Graphormer: Do Transformers Really Perform Bad for Graph Representation?(NeurIPS_2021)
Graph Neural Network
Introduction
--Transformer는 natural language, computer vision에서 powerful neural network로 좋은 performance를 보여줌
--하지만 graph domain에서의 Transformer 방법론은 Graph neural network에 Aggregation을 softmax attention으로 대체하는게 유일한 방법론이였음
--이후, Graphormer 저자들은 graph에서 Transformer를 보다 효과적으로 사용하려면 graph 구조 정보가 중요한 key라고 설명
--즉, self-attention은 graph의 구조적 정보를 반영하지 않고 노드간의 유사성만 계산하기 때문에 저자들은 graph 구조 정보를 반영할 수 있는 encoding methods를 제시함
encoding methods
- Centrality Encoding
- Spatial Encoding
- Edge Encoding
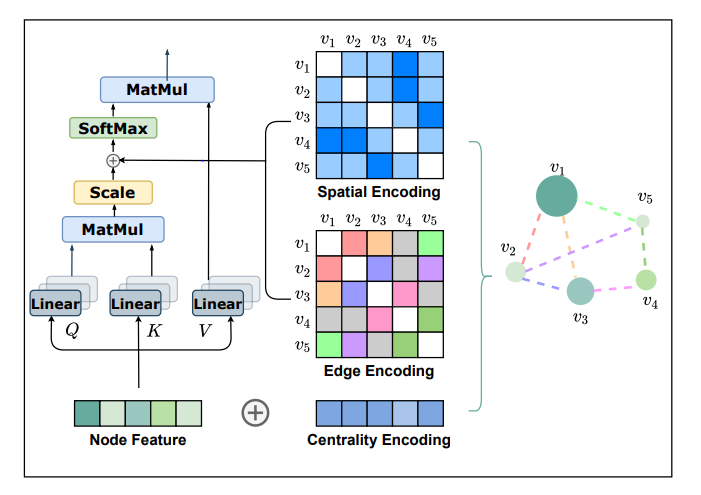
Graphormer
1. Centrality Encoding
-centrality endcoding은 graph에서 node의 중심성을 나타내는 과정이다.
-centrality를 계산하는 방법에는 betweenness, eigenvalue,.. 여러 방법이 있지만 해당 논문에서는 degree를 통해 계산
-directed graph에서는 degree 정도를 계산하기 위해 각 노드의 indegree, out-degree 두 개의 embedding 값을 계산
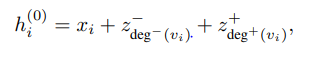
-undirected graph 경우에는 indegree 하나로 계산 이후, node features에 더하고 input으로 사용
-저자들은 centrality encoding을 사용함으로써 attention mechanism을 통해 correlation과 node 중심성(importance)를 고려할 수 있다고 설명
2. Spatial Encoding
-Transformer는 sequence data에 position embedding을 진행, 하지만 graph 구조의 경우 유클리드 공간에 표현이 불가능
-저자들은 노드간의 상대적 거리를 측정하기 위해 function 정의
(는 graph의 node 사이의 연결성을 정의한 function)
-이후 를 통해 node 와 가 연결되어 있다면 shortest path(SPD)를 통해 와 의 상대적 거리 계산
(만약 연결이 안 되어 있다면 임의로 지정한 special value 값을 사용 ex) -1)
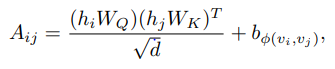
-상대적 거리를 계산한 후 self-attention module에서 bias term으로 사용
- 는 learnable scalar, and shared across all layers.
-저자들은 spatial encoding의 이점을 설명
- 제한적인 receptive field를 가지는 GNN과 비교하면 spatial encoding은 각 node의
global information을 받을 수 있음
- 제한적인 receptive field를 가지는 GNN과 비교하면 spatial encoding은 각 node의
- bias turm을 사용함으로써 graph의 구조적 정보를 반영할 수 있음
ex) 만약 가 감소하는 방향으로 학습한다면 근처 node에 attention하고 멀리 있는 node에는 덜 attention
- bias turm을 사용함으로써 graph의 구조적 정보를 반영할 수 있음
3. Edge Encoding
-Graph task에서 node의 구조 정보를 반영하는 것이 중요하듯 edge의 구조 정보를 반영하는 것도 중요하다고 저자들은 설명
ex) 분자 구조의 단일결합, 이중결합, 삼중결합을 edge로 표현
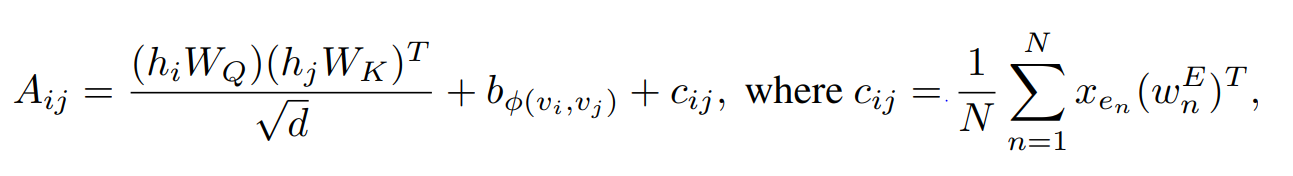
: n-th edge feature
: n-th weight embedding
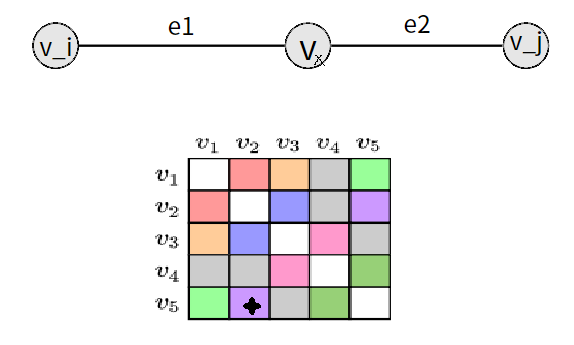
4. Virtual Node
readout function
-readout function을 통해 graph representation 진행
(fully connected layer, pooling.. 여러 방법론이 있음)
Virtual Node
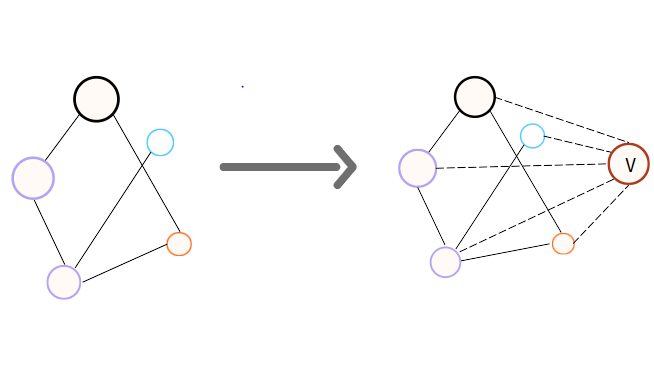
-graphormer 저자들은 readout function 대신 virtual node를 만들고 graph의 모든 node를 virtual node에 1-hop으로 연결 즉, graph의 모든 node에서 virtual node까지 shortest path가 1
-virtual node는 graph의 모든 node로부터 정보를 받기 때문에 graph의 대표 node가 됨
Experiments
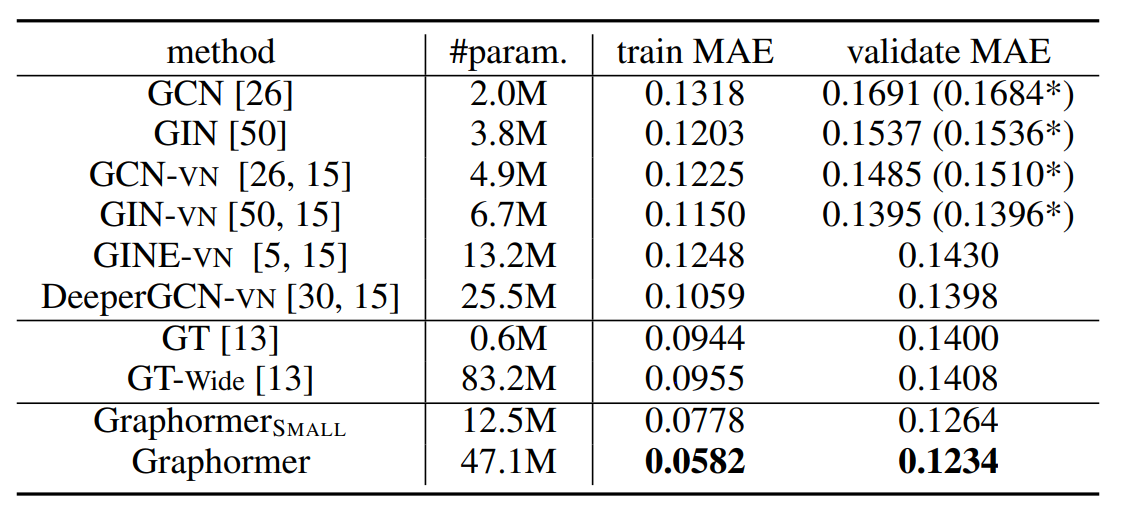
Dataset : PCQM4M-LSC
-PCQM4M-LSC는 양자 화학 데이터셋으로 밀도범함수(DFT)로 분자 에너지 차이를 예측
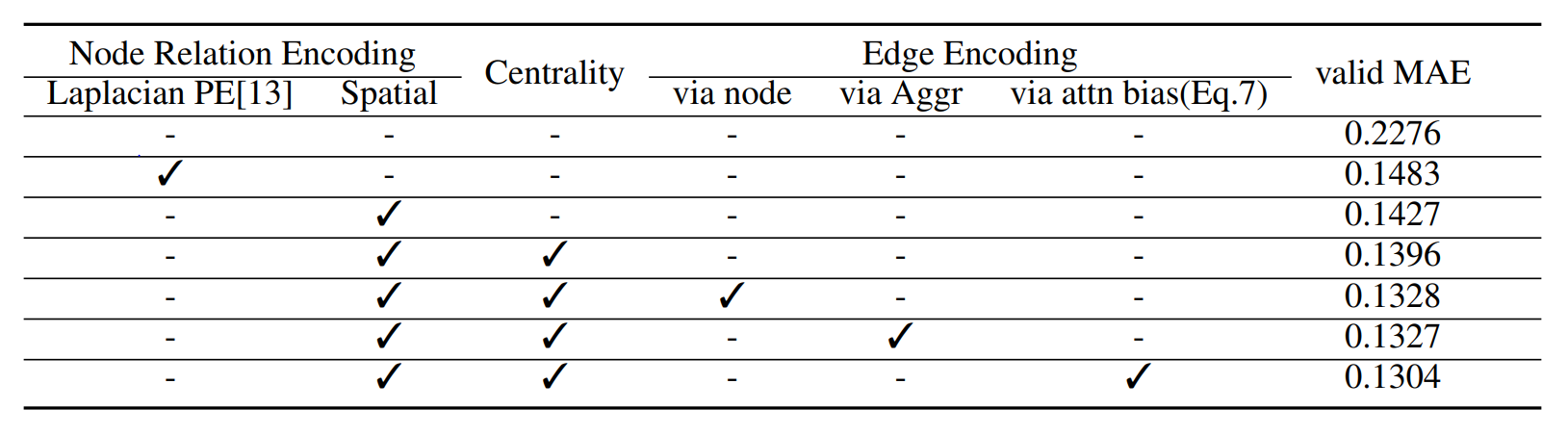
Ablation Studies
Conclusion
-large graph에서의 효율적인 Graphormer 연구가 필요
-node representation을 위한 graph sampling 방법론의 연구가 필요
