
📝 쿠버네티스 제공 기능
- 서비스 디스커버리와 로드밸런싱
- 스토리지 오케스트레이션
- 자동화된 롤아웃과 콜백
- 자동화된 빈 패킹(각 컨테이너 별 필요한 cpu 자동 설정)
- 자동화된 복구(실패한 컨테이너 다시 시작)
- 시크릿과 구성 관리(중요한 정보 저장 및 관리) : config 설정 바뀔 시 재배포 필요한데 쿠버네티스 리소스에 환경변수를 넣어주면 자동 마운트 -> 의존성 분리 -> 기능 변경이 있을때만 재배포 하면 됨
📝 쿠버네티스 아키텍처
-
Master Node와Worker node로 구성
(둘다 여러개로 구성될 수 있음) -
pod단위로 움직임
각 api 서버 별 컨트롤러 매니저가 알맞은 컨트롤러를 배치해줌
모든 명령은 api서버로 부터 받고, 그 응답 또한 api 서버에게 보내줌
(모든 통신은 API서버를 이용 => api는 굉장히 중요)
워커 노드 또한 api 서버로 요청 받음(Kubelet)
이때 상태는,
ready : 통신환경 세팅 완료
not ready : 통신환경 세팅X
api 서버가 주기적으로 상태를 체크 -> 통신이 안될 경우 해당 pod를 다른 곳에 분산배치 하는 방식으로 진행
(해당 방식도 사용자가 원하는 옵션에 따라 설정 가능)
또한 pod의 중요도에 따라 우선순위를 다르게 하는 것도 가능함
📝 쿠버네티스 오브젝트
pod에 관한 명세를 YAML 파일로 정의 (사용자가 원하는 방식으로)
현재 상태(Current State)를 원하는 상태(Desired State)로 맞추기 위해 무한으로 스케줄링
📌 kubernetes configuration
1. Imperative(명령형)
- 무언가를 작업하기 위한 방법을 정의
- run, create 등의 명령어가 다양함
- 명령어를 사용하기 때문에 편리하지만, 명령어가 증가하면 어려움
2. Declarative(선언형)
- 무언가 작업을 하기 위해 파일에 미리 선언
- YAML 파일에 선언 하는등의 방식
- 사용자가 원하는 방식을 파일에 미리 선언만 해 두면 되기 때문에 간편하나,
처음 사용 시 해석이 어렵다는 단점이 있음
📌 Kubernetes Control loop
- Desired State가 Current State와 일치할때까지 계속 반복
- Watch 매커니즘
📌 Kubernetes YAML
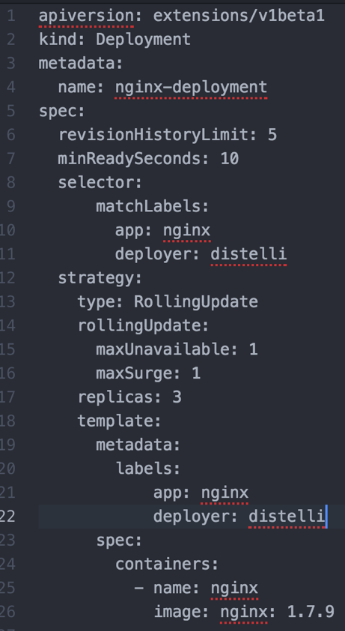
이미지 출처 : https://developer.ibm.com/tutorials/yaml-basics-and-usage-in-kubernetes/
- apiVersion : 쿠버네티스 오브젝트에 사용되는 API 버전 지정
- kind : YAML을 이용해 생성하고자 하는 쿠버네티스 오브젝트 지정
- metadata : 오브젝트 구분이 가능한 데이터 정보 (이름 등)
- annotations : 오브젝트에 메타데이터 첨부 시 사용
- lables : 태그와 같은 기능
- spec : 사양 정보
-> replicas : 몇개의 pod를 띄울건지?
-> selector : 레이블을 이용해 오브젝트 쉽게 식별. 컨트롤러가 모니터링 해 야 하는 대상을 명시
-> template : 새 pod를 런칭하는데 사용할 템플릿
📌 workload 생성을 위한 기본 컨셉
- Sidecar : 기본 컨테이너 기능을 확장하거나 강화하는 용도의 컨테이너
(메인이 되는 컨테이너 옆에 추가로 붙이는 컨테이너 -> 로그수집 등의 용도) - DaemonSet : 모든(또는 일부) 노드가 동일한 pod 실행
(각 노드에 하나씩 pod를 실행) - Addon : 기능을 구현 및 확장하는 역할
(부족한 기능이 있을 경우 추가 기능)
📝 Deployment 업데이트 흐름
예를들어, pod를 총 3개 띄우고 싶을 경우?
deployment로 version이 1이라는 replication set을 하나 띄움
여기서, 새로운 set을 만들고 싶을 경우 version 2의 replication set을 하나 더 띄움
이때, version 2라는 replication set은 pod가 하나만 뜬다.
이전 pod를 모두 지우는것이 아니라 하나의 pod씩 띄우면서 이전의(version 1의) pod를 하나씩 지워준다.
