refactoring
이번 Full-text search로 전환하는 김에 리팩토링을 진행하기로 결정했고, 리팩토링 이후 쿼리를 변경해야 하므로 이 과정을 먼저 정리한다.
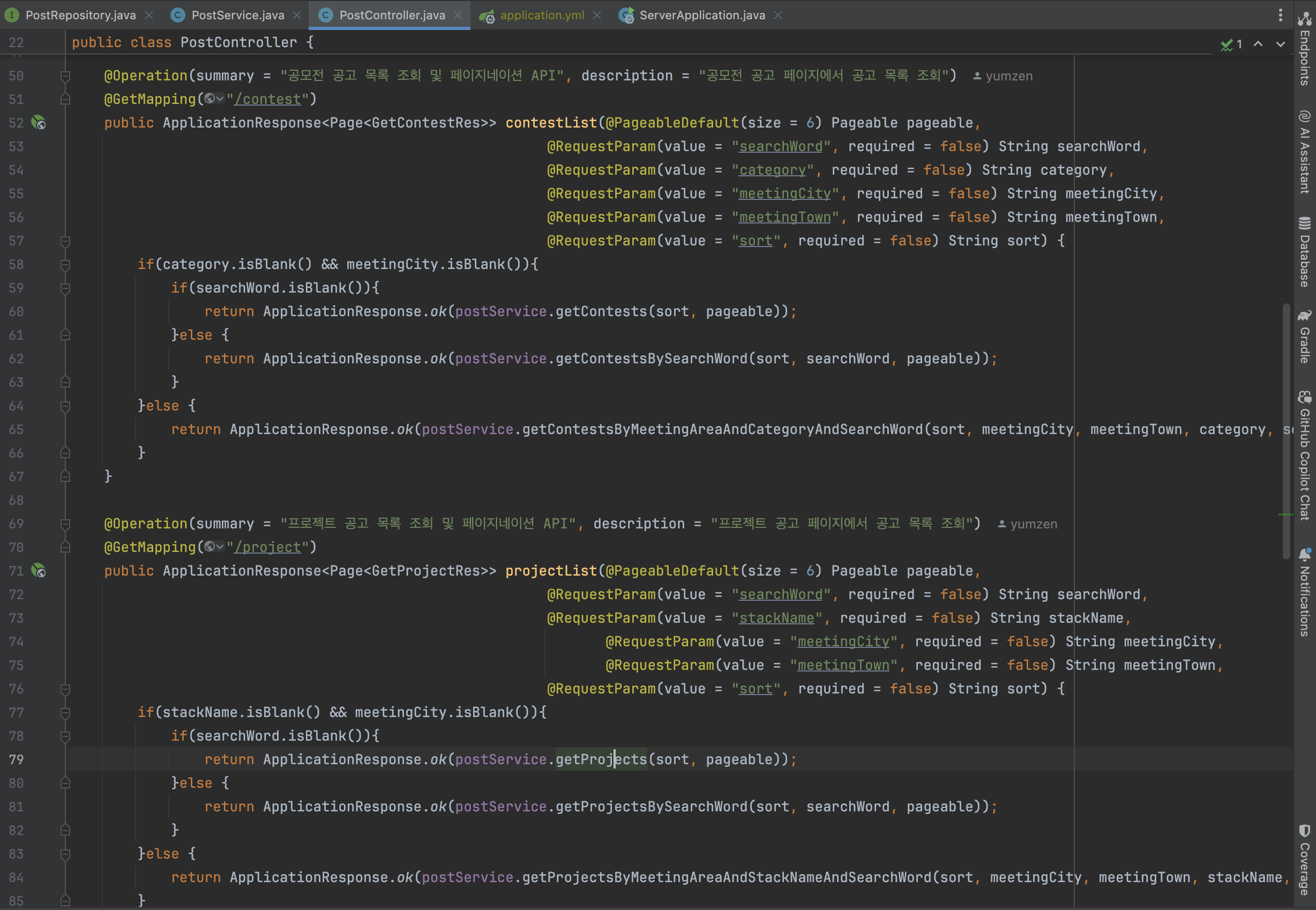
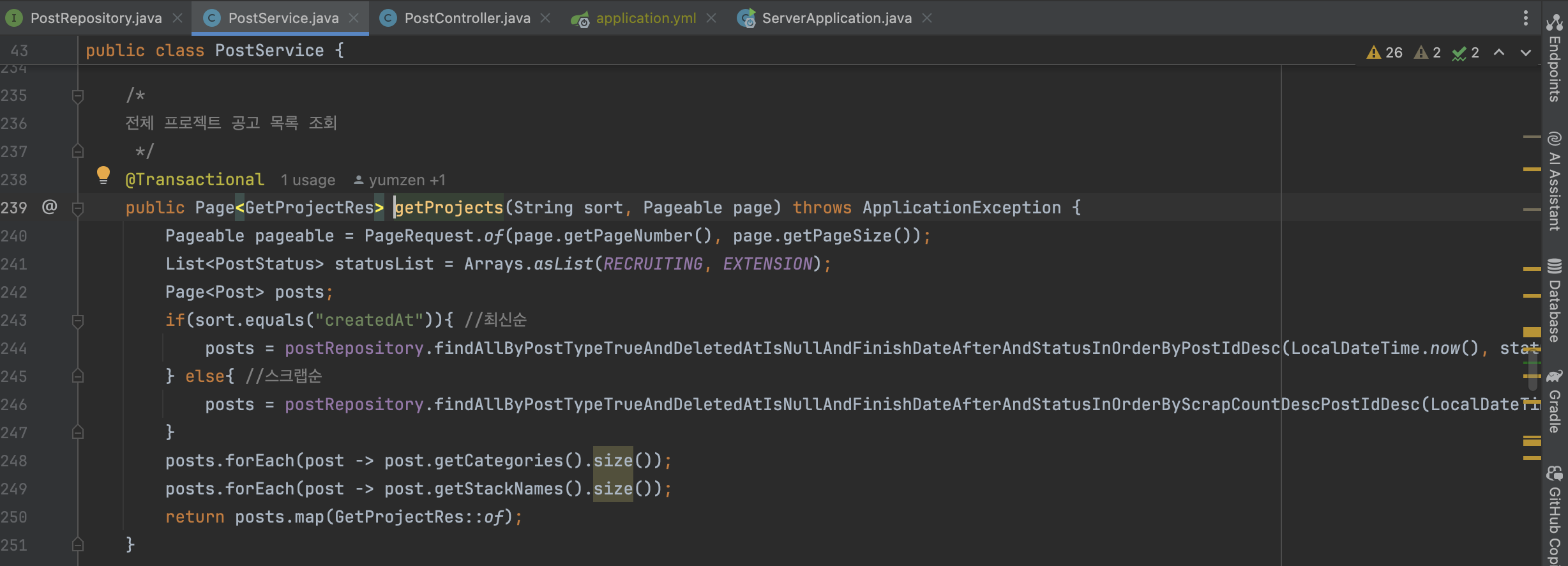
검색이 들어간 API는 두 가지다.
- 공모전 공고 목록 조회 및 페이지네이션 API
- 프로젝토 공고 목록 조회 및 페이지네이션 API
같은 테이블에 존재하지만, 공고의 타입에 따라 필터도 달라질 수 있기에 두 엔드포인트로 구분해서 개발했다.
개선하고자 하는 점은 아래와 같다.
-
필터 적용 계층의 결정
정렬 조건을 제외하고, 나머지 조건에 대해서는 Controller 계층에서 조건 분기 후 Service 계층을 호출하고 있다. 이는 필터 조건을 묶어서 관리하지 않으므로, 추후 다른 필터가 추가될 때마다 혼돈을 야기할 수 있다고 생각했다. 필터 적용 여부는 사용자 입력에 따라 비즈니스 로직에서 분기되어야 한다고 판단하여 Controller 계층에 있든 분기를 Service 계층으로 변경하는 것으로 결정했다. -
코드 가독성 문제(= 유지보수 문제)
검색이라는 한 기능에 대해 총 8번의 조건 분기를 가지고 있다 보니, 추후 유지보수 관점에서 새로운 조건이 생긴다는 등의 상황에서 비효율을 가져올 것이라고 생각했다.
위의 두 가지 개선점을 고려한 결과, JPA의 @Query를 활용해서 Native Query를 직접 작성해서 하나의 쿼리로 1번을 명확히 해결하며, 2번에서 유지보수 코스트를 그나마 줄일 수 있는 방안이라고 판단했다.
(Query DSL의 도입은 QueryDSL을 사용해본 팀원이 없고, 첫 프로젝트인 사람들이기에 일단 JPA를 더 다룬 뒤에 도입 여부를 결정하기로 했다.)
Sort를 Pageable에 포함시켜야 하지만, 프론트와 동시에 배포가 되어야 해당 방식을 다운타임 없이 적용할 수 있으므로, 임의로 Service 계층에서 Pageable 객체를 재생성하는 방식을 택했다.
Full-text search 적용
위의 리팩토링하고자 하는 내용을 포함해서 Full-text search를 적용한 쿼리로 변경했다.
1:N의 관계 처리하기

데이터베이스의 구조를 보면, 연관 관계로 인해 굉장히 많은 요소를 고려해야했다.
- Member:Post = 1:1
- Post:Category = 1:1
- Post:PostScrap = 1:N
- Post:StackName = 1:N
PostScrap의 경우, ScrapCount를 Post의 칼럼으로도 가지고 있는 반정규화를 통해 페이지네이션 시의 JOIN을 걸지 않을 수 있다.
다만, StackName은 검색 필터로도 사용되다보니 이는 필수적으로 JOIN을 묶어줘야 한다.
위와 같은 상황에서 2가지 방법을 고민했고, 그 중 후자의 방식을 선택했다.
N + 1 문제 해결을 포기하기
기본적으로 @ManyToOne을 활용한 이후, get@@@()라는 메소드를 활용해서 데이터를 가져올 경우, 추가적인 쿼리가 발생하게 되며, 우리는 이를 N+1 문제라고 칭한다.
FetchType.EAGER와FetchType.LAZY에 따라서는 쿼리의 발생시점에 차이만 있기에, 별도로 구분짓지 않았다.
N+1문제를 해결하기 위해서는 FetchJoin을 사용해야 하나, 이는 페이징 처리에서는 OOM과 관련된 경고를 출력하며 사용을 권장하지 않는다. (관련 자료)
그래서, Post데이터만 가져온 이후, Service 계층에서 이를 DTO로 바꾸는 stream().map()에서 쿼리를 통해 조회하여 바인딩할 수 있도록 변경하는 방법을 생각했었지만, 아래와 같은 이유로 해당 방법을 선택하지 않았다.
Post에 연관된 데이터가 많기에, 10개의 Post를 조회할 경우 사실상 31개의 쿼리가 발생한다. (Member, Category, StackName 각각 조회해야 하므로)
이는, Full-text Search를 활용해 응답 시간을 조금이라도 줄일려고 한 것들을 다 잃어버리게 될 것이라고 판단했다.
비즈니스 로직에서 합치기
Left Join을 통해 1:N의 관계에 있는 데이터들을 다 가져오고, 이를 DTO로 변환하는 과정에서 합치고자 했다.
이 방식을 선택하게 된 이유는 아래와 같다.
- QueryDSL의
transform()과 유사한 방식 - 쿼리는 최초 발생 이후, 별도의 쿼리 발생 X
- Service 계층에서 데이터를 조합하므로 반환하는 데이터 형식이 바뀌었을 때 수정하기 용이
Offset 활용 불가능한 오류
위와 같이 비즈니스 로직에서 합치고자 한다면, 데이터 중 Post 1개에 4개의 category가 있는 Post가 존재할 경우, size가 6임에도 불구하고 3개의 Post만 조회되게 된다. (A라는 Post에 관련된 Row만 4개)
Offset쿼리를 올바르게 적용할 수 없다는 것이다.
이 문제를 최소화하기 위해, 검색 조건에 해당하는 Post 공고를 조회한 이후, 해당 Post Id에 해당하는 데이터를 가져오는 방식으로 두 개의 쿼리로 분리하여 개발했다.
결과값의 순서 보장하기
비즈니스 로직에서 Id값만 리스트로 조회한 이후, 이를 in조건문을 활용한 쿼리를 통해 전체 데이터를 가져오는 과정에서 순서를 보장할 수 없다. 그렇기에, 정렬 순서를 위한 switch문을 한 번 더 활용해야 한다.
이외에도, DTO로 변환할 때 Map을 활용하게 되는데, HashMap을 활용할 경우에도 순서를 보장할 수 없기 때문에 LinkedHashMap을 활용해야 한다.
별칭 중복으로 인한 문제 해결
Encountered a duplicated sql alias [post_id] during auto-discovery of a native-sql query라는 오류를 마주쳤다.
이는 select p.*, m.*, c.*과 같이 쿼리를 작성했더니, created_at과 같은 BaseEntity 칼럼들이 중복되어 발생하는 문제였다.
이를 해결하기 위해 Closed Projection을 활용하여 필요한 데이터만을 뽑을 수 있도록 수정했다.
코드
공모전 Service
@Transactional(readOnly = true)
public Page<GetContestRes> getContestsByFilter(String sort, String meetingCity, String meetingTown, String category, String searchWord, Pageable page) {
// Business Logic
List<String> statusList = Arrays.asList(PostStatus.RECRUITING.toString(), PostStatus.EXTENSION.toString()); // 공고가 모집/연장 상태인 경우만 조회되도록 하기 위한 상태값 설정
String search = (searchWord != null && !searchWord.isEmpty()) ? searchWord.toLowerCase() : searchWord;
Sort sortCondition = switch (sort) {
case "createdAt" -> Sort.by("created_at").descending();
case "scrapCount" -> Sort.by("scrap_count").descending();
default -> throw new IllegalStateException("Unexpected value: " + sort);
};
page = PageRequest.of(page.getPageNumber(), page.getPageSize(), sortCondition);
Page<Long> postIdPage = postRepository.findContestPaginationByFilter(
search,
LocalDateTime.now(),
statusList,
meetingCity,
meetingTown,
page
);
List<ContestProjection> contestProjectionList = switch (sort) {
case "createdAt" -> postRepository.findContestProjectionListByPostIdListAndCreatedAtDesc(postIdPage.getContent());
case "scrapCount" -> postRepository.findContestProjectionListByPostIdListAndScrapCountAtDesc(postIdPage.getContent());
default -> throw new IllegalStateException("Unexpected value: " + sort);
};
// PostId 기준으로 그룹화
Map<Long, List<ContestProjection>> groupedByPostId = contestProjectionList.stream()
.collect(Collectors.groupingBy(ContestProjection::getPostId, LinkedHashMap::new, Collectors.toList()));
// PostId 기준으로 그룹화된 맵을 사용하여 GetContestRes 객체 리스트 생성
List<GetContestRes> contestResList = groupedByPostId.entrySet().stream()
.map(entry -> {
Long postId = entry.getKey();
List<ContestProjection> contestProjections = entry.getValue();
// CategoryRes 리스트 구성
List<CategoryRes> categoryResList = contestProjections.stream()
.filter(contestProjection -> contestProjection.getCategoryId() != null && contestProjection.getCategoryType() != null && contestProjection.getCategorySize() != null)
.map(contestProjection -> CategoryRes.builder()
.categoryId(contestProjection.getCategoryId())
.categoryType(contestProjection.getCategoryType())
.size(contestProjection.getCategorySize())
.build())
.collect(Collectors.toList());
// GetContestRes 객체 생성
ContestProjection firstProjection = contestProjections.get(0); // 여기서도 첫 번째 객체를 가져올 수 있습니다.
return GetContestRes.builder()
.postId(postId)
.title(firstProjection.getTitle())
.name(firstProjection.getMemberName())
.status(firstProjection.getStatus())
.startDate(firstProjection.getStartDate())
.endDate(firstProjection.getEndDate())
.finishDate(firstProjection.getFinishDate())
.daysRemaining(firstProjection.getDaysRemaining())
.categories(categoryResList)
.scrapCount(firstProjection.getScrapCount())
.build();
})
.collect(Collectors.toList());
// Response
return new PageImpl<>(contestResList, postIdPage.getPageable(), postIdPage.getTotalPages());
}공모전 Repository
@Query(value = """
select p.post_id
from post p
left join member m on p.member_id = m.member_id
left join category c on p.post_id = c.post_id
where p.post_type = false
and p.deleted_at is null
and p.finish_date > :currentTimestamp
and p.status in (:status)
and (
case
when :searchWord is not null and :searchWord != '' then match(p.title, p.contents) against(:searchWord in natural language mode)
else true
end
)
and (
case
when :meetingCity is not null and :meetingCity != '' then p.meeting_city = :meetingCity
else true
end
)
and (
case
when :meetingTown is not null and :meetingTown != '' then p.meeting_town = :meetingTown
else true
end
)
group by p.post_id
""",
countQuery = """
SELECT COUNT(*)
FROM post p
LEFT JOIN member m ON p.member_id = m.member_id
LEFT JOIN category c ON p.post_id = c.post_id
WHERE p.post_type = false
AND p.deleted_at IS NULL
AND p.finish_date > :currentTimestamp
AND p.status IN (:status)
AND (
CASE
WHEN :searchWord IS NOT NULL AND :searchWord != '' THEN MATCH(p.title, p.contents) AGAINST(:searchWord IN natural language mode)
ELSE 1=1
END
)
AND (
CASE
WHEN :meetingCity IS NOT NULL AND :meetingCity != '' THEN p.meeting_city = :meetingCity
ELSE 1=1
END
)
AND (
CASE
WHEN :meetingTown IS NOT NULL AND :meetingTown != '' THEN p.meeting_town = :meetingTown
ELSE 1=1
END
)
group by p.post_id
""",
nativeQuery = true)
Page<Long> findContestPaginationByFilter(@Param("searchWord") String searchWord,
@Param("currentTimestamp") LocalDateTime currentTimestamp,
@Param("status") List<String> status,
@Param("meetingCity") String meetingCity,
@Param("meetingTown") String meetingTown,
Pageable pageable);
@Query(value = """
select p.post_id as postId, p.title as title, m.member_id as memberId, m.name as memberName, p.status as status, p.start_date as startDate, p.end_date as endDate, p.finish_date as finishDate, p.days_remaining as daysRemaining, c.category_id as categoryId, c.category_type as categoryType, c.size as categorySize, p.scrap_count as scrapCount
from post p
left join member m on p.member_id = m.member_id
left join category c on p.post_id = c.post_id
where p.post_id in (:postIdList)
order by p.created_at desc
""", nativeQuery = true
)
List<ContestProjection> findContestProjectionListByPostIdListAndCreatedAtDesc(@Param("postIdList") List<Long> postIdList);
@Query(value = """
select p.post_id as postId, p.title as title, m.member_id as memberId, m.name as memberName, p.status as status, p.start_date as startDate, p.end_date as endDate, p.finish_date as finishDate, p.days_remaining as daysRemaining, c.category_id as categoryId, c.category_type as categoryType, c.size as categorySize, p.scrap_count as scrapCount
from post p
left join member m on p.member_id = m.member_id
left join category c on p.post_id = c.post_id
where p.post_id in (:postIdList)
order by p.scrap_count desc
""", nativeQuery = true
)
List<ContestProjection> findContestProjectionListByPostIdListAndScrapCountAtDesc(@Param("postIdList") List<Long> postIdList);프로젝트 Service
@Transactional(readOnly = true)
public Page<GetProjectRes> getProjectsByFilter(String sort, String meetingCity, String meetingTown, String stackName, String searchWord, Pageable page) {
// Validation
if(stackName != null && !stackName.isBlank() && !StackNameType.isValid(stackName)) {
throw new ApplicationException(INVALID_VALUE_EXCEPTION);
}
// Business Logic
List<String> statusList = Arrays.asList(PostStatus.RECRUITING.toString(), PostStatus.EXTENSION.toString()); // 공고가 모집/연장 상태인 경우만 조회되도록 하기 위한 상태값 설정
String search = (searchWord != null && !searchWord.isEmpty()) ? searchWord.toLowerCase() : searchWord;
Sort sortCondition = switch (sort) {
case "createdAt" -> Sort.by("created_at").descending();
case "scrapCount" -> Sort.by("scrap_count").descending();
default -> throw new IllegalStateException("Unexpected value: " + sort);
};
System.out.println(searchWord);
page = PageRequest.of(page.getPageNumber(), page.getPageSize(), sortCondition);
Page<Long> postIdPage = postRepository.findProjectPaginationByFilter(
search,
LocalDateTime.now(),
statusList,
meetingCity,
meetingTown,
stackName,
page
);
List<ProjectProjection> projectProjectionList = switch (sort) {
case "createdAt" -> postRepository.findProjectProjectionListByPostIdListAndCreatedAtDesc(postIdPage.getContent());
case "scrapCount" -> postRepository.findProjectProjectionListByPostIdListAndScrapCountDesc(postIdPage.getContent());
default -> throw new IllegalStateException("Unexpected value: " + sort);
};
// PostId 기준으로 그룹화
Map<Long, List<ProjectProjection>> groupedByPostId = projectProjectionList.stream()
.collect(Collectors.groupingBy(ProjectProjection::getPostId, LinkedHashMap::new, Collectors.toList()));
List<GetProjectRes> projectResList = groupedByPostId.entrySet().stream()
.map(entry -> {
Long postId = entry.getKey();
List<ProjectProjection> projections = entry.getValue();
// CategoryRes 리스트 구성 (중복 제거)
Set<CategoryRes> categoryResSet = projections.stream()
.filter(contestProjection -> contestProjection.getCategoryId() != null
&& contestProjection.getCategoryType() != null
&& contestProjection.getCategorySize() != null)
.map(category -> CategoryRes.builder()
.categoryId(category.getCategoryId())
.categoryType(category.getCategoryType())
.size(category.getCategorySize())
.build())
.collect(Collectors.toSet()); // Set으로 수집하여 중복 제거
// StackName 리스트 구성 (중복 제거)
Set<StackNameRes> stackNameSet = projections.stream()
.filter(stack -> stack != null
&& stack.getStackNameId() != null
&& stack.getStackNameType() != null)
.map(stack -> StackNameRes.builder()
.stackNameId(stack.getStackNameId())
.stackNameType(stack.getStackNameType())
.build())
.collect(Collectors.toSet()); // Set으로 수집하여 중복 제거
// GetProjectRes 객체 생성
ProjectProjection firstProjection = projections.get(0);
return GetProjectRes.builder()
.postId(postId)
.title(firstProjection.getTitle())
.name(firstProjection.getMemberName())
.status(firstProjection.getStatus())
.startDate(firstProjection.getStartDate())
.endDate(firstProjection.getEndDate())
.finishDate(firstProjection.getFinishDate())
.daysRemaining(firstProjection.getDaysRemaining())
.categories(new ArrayList<>(categoryResSet)) // Set을 List로 변환
.stackNames(new ArrayList<>(stackNameSet)) // Set을 List로 변환
.scrapCount(firstProjection.getScrapCount())
.build();
})
.collect(Collectors.toList());
// Response
return new PageImpl<>(projectResList, postIdPage.getPageable(), postIdPage.getTotalPages());
}프로젝트 Repository
@Query(value = """
select p.post_id
from post p
left join member m on p.member_id = m.member_id
left join category c on p.post_id = c.post_id
left join stack_name sn on p.post_id = sn.post_id
WHERE p.post_type = true
AND p.deleted_at IS NULL
AND p.finish_date > :currentTimestamp
AND p.status IN (:status)
and (
case
when :searchWord is not null and :searchWord != '' then match(p.title, p.contents) against(:searchWord in natural language mode)
else true
end
)
and (
case
when :meetingCity is not null and :meetingCity != '' then p.meeting_city = :meetingCity
else true
end
)
and (
case
when :meetingTown is not null and :meetingTown != '' then p.meeting_town = :meetingTown
else true
end
)
and (
case
when :stackName is not null and :stackName != '' then sn.stack_name_type = :stackName
else true
end
)
group by p.post_id
""",
countQuery = """
select count(*)
FROM post p
left join member m on p.member_id = m.member_id
left join category c on p.post_id = c.post_id
left join stack_name sn on p.post_id = sn.post_id
WHERE p.post_type = true
AND p.deleted_at IS NULL
AND p.finish_date > :currentTimestamp
AND p.status IN (:status)
and (
case
when :searchWord is not null and :searchWord != '' then match(p.title, p.contents) against(:searchWord in natural language mode)
else 1=1
end
)
and (
case
when :meetingCity is not null and :meetingCity != '' then p.meeting_city = :meetingCity
else 1=1
end
)
and (
case
when :meetingTown is not null and :meetingTown != '' then p.meeting_town = :meetingTown
else 1=1
end
)
and (
case
when :stackName is not null and :stackName != '' then sn.stack_name_type = :stackName
else 1=1
end
)
group by p.post_id
""",
nativeQuery = true)
Page<Long> findProjectPaginationByFilter(
@Param("searchWord") String searchWord,
@Param("currentTimestamp") LocalDateTime currentTimestamp,
@Param("status") List<String> status,
@Param("meetingCity") String meetingCity,
@Param("meetingTown") String meetingTown,
@Param("stackName") String stackName,
Pageable pageable
);
@Query(value = """
select p.post_id as postId, p.title as title, m.member_id as memberId, m.name as memberName, p.status as status, p.start_date as startDate, p.end_date as endDate, p.finish_date as finishDate, p.days_remaining as daysRemaining, c.category_id as categoryId, c.category_type as categoryType, c.size as categorySize, sn.stack_name_id as stackNameId, sn.stack_name_type as stackNameType, p.scrap_count as scrapCount
from post p
left join member m on p.member_id = m.member_id
left join category c on p.post_id = c.post_id
left join stack_name sn on p.post_id = sn.post_id
where p.post_id in (:postIdList)
order by p.created_at desc
""", nativeQuery = true)
List<ProjectProjection> findProjectProjectionListByPostIdListAndCreatedAtDesc(@Param("postIdList") List<Long> postIdList);
@Query(value = """
select p.post_id as postId, p.title as title, m.member_id as memberId, m.name as memberName, p.status as status, p.start_date as startDate, p.end_date as endDate, p.finish_date as finishDate, p.days_remaining as daysRemaining, c.category_id as categoryId, c.category_type as categoryType, c.size as categorySize, sn.stack_name_id as stackNameId, sn.stack_name_type as stackNameType, p.scrap_count as scrapCount
from post p
left join member m on p.member_id = m.member_id
left join category c on p.post_id = c.post_id
left join stack_name sn on p.post_id = sn.post_id
where p.post_id in (:postIdList)
order by p.scrap_count desc
""", nativeQuery = true)
List<ProjectProjection> findProjectProjectionListByPostIdListAndScrapCountDesc(@Param("postIdList") List<Long> postIdList);OrderBy는 왜 작성하지 않았는가?
JPA를 이용할 경우, Pageable 객체가 매개변수에 존재한다면 자동적으로 바인딩시킨다. 다만, Native Query에 있으면 무시되므로 이를 생각해 Native Query에서는 별도로 정렬 조건을 작성하지 않았다.
결과
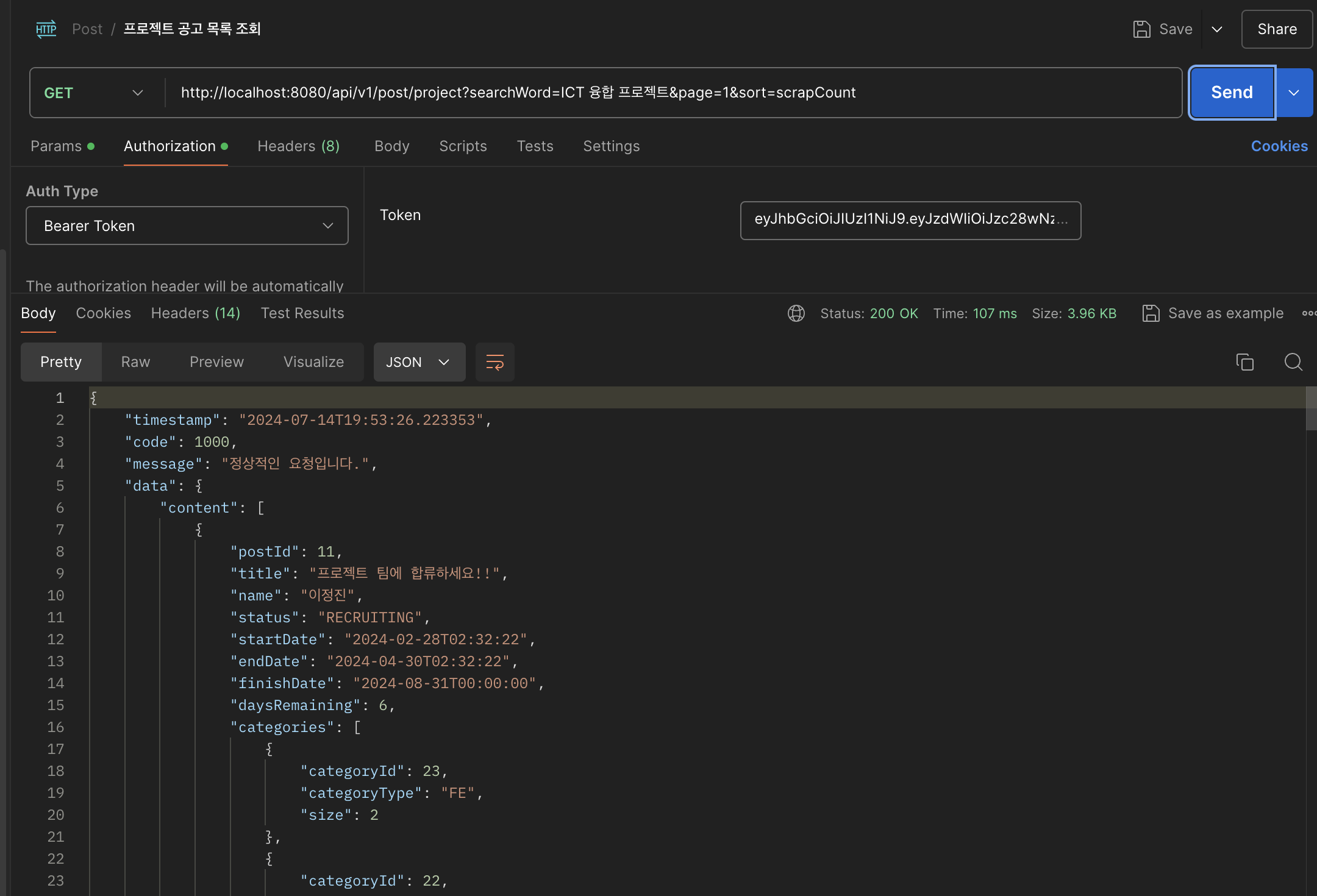 위와 같이
위와 같이 ICT 융합 프로젝트라는 키워드로 검색했음에도 불구하고, 프로젝트라는 키워드의 유사도로 인해 다른 프로젝트까지 잘 조회되는 것을 확인할 수 있다. 단순 문자열 완전 일치를 넘어서 유사도가 높아도 조회될 수 있으므로, 사용자들이 검색 과정에서 관련 정보를 더욱 쉽게 찾아볼 수 있다.
개발 코드 전체는 공작소 서버 Repository에서 확인할 수 있다.
후기
이 모든 과정을 JPA로 해결해보면서 QueryDSL의 필요성을 굉장히 많이 느꼈다. JooQ라는 것이 활용되고 있는 경우도 많기에, 시간이 된다면 JooQ를 이용해서 다루는 과정도 한 번 정리해볼 예정이다.
QueryDSL 최고다..
또한, 위 내용 중 실제 적용 과정은 Full-text search 적용 과정이지만, 공작소 프로젝트의 특성에 따라 다양한 부분이 변경되어 적용되었기에 보시는 분들은 참고용도로만 활용하시면 좋을 것 같다.
레퍼런스
