성능 테스트

성능 테스트란?
특정 워크로드에서 애플리케이션의 안정석과 속도, 확장성 및 반응성이 어떻게 유지되는지를 판별하는 과정
- 소프트웨어의 품질을 보장하는 방법이지만 나중에 고려할 요소로 남겨둠
- 성공적인 성능 테스트는 DB, 네트워크, 소프트웨어, 하드웨어 등과 관련 될 수 있는 대부분의 성능 문제를 예측해야 할 수 있어야 함
성능 테스트의 의미
- 애플리케이션 혹은 서비스가 충분한 성능 요건을 충족하는지
- 병목 지점은 없는지
- 최대 트래픽에서 안정성에 이상이 없는지
- 오랫동안 같은 동작을 할 수 있는지
성능 테스트 계획 세우기
- 요구사항 분석: DB 쿼리속도, URL요청에 대한 수준
- 수행계획 수립: 테스트 툴 및 환경 지정
- 성능목표 수립: 어떤 성능을 타겟으로 하는지 지정
- 테스트 환경 설정 및 설계: 어떤 테스트 시나리오에서 어떻게 동작할지
- 테스트 설계에 대한 구현
- 테스트 실행
- 테스트 데이터 분석 및 리포팅, 재 테스트
성능 테스트의 종류
- 부하 테스트 (Load Test)
- 일정 시간 동안 부하를 가하여 처리할 수 있는
최대 TPS(Transaction Per Second)와 응답시간을 구하는 테스트 - 1시간 정도의 부하를 가함
- 일정 시간 동안 부하를 가하여 처리할 수 있는
- 내구성 테스트 (Endurance Test)
- 긴 시간 동안 부하를 가하여 시스템의 안정성을 점검하는 테스트
- 8시간 이상 부하를 가함
- 스트레스 테스트 (Stress Test)
- 정상보다 더 많은 부하를 주는 테스트
- 피크 트래픽의 2배 정도 부하를 가함
- 스파이크 테스트 (Spike Test)
- Stress Testing의 Subset
- 상용 운영환경에서 예상되는 부하 이상의 Workload를
짧은 기간동안 반복적으로 증가시킬 때 나타나는 성능 특성을 검증 - 즉, 낮은 트래픽에서 급작스럽게 2~3배 이상의 트래픽이 들어왔을 때 정상적으로 작동하는지 테스트
- 확장성 테스트 (Scalability Test)
- 트랜잭션 수, 데이터 양 등과 같은 측면에서
시스템이 확장할 수 있는지를 판단하기 위한 테스트 - 더이상 확장하지 못하도록 막는 시스템의 최대치가 무엇인지 확인하는 것
- 트랜잭션 수, 데이터 양 등과 같은 측면에서
- 볼륨 테스트 (Volume Test)
- 처리해야 할 많은 양의 데이터를 가진
애플리케이션의 성능을 확인하기 위한 테스트
- 처리해야 할 많은 양의 데이터를 가진
성능 테스트를 위한 Tools
JMeter
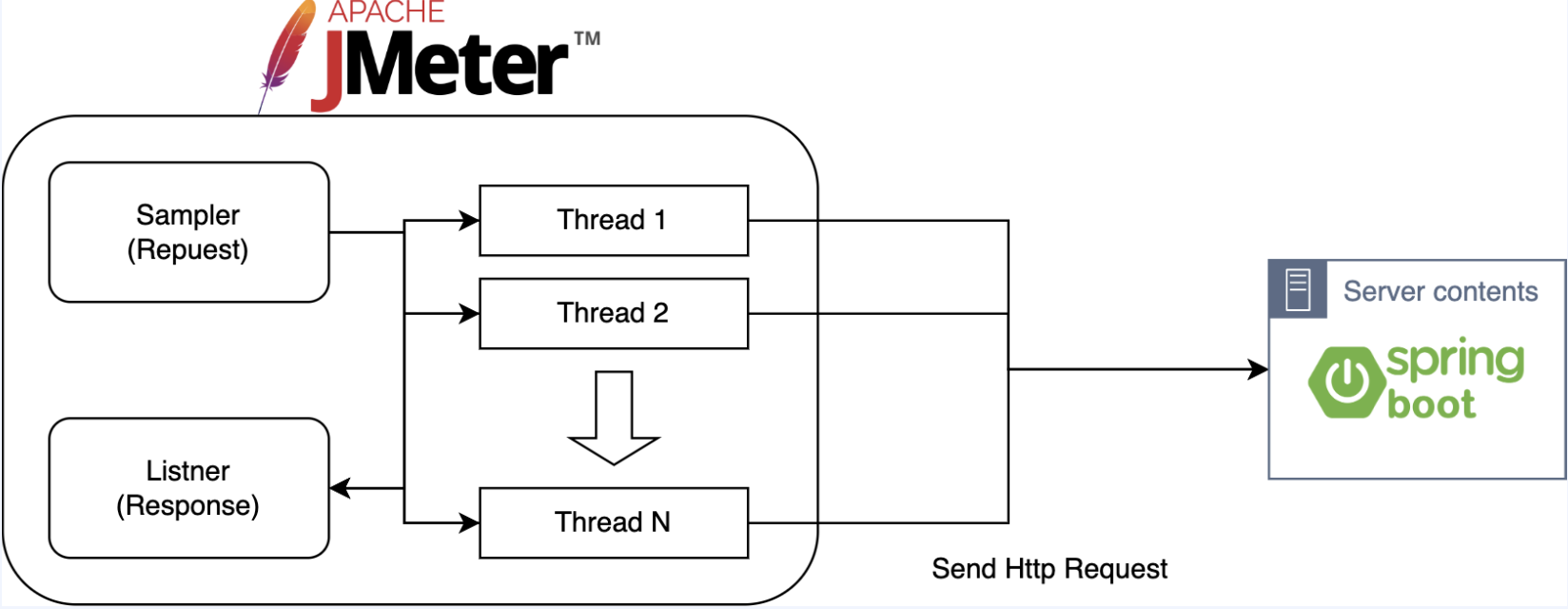
Apache 재단에서 오픈소스로 만든 Java 기반의 성능 테스트 툴
- 생성된 .jmx 파일을 이용해서 CLI로 실행도 가능
- HTTP(s), FTP, SOAP등 다양한 프로토콜을 지원
nGrinder

네이버에서 성능 측정 목적으로 jython(JVM 위에서 파이썬이 동작)으로 개발된
오픈소스 성능 테스트 툴
- Custom library를 활용한 Test 가능
- Web UI를 제공
- 부하를 주는 Agent와 부하를 받는 Target 서버에 대한 모니터링
- 동시에 여러 성능 테스트 가능
Locust
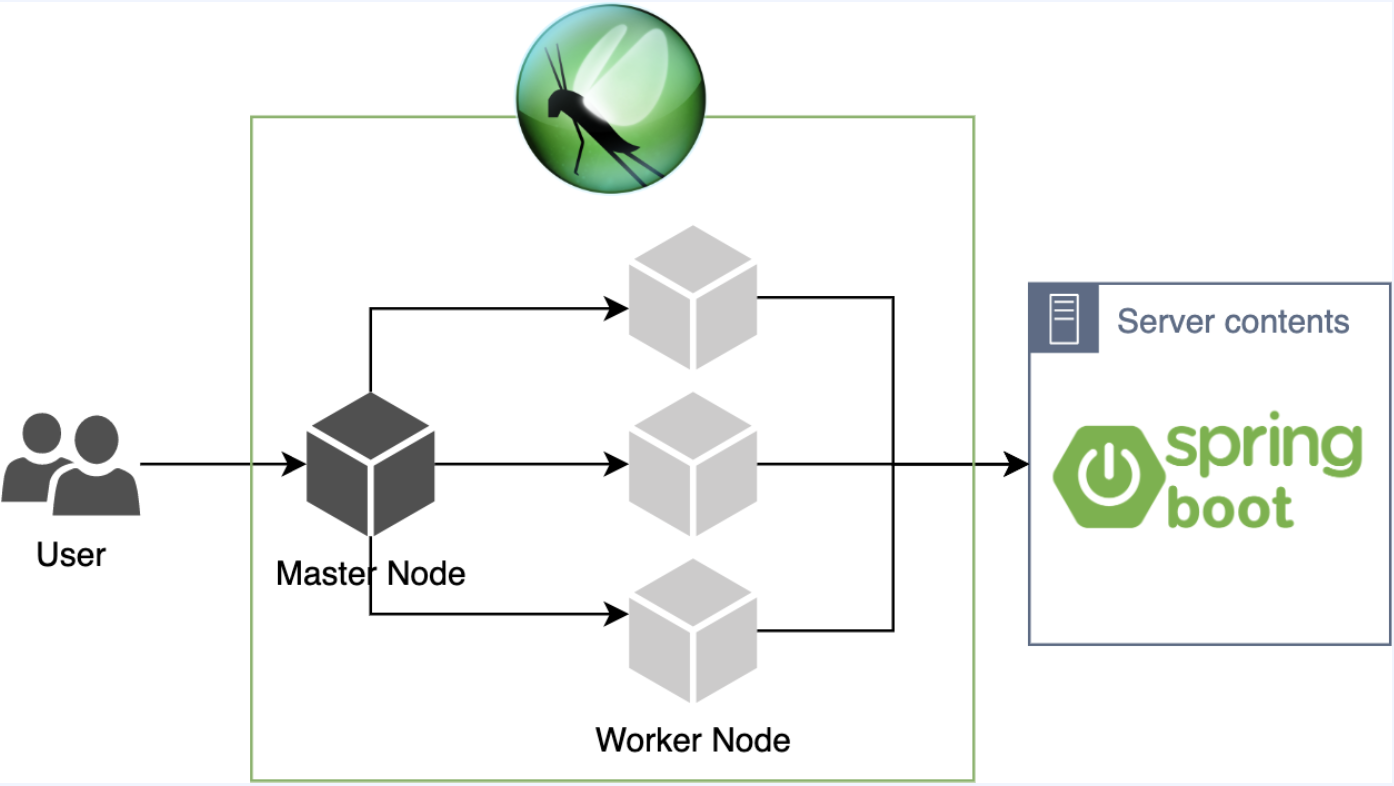
Python Script 기반의 오픈소스 성능 테스트 툴
- Greenlet이라는 경량화된 프로세스/코루틴을 사용해서 수십만의 유저를 지원
- Flask를 사용하여 Web_UI로 설정/모니터링 가능
성능 테스트 지표란?
성능 테스트에 대해 설정을 하고, 이를 수행한 다음 서비스에 대해 성능을
객관적인 데이터로 보는데 사용
- 이 데이터들을 활용해 서비스의 임계점이나 병목지점을 찾을 수 있음
- 실제 서비스를 운영하는 환경과는 다르지만 예측할 수 있는 데이터로 활용됨
성능테스트 지표와 개념 (User)
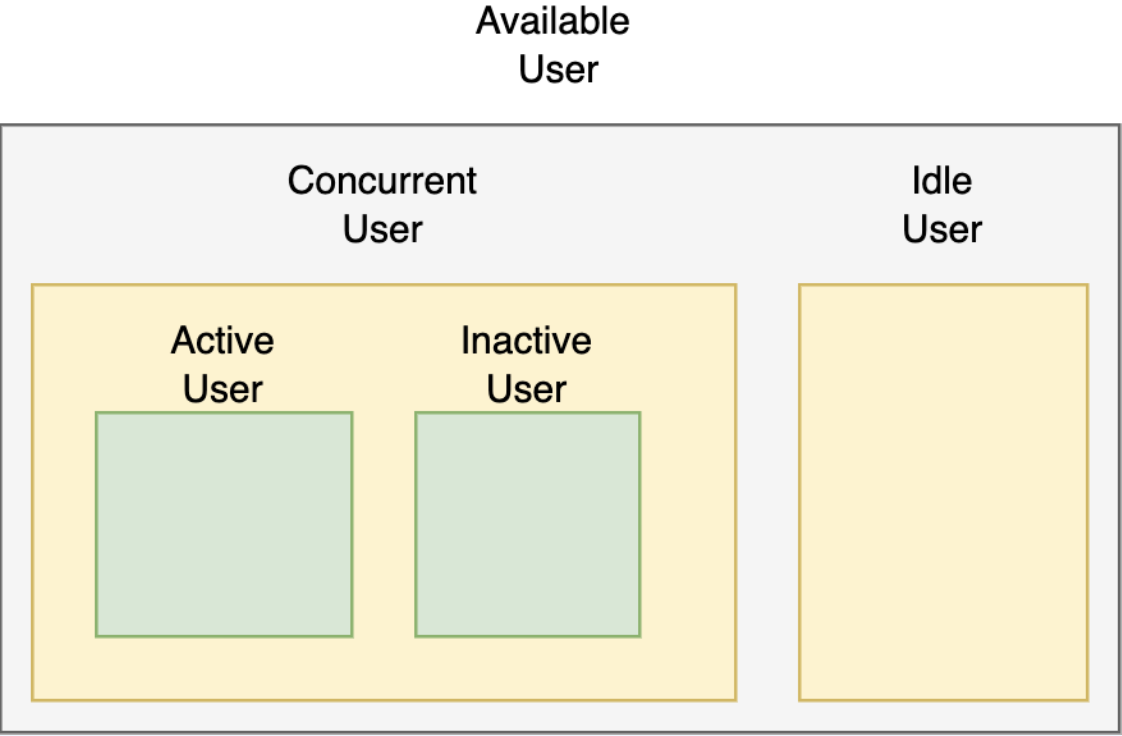
- vUser: 가상 사용자 수
- Active user: 메뉴나 링크를 누르고 결과가 나오기를 기다리는 등
실제로 서버에 부하를 주고 있는 사용자 - Concurrent user: 웹 페이지를 띄워 놓은 사용자처럼,
언제든지 부하를 줄 수 있는 사용자
성능테스트 지표와 개념 (Request)
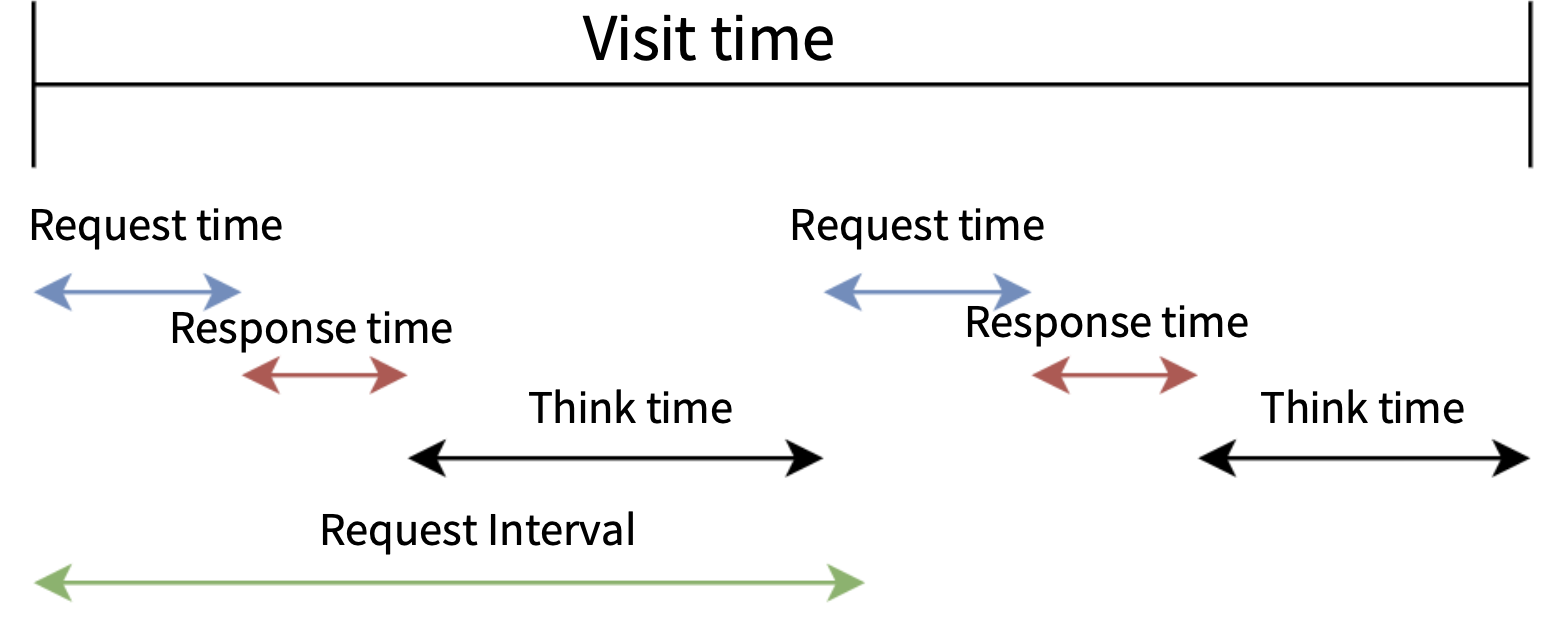
- Visit Time: 접속한 페이지를 들어오고 나가는데 까지의 시간
- Request Time: 요청하는데 걸리는 시간
- Response Time: 요청에 응답이 오는 데까지 걸린 시간
- Think Time: 응답을 이후 다음 요청까지 걸리는 시간
- Request Interval: 요청과 다음 요청 사이의 간격 시간
- TPS: 단위시간(초)당 서버에서 Transaction(요청)을 처리할 수 있는 양
성능테스트 지표와 개념 (System)
- CPU Usage/Used: Host CPU의 사용량 혹은 사용률
- 사용량: core/mb
- 사용률: %
- Memory Usage/Used: Host Memory의 사용량 혹은 사용률
- Disk I/O Time: 요청을 디스크에 작성(Write)하거나 읽기(Read)를 실행하는데 소요되는 시간
- Network I/O throughput: 네트워크 인터페이스에서 사용하는 초당 비트수
- Active Thread Count: 활성 스레드 수
모니터링
모니터링이란?
지속적인 관찰을 통해 모니터링 대상의 상태나 가용성, 변화 등을 확인하고
예상하지 못한 상황과 오류에 대비하는 것
- 클라우드 모니터링, 시스템 모니터링, 데이터베이스 모니터링, APM, UI 모니터링, CI 모니터링, 보안 모니터링...
모니터링이 필요한 이유
- 사전 분석을 통해 장애를 방지
- 다운 타임 최소화로 손실 방지
- 생산성 및 성능의 향상
- 모니터링을 통해 IT 비용 예산 수립 가능
- 데이터 기반의 의사결정 가능
Open Telemetry란?
Trace, Metric, Log와 같은 Telemetry 데이터를 Instrumenting, Generating, Collecting, Exporting 하기 위한 특정 벤더에 종속되지 않은 오픈소스
오픈 텔레메트리(Open Telemetry)
= 오픈 트레이싱(Open Tracing) + 오픈 컨세서스(Open Consesus)
- Instrumenting (계측): 이 단계에서는 애플리케이션 또는 시스템에
측정 도구를 설치.
이를 통해 Trace, Metric, Log와 같은 Telemetry 데이터를 수집.
예를 들어, 웹 애플리케이션에서 사용자의 요청 시간이나 서버의 응답 시간을 측정. - Generating (생성): Telemetry 데이터가 실제로 생성되는 단계.
예를 들어, 사용자의 요청에 대한 로그 파일이 생성되거나,
시스템의 CPU 사용량과 같은 메트릭 데이터가 생성. - Collecting (수집): 생성된 데이터를 수집하는 단계.
수집된 데이터는 로컬 또는 클라우드 기반 저장소에 저장. - Exporting (내보내기): 수집된 데이터를 다른 시스템이나 도구로 전송하는 과정. 이를 통해 데이터 분석, 모니터링, 경고 설정 등의 목적으로 데이터를 활용.
인프라 수준에서의 모니터링
- IaaS수준에서 제공되는 서비스에 대한 모니터링
- 서버의 상태나 시스템에서 발생한 이벤트를 모니터링 할 수 있음
- 데이터베이스 혹은 네트워크 흐름을 모니터링하여 병목 지점을 찾을 수 있음
애플리케이션 수준에서의 모니터링
- 분산된 여러 클라우드 기반 앱을 한 시스템 혹은 대시보드에서 모니터링
- 인프라 수준 지표 뿐 아니라 비즈니스 트랜잭션 및 코드레벨까지 모니터링
- 각 서비스 구간 별로 성능을 기록해 병목을 파악하고 대응(Trace-span 구조)
로그 수준에서의 모니터링
- 애플리케이션 혹은 액세스 로그 등의 요소를 수집하여 로그와 메트릭을 조합하여 특정 시점에 발생한 오류에 대해 인사이트를 찾아낼 수 있음
SLI와 SLO
서비스가 잘 돌아간다 혹은 성능이 좋다는 객관적 기준
➡️ 즉, 서비스를 운영함에 있어 데이터를 기반한 의사결정이 필요
➡️ SLI(서비스 수준의 척도)와 SLO(서비스 수준의 목표)
- SLI는 서비스에 대한 수준을 측정하여, 정량적으로 정의한 지표
- SLO는 각 지표에 대한 목표 값 = SLI + Target Value (목표 값)
SLI
SLI: 서비스에 대한 수준을 측정한 지표
Ex) 1주인 간 10분의 장애로 서비스를 사용 못했을 경우, 가용성을 계산
1주일(7x24x60) - 10분 / 1주일 = 99.9007%의 가용성
- 평균값이나 중간값보단 Percentile에 따른 분포로 사용하는 것을 추천
시스템에 따른 SLI로 사용할 만한 지표
- B2C 서비스: 가용성, 응답시간, 처리량
- 스토리지 시스템: 가용성, 응답시간, 내구성
- ML 시스템: 서빙 응답시간, 학습시간, 처리량, 가용성, 서빙 정확도
SLO
SLO: 서비스에 대한 수준에 대한 목표치
- SLO=SLI<=목표값 OR 하한값<=SLI<=상한값
- 측정방식과 유효 값의 기준이 명확해야 함
- SLO는 서비스의 사용자관점에서 서비스에 얼마나 영향을 주는 지에 대한
관점에서 결정
SLO에 대한 5가지 조언
1. 현재의 성능을 기준으로 목표치를 설정하지 말 것
2. 최대한 단순하게 생각할 것
3. 현실성 있는 목표치를 설정할 것
4. 시스템의 특성을 잘 확인할 수 있는 가능한 적은 수의 SLO를 설정할 것
5. 처음부터 완벽하게 하려고 하지 말 것
모니터링에 SLI/SLO를 적용하는 방법
Observability = 모니터링을 통해 왜 현상이 일어났는지 분석하고 해결하는 접근방식
- 시스템의 SLI들을 모니터하고 측정하기
- SLI를 SLO와 비교해서 대응이 필요한지 판단하기
- 대응이 필요한 경우, SLO를 달성하기 위해 어떻게 대응할지 판단하기
- 대응하기
