Transformer code 분석
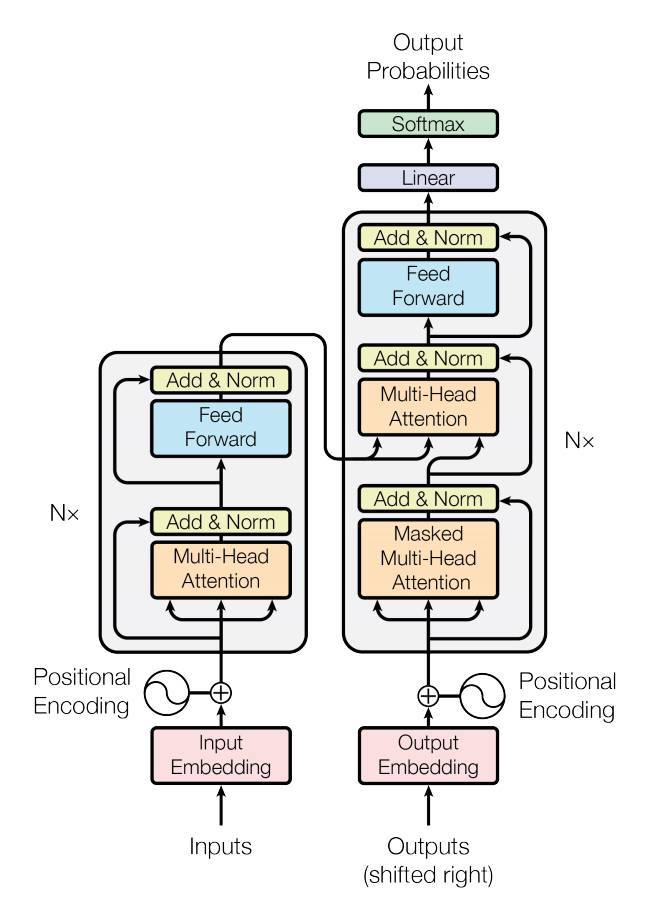
Cross Attention을 구현하기 위한 초석으로
나동빈님의 코드를 분석하며 개인적으로 정리하는 글입니다.
import torch.nn as nn
class MultiHeadAttentionLayer(nn.Module):
def __init__(self, hidden_dim, n_heads, dropout_ratio, device):
super().__init__()
assert hidden_dim % n_heads == 0
self.hidden_dim = hidden_dim # 임베딩 차원
self.n_heads = n_heads # 헤드(head)의 개수 ( 논문은 8개 )
self.head_dim = hidden_dim // n_heads # 각 헤드(head)에서의 임베딩 차원
self.fc_q = nn.Linear(hidden_dim, hidden_dim)
# Query 값에 적용될 FC 레이어
self.fc_k = nn.Linear(hidden_dim, hidden_dim)
# Key 값에 적용될 FC 레이어
self.fc_v = nn.Linear(hidden_dim, hidden_dim)
# Value 값에 적용될 FC 레이어
self.fc_o = nn.Linear(hidden_dim, hidden_dim)
self.dropout = nn.Dropout(dropout_ratio)
self.scale = torch.sqrt(torch.FloatTensor([self.head_dim])).to(device)
def forward(self, query, key, value, mask = None):
batch_size = query.shape[0]
# query: [batch_size, query_len, hidden_dim]
# key: [batch_size, key_len, hidden_dim]
# value: [batch_size, value_len, hidden_dim]
Q = self.fc_q(query)
K = self.fc_k(key)
V = self.fc_v(value)
# Q: [batch_size, query_len, hidden_dim]
# K: [batch_size, key_len, hidden_dim]
# V: [batch_size, value_len, hidden_dim]
# hidden_dim → n_heads X head_dim 형태로 변형
# n_heads(h)개의 서로 다른 어텐션(attention) 컨셉을 학습하도록 유도
Q = Q.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
K = K.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
V = V.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
# Q: [batch_size, n_heads, query_len, head_dim]
# K: [batch_size, n_heads, key_len, head_dim]
# V: [batch_size, n_heads, value_len, head_dim]
# Attention Energy 계산
energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
# energy: [batch_size, n_heads, query_len, key_len]
# 마스크(mask)를 사용하는 경우
if mask is not None:
# 마스크(mask) 값이 0인 부분을 -1e10으로 채우기
energy = energy.masked_fill(mask==0, -1e10)
# 어텐션(attention) 스코어 계산: 각 단어에 대한 확률 값
attention = torch.softmax(energy, dim=-1)
# attention: [batch_size, n_heads, query_len, key_len]
# 여기에서 Scaled Dot-Product Attention을 계산
x = torch.matmul(self.dropout(attention), V)
# x: [batch_size, n_heads, query_len, head_dim]
x = x.permute(0, 2, 1, 3).contiguous()
# x: [batch_size, query_len, n_heads, head_dim]
x = x.view(batch_size, -1, self.hidden_dim)
# x: [batch_size, query_len, hidden_dim]
x = self.fc_o(x) # x: [batch_size, query_len, hidden_dim]
# x: [batch_size, query_len, hidden_dim]
> return x, attention풍부한 관점에서 feature을 보기 위해 MultiHeadAttention을 채택
Head가 사람, Attention이 시각이라고 생각했을때 다양한 사람이 보는 시각이 다 다르기 때문에 좋은 특징공간을 찾을 수 있을거라 생각함
Positionwise
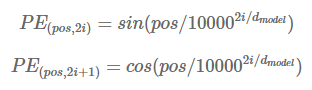
class PositionwiseFeedforwardLayer(nn.Module):
def __init__(self, hidden_dim, pf_dim, dropout_ratio):
super().__init__()
self.fc_1 = nn.Linear(hidden_dim, pf_dim)
self.fc_2 = nn.Linear(pf_dim, hidden_dim)
self.dropout = nn.Dropout(dropout_ratio)
def forward(self, x):
# x: [batch_size, seq_len, hidden_dim]
x = self.dropout(torch.relu(self.fc_1(x)))
# x: [batch_size, seq_len, pf_dim]
x = self.fc_2(x)
# x: [batch_size, seq_len, hidden_dim]
return x위치별 특징을 적용시키기 위한 것으로 서로 다른 주기를 가지는 sin, cos을 채택
동일 column이어도, pos값이 다를경우 다른 값이 되므로 겹치는 정보를 갖는것을 방지
EncoderLayer
class EncoderLayer(nn.Module):
def __init__(self, hidden_dim, n_heads, pf_dim, dropout_ratio, device):
super().__init__()
self.self_attn_layer_norm = nn.LayerNorm(hidden_dim)
self.ff_layer_norm = nn.LayerNorm(hidden_dim)
self.self_attention = MultiHeadAttentionLayer(hidden_dim, n_heads, dropout_ratio, device)
self.positionwise_feedforward = PositionwiseFeedforwardLayer(hidden_dim, pf_dim, dropout_ratio)
self.dropout = nn.Dropout(dropout_ratio)
# 하나의 임베딩이 복제되어 Query, Key, Value로 입력되는 방식
def forward(self, src, src_mask):
# src: [batch_size, src_len, hidden_dim]
# src_mask: [batch_size, src_len]
# self attention
# 필요한 경우 마스크(mask) 행렬을 이용하여 어텐션(attention)할 단어를 조절 가능
_src, _ = self.self_attention(src, src, src, src_mask)
# dropout, residual connection and layer norm
src = self.self_attn_layer_norm(src + self.dropout(_src))
# src: [batch_size, src_len, hidden_dim]
# position-wise feedforward
_src = self.positionwise_feedforward(src)
# dropout, residual and layer norm
src = self.ff_layer_norm(src + self.dropout(_src))
# src: [batch_size, src_len, hidden_dim]
return srcsrc 번역하는 문장 즉, input을 통과시키는 layer을 의미
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, n_layers, n_heads, pf_dim, dropout_ratio, device, max_length=100):
super().__init__()
self.device = device
self.tok_embedding = nn.Embedding(input_dim, hidden_dim)
self.pos_embedding = nn.Embedding(max_length, hidden_dim)
self.layers = nn.ModuleList([EncoderLayer(hidden_dim, n_heads, pf_dim, dropout_ratio, device) for _ in range(n_layers)])
self.dropout = nn.Dropout(dropout_ratio)
self.scale = torch.sqrt(torch.FloatTensor([hidden_dim])).to(device)
def forward(self, src, src_mask):
# src: [batch_size, src_len]
# src_mask: [batch_size, src_len]
batch_size = src.shape[0]
src_len = src.shape[1]
pos = torch.arange(0, src_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
# pos: [batch_size, src_len]
# 소스 문장의 임베딩과 위치 임베딩을 더한 것을 사용
src = self.dropout((self.tok_embedding(src) * self.scale) + self.pos_embedding(pos))
# src: [batch_size, src_len, hidden_dim]
# 모든 인코더 레이어를 차례대로 거치면서 순전파(forward) 수행
for layer in self.layers:
src = layer(src, src_mask)
# src: [batch_size, src_len, hidden_dim]
return src # 마지막 레이어의 출력을 반환encoder는 layer을 6개 쌓으므로 encoder layer와 structure을 구분해서 구현
class DecoderLayer(nn.Module):
def __init__(self, hidden_dim, n_heads, pf_dim, dropout_ratio, device):
super().__init__()
self.self_attn_layer_norm = nn.LayerNorm(hidden_dim)
self.enc_attn_layer_norm = nn.LayerNorm(hidden_dim)
self.ff_layer_norm = nn.LayerNorm(hidden_dim)
self.self_attention = MultiHeadAttentionLayer(hidden_dim, n_heads, dropout_ratio, device)
self.encoder_attention = MultiHeadAttentionLayer(hidden_dim, n_heads, dropout_ratio, device)
self.positionwise_feedforward = PositionwiseFeedforwardLayer(hidden_dim, pf_dim, dropout_ratio)
self.dropout = nn.Dropout(dropout_ratio)
# 인코더의 출력 값(enc_src)을 어텐션(attention)하는 구조
def forward(self, trg, enc_src, trg_mask, src_mask):
# trg: [batch_size, trg_len, hidden_dim]
# enc_src: [batch_size, src_len, hidden_dim]
# trg_mask: [batch_size, trg_len]
# src_mask: [batch_size, src_len]
# self attention
# 자기 자신에 대하여 어텐션(attention)
_trg, _ = self.self_attention(trg, trg, trg, trg_mask)
# dropout, residual connection and layer norm
trg = self.self_attn_layer_norm(trg + self.dropout(_trg))
# trg: [batch_size, trg_len, hidden_dim]
# encoder attention
# 디코더의 쿼리(Query)를 이용해 인코더를 어텐션(attention)
_trg, attention = self.encoder_attention(trg, enc_src, enc_src, src_mask)
# dropout, residual connection and layer norm
trg = self.enc_attn_layer_norm(trg + self.dropout(_trg))
# trg: [batch_size, trg_len, hidden_dim]
# positionwise feedforward
_trg = self.positionwise_feedforward(trg)
# dropout, residual and layer norm
trg = self.ff_layer_norm(trg + self.dropout(_trg))
# trg: [batch_size, trg_len, hidden_dim]
# attention: [batch_size, n_heads, trg_len, src_len]
return trg, attentiontrg 즉 번역 이후의 문장을 의미하며 decoder엔 6개의 layer가 들어감
class Decoder(nn.Module):
def __init__(self, output_dim, hidden_dim, n_layers, n_heads, pf_dim, dropout_ratio, device, max_length=100):
super().__init__()
self.device = device
self.tok_embedding = nn.Embedding(output_dim, hidden_dim)
self.pos_embedding = nn.Embedding(max_length, hidden_dim)
self.layers = nn.ModuleList([DecoderLayer(hidden_dim, n_heads, pf_dim, dropout_ratio, device) for _ in range(n_layers)])
self.fc_out = nn.Linear(hidden_dim, output_dim)
self.dropout = nn.Dropout(dropout_ratio)
self.scale = torch.sqrt(torch.FloatTensor([hidden_dim])).to(device)
def forward(self, trg, enc_src, trg_mask, src_mask):
# trg: [batch_size, trg_len]
# enc_src: [batch_size, src_len, hidden_dim]
# trg_mask: [batch_size, trg_len]
# src_mask: [batch_size, src_len]
batch_size = trg.shape[0]
trg_len = trg.shape[1]
pos = torch.arange(0, trg_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
# pos: [batch_size, trg_len]
trg = self.dropout((self.tok_embedding(trg) * self.scale) + self.pos_embedding(pos))
# trg: [batch_size, trg_len, hidden_dim]
for layer in self.layers:
# 소스 마스크와 타겟 마스크 모두 사용
trg, attention = layer(trg, enc_src, trg_mask, src_mask)
# trg: [batch_size, trg_len, hidden_dim]
# attention: [batch_size, n_heads, trg_len, src_len]
output = self.fc_out(trg)
# output: [batch_size, trg_len, output_dim]
return output, attention전체적인 Transformer의 structure
class Transformer(nn.Module):
def __init__(self, encoder, decoder, src_pad_idx, trg_pad_idx, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.device = device
# 소스 문장의 <pad> 토큰에 대하여 마스크(mask) 값을 0으로 설정
def make_src_mask(self, src):
# src: [batch_size, src_len]
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
# src_mask: [batch_size, 1, 1, src_len]
return src_mask
# 타겟 문장에서 각 단어는 다음 단어가 무엇인지 알 수 없도록(이전 단어만 보도록) 만들기 위해 마스크를 사용
def make_trg_mask(self, trg):
# trg: [batch_size, trg_len]
""" (마스크 예시)
1 0 0 0 0
1 1 0 0 0
1 1 1 0 0
1 1 1 0 0
1 1 1 0 0
"""
trg_pad_mask = (trg != self.trg_pad_idx).unsqueeze(1).unsqueeze(2)
# trg_pad_mask: [batch_size, 1, 1, trg_len]
trg_len = trg.shape[1]
""" (마스크 예시)
1 0 0 0 0
1 1 0 0 0
1 1 1 0 0
1 1 1 1 0
1 1 1 1 1
"""
trg_sub_mask = torch.tril(torch.ones((trg_len, trg_len), device = self.device)).bool()
# trg_sub_mask: [trg_len, trg_len]
trg_mask = trg_pad_mask & trg_sub_mask
# trg_mask: [batch_size, 1, trg_len, trg_len]
return trg_mask
def forward(self, src, trg):
# src: [batch_size, src_len]
# trg: [batch_size, trg_len]
src_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(trg)
# src_mask: [batch_size, 1, 1, src_len]
# trg_mask: [batch_size, 1, trg_len, trg_len]
enc_src = self.encoder(src, src_mask)
# enc_src: [batch_size, src_len, hidden_dim]
output, attention = self.decoder(trg, enc_src, trg_mask, src_mask)
# output: [batch_size, trg_len, output_dim]
# attention: [batch_size, n_heads, trg_len, src_len]
return output, attention
work0ut
글이 너무 야해요