우리 회사에서는 주문 도메인을 운영하고 있으며, 주문 개수가 증가하면서 점차 조회 성능이 저하되는 문제가 발생했다.
특히, 주문 목록을 조회할 때 응답 시간이 길어져 운영에 불편함이 발생했다.
이에 따라, MySQL 쿼리 최적화를 통해 성능을 개선하는 작업을 수행했고, 그 과정과 결과를 공유하고자 한다.
문제 상황
- 주문 개수가 증가하면서 주문 조회 API의 실행 속도가 느려짐
- 운영 중 관리자가 특정 기간의 주문 데이터를 조회하는 데 6초 이상 소요
- 개선 목표: 응답 시간을 최소한 1초 이내로 줄이는 것
기존 쿼리 구조
테이블은 orders, orders_detail 이 존재한다.
SELECT
o.id,
od.id,
...
od.created_at
FROM
orders_detail od
JOIN
orders o ON od.order_id = o.id
WHERE
od.created_at BETWEEN :ordered_start_date AND :ordered_end_date;조금 간추렸지만 대략적으로 주문 조회시 해당 쿼리를 사용하고 있다
주문이 많을 경우를 테스트하기 위해여 100만 정도의 주문 개수를 넣었다
(created_at 은 2024-01-01 부터 2024-12-29 까지 랜덤)
전체 테스트 상황은 아래와 같다.
- orders_detail(주문 상세)과 orders(주문) 테이블을 JOIN하여 조회
- created_at 범위 조건을 사용하여 특정 날짜의 주문만 조회
- 테스트 데이터: 약 100만 개의 주문 데이터 삽입 후 테스트 진행
2일치 데이터 테스트
- 조회 조건: created_at 기준 2일치 데이터 (약 5,553건)
- 평균 실행 시간: 6초 511ms
EXPLAIN 결과 분석
EXPLAIN 결과를 보면, 주요 성능 저하 원인이 orders_detail 테이블의 Full Table Scan(전체 테이블 스캔) 에 있었다.

[분석 결과]
-> Limit: 10000 row(s) (cost=227608 rows=10000) (actual time=11.4..6888 rows=5553 loops=1)
-> Nested loop inner join (cost=227608 rows=106021) (actual time=11.4..6888 rows=5553 loops=1)
-> Filter: (od.created_at between '2024-09-01' and '2024-09-02') (cost=111017 rows=106021) (actual time=11.2..6884 rows=5553 loops=1)
-> Table scan on od (cost=111017 rows=954288) (actual time=0.817..6734 rows=1e+6 loops=1)
-> Single-row covering index lookup on o using PRIMARY (id=od.order_id) (cost=1 rows=1) (actual time=356e-6..380e-6 rows=1 loops=5553)문제점
- orders_detail 의 테이블 스캔 시간 : 6734 ms (끝) - 0.817 ms (시작) = 6733.183 ms (약 6.733초)
- 주요 원인
- 필터링 시간 : 6884 ms - 11.2 ms = 6872.8 ms 그러나, 시간이 누적되므로 6.733 초를 빼야한다 -> 약 0.140초
개선과정
1. 쿼리 순서 변경
처음에는 새로운 인덱스를 생성하지 않고도 성능을 개선할 수 있는 방법을 우선적으로 고려했다.
그 이유는 인덱스 생성에는 비용이 따르기 때문이다.
(인덱스 추가시 데이터 변경에 대한 부가적인 성능 오버헤드가 발생)
첫째로 데이터 접근 수를 줄이는 방법을 생각해보았다
이유는, 두 테이블에 대한 Join 을 했을 때 분석결과를 보면 풀 테이블 스캔 결과 전체를 조인하는 결과가 나왔다
쿼리 순서를 필터링 후 필요한 테이블만 조인하도록 변경해보았다
SELECT *
FROM (
SELECT od.id, od.order_id, od.created_at
FROM orders_detail od
WHERE od.created_at BETWEEN '2024-09-01' AND '2024-09-02'
LIMIT 10000
) AS filtered_orders
JOIN orders o ON filtered_orders.order_id = o.id;테스트 결과
- 테이블 스캔 이후 필터링이 먼저 적용됨
- 이후 임시테이블로 생성된 5,553건의 orders 테이블과
Join
[분석 결과]
-> Nested loop inner join (cost=123141 rows=10000) (actual time=6483..6485 rows=5553 loops=1)
-> Table scan on od (cost=112017..112144 rows=10000) (actual time=6483..6484 rows=5553 loops=1)
-> Materialize (cost=112017..112017 rows=10000) (actual time=6483..6483 rows=5553 loops=1)
-> Limit: 10000 row(s) (cost=111017 rows=10000) (actual time=21.5..6457 rows=5553 loops=1)
-> Filter: (orders_detail.created_at between '2024-09-01' and '2024-09-02') (cost=111017 rows=106021) (actual time=21.5..6456 rows=5553 loops=1)
-> Table scan on orders_detail (cost=111017 rows=954288) (actual time=1.71..6309 rows=1e+6 loops=1)
-> Single-row covering index lookup on o using PRIMARY (id=od.order_id) (cost=1 rows=1) (actual time=75.9e-6..95.3e-6 rows=1 loops=5553)
결과를 보면 전체 실행 시간은 6초에서 크게 변하지 않았다 (약 6.4초)
분석 결과를 확인해보니 orders_detail 의 풀 테이블 스캔 자체가 90% 이상의 시간을 차지하고 있다
(임시 테이블 또한 인덱스를 활용하지 못할 가능성이 존재함)
2. 인덱스 생성
주요 원인을 파악했으므로 orders_detail 테이블 스캔 부분을 최적화해보았다
테이블 스캔 최적화에서는 여러가지 방법이 존재한다
- 테이블 파티셔닝
- 특정 컬럼에 대한 인덱스 추가
테이블 파티셔닝 방법은 기존 테이블을 직접 파티셔닝하기 어렵고 데이터 이관 작업이 필요하다 더불어 Join 을 통한 쿼리시 고려해야 할 점들이 많다
당장에 적용하기에 오버 엔지니어링이라 생각하여 인덱스 생성 방법을 적용하기로 했다
created_at 인덱스 추가
해당 쿼리의 조건이 created_at 컬럼이기 때문에 해당 컬럼에 대해 인덱스를 생성하면 좋겠다
그러나 단순히 조회 조건에 있다고 해서 인덱스를 생성하기로 결정한 것은 아니다
특정 컬럼에 대한 인덱스 생성시 고려사항으로
- 중복도
- 해당 쿼리를 자주 사용하는가
위 기준을 통해 해당 컬럼을 선택했다
참고) 중복도가 낮은 컬럼에 대한 인덱스 생성시 장점
- 고유값이 많을수록 원하는 데이터를 빠르게 찾아내기 때문에 인덱스 효율성이 증가함
- 중복이 많으면 조회해야할 데이터 범위가 너무 넓으며 전체 테이블 스캔하는 효율과 비슷하게 결과가 나올수 있다 또한 비슷한 결과가 나올 경우 실행계획을 세울때 굳이
range스캔이 아닌ALL(테이블 스캔) 을 실행할 것이다- 중복도가 많으면 데이터가 많으므로 I/O 작업이 많이 발생한다
(그러나 MySQL 에서는 read-ahaed 기법을 사용해 필요한 데이터 페이지를 미리 읽는 방식을 사용해 최적화하며 버퍼를 통해 미리 캐싱하기도 한다)
컬럼 중복도
주문 도메인의 created_at 컬럼은 주문이 생성될 때의 시간이며 이는 카디널리티가 높은, 중복도가 낮은 컬럼이다
(테스트 데이터에서는 2024-09-01 ~ 2024-09-02 의 데이터는 대략 전체에서 0.5%의 비율을 차지함)
사용자 사용률
SELECT DIGEST_TEXT, COUNT_STAR AS execution_count
FROM performance_schema.events_statements_summary_by_digest
ORDER BY execution_count DESC
LIMIT 10;위 쿼리를 통해 어느 쿼리가 가장 많이 사용되었는데 최대 10개를 확인해보았다
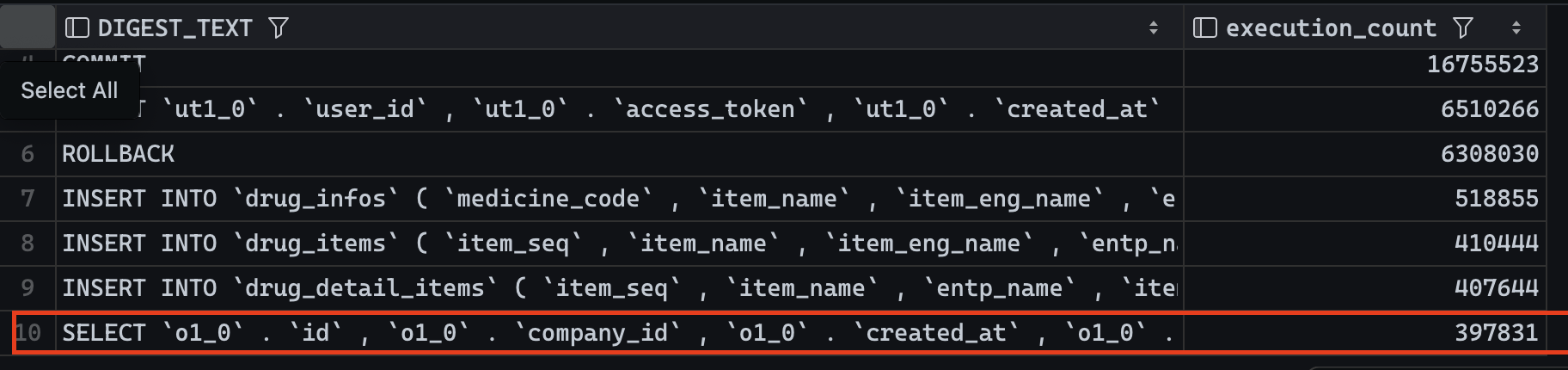
주문에 대한 조회 사용률이 다른 도메인 보다 많은 결과를 기록했다
created_at 컬럼에 대해 인덱스 생성
(idx_created_at)

- 결과는 평균적으로 126ms
- 대략 50배 이상의 성능 개선이 이루어졌다
인덱스를 활용한 실행 계획 변경
- 기존: ALL (Full Table Scan) → 6.7초
- 최적화 후: range (Index Range Scan) → 126ms
[분석 결과]

실제로 임시 테이블을 만들때 idx_created_at 인덱스를 활용했으며 range 스캔을 통해 가져왔다
(정렬된 리프노드 인덱스키를 범위 탐색하여 가져옴)
EXPLAIN ANALYZE
-> Nested loop inner join (cost=11936 rows=5553) (actual time=40.5..43.5 rows=5553 loops=1)
-> Table scan on od (cost=5757..5829 rows=5553) (actual time=40.5..42.2 rows=5553 loops=1)
-> Materialize (cost=5757..5757 rows=5553) (actual time=40.5..40.5 rows=5553 loops=1)
-> Limit: 10000 row(s) (cost=5202 rows=5553) (actual time=3.94..25.9 rows=5553 loops=1)
-> Index range scan on orders_detail using idx_created_at over ('2024-09-01 00:00:00' <= created_at <= '2024-09-02 00:00:00'), with index condition: (orders_detail.created_at between '2024-09-01' and '2024-09-02') (cost=5202 rows=5553) (actual time=3.94..25.6 rows=5553 loops=1)
-> Single-row covering index lookup on o using PRIMARY (id=od.order_id) (cost=1 rows=1) (actual time=87.1e-6..112e-6 rows=1 loops=5553)분석결과를 보면 따로 필터링하는 부분이 사라져있고 Index range scan 을 통해 범위 최적화를 진행했다
Range Scan 시간 : 25.6ms − 3.94ms = 21.66ms
그외에는 크게 걸린 시간은 없었다
- Table scan on od : 42.2 ms - 40.5 ms = 1.7 ms
- Nested loop inner join : 43.5 ms - 40.5 ms = 3 ms