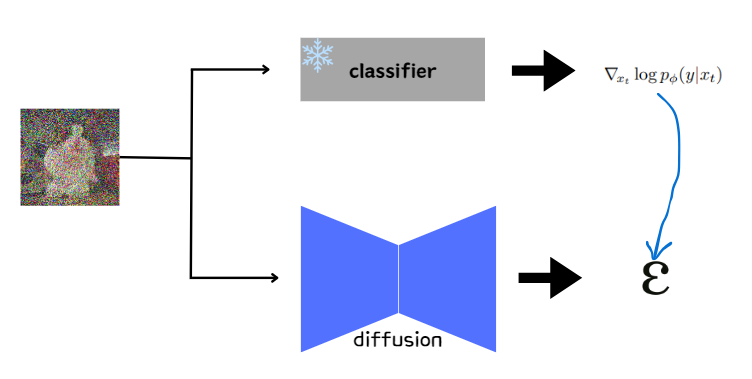
Classifier Guidance
score function
score function: ∇logp(xt)=−1−αˉt1ϵθ(xt)
-likelihood의 gradient 방향으로 이동하면 우도가 높아짐
∇logp(xt∣y)=∇log(p(y)p(xt)p(y∣xt))
=∇logp(xt)+∇logp(y∣xt)−∇logp(y)
=unconditional score∇logp(xt)+adversarial gradient∇logp(y∣xt)
∇logp(xt∣y)=∇logp(xt)+γ∇logp(y∣xt)
classifier free guidance
unconditional score∇logp(xt)+adversarial gradient∇logp(y∣xt)
∇logp(y∣xt)=∇logp(xt∣y)−∇logp(xt)
∇logp(xt∣y)=∇logp(xt)+γ(∇logp(xt∣y)−∇logp(xt))
=∇logp(xt)+γ∇logp(xt∣y)−γ∇logp(xt)
=conditional scoreγ∇logp(xt∣y)+unconditional score(1−γ)∇logp(xt)


